
未経験39歳が機械部品を判別するAIをつくってみた

はじめに
私は転職のためにAIを勉強しました。年齢は39歳でギリ30代のガケっぷちです。しかもプログラミングなどこれまでやったことがありません。そんな自分が「AIを勉強してAIなんて難しそうなものが作れるのか?」がテーマです。(それより転職に成功するか?が最大のテーマかもしれません)
現在の職業
現在は某中小企業メーカーで機械系エンジニアとして働いています。新卒からこれまでずっとこの会社で勤めてきました。職種は生産技術と呼ばれる工場などの生産に関わる技術職です。
そんな自分がAIに興味を持ったのは「会社の生産性を上げたい」という思いからでした。
中小企業の問題
中小企業は人手が足りていません。にも関わらず、募集しても人はなかなか来ません。ベテランの人は定年でどんどん退職していきます。技術の伝承も思うように進んでいません。
生産性を上げるために設備導入をしようにも、導入には人手が必要です。しかし、人手は日々の生産に回ってしまいます。日々の生産ができなければ、設備導入資金も用意できません。もう悪循環です。
そういった背景から、AIを使って省力化や自動化を実現させ「生産性を上げたいなぁ」と思うようになりました。
なぜAI?
AIによる画像認識は、従来のセンサーを使った方法より低コストで実現できます。これまでのセンサーなどの方法では、仕組みが大がかりで複雑になりがちです。その結果、導入コストが高くなってしまいます。その反面、AIを使った方法は簡素化が容易です。例えば検査工程などは、AIで判定するカメラを設置するだけで、自動化が実現できます。
また、深層学習の進歩によってこれまで機械ではできなかった仕事が代替えできるようになりました。人でしかできなかった作業を機械にやってもらえば、それだけ生産性が上がります。
中小企業の抱える人手不足の問題を解決するには、生産性向上が1つの答えです。AIを使えばさまざまな作業で生産性向上が期待できます。
こうしたAIによる生産性向上を実現するには、AIを扱える人材が必要です。しかし、AI人材はまだまだ不足しています。そこで自分がAIを勉強し、AIビジネスを展開している企業へ転職し、企業の抱える問題を解決していくAI人材になるのが最善だと考えました。
つくったAIってどんなもの?
部品を判別するAI、それをアプリに
部品の画像を送れば、AIがなんの部品かを判別してくれます。そしてこのAIを使ったアプリを製作します。アプリはあまり機械部品の知識がない方でも、画像を送るだけで部品の選定ができる支援アプリです。
なぜ作ったのか?
製造業において、製造工程の設備のメンテナンスにはすごく気を使います。設備に不具合が出ると不良品を作ってしまうだけでなく、工程が止まってしまうからです。この損失コストは、生産したものを売って利益を出す製造業にとって、かなり痛いコストです。
設備のメンテナンスは、調整や部品交換が主です。しかし、現場の方だけでは部品の選定が困難な場合があります。
交換部品の選定は機械の知識やノウハウといったものが必要で、経験がないと難しいものです。その難しい部分を「サポートするAIをつくり、現場の方でも部品選定がスムーズにできないか?」と考えました。
判別する部品は?
AIの画像認識を使って、送られた画像から「なんの部品か」を判別します。
判別する部品は「ベアリング」「スプロケット」「六角ナット」です。

なぜこの3つの部品を選んだかというと(しっかり理由があります。適当ではありませんよ?)
一般的な部品で画像がたくさんある
機械関係でよく使用される部品である
比較的形状が似ており判別できるか興味があった
からです。
その部品ってどういうもの?
「その部品ってなに?聞いたことない」という人のためにざっくり説明します。
ベアリング
ベアリングは軸受けとも呼ばれ、軸を滑らかに回転させるための部品です。扇風機の中心部や、自転車のホイール回転部に使われています。
工場設備では、モーターから駆動力を伝える部分によく使われています。
スプロケット
スプロケットは、チェーンによって駆動力を伝えるための部品です。自転車ではペダルやホイールの中心にあるギザギザしたヤツです。
工場設備では、ベルトコンベアなどの駆動力を伝える部分によく使われています。
六角ナット
六角ナットは、機械には絶対というほど使用されている部品です。ボルトとセットで使用し、ボルトを固定するために使われます。身近なところだと、大抵どこでも使われていますが、標識や看板を固定していたりするかも?
工場設備では、部品を固定する所などだいたいどこでも使われています。
なんで3つなの?
3つという数にしたのは自分が持っている環境などのリソースで、うまく機能するものを実現するには、この辺りがちょうど良いと考えたからです。
AIで3つ以上を分類することを「多クラス分類」と呼びます。多クラス分類は一般の個人が持てる環境だと、5つくらいが限界という話を聞きました。
限界となる理由は、AIに1つのクラスを学習させるのに、膨大な量のデータが必要になること。また、その膨大な量のデータをAIに学習させる必要があることなどがあります。これらを実行するには、マシンスペックや投下する時間などがないと難しいです。
もちろん5つ以上から判別するAIを作っている方もいますが、やはりかなり難しいようです。私は3つでも5つでもやることはほぼ変わらないこと、自分が実現できそうな量などから、今回3つが良い判断しました。
AIアプリはどうやって製作したか
製作工程と実行環境
アプリをつくるまでの製作工程は
スクレイピング:機械学習をさせるための画像を集める
データクレンジング:集めた画像を学習に最適になるよう加工する
学習モデル構築:学習モデルをつくり、機械に学習させる
テストと評価:モデルをテストし、実際に使えるかを評価する
アプリをデプロイ:アプリの見た目や動作ををつくり、Herokuへデプロイ(公開)する
です。
実行環境は
1.スクレイピング~2.データクレンジング:jupyter lab
3.学習モデル構築~4.テストと評価:google colaboratory
5.アプリをデプロイ:Visual Studio Code
で作業しました。
各製作工程の詳しい内容
1.スクレイピング
「機械学習をさせるための画像を集める」工程です。
jupyter labを使って作業します。グーグル検索から検索した画像をスクレイピングしていきます。
まずはBeautiful Soup 4で
当初はライブラリ「Beautiful Soup 4」を使ってやりました。しかし、取得できる画像が1枚だけでうまくいきませんでした。画像が掲載されているサイトから画像を取得しても1度に数枚しかできません。機械学習にはたくさんのデータが必要なので、これでは時間がかかってしまいます。別の方法を考えます。
seleniumを使う方法に変更
ネットで方法を調べていると、seleniumを使ってグーグル検索の画像をスクレイピングする方法が紹介されてました。さらに調べていると「まさに自分がやろうとしていること」にピッタリなコードを公開してくれている方がいました。
以下のサイトを参考にさせて頂きました。
これで学習に必要なデータを集められました。
この工程でつまずいた所
seleniumを使ってWebドライバーを動かし、画像を取得しようとしました。しかし、seleniumをインストールしたはずなのにインポートできませんでした。
調べてみると以下のサイトで原因がわかりました。
どうやらPythonが2つインストールされていたのが原因のようでした。
私は、Anacondaと単独のPythonを2つインストールしていました。このAnacondaのPythonと単体のPythonが2つあることで、seleniumは単体のPythonを優先してしまい動作しなかったようです。単体のPythonを削除するとインポート可能になりました。
2.データクレンジング
「集めた画像を学習に最適になるよう加工する」工程です。
不要な画像を削除したり、トリミングしたりします。
あきらかに関係のない画像は迷わず削除しました。また、関係のないものが写り込んでいるものは、トリミングしました。
トリミングするコード
pillowで読み込み、cv2に変換しています。
はじめはcv2を使ってトリミングする予定でした。ところがcv2は日本語表記のファイルは読めないと分かりました。しかしここは勉強のためにpillowで読み込み、cv2へ変換する方法をやってみることにしました(決して変更するのがメンドクサイからではありませんよ?)。
# 必要なライブラリをインポート
import cv2
import numpy as np
from PIL import Image元画像の大きさをshapeで確認しておきます。縦横比率を確認するのと、おおよそどこを切り抜けばいいか検討をつけるためです。
# Pillowで画像ファイルを開く
path = r"path.jpg" # 頭にrを。pathは画像の絶対パスを入れてください
pil_img = Image.open(path)
# PillowからNumPyへ変換
img = np.array(pil_img)
# カラー画像のときは、RGBからBGRへ変換する
if img.ndim == 3:
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
cv2.imshow("Image", img)
cv2.waitKey(0)
img.shape #画像のサイズを確認する 切り抜きを行います。数字を指定して、画像を表示し切り抜いた結果を確認します。私は手計算で縦横の比率が同じになるようにやりました。
img1 = img[0 : 120, 50 : 170] # 切り抜く場所を指定します
img1 = cv2.resize(img1, (225, 225))
cv2.imshow("Image", img1)
cv2.waitKey(0)
img1.shape上書き保存するのにも、cv2は日本語表記で保存できません。なので再度pillowへ変換します。
if img1.ndim == 3:
img1 = cv2.cvtColor(img1, cv2.COLOR_RGB2BGR) #再度色を反転させる
pil_img = Image.fromarray(img1) #pil_img .show()
pil_img.save(path)この工程でつまずいた所
opencvがインポートできませんでした。調べていると以下のサイトで解決しました。
また、すでに述べていますが、cv2は日本語表記でファイルを読み書きできません。これもわかるまで時間がかかりました。以下のサイトで原因がわかりました。
ファイル名を英語表記にrenameする
日本語表記ではあとあと面倒なことになるので、ここは素直に英語表記のファイル名へ変更します。自分のように特別な理由がない限り、はじめから英語表記のファイルを扱うことをお勧めします。
Pythonを使えば、あっという間に名前を一括で変更できます。
import os
import glob
# 画像のpathを指定する。最初にrをつけないと認識してくれません。
path = r"path"
i = 1
# jpgファイルを取得する
flist = glob.glob(path + '/*')
print('変更前')
print(flist[:5]) # 確認のため5個を表示する# ファイル名を一括で変更する
for file in flist:
os.rename(file, r'変更する名前/_' + '{0:03d}'.format(i) + '.jpg') # 名前_001.jpgに変更します
i+=1
list = glob.glob(path + '/*')
print('変更後')
print(list[:5]) # 確認のため変更後の名前を5個を表示する3.学習モデル構築
「学習モデルをつくり、機械に学習させる」工程です。
ここからはcolaboratoryで作業します。
今回はTensorFlowを使いVGG16から転移学習をします。
TensorFlowや転移学習とは?
TensorFlowはグーグルが出しているライブラリで、画像認識などのディープラーニングを行うものです。VGG16は画像認識で様々なものを分類するために開発されたものです。その学習済みデータが利用できるように公開されています。
今回はVGG16の学習済みデータに、新たに自分のデータを連結し学習させます。これを転移学習と呼び、少ないリソースで精度の良い学習モデルを作ることができます。
学習モデルをつくって学習させる
まず、集めたデータをグーグルドライブのマイドライブへアップロードします。それから、colaboratory上でマイドライブをマウントします。これでcolaboratoryからマイドライブのマイフォルダが参照できるようになります。
以下参考サイトです。
では学習モデルをつくっていきます。
必要なライブラリをインポートします。
# ライブラリをインポート
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from keras.utils.np_utils import to_categorical
from keras.layers import Dense, Dropout, Flatten, Input
from keras.applications.vgg16 import VGG16
from keras.models import Model, Sequential
from tensorflow.keras import optimizers機械学習に必要な画像を読み込み、リストに入れます。
# 画像のパスをリストにします
path_bea = os.listdir('/content/drive/MyDrive/my_product/bearing')
path_spr = os.listdir('/content/drive/MyDrive/my_product/sprocket')
path_nut = os.listdir('/content/drive/MyDrive/my_product/hexagon_nut')
path_test = os.listdir('/content/drive/MyDrive/my_product/test_img')
# 空のリストを用意します
img_bea = []
img_spr = []
img_nut = []
# for文で繰り返し処理をします。画像のパスから画像を読み込み、サイズを変更し、リストに格納します
for i in range(len(path_bea)):
img = cv2.imread('/content/drive/MyDrive/my_product/bearing/' + path_bea[i]) #Noneになってしまう 。うまく参照できていない。最期の/が足りなかった
img = cv2.resize(img, (150,150))
img_bea.append(img)
for i in range(len(path_spr)):
img = cv2.imread('/content/drive/MyDrive/my_product/sprocket/' + path_spr[i])
img = cv2.resize(img, (150,150))
img_spr.append(img)
for i in range(len(path_nut)):
img = cv2.imread('/content/drive/MyDrive/my_product/hexagon_nut/' + path_nut[i])
img = cv2.resize(img, (150,150))
img_nut.append(img)画像を数列に置き換え、学習用データとテスト用データに分けます。
集めたデータはすべて学習に使わず、精度を確認するためテスト用データに分けます。今回は学習用80%、テスト用20%に分けました。
# 画像を数列に変換します。部品名を数字にします。
X = np.array(img_bea + img_spr + img_nut)
y = np.array([0]*len(img_bea) + [1]*len(img_spr) + [2]*len(img_nut))
# 精度向上のため、数列を乱数によって並び替えます #np .random.seed(0) #パラメータ調整するときは乱数を固定すると比較できます
rand_index = np.random.permutation(np.arange(len(X))) #等差数列を生成し 、数列の要素をランダムに並べ替える。
X = X[rand_index]
y = y[rand_index]
# データの分割
X_train = X[:int(len(X)*0.8)] # 0.8までを学習データにします。
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):] # 0.8の残り0.2をテストデータにします。
y_test = y[int(len(y)*0.8):]
# 正解ラベルをone-hot(正解が1、それ以外が0)の形にします
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)転移学習と学習モデルをつくります。
# モデルにvggを使います
input_tensor = Input(shape=(150, 150, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vggのoutputを受け取り、3クラス分類する層を定義します
# 以下のように中間層をつくり精度を上げます
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.1))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dropout(0.2))
top_model.add(Dense(64, activation='relu'))
top_model.add(Dropout(0.2))
top_model.add(Dense(3, activation='softmax'))
# vggと、top_modelを連結します
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vggの層の重みを変更不能にします
for layer in model.layers[:11]:
layer.trainable = False
# コンパイルします
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])作った学習モデルにデータを渡し学習させます。
# 学習を行います
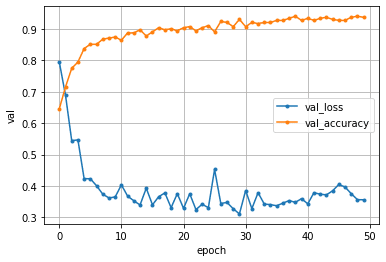
history = model.fit(X_train, y_train, batch_size=100, epochs=50, validation_data=(X_test, y_test))テストデータの正解率(Val_accuracy)と損失値(Val_loss)をグラフにします。
正解率:機械が判断したものが、どれだけ正解していたか
損失値:正解値と機械が判断した値とのズレ
%matplotlib inline
val_loss = history.history['val_loss']
val_accuracy = history.history['val_accuracy']
epochs=len(val_accuracy)
plt.plot(range(epochs), val_loss, marker = '.', label = 'val_loss')
plt.plot(range(epochs), val_accuracy, marker = '.', label = 'val_accuracy')
plt.legend(loc = 'best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('val')
plt.show()最初につくった学習モデルでの結果は、テストデータの正解率(Val_accuracy)で0.850でした。ここから精度を上げるために、パラメータ調整をします。
パラメータ調整について
パラメータは正式にはハイパーパラメータと呼びます。このハイバーパラメータを調整することをチューニングと呼びます。機械学習では学習を最適化するため、パラメータ調整をすることが重要になってきます。これをしないと、精度が上がらず実用に耐えられません。
今回主に調整したパラメータを下の表にまとめます。また、各パラメータとその簡単な説明を表にまとめます(説明は正確ではないかも)。

パラメータ調整した結果
パラメータ調整で判明したことを以下に述べます。
学習回数(epoch)は50回でほどで頭打ちになる
バッチサイズは変更しても大きな変化はないので100にする
中間層を2層(256→3)から3層(256→128→3)にすると精度が上がった。しかし4層(256→128→64→3)にしても精度は向上するものの変化が少ない。なので4層にする
画像サイズを上げると精度が向上した。50→100→150とサイズを上げると精度が向上。150→200は大きな変化はなく時間もかかるので150にする
モデルレイヤーは15が精度が高い
ドロップアウトは変更しても変化が少ないが(0.1-0.2-0.2)が比較的精度が高かった
以上のパラメータ調整で正解率は0.921ほどまで上がりました。
画像を少し整理してみる
「もう少し上げられるかも?」と思い、画像データを整理します。残っている悪影響がありそうなイラストなどの画像を数枚削除しました。
再度学習させると正解率は0.850(正確な数値は覚えていません)と下がってしまいました。
「数枚程度のデータ整理で精度がこんなに下がるとは!?」と、驚きました。「なにが学習の結果に影響しているのか?」の把握が難しいという良い勉強になります。
再度パラメータを調整します。以下判明したことを述べます。
学習回数(epoch)は50回でほどで頭打ちになることは変わらない
モデルレイヤーは11が精度が高くなった
ドロップアウトはやはり(0.1-0.2-0.2)が精度が高かった
他の値についても、変更しても変わらないか、精度が落ちる結果になった
このパラメータ調整の結果、正解率0.937と出ました。

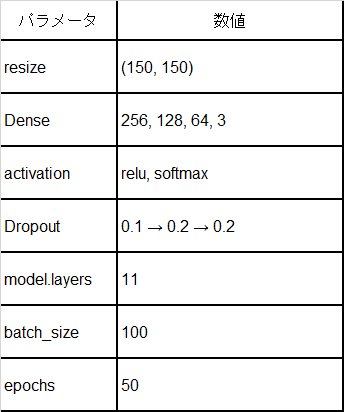
最終的な調整後のパラメータ数値を表にまとめます。
白黒画像を加えて学習させてみた
さらに精度が上がるかを試してみるため、画像を白黒に加工してデータ数を増やします。こうしてデータ数を水増しし、学習させます。
例えば、下の画像を

下の画像のように白黒にします。

このようにして画像を水増しすることで、学習するデータが増えます。データが増えると精度が上がることがあります。
AIはなにかを学習するとき、膨大なデータが必要になります。その学習に使うデータを水増しするのに白黒画像などがよく使われます。
白黒にするコード
白黒には閾値の調整が必要です。まずは画像を加工して「どんな具合か」を確認します。
import os
import cv2
from matplotlib import pyplot as plt
# 画像の読み込み
img = cv2.imread('/content/drive/MyDrive/path.jpg')
# グレイスケールに変換
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.gray() # pltではグレーに表示されないので、このコードを入れる
plt.imshow(img_gray)
# 白黒化する。閾値の調整がいるのでここで確認する
retval, img_binary = cv2.threshold(img_gray,160, 255, cv2.THRESH_BINARY)
plt.imshow(img_binary)閾値の数値が良ければ以下のコードで一括変換します。
path_a = os.listdir('/content/drive/MyDrive/path') # pathは目的のパスを記述
for i in range(len(path_a)):
img = cv2.imread('/content/drive/MyDrive/path/' + path_a[i])
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
retval, img_binary = cv2.threshold(img_gray,160, 255, cv2.THRESH_BINARY)
cv2.imwrite('/content/drive/MyDrive/保存したいpath/' + str(i) + '.jpg', img_binary)自動で閾値を調整してくれるものも
調べていると「大津の二値化」と呼ばれる、閾値の調整を自動でやってくれるものがありました。今回は自分で閾値を決めましたが、機会があれば試してみたいです。
以下のサイトが参考になります。
学習結果
白黒画像を加えて学習してみたところ、精度は下がりました。パラメータ調整しても、最終的な精度は0.831と水増し前より伸びませんでした。
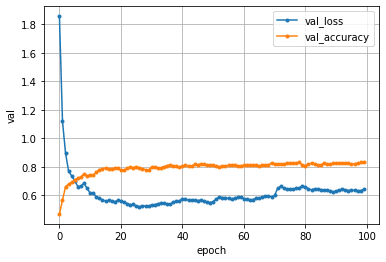
以下パラメータ調整で判明したこと
学習回数は100回で頭打ちになる(微妙に上がっているのかも)
中間層は5層(256→128→64→32→3)にしたら少し向上した
ドロップアウトは0.2だと精度が高い(でも大した違いはない)
画像サイズは200にしても変化しない
モデルレイヤーは18が最高値。19だと下がる
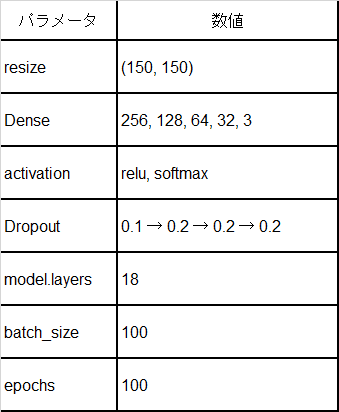
最終的な調整後のパラメータ数値をまとめます。
水増しデータによる学習の傾向や精度が伸びなかった理由の考察
水増しデータによる学習によって分かった傾向や推察を述べます。
今回の水増しによりデータ数を増やすことで、頭打ちになる学習回数が増えるという傾向が見られました。また、精度の向上に関しデータ数が増えるほど中間層が増え、VGG16のモデルレイヤー層が増える傾向がありました。
これらはデータが増えることにより、以前に比べ複雑な特徴を学習する必要があるため、結合層や学習回数が増える傾向があるのではと推察します。
白黒画像で水増ししても精度が向上しなかった理由について考察します。
理由として、今回選んだ機械部品が比較的単純なものだったことが上げられます。
部品はもともと単純であり、用意したデータだけで十分な学習できていたと考えられます。しかし、白黒化した画像を加えることで、データ数を増やしより複雑にしてしまい、むしろ逆効果だったと推察します。
また、白黒の画像が精度を向上させるほど品質の良いものではなかった可能性が考えられます。
今回、白黒化において閾値を一つの数値で一括変換しました。このことでそれぞれの画像に最適化されたものに加工できていませんでした(白すぎるものや黒すぎるものがあった)。このことが影響し、精度があまり上がらなかったと推察します。
改善策として、大津の二値化などを使い白黒画像の最適化させると、精度が向上するかもしれません。
学習モデルの結論
これまでの結果から以下のことが言えます。
正解率が0.937と精度が出ている。これ以上精度を上げても過学習になる懸念がある。
さらに精度上げるなら、データを整理したり、白黒画像の閾値を調整したりする必要がある。しかし、すでに精度が出ているため、これ以上精度を上げる必要はないと考える。
以上のことから、学習モデルは精度が高かったモデル(下表のmodel_2)を採用します。

もっと精度を上げるには?
もっと精度を上げる方法に、VGG16より良いモデルを使う方法があると知りました。例えばXceptionなどがあるようです。
また、実戦現場では1つのモデルだけで精度を上げることはあまりしないそうです。これは過学習のリスクを下げるためで、1つのモデルで良い精度が出ても、安易にそれを採用とはしないそうです。
例えば、VGG16で良い結果が出ても、他のモデル(SVCやランダムフォレストなど)を使い、同じ意見を出すか確認してみるそうです。それで多数決を取り「多い意見だから良いモデルの可能性が高い」と判断するそうです。
実戦現場ではいろいろなことを考えているのだなぁと感心してしまいます。
この工程でつまずいた所
最も苦労し、つまづいた点はパラメータ調整の管理でした。どのパラメータをいくつの数値にして、その結果はどうだったかを管理することが一番大変でした。やっていると「何がどうだったか」が整理できず、訳がわからなくなります。
私は始め、直接コメントアウトでメモしてやっていました。
以下メモの参考(内容は自分にしかわからないと思いますが)。
#epochsはだいたい50で頭打ち 。sizeは150が良い、200にしても変わらない。batchは変化が少ないが100が良い。 #結合層は3層 、4層にしても変わらない。layer(256-128-3)。dropoutは(0.2-0.5)。layersは15が良い。 #画像を整理したら精度が落ちた 。layer(256-128-64-3)。dropoutは(0.1-0.2-0.2)。layersは10が良い。
#size (150, 150)
#4layer (256-128-64-3)
#layers15 =0.907->17=0.904 20=0.317 10=0.927 5=0.917 8=0.943
#dropout (0.1-0.2-0.3)->( - -0.5)=0.930 ( - -0.4)=0.864 ( - -0.2)=0.950 ( - -0.1)=0.933
#(0.1-0.2-0.2)->(0.2- - )=0.87 (0.3- - )=0.938
#layers10 =0.940/0.913 8=0.933 9=0.927 11=0.950/0.927 12=0.953/0.920 15=0.920 13=0.920colaboratoryだと、別セルに文字やテキストでメモできます。こっちの方がやりやすいかもしれません。
Pandasを使ってCSVに記録する人もいるようです。
以下その際の参考サイト。
プロのエンジニアはどうしてるのか
プロの方に「パラメータの管理はどうていますか?」を聞きました。するとその方は「クラウドを使って管理している」と回答を頂きました。やはり仕事となると、管理に手間と時間をかけるようなことはせず、良いサービスやツールを使って「集中するべき所に集中する」のが効率的なのだなと思いました。
また、アドバイスとして「Optuna」というパラメータを自動調整してくれるものがあると教えて頂きました。プロとの知識量の差を感じる所です。
グリッドサーチやランダムサーチと同じように、パラメータを自動で調整してくれるとのことでした。これも機会があればやってみたいと思います。
4.テストと評価
「モデルをテストし、実際に使えるかを評価する」工程です。
現物の画像を準備し、AIに判別してもらいます。
学習済みモデル(AI)のテスト
現物の「ベアリング」「スプロケット」「六角ナット」を準備し、画像を撮影します(自分の職業上、部品は簡単に準備できました)。角度を変えて撮影し、各部品の画像を10枚用意しました。
学習済みモデル(AI)をテストします。用意した現物の部品画像をAIに分類させます。
下のコードで行いました。
# 画像を一枚受け取り、部品の種類を判定する関数
def pred_parts(img):
img = cv2.resize(img, (150, 150))
pred = np.argmax(model.predict(np.array([img])))
#0 ,1,2でif文をつくる
if pred == 0:
return 'bearing'
elif pred == 1:
return 'sprocket'
else:
return 'hexagon_nut'
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# pred_parts関数に画像を渡して部品を予測します
for i in range(len(path_test)):
# pred_parts関数に部品画像を渡して部品名を予測します
img = cv2.imread('/content/drive/MyDrive/my_product/test_img/' + path_test[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
plt.imshow(img)
plt.show()
print(pred_parts(img))結果は
ベアリング:正解数(9/10)1個失敗
スプロケット:正解数(9/10)1個失敗
六角ナット:正解数(10/10)全部正解
という結果でした。正解率でいうとベアリング90%、スプロケット90%、六角ナット100%でした。全体では93.3%の正解率になります。
評価
感想としては「思った以上に判別しているな」でした。比較的似た部品を選んでいたので「AIはしっかり判別している」と感心しました。でも失敗もしています。
判別を失敗した画像は

というものでした。2つとも部品を真横から撮影している画像でした。
六角ナットは真横から撮影している画像でも

と、しっかり判別できていました。
もし、実際にこの学習モデルを使用するには、真横の画像も判別できないと、実使用できないと思います。「真横の画像は間違えるので使わないでください」とは言えないですからね。
差が出た理由の考察
この差は次のことが考えられます。
学習に使用した画像を見てみると、ベアリングとスプロケットは真横からの形状を表したものがありませんでした。一方、六角ナットは真横から表した画像がありました。
今回、グーグル検索から画像を入手しました。検索した画像は商品を紹介するものが多く、真横から撮影した画像はありませんでした。もしかすると、ベアリングとスプロケットに真横からの画像を加えるとうまく判別するようになるかもしれません。
もう一つの仮説は、テストで使用した画像は六角ナットと認識してしまうものである可能性です。画像をよく見ると、ベアリングの曲面部の明暗の具合は六角ナットに見えなくもありません。スプロケットも歯車部が六角の角に見えなくもないと思います。
これも改善するなら、真横からの画像を加え学習させると精度が上がるかもしれません。
人間は、見たことがないものでも推定して判断できます。機械はデータがなければ判断できません。「何がどの程度結果に影響しているのか?」は人間が考えて調整していくしかないようです。画像認識は奥が深いと感じました。
今回は真横の画像が入手できないことから、このモデルでのデプロイをすることにします。
この工程でつまずいた所
ここでは「真横の画像がうまくいかない」以外はありませんでした。部品も会社の遊休品から簡単に見つかりました。強いてあげるなら、部品を何枚もスマホで撮っているところを見られないか心配だったことです。「あいつは何で部品をスマホで何枚も撮っているんだ?あぶないヤツ」と思われるんじゃないかと、内心は穏やかではありませんでした。
5.アプリをデプロイ
「アプリの見た目や動作ををつくり、Herokuへ公開する」工程です。
HTMLで見た目をつくり、Flaskを使って動作するアプリをつくります。そしてHerokuへデプロイ(公開)し、みなさんに使ってもらえるようにします。
学習して覚えた重みを保存します。
from google.colab import files
#resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save(os.path.join(result_dir, 'model.h5'))
files.download( '/content/results/model.h5' ) 私の場合、なぜかダウンロードされなかったので、colaboratoryの左に表示されているresultフォルダから、model.H5を直接ダウンロードしました。
HTMLとCSSでアプリの見た目を作ります。
HTMLです。参考に。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Part identification</title>
<link rel="stylesheet" href="../static/stylesheet.css">
</head>
<body>
<div class="header">
<div class="header-logo" >Parts identification</div>
</div>
<div class="main">
<div class="submit-wrapper">
<h2> AIが送信された部品を識別します</h2>
<h3 class="send-p">部品の画像を送信してください</h3>
<p class="send-p2">
「ファイルを選択」で画像を選び「送信!」を押してください
</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="送信!" type="submit">
</form>
<div class="answer">{{answer}}</div>
</div>
<div class="parts-contents">
<h3 class="parts-title">識別する部品</h3>
<div class="parts-wrapper">
<div class="manual">
次の3つ部品から識別します
</div>
<div class="parts">
<p>bearing</p>
<img src="../static/bearing_004.jpg">
<a href="https://www.ntn.co.jp/japan/what_is_bearing/index.html">
bearingって?
</a>
</div>
<div class="parts">
<p>sprockt</p>
<img src="../static/sprocket_099.jpg">
<a href="https://popponagaoka.xyz/sprocket/">
sprocktって?
</a>
</div>
<div class="parts">
<p>hexagon_nut</p>
<img src="../static/hexagon_nut_009.jpg">
<a href="https://e-neji.info/%E3%83%9C%E3%83%AB%E3%83%88%E3%81%A8%E3%83%8A%E3%83%83%E3%83%88%E3%81%AE%E9%81%95%E3%81%84">
hexagon_nutって?
</a>
</div>
</div>
</div>
</div>
<footer>
<div class="footer-logo">
Created by T.H
</div>
</footer>
</body>
</html>CSSです。
.header {
background-color: #26d0c9 ;
height: 60px;
margin: -8px;
display: flex;
/*flex-direction: row-reverse;*/
/*justify-content: space-between;*/
}
.header-logo {
float: left;
color: #fff ;
font-size: 25px;
margin: 15px 25px;
}
.main {
height: 745px;
}
.submit-wrapper {
height: 380px;
}
h2 {
color: #444444 ;
margin: 60px 0px;
text-align: center;
}
.send-p {
color: #444444 ;
margin: 60px 0px 30px 0px;
text-align: center;
}
.send-p2 {
text-align: center;
margin-bottom: 50px;
}
.answer {
color: #444444 ;
margin: 30px 0px 30px 0px;
font-size: 25px;
text-align: center;
}
.parts-wrapper {
position:absolute;
left: 50%;
margin-left: -450px;
max-width: 100%;
}
.parts-title {
border-bottom: 2px solid #dee7ec ;
padding-bottom: 15px;
margin-bottom: 15px;
text-align: center;
}
.manual {
text-align: center;
}
.parts {
float: left;
width: 200px;
text-align: center;
padding: 0px 50px;
margin-left: auto;
}
img {
height: 150px;
width: 150px;
}
form {
text-align: center;
}
footer {
background-color: #59839e ;
background-size: cover;
height: 60px;
/*width: 100%;*/
margin: -8px;
/*display: flex;*/
/*position: absolute;*/
/*bottom: 0;*/
}
.footer-logo {
color: #dee7ec ;
text-align: right;
font-size: 20px;
padding-top: 20px;
margin: 0px 25px;
}Flaskで動作するようにします。
このpythonのファイル名は「main.py」にして下さい。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["bearing","sprockt","hexagon_nut"]
image_size = 150
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5')#学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み 、np形式に変換
img = image.load_img(filepath, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "この部品は " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)Herokuへデプロイします。

無事デプロイできました。
Herokuへの公開は以下のサイトが参考になります。
この工程でつまずいた所
やったことないものばかりだったので、たくさんつまずきました。その中からいくつか紹介します。
HTMLとCSSで見た目をつくる
まずつまずいたのが、HTMLとCSSで見た目を整えることです。HTMLとCSSはProgateで事前に学習していましたが、実際に自分でなにかをつくったことがありませんでした。
とにかく思い通りにならず、あれやこれをいじり回してなんとかしたので、「なにをどうしたらできたのか?」がよく分かっていません。フッターが中央に表示されてしまった時は思わず笑ってしまいました。
Flaskで画像が表示されない
Flaskで画像が表示されなかったことです。これは、HTMLで絶対パスを指定していたことが原因でした。相対パスに修正したら表示されるようになりました。Flaskで反映させるには相対パスにする必要があるようです。
HTMLでは問題なく表示できていたのにFlaskだと表示されないので「なにがいけないんだろう?」と悩みました。これも分かるまで時間がかかりました。しかし、これがきっかけで絶対パスと相対パスをしっかり理解することができました。
Herokuへデプロイしたアプリがエラーになる
Herokuへデプロイしたアプリが「Internal Server Error」となってしまったことです。自分で調べても解決できず、チューターの方に聞きました。すると、pythonのファイル名が「main.py」となっていないことが原因であるとわかりました。ファイル名を変更し、再度デプロイすると、正常に動作しました。
エラーの原因を調べるため、コマンドプロンプトで
heroku logs --tailと入力し、エラーを見てみました。ところが、表示される情報量がとても多く「なにが問題なのか?」がさっぱり理解できませんでした。
原因が分かったあとで見てみると、エラーにはしっかり「ディレクトリにmain.pyがないですよ」と表示されていました。こういうものにも冷静に対応できないとダメだなぁと反省しました。
アプリへのリンク
今回つくったアプリのリンクを掲載します。興味がありましたら見てみてください。
まとめ
考察や感想
今回つくった学習モデルは、当初の予想より精度が良かったです。多くの場合、精度は0.80ほどでそこから調整を加え精度を上げても0.85止まりだそうです。自分の予想もその辺りかなと思っていました。ところが調整後は0.937と高い精度が出ました。
精度が良かった理由として、機械部品の特徴が上げられます。機械部品は輪郭がはっきりしていて、機械が特徴をとらえやすいのかもしれません。また、機械部品は規格をもとに作られているので、形状も安定しています。このことが精度を高くできた理由と考えています。もしこれが自然由来のもの(例えば人の顔や動物、植物など)だったりすると、もっと難しかったかもしれません。
画像を少し変更しただけで、精度が大きく変わってしまうのは驚きでした。画像を数枚削除しただけで、大きく精度が落ちました。削除した画像が学習に影響を与えていたのだと思います。「この画像は大したことないし、数枚削除するだけだから影響少ないだろう」という考えと、実際の結果にかい離があると知りました。
深層学習の学習結果に何がどれだけ影響しているのか?は、人間は完全に把握できません。画像を追加・削除・加工など変更が加わると、その都度調整が必要だということが分かりました。
現物を使ったテストでは、ベアリングとスプロケットの画像が六角ナットと認識されてしまいました。これは「学習用データに真横の画像がない」ことが原因と考えられます。
ベアリングとスプロケットは真横の画像がなく、六角ナットには真横の画像がありました。これにより横から見た画像は「六角ナット」と判断してしまった可能性が考えられます。
「人間ならできそうなことが、機械では難しい」という例だと思います。人間なら「推定して判断する」ことができ、見たことないものでも類推して判別できます。しかし、機械では学習データにないものは判別できません。
機械学習で精度を上げるには、品質の高い膨大なデータが必要だと認識しました。
今回AIをつくってみて、本を読んだだけでは分からない貴重な学びを得られました。今後も実践を重ね、スキルアップしていきたいと思います。
今後の展開
アプリの今後の発展として、部品判別から購入まで行えることを考えています。例えば、送った画像から部品を判別しアマゾンやモノタロウで一致する部品を探し出し、購入できるなど。ただし、それを実現するには大きな問題を解決しなければいけません。
大きな問題が残っている
実際にアプリを使ってもらうには、大きな問題があります。それは「何の部品かわかっても、必要な情報が足りない」ことです。
部品を選定するには、部品の名前からさらに細かい規格・仕様を決めなければいけません。メーカーもそれぞれの使用条件にあった多種多様な部品を販売しています。組み合わせる部品、使用する環境などなど、考慮する項目がたくさんあります。
その膨大な部品の中から「自分が使用する条件にあったもの」を選定するのが一番難しいところです(現場の方もここでよくつまずきます)。
特に今回のベアリングやスプロケットなどはコツを知らないとかなり難しい部類です。なので本当のゴールは「型番までたどり着くこと」だったりします。
もしアプリに改良を加えるなら、対話形式で「軸の寸法は?環境は熱い?シールは必要?グリスは必要?」など選択できるようにするといいかもしれません。
ただ、自分のスキルがまだまだ足りていないので、実現するにはもっと勉強が必要です。
AIの知識を今の職場で活かすなら
生産工程の設備で使われている加工部品を、画像から「図面・図番」を探してくれる仕組みがあるといいなと思っています。これも現場の方だと難しいものです。
「この部品を交換したいんだけど、なんの部品か分かる?」と相談されることがよくあります。このような場合、まず使われている工程から追っていき、現物と同じ図面を探します。寸法などを確認し、図面と現物が同一であるか調べます。こうしてやっと図番がわかり、加工部品を製作するという流れが多いです。
この部分を画像を送るだけで「図番」まで探してくれると、効率的だなと思いました。更に、見積もり依頼から発注までこなせると便利だなと思います。
考えられる仕組みは、データベースに図面、図番、名前などを管理しておきます。AIが画像から一致する図面を探し出し、図面に紐づけられている図番や名前が判明します。
この際、懸念する問題は「画像から図面を判断できるのか?」です。
AIをつくるなら図面を教師データ、画像を学習データにすればいけると想像しますが、これがうまくいくのかわかりません。また、うまくいったとしても、図面ごとに部品の画像をたくさん用意しないといけません。コストが効果に見合うのか心配です。
これも、自分のスキルがまだまだ足りていないので、実現するにはもっと勉強が必要です。
おわりに
テーマの答え
冒頭で述べた「未経験で39歳のおっさんが、勉強してAIをつくることができるのか?」の答えは…
「まだわからない部分もあるけどなんとかつくれる!!」
です。なんともスッキリとしない答えで申し訳ありません。でもやってみた正直な感想です。
AIは言語のPythonを覚える必要はありますが、AIをつくることに関していえばそこまで難しくないと思います。なぜならAI関連はライブラリが充実しているので、それを理解しうまく使えば「なんとかなる」というのが印象です。
では「AIつくりにおいて肝の部分は何?」と疑問に思うかもしれません。それは「データ集め」と「パラメータ調整」だと思います。自分がAI製作をやってみて、重要だと思った部分です。
目的を達成するAIをつくるために「どんなデータを用意すればいいか?」はとても重要になります。集めたデータがダメだと「いくら学習させても使い物にならない」という結果になります。これはセンスを磨くしかなく、統計的センスや経験が必要だなと感じました。
パラメータ調整は「精度を上げる」ために必要な知識です。パラメータの数値を変えるだけで、精度が10%向上しました。また、過学習も大事な観点です。講座でも重要と位置づけられていましたし、現役エンジニアの方も過学習を懸念されていました。この辺りの作り込みができないと、実用化できないなぁと感じました。
この辺りの感覚は、現職の機械系エンジニアに似ていると思いました。
機械系エンジニアではまず、出された課題に対し「どんなものを設計すれば目的が達成できそうか?」を考える点が重要です。一度設計して製作してしまうと、大きな変更はできません。なので、そもそも大きく外していないことが重要になります。
次に、「作ったものを調整し精度を上げていく」という点も重要です。設計したものを提案しただけでは、現物や実際の使用に耐えない場合が多いです。加工部品にはバラツキが存在し、1つの部品にフィットするだけではいけません。そこを修正や調整をして、使えるものに改良していく作り込みが重要になります。
AIを勉強するのに必要なことは
これからAIを学びたいという方向けに、自分が感じた学ぶコツなどを紹介します。
私は今回AIを学ぶために、Aidemyの「AIアプリ開発コース」を利用しました。スクールに通うことはもちろん大事ですが、それ以上に大事なことがあると思います。
大事なのは「学習時間を作る」ことです。時間をつくりだすことができれば、AIを覚えることができます。ただ、一番大変なのも「学習時間を作る」ことです。よくある「年齢がもう若くない」は、学習時間をつくることに比べると、それほど重要ではないと思います。
この「学習時間を作る」という課題を解決するには「学習ができる生活スタイルを作る」ことが良い方法です。
自分の例を紹介すると、平日は朝に1時間の学習時間を確保してました。仕事から帰宅してからも2時間は学習時間を取っていました。仕事中も時間があればAIの勉強をしていました。休日は午前に3時間、午後は4時間(2時間と2時間)と時間を取りました。
この平日3時間、休日7時間をコンスタントにこなすことが、一番のコツだと思います。
私はプログラミングの経験もなく、AIに関しての知識もありませんでした。しかし、コンスタントにこの学習時間を取ることで、2カ月ほどでカリキュラムを終えることができました。
ただいきなり「学習ができる生活スタイルを作る」ことは難しいと考えます。まずは練習してみるところから始めるとスムーズかと思います。
私の場合、給付金制度を利用したので、申請してから講座の開始まで1カ月ほど期間が空きました。その1カ月を使って、学習習慣を身につけることに専念しました。
「学習ができる生活スタイル」づくりをする練習は、まず1日の生活のどこに学習時間を入れると良いかを紙に書き出します。「朝は何時に起きればうまくいくかな?」「食事はいつ取ればスムーズだろう?」など、うまくいきそうなスケジュールを立てます。そのあとは実際にやってみて、試行錯誤しながら自分がうまく続けられそうな生活に変えていきました。大変なのは最初だけで、一端身に付いてしまえばあとは続けていけると思います。
このおかげで実際に講座がはじまっても、スムーズに学習することができたと思います。
この練習期間でやった学習は、ProgateでHTMLやPythonなどのプログラミングの勉強、AIに関しての本や動画を見るなどです。これもある程度効果があったと思います。
学習のコツは一度に長時間やるのではなく、コマ切れでやって行く事だと思います。長時間の勉強はつらく、集中もできません。なので運動や趣味など他のことも間にはさみながら、勉強すると良いと思いました。実際私は、趣味の運動やサウナなど入れながら学習を進めていました。このおかげで集中力を切らすことなく学習できたと思います。
こうした勉強をするのに大事なスキルがスケジュール管理になります。自分はスケジュール用のノートに日々の学習時間を記録してやっていました。こうした見える化もやれない日を防ぐ効果があります。さらにスケジュール管理が大事な理由は、学習時間を週単位で管理できることです。
社会人になると、様々な用事が入り予定していたことができないことがあります。私もAIの勉強に加え、自治会長を並行してやっていたので、時間が取れない日もありました。これは社会人である以上しょうがないことなので、「できない日があっても他の日でカバーする」管理が大事になると思います。これも学習時間を記録し、管理していないとできません。
毎日新聞を読んでいると、最近は頻繁にAIに関する記事が出ています。AIはこれからのビジネスや生活でより利用されるだろうと思います。AIを学び、活躍できる人材になることは「これからの社会に必要なことでは」と感じます。
また、リスキリング(学び直し)も盛んに叫ばれています。これからも活躍するビジネスパーソンになるには、「学ぶこと」は避けては通れない時代が来ているのではないでしょうか。
うまく学べるようになることは、これから一番重要なスキルになるかもしれません。
以上参考になれば幸いです。最期まで読んで頂きありがとうございます。
今後の予定
まだ受講期間が余っているので、E資格コースを受けようと考えています。そして、その後は転職活動を進める予定です(最大のテーマです)。
この記事が気に入ったらサポートをしてみませんか?