NDLOCRをインストールしました

WindowsにNDLOCR(国立国会図書館NDLラボの開発したOCR処理プログラム)をインストールした際に、少し設定などを変更する必要があったので、備忘録代わりに書いておきます(2024/1/22)。Windows11、GPUはNVIDIA GeForce RTX 2070 with Max-Q Design、Git Bash上の操作です。なお、1810年出版の英語の文献(二段組み、カラー、HathiTrust Digital Library所収)をOCRしました。
1.インストール
githubレジストリのREADMEファイルの通りにインストールします。Git Bashから、1.リポジトリのクローンをし、3.Dockerをインストールし、4.Dockerコンテナのビルドを行います(LinuxOSを入れるため時間がかかります)。リポジトリのクローンとDockerコンテナのビルドはコマンドをコピーペーストで大丈夫です。
https://github.com/ndl-lab/ndlocr_cli
2.画像ファイルの用意
OCR処理したい画像ファイルを入れたフォルダーを作成します。フォルダーは二つ必要です。以下のように作成しました。
(abcはユーザー名)
C:\Users\abc\input_root
C:\Users\abc\input_root\img
input_rootのフォルダー名はなんでもよいのですが、中にimgという名前のフォルダを作成します。imgフォルダの中に画像ファイルを入れます。今回は英語のpdfをjpg画像で保存したものをいれました。Hathitrustから入手した古い書籍のpdfファイルの一部です。計12のjpgファイル。ただしNDLOCRは日本語用です。
なお、画像ファイルは、テキストのpdfファイルを用意し、python上のプログラムを使用したり市販のpdfソフトウェアを使用するなどして、pdfファイルを画像ファイルに変換することができます。
3.Docker起動ファイルの修正
Dockerの起動ファイルを修正します。共有メモリの量と、さきほどの画像をいれたフォルダーの指定です。(abcはユーザー名)
cd /c/Users/abc/ndlocr_cli
cp docker/run_docker.bat docker/run_docker2.bat
起動ファイルはdockerフォルダ内のrun_docker.batです。オリジナルはそのままにしておいて、run_docker2.batファイルを作成してこちらを利用することにします。
vi docker/run_docker2.bat
以下のように修正します。
docker run --gpus all -d --shm-size=16gb --rm --name ocr_cli_runner -v C:/Users/abc/input_root:/root/ocr_cli/input_root -i ocr-v2-cli-py38:latest
修正点は、
1. --shm-size=16gbの追加と(16gbの部分は256mbや2gbなどでもよい)、
2. -v C:/Users/abc/input_root:/root/ocr_cli/input_rootの追加です(C:/Users/abc/input_rootの部分は画像フォルダの場所)。
それぞれ、共有メモリの増加と、画像フォルダーのマウントです。先ほど作成した画像フォルダーを、Dockerを起動してLinuxに移動した際に、/root/ocr_cli/input_rootフォルダとして使えるようにします。
4.起動
NDLOCRを起動し、画像ファイルをOCRにかけます。以下の4行が、今後もコピーペーストして使う内容で、起動からOCR処理まで行います。1行目は先ほどすでに行っている場合は不要です。
(Windows上でDocker Desktopアプリを起動)
(Windows上でGit Bashアプリを起動し、以下のコマンドを順番に実行)
cd ndlocr_cli
docker/run_docker2.bat
winpty docker exec -it ocr_cli_runner bash
python main.py infer ~/ocr_cli/input_root/ ~/ocr_cli/input_root/output/ -s s
注意点としては、3行目のdocker execを行う際はwinptyをつけること(winpty上で起動)、OCR処理を行う際、outputフォルダー(~/ocr_cli/output/input_root/txt、PC側から見れば先に作成した画像フォルダー)に結果が入ることです(入力フォルダーはマウント済みかつ指定された形式に沿ったフォルダー、出力フォルダーはすでに同じフォルダーが存在する場合、名前が変わる)。
5.確認
cat ~/ocr_cli/output/input_root/txt/***02_main.txt
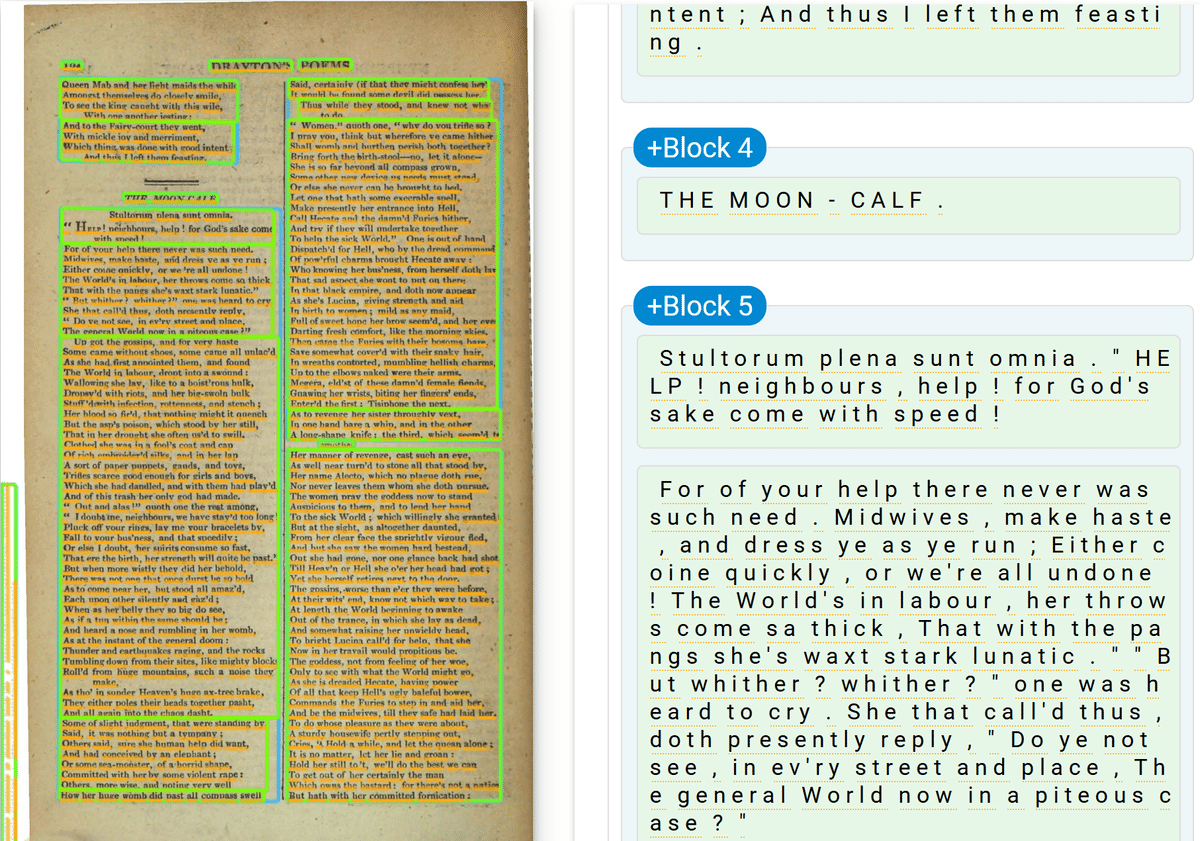
だいたいきちんと読み取りができていました。tessseractよりも精度は高そうな印象です。これならテキストを突き合わせて修正する作業もかなり楽になるのではないでしょうか。なおPC上では、画像フォルダー内のoutput/input_root/txt/以下に保存されたテキストファイルになります。

HathiTrustからダウンロードした大体同じ場所のテキストは以下のようになります。文字は正確ですが、段組みが処理しきれていない点が問題点です。

同部分は、TesseractとPyOCRの組み合わせでは以下のようになります(Google Colaboratory上で実行)。つぶれた字などが英語以外の外国語に翻訳されます。また段組み処理もうまくいっていないようです。

以下は有料ですが、定評のあるGoogle Cloud Visionデモ版でのOCRです。おそらくほぼ問題なくテキスト化できています。
市販のソフトウェアであるAdobe Acrobat、ABBYYなども試しましたが、段組みやその他の点(前置詞が消去されるなど)でなぜかうまくいきませんでした。
この記事が気に入ったらサポートをしてみませんか?