
未経験からAI絵師になる方法

突然来た未来
2022年8月にStable Diffusionが発表されてから、生成系AI(画像、文章などを作成する)が突然脚光を浴びました。
Stable Diffusionだけでなく、Novel-AI、Midjourney、ChatGPTで有名なOpenAI社のDALL-Eなど、文章(テキスト)から画像が作成できることに本当に驚きました。
それから半年経った今では、AIが生成できる画像も飛躍的に進歩しました。
これは、Stable Diffusionがオープンソースで公開されたのが大きな理由だと思います。
無料でソースコードが公開されているのですから、興味を持った世界中の人たちが独自の学習モデルや追加学習を公開しています。
イラストやマンガを描いても小学生の落書きに負ける私としては、映画や小説で描かれていた未来が突然現実となりました。
いや〜、スゴい世界になったものです。
あなたもAIでイラスト作成しませんか?
あなたも、こんなイラストを「クリックだけ」で作成してみませんか?

もし、あなたがAIイラストを作りたいと思ったのであれば、今から始めませんか?。
まずは、どの方法でイラストを作るかを決める。
AIイラストを作成する方法はいくつかありますが、2023年5月のAIイラスト生成は、Stable DiffusionとMidjourney(nijijourney)のツートップ状態と言ってもよいでしょう。
その中から、私は、Stable Diffusionを選択します。
なぜ、Stable Diffusionを選ぶのか?
Midjourneyに毎月30米ドルを支払えば、実質、無制限でAIイラストを作成することができます。しかも、かなり良いイラストが。
Stable Diffusionは、オープンソースで公開されているPython言語で書かれたプログラムで自分でマシンへインストールするところから始めます。
正直、大変です。でも、苦労する価値は絶対にあります。
では、なぜ?
毎月30ドルを支払えばスグにでも始めることのできるMidjourneyではなく、メンドウなStable Diffusionを選択するのでしょうか?
人とは違う画を作りたい
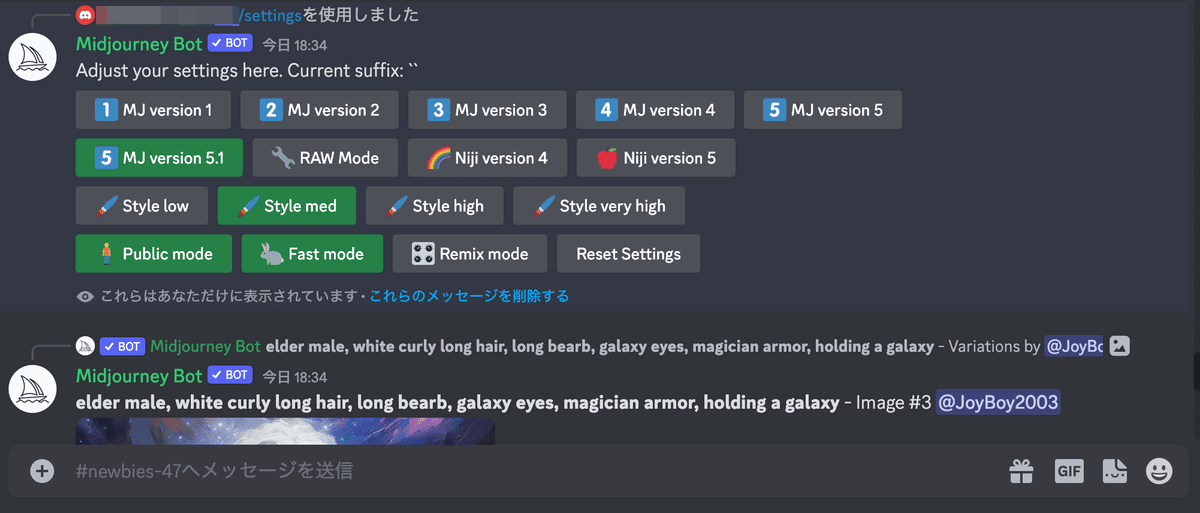
Midjourneyは設定項目はいくつかありますが、選択できる画像生成モデルがバージョン違いのものくらいで、生成される画はバージョンで違いがでますが、他の人との差別化はプロンプトだけが頼みとなります。
Midjourneyでの設定項目は、これくらいです。
一方、Stable Diffusionはオープンソースで公開されているため学習モデルが沢山公開されています。
モデルを変えるだけで、同じプロンプトでも生成される画が大きく変わります。
例えば、この画像は同じプロンプトで学習モデルを変えただけです。AIが生成する画像はガチャ要素が強いといっても、同じ学習モデルでここまでの差はでません。
つまり、学習モデルやLoRA(追加学習モデル)を組合せ、さらにプロンプトで作成する画像を変化させ拡張機能でポーズをつけたり表情を変えれば、
もうそれは「あなたの作品」になります。

AI絵師になる手順
未経験からAI絵師になる手順は、以下の通りです。AIが画を生成するため、あなたが絵が上手いか下手かは関係ありません。
Stable Diffutionで使う用語を知る
必要なアカウントの作成
モデル、LoRAのダウンロード
インストール(クラウドサービス、Windows、macOS)
WebUIの操作方法を知る
拡張機能のインストール
プロンプトの組み立て方法を知る。
初めての画像生成
ひたすら実践(テクニックを学ぶ)
発表する
それでは、ひとつずつ説明していきます。
読み終えた「あなた」は、スグに始めたくなります。
この手順の中で「テクニックを学ぶ」ことだけが大変かと思います。自分でネット上を調べ、試してを繰り返します。
とにかく早くAI絵師になりたいのであれば、「AI絵師養成講座」をご検討ください。

このノートの有料部分には、AI絵師養成講座の15%割引クーポンコードがあります。

Stable Diffusionで使う用語を知る
Stable Diffusionの理論や仕組みを知る必要はありませんが、以下の用語については何となくで良いので頭のスミに置いてください。
学習モデル
学習モデルとは、AIが学んだ結果です。人間で言えば、ある程度の年齢になった脳と言えます。
脳は、生まれてから周りの環境(音、言葉、明るさ、景色など)から学習し、言葉を使えるようになり、他人と意思疎通ができるようになります。
Stable Diffusionでは、学習元の画像とキーワードをAIに与え、画像にノイズを乗せ、最終的には元画像が分からなくなるまでノイズを乗せます。学習は、これを逆にたどることで、キーワードとノイズの画像から元画像を推測します。
学習にどんな画像を使ったのかで、同じキーワードからでも違う画像が生成されます。学習モデルを切り替えると鳥山明が尾田栄一郎になるようなものです。
LoRA
LoRA(Low-Rank Adaptation)は、20〜30枚の画像で行った追加学習です。
服装、キャラクター、背景などを学習させ、プロンプトに書き込むことで生成される画像に追加学習のテイストを追加します。
VAE
VAE(Variational Auto Encoder)は、鮮やかさ、鮮明度、塗り具合などが変わります。
VAEも沢山公開されています。
Embedding
Embedding(本来はTextual Inversion)は、同じ意味や近い意味のことばを学習させ、ひとつの観念にしたものです。
低解像度、低品質のような言葉を学習させたEasyNegativeが良く使われます。
ネガティブ・プロンプトに「EasyNegative」と入れることで、低品質な画像が生成されにくくなります。
Extension
拡張機能と呼ばれ、
WebUIの使い勝手を良くしたり
画像の変換(高画質化、背景除去)
ポーズや表情を変える
など、いろいろな機能をもつ拡張機能が公開されています。
必要なアカウントの作成
Stable Diffusionで画像を生成するために必要なアカウントは、
学習モデルなどをダウンロードするためのHugging Face
学習モデルなどをダウンロードするためのCititAI
必要な方のみ:クラウドサービス(Google、Paperspaceなど)
です。
Hugging Face
Hugging Faceは、機械学習アプリケーションを作成するためのツールを開発している米国企業です。ユーザーが機械学習モデルやデータセットを共有するためのプラットフォームを提供しています。
Stable Diffusionの学習モデルなどが共有されています。ダウンロードするためにはアカウントが必要です。
Hugging Faceへアクセスします。右上の「Sign Up」ボタンをクリックします。

メールアドレス、パスワードを入力し「Next」ボタンをクリックします。

ユーザー名、氏名(Full name)を入力し「Create Account」ボタンをクリックします。

Welcome画面が表示されれば完了です。
CivitAIは、Stable Diffusionの学習モデル、LoRAなどを公開、共有できるサイトです。2023年5月27日現在では無料で使えます。
CivitAIへアクセスします。右上にある「Sign In」ボタンをクリックします。

Discord、GitHub、Googleなどのアカウントでサインインできます。

初めての場合には、「Welcome」画面なり規約が表示されますので「Accept」ボタンをクリックします。

CivitAIでのユーザー名を入力します。CivitAI側から提示されているものでよければ変更は必要ありません。「Save」ボタンをクリックします。

ユーザーの設定画面が表示されます。「Mature Content(R13,R18)」のスイッチをONにします。

以下のように問題のある画像は表示されませんが、左上の年齢の橫にある目アイコンをクリックすると表示されます。

学習モデルのダウンロード
インストール前に学習モデル、LoRAをダウンロードしておきます。
学習モデルには、大きくわけると
Stable Diffusion開発元などが作成した汎用のもの
写真のようなリアルさの実写系のもの
アニメ、まんがなどのイラスト系のもの
が、あります。
ネット上には学習モデルのおすすめ記事が沢山あります。また、頻繁にバージョンアップしたり、新しい学習モデルが公開されます。
以下の学習モデル紹介の生成画像は、全て同じプロンプト、シード値で生成しています。簡単なプロンプトだけですので学習モデルによる生成画像の違いが分かると思います。
プロンプト: a beautiful stern woman librarian. adding a book to a bookcase.
ネガティブ: child, bad detail, worst quality, low resolution, watermarks, censored, cat, speech, text, EasyNegative
Sampling: DPM++ 2S a Karras
Seed: 1079197834, 1079197835
私のおすすめは、
実写系
Chilled_remixV2
実写系で人気のあったChilloutMixがライセンスで商用利用ができなくなりました。ライセンス問題をクリアにするために作成されました。
こちらはChilled_remixV2で生成した画像です。

ダウンロード
Hugging Faceからダウンロードします。Chilled_remixのページへアクセスし「Files」タブをクリックします。2つファイルがありますが、違いはこのページに説明があります。

2つファイルがありますが、使う方をダウンロードします。

BRAV5(Beautiful realistic Asians)
アジア系美女を生成できるモデルです。上記のChilled_remixV2と同じプロンプトで生成しました。このモデルも頻繁にアップデートされます。
作者の方はシンガポール人だそうですが日本語も大丈夫とのことです。Discordにコミュニティがあります。また、こちらから作者を応援できます。

ダウンロード
Hugging Faceからダウンロードできます。「ダウンロード」ボタンをクリックします。

アニメ系
Anything系
現在は、基本バージョンが4つあります。
「RE」が付いているものは修正バージョン
「Prt」が付いているものはスリム化したバージョン
こちらは、AnythingV5で生成しました。

ダウンロード
Anything系は、CivitAIからダウンロードします。

CounterfeitV3
こちらも、V3、V2、V2.5と3バージョンがあります。ネガティブプロンプトには、EasyNegativeが推奨です。
CounterfeitV3で生成しました。

ダウンロード
CititAIからダウンロードします。

Pika's New Generation
なんとなくnijijourneyっぽい画像が生成されるので使っています。

ダウンロード
CititAIからダウンロードします。

LoRAのダウンロード
LoRAは、用語説明にあるように追加学習したものです。学習モデル+LoRAで学習モデルの性格が少し変わると考えてよいでしょう。
LoRAは、沢山のものが公開されています。例えば、こちらはAV女優をされていた上原亜衣さんのオフィシャルLoRAです。

これを先ほどのBraV5に追加します。比率は0.7にしています。
プロンプト: a beautiful stern woman librarian. adding a book to a bookcase, lora:v1-1-ai-uehara:0.7
いかがでしょうか?左側と比較すると右側に上原亜衣さんのテイストが入っています。
LoRAは、プロンプト内に複数挿入できますので組合せ(比率も)で生成される画像の変化をお楽しみください。

LoRAの探し方
CivitAIにアクセスし、右上のフィルターアイコンをクリックし、LoRAをクリックします。

あとは、キーワードで検索してください。例えば、グラビアアイドルを探す場合には、「grav」のキーワードで探します。

表示されたものをクリックすると詳細ページが表示します。伏せ字にしてありますが、誰かはスグにわかります。
あまりにも似たものを公開すると問題が発生するかもしれませんので、個人の責任で使用してください。

「idole」で探すと、こんなのがありました。

日本のアダルトビデオを意味する「JAV」で検索すると、こんなのがあります。

衣装やファッションでも検索できます。制服(uniform)で検索すると、こんなのがあります。

VAEのダウンロード
VAE(Variational Auto-Encoder)は、理論の解説は行いませんが、色調を整え生成する画像の品質があがります。
画像サイズを縮小しているため、色の違いが分かりづらいかもしれませんが、左がVAEなし、右がVAEありです。
顔にかかる影の陰影がキレイに出ています。

VAEには、汎用的なものと学習モデルに特化したものとあります。学習モデルに特化したものは、学習モデルのサイトにVAEを指定していますので確認してください。
汎用なものは、以下からダウンロードしてください。
Embedding
Embedding(Textual Inversion)は、同じような意味を持つキーワードと画像を使い、ひとつのキーワードへ集約したように追加学習したものです。
良く使われるのは、ネガティブ系の観念をひとつの単語に集約しています。
Counterfeitの作者さんが公開されている「EasyNegative」ですが、ネガティブ・プロンプト欄に「EasyNegative」と入れるだけで低品質なものが生成されにくくなります。

EasyNegativeは、Counterfeit以外でも使えるが効果は不明と作者さんが言われています。
試して不要であれば、使わなければよいだけです。
ダウンロード
ダウンロードは、Hugging Faceからします。
インストール
必要なものが揃いましたので、Stable DiffusionとWebUIをインストールします。
インストールは、
クラウドサービス(Google Colab、Paperspace)有料です。
Windows(ビデオメモリーが4GB以上)
Mac(M1、M2)
を個別に解説します。お持ちのWindowsのビデオメモリーが不足している場合やIntel Macの場合には、使用料金が発生しますがクラウドサービスを使用してください。
また、Mac(M1、M2)の場合でも一部動かない機能もあります。詳しくは、こちらを参照してください。
また、Macではアップスケールには大変な時間がかかるため、クラウドサービスの併用も検討してください。
クラウドサービス
クラウドサービスは、以下の2つのサービスのどちらかを使います。
Google Colab(100コンピューティングユニット) 1,072円
Paperspace 月額8米ドル
AI絵師養成講座では、インストールに関する質問も受け付けます。また、有料ですがリモートでのインストール代行も承ります。

この先には、AI絵師養成講座の15%割引クーポンコードがあります。

ここから先は
¥ 9,800
この記事が気に入ったらチップで応援してみませんか?