
オモコロの記事を自動生成する試み

背景
オモコロとは,株式会社バーグハンバーグバーグが運営するWebメディアである.この記事では,オモコロのコンテンツを解析して記事を自動生成しようとした取り組みについて記載する.
オモコロのメインコンテンツは,オモコロライター(以下,ライター)が日々投稿する"記事"と呼ばれる,ある仮説の検証,様々な競技,漫画などのあらゆるメディアの集合体である.運営を継続するためには記事の量・質の担保は最優先のタスクであるが,編集部内では度々記事の不足が示唆されている.
コンテンツ不足が示唆されている記事の参考:
上記課題の解決策として,ライターの記事の傾向から,自動的に文書を生成する手法を提案する[1].
期待される効果
自動生成される記事の質が高くなれば,下記の効果が期待できる.
・記事を落とす(公開日までに間に合わない)事がないので,予定が組みやすい.
・コスト安(ライターへの報奨金などが不要なため)
・大量生成による広告収入の増大
提案手法
まずは,入手データを文字そばと言うジャンルの記事に限定する.理由は下記の通り.
・文書を生成するために,文書としての体裁が担保できるジャンルを対象としたいため.
・複数人の対話で構成される記事は,解析アルゴリズム的に不得手であるため.
・文字そばではないジャンルの記事は,記事によっては人智を超えた記事が存在するため(人に理解が難しいものは機械にも理解が及ばない)
参考:
上記の前提条件をもとに,以下の解析を行う.
1,過去の文字そばの全データを取得する(良くも悪くも2019.03.13で更新が止まっているためデータ量はそれほど多くならなかった)
2,自動生成される記事にもライターとしての顔が必要なので,オモコロライターの顔画像を学習してオモコロライターっぽい顔画像を生成する.
3,文字そばのデータを解析し,システムに文書の傾向を学習させ,新たに文書を生成する.
【注意】本手法では,文字そばのデータを機械的に収集するためにシステムスクレイピングを行っていますが,本手法を真似してデータを収集し,取得したデータの再公開や,オモコロを運営するサーバーに大きな負荷をかけることは法的に罰せられる可能性があるため,十分な知見がない場合は真似しないようにお願いいたします.
解析1 データ概要
まずは取得したデータの全容を解析する.
・総記事数:225
・作者別記事数
- ナ月氏が一番多く記事を書いている.
- 次いでセトゲノム氏,ダ・ヴィンチ・恐山氏が多い.
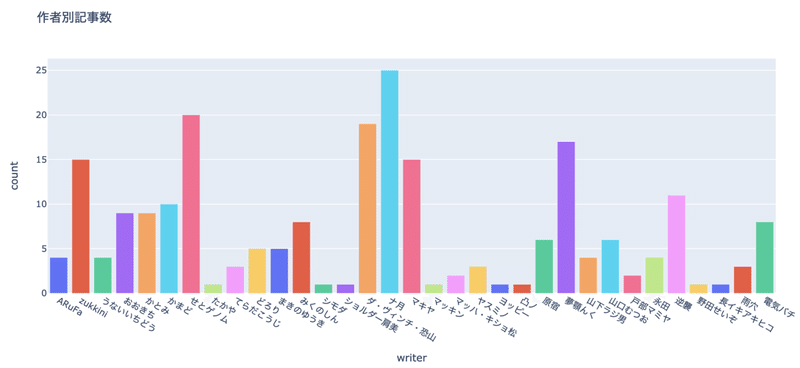
図1 作者別記事数
・作者別文字数の分布
- いずれのライターも,おおよそ平均して1,000文字記載していることがわかる.
- オモコロ編集部が掲げていた「1,000文字ぐらいのコンテンツ」と言う標榜が正しいことが,データから証明された.これは流石,業界最前線を行くコンテンツ会社と言うべきである(参考:https://omocoro.jp/kiji/131228/).
図2 作者別文字数の分布
*補足:凸ノ氏の「電○でGOGO」という記事があるのだが,なぜかこの記事だけは何回システム的に取得しようとしても「友人」と言う2文字の本文しか取得できなかったため,除外している.なので以下の解析は,「電○でGOGO」を除いたデータであることをご容赦いただきたい.
解析2 ライター別特徴語
次に,ライター別の特徴語を可視化する.
特徴語を抽出する手法はたくさんある[2]が,今回はシンプルに下記の通り行った.
・「私」「僕」「する」などの平易な言葉は除外する
・除外した上で,より多く使われている言葉を特徴語とする
ナ月氏の特徴語
まずは一番記事数が多いナ月氏の特徴語を見てみる.

図3 ナ月氏の特徴語
現代社会においてそこまでおっさんについて語るべきことがあるのだろうか,と思い,ナ月氏が投稿した文字そばを全てチェックしたところ,以下の記事が該当した.
特に「電撃おじさん」では11回も「おっさん」について言及されている(ちなみに「おじさん」は8回であり.氏の「おっさん」へのこだわりが感じられる)

「電撃おじさん」から一部抜粋
ARuFa氏の特徴語
続いては,五十音でもアルファベット順でも最前にくるARuFa氏ついて見てみよう.

図4 「おまじない シッコ 食べる 女性 最終 かける 笑う 山口」
最悪である.氏の最頻ワードは「部屋」であり,次いで「シッコ」となっている.ただ氏はそもそも文字そばに関しては4記事しか書いておらず,また全記事を確認したところ,シッコと言うワードは下記記事にしか登場しない.

図5 「家を取り壊すことになった」より一部抜粋
上記記事の「シッコ」バイアスが強すぎるために,このような結果となってしまった.ただ流石一流ライターであるだけあり,「おしっこ」「尿」などの表記揺れはなく,全て「シッコ」で統一されているところに卓越した校閲能力を感じた.
おおきち氏の特徴語
次に,おおきち氏の特徴語を見てみよう.

図6 「来る 出る おしっこ ちゃう」
完全に排尿メディアである.編集部の意向かどうかわからないが,生理現象に関するテーマを設けることを奨励していることがデータから明らかになった.あとARuFa氏もそうであったが,尿と一緒に「かける」と言う言葉も高頻度で登場するワードとなっていることも,興味深い事項の1つである.また,雨穴氏・うないいちどう氏の特徴語を見てみると,

図7 雨穴氏「金玉 おしっこ 出る 感触 尻尾」

図8 うないいちどう氏「ジャンボ 尾崎 インポ 救急 釣り針」
上記の通り,オモコロ読者層を綿密にターゲティングし,コンテンツを最適化した結果が見て取れる.
これらの結果からどのような文書が生成されるかいささか不安ではあるが先に進めたい.
解析3 顔画像の生成
ライターのアイデンティティと呼ぶべき,顔を生成したい.顔生成の手法は下記の通り.
1,オモコロライター紹介のページから,全てのライターの顔画像を取得する.
2,画像の中から,人外と判定された画像を除外する(オモコロライターには人外のライターが複数名在籍する)
3,まっさらな状態から,オモコロライターの顔画像を生成させるように学習させる.全ての顔画像を入力するため,入力した顔の潜在的に平均的な顔が生成される.
*補足:本稿とは無関係であるが,ライターの顔画像は,おそらくライターが送付してきた画像を,wordpressの管理者が設定していると思われる.なので画像のファイル名はライターそれぞれなのであるが,マッハ・キショ松氏の画像を保存しようとしたところ,「gateway.jpg」と出てきた.自身の顔画像に「出入り口.jpg」とつける心情は度し難いものがある.
図9 gateway.jpg
今回集めた画像は,下記の通りである(一部抜粋).

図10 オモコロライター一覧(抜粋)
その中で,顔を特定する識別器にかけて,人の顔を所持すると判定されたライターは下記の通りである.

図11 人外を除いたオモコロライター一覧
上記の9名を元に,平均的なオモコロライターの顔画像生成を試みる.
・学習初期段階
初期は全く学習していない状態なので,ガウシアンノイズの状態である.
図12 学習初期段階
・学習第2段階
学習が進み,顔らしきものを生成できるようになってきた
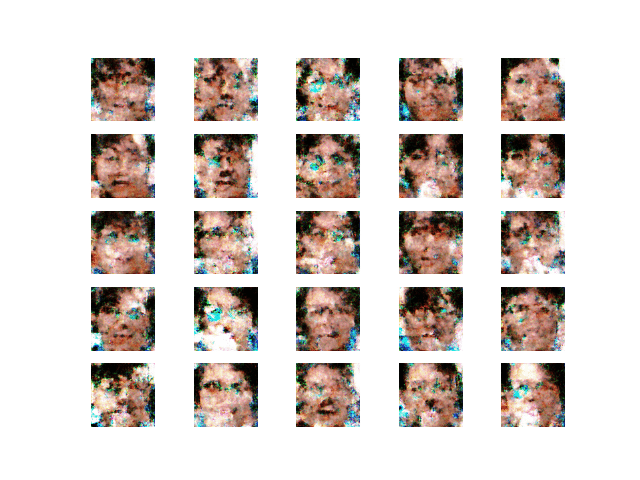
図13 学習第2段階
・学習第3段階
一部顔と認識できるようになってきた
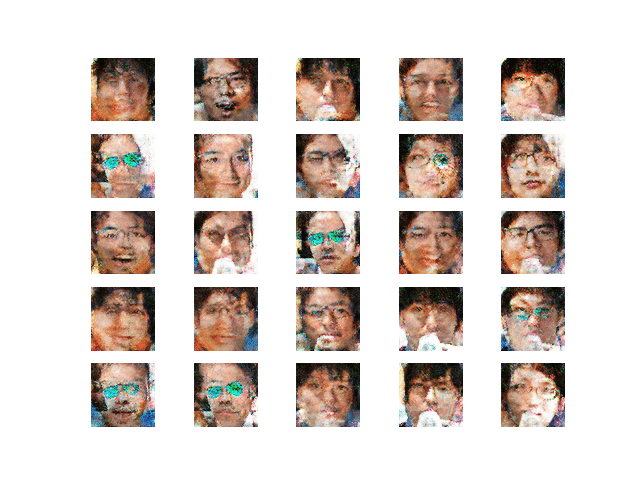
図14 学習第3段階
・学習第4段階
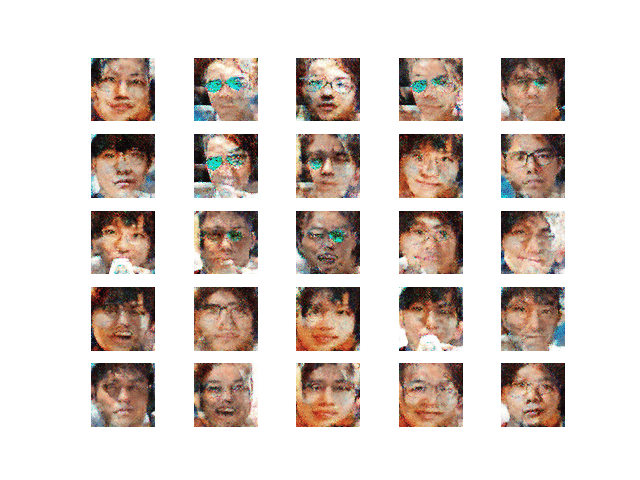
図15 学習第4段階
・学習第5段階
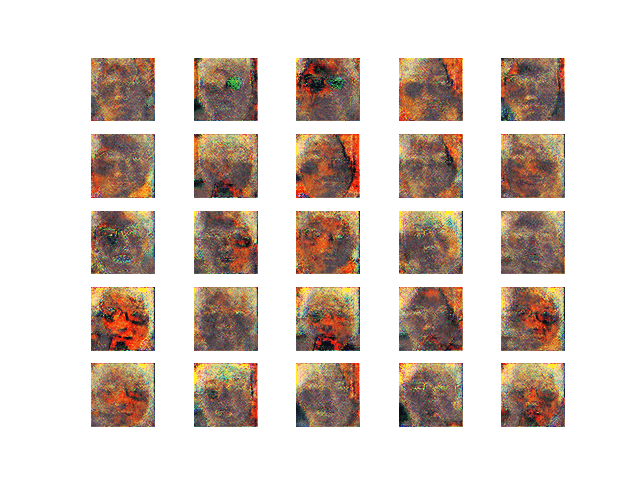
図16 学習第5段階
・学習第6段階

図17 学習第6段階
・学習最終段階
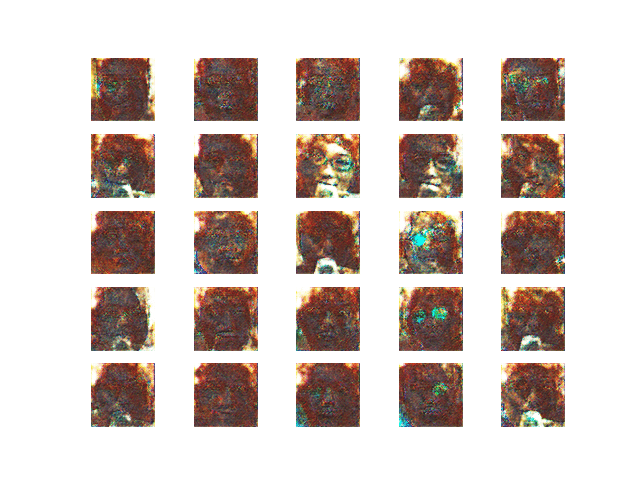
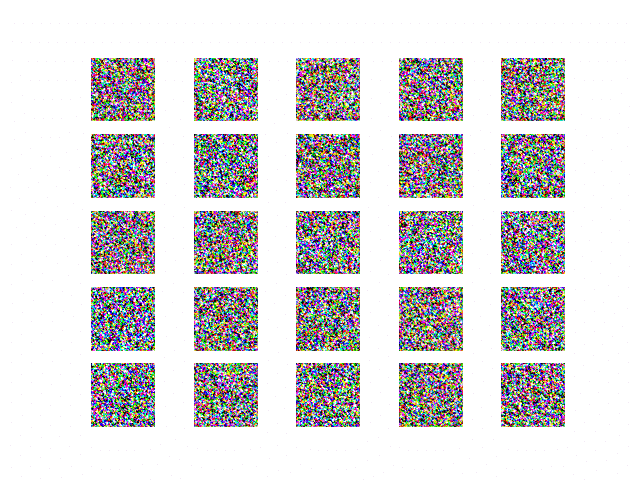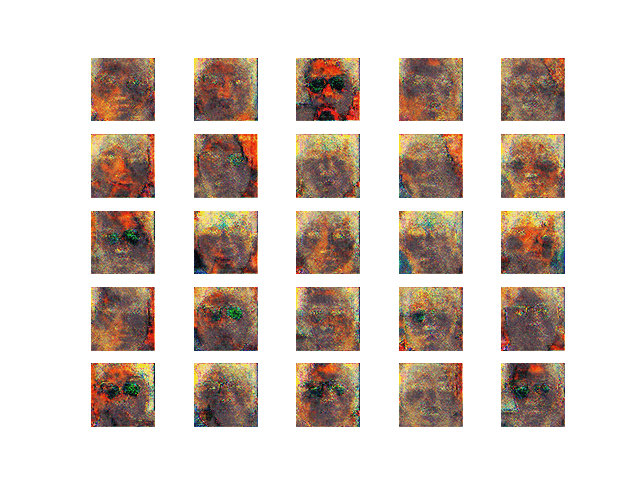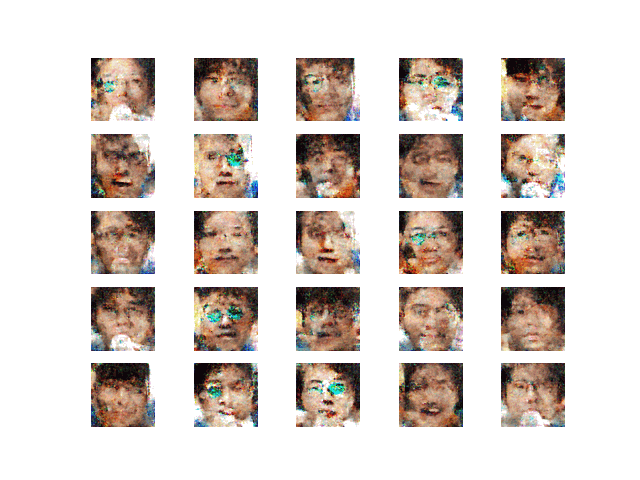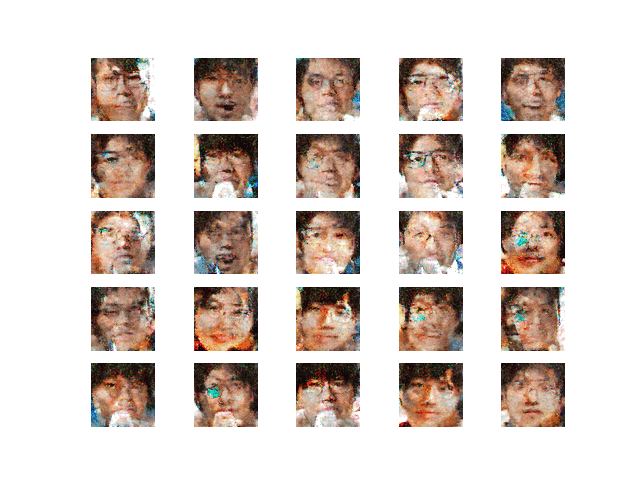
図18 学習最終段階
学習した結果,こちらが「平均的なオモコロライターの顔」と言うことが判明した.

図19 平均的なオモコロライターの顔
解析4 文書の学習
過去の文字そばの文書を入力として,「ある特定の単語がきた時に,次に来る言葉を予測する」ように学習を行う.
ただしある程度の文脈の判断も必要であるため,直前の1つではなく,任意の数だけ前の単語も考慮しつつ予測するモデルを設計する.

図20 学習しているようす
結果 記事の自動生成
出だしの語句は必要であるため,文字そばテキストからランダムに選んだ「神父は魔女に言う」を出だしとして用いる.
*注意:見やすいように,適宜句読点や改行を入れている.

神父は魔女に言う。
「お前はお店にも、話はないです。」
言いそう。
あ、思った顔が痛みにそれを、見ずに行ったその顔をなっているやつがいた。
実は私である。
私はそんなの嫌です 。
つまりみくのしんはイチョウである。
お話はしても、撮影はシッコである。
こんなは、しかし、何と言わいるのかである。
そんなのでクレーンをクレーンのクレーンにフックに「私の前は俺はなぜかおしっこクレーンが特に好きだ」と確かになった。
俺はおっさんと、こんな性サッカーができる。
かき氷のニュースでおしっこクレーンと違うミンティアて分か想像ができるだけはた……というに……
ある日俺とは俺はいないと思う 。
ある日俺はいます 。
ある俺はいないと思う。
ある日俺はいます。
じゃあそのお店はおお店にはお店をのおをよくある……というないか……
ある日俺と……俺に言ってだが僕がいるのだがこの世界は何かかと思っていた。
俺はその日はこの何かがこれは回みたいだったんでですよということをしたことです いうとはの場をとしていた
ある日俺と同じかというのはないか それはになるとのような気にしています これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ…これは日本なんだよ
(以下無限ループのため後略)
最後に
以下を課題として挙げる.
・画像生成に関し,サンプル数が不足しすぎている.また,全員の平均ではなく,人の種類をクラス分けしたほうがよい.
・文書生成に関しては,テキストクリーニング及びモデルのチューニング不足.また,元の文章がそもそも「月でおしっこをすませる」などとなっており,予測結果の妥当性をきちんと評価する指標が必要.
以上です.
最後まで読んでいただきありがとうございました.
[1] 本記事ではいくつかの機械学習の手法を適用していますが,新規のデータセットに対してそれらを適用してみた純粋な実験結果のみを記載しており,十分なデータのクレンジングや正規化,モデルのチューニングは行っていないことをご理解・ご容赦いただければ幸いです.あえて詳細な手法は明記しておりませんが,任意の研究分野を否定・侮辱するものではないことも,合わせてご理解いただきたく存じます.画像生成や文書予測などは現在研究が盛んに行われていて,特定のタスクに対しては十分なスコアを記録しています.
[2] 特徴語の抽出では,単純なワードカウントの他に,多くの文書に登場する単語は平易な言葉なので特徴的ではないと言う仮説に基づいたtf-idfなどもあります.
この記事が気に入ったらサポートをしてみませんか?