
はじめての自然言語解析(全文公開)

技術書店5にて出品したはじめての自然言語解析を全文公開します!
1.1 自然言語解析のステップ
自然言語解析を行う際は基本的な流れとして、下記3ステップを踏むことになります。
形態素解析・分かち書き→数値ベクトルへ変換→機械学習アルゴリズム適用
形態素解析とは、品詞等の情報に基づいて、意味のわかる最小単位に文章を区切ることを言います。
例えば、「今日は学校に行って、その後塾に行って、数学を勉強した。」という文章があったとします。
これを形態素解析すると下記のようになります。(MeCabというツールを使用しています。後ほど詳しくご説明します。)

分かち書きとは、文章において形態素解析に従って語の区切りに空白を挟んで記述することです。英語では単語と単語の間には空白が存在していますが、日本語にはないため、空白を付け足す必要があります。自然言語処理のアルゴリズムは基本的に英語をベースに作成されたもののため、日本語に適用する際には、適用可能な状態に処理してあげる必要があります。最初に例に挙げた文章は分かち書きをすると
「今日 は 塾 に 行って 、 その 後 塾 に 行って 数学 を 勉強 した 。」
というように意味のわかる最初単位ごとに空白が入る形になります。
次に数値ベクトルへ変換します。自然言語処理で行われる数値ベクトル変換の方法は3章で詳しく解説します。
それ以外の方法としてOne-hot表現の利用も考えられます。One-hot表現とは、1つだけHigh(1)であり、他はLow(0)であるようなビット列という意味です。
分かりづらいので、例を用いてご説明しましょう。「赤」、「緑」、「青」の三種類のデータがある場合、
赤→[1,0,0]、緑→[0,1,0]、青→[0,0,1]というようにマッピングすることをOne-hot表現と言います。
One-hot表現は機械学習を行う際に、よく使われます。なぜなら、赤を1、緑を2、青を3に置き換えてしまうと、
それぞれの色同士の関係性が生じてしまうのです。「赤(1)」と「青(3)」より「赤(1)」と「緑(2)」の方が距離が近い
(似ている)ことになってしまいます。赤、青、緑を同列に扱うためにOne-hot表現にする必要があるのです。
そして最後に作成した数値ベクトルを機械学習アルゴリズムに適用します。今回はLDAというクラスタリング手法を適用します。
既に数値ベクトルになっているので、分類・回帰など目的に応じて様々な機械学習アルゴリズムに適用することが可能です。
1.2 トピックモデルとは?
トピックモデルとは文章の潜在的意味を推定するモデルです。トピックモデルでは、文章が複数の潜在的なトピックから確率的に生成されると仮定します。ある新聞記事があった際に、経済のこと80%、国際的なこと20%、というように複数の潜在的なトピックの構成具合を算出することができます。
例えば、“日銀の量的緩和によって日経平均株価の上昇を達成し、日本の貿易黒字にも好影響を与えている。”
という文書があったとき、従来の潜在意味解析ではこの文書を「経済」と「国際」両方のトピックに関連付けることは難しいですが、トピックモデルでは可能になります。文章の各トピックへの所属確率値が算出出来るので、この値を使って各文章がどの程度「近いか」ということを算出することが出来ます。これがどんなことに応用できるでしょうか?例えば、グルメサイトのレビュー投稿記事から、似ているユーザー同士をグルーピングすることも可能です。ユーザーのレビュー投稿記事を自然言語解析してトピックモデルに適用することで、算出されたトピックの所属確率値をレビューの特徴量に割り当てられるので、各ユーザーの類似度を求めてグルーピング出来るのです。
1.3 自分の好きな文章をトピックモデルに適用してみよう(今回使うデータセットは橋下徹さんのメルマガ)
今回使用するデータセットは橋下徹さんのメルマガです。このデータを解析しようと思った理由として、
単純に僕(@Seiyan1)が橋下徹さんの大ファンというのがあります笑
ただ、それだけではなく、橋下徹さんのメルマガは毎回あるテーマについて書いてあるため、
各メルマガごとに特徴的な単語があるはずです。そこで単語の出現頻度分布から文章を潜在的なトピックへ確率値として
分類するトピックモデルを使用すれば、文章ごとに当てはまりの良いトピックへ分類することが出来るのでは、と考え、今回の解析を行おうと思いました。
元データは著作権の関係でアップロード出来ませんが、各メルマガ号ごとに分かち書きされたデータをgithubに上げております。
https://github.com/seiyakitazume/NLP_hashimoto_toru
上記URLにアクセスし、「tokenized_data.csv」をダウンロードすれば、
橋下徹さんのメルマガ文章が分かち書きされたデータを取得できます。こちらで公開しているコードを使ってみたい方は、
3章の数値ベクトルへ変換から分かち書きされたデータを読み込み、適用することで、
この本と同じ結果を得ることが出来ると思います。
【余談】広告代理店の営業の時のどん底時代、いつもYouTubeで橋下徹さんの記者会見を見ていた
広告代理店の営業として働いている際、テレビ広告を売っていました。
お客さんは各テレビ局の視聴率の状況や広告プランを比較検討しながら発注する局を決めます。大抵2局〜3局に発注することが多いですね。キー局は日本テレビ、TBS、フジテレビ、テレビ朝日、テレビ東京の5局しかないと思いがちですが、各都道府県にキー局の系列テレビ局が2〜4局あるので、全国に向けてテレビ広告を発注すると、80局近くのテレビ局に発注することになります。そして、発注すると80局のテレビ局の広告プラン(どの番組の後に広告が流れるか)が紙で出力されて、それをお客さんに説明に行きます。そしてお客さんから「湯けむり温泉殺人事件の後の広告枠は変えて欲しい」と
ご要望を頂くと、紙にバッテンをしてこちらの広告枠へ変更と鉛筆で記入するのです。それを社内のテレビ局担当の方に持っていき、システムに打ち込み、広告枠変更の希望を出します。人づてに情報が伝わっていき、受け入れられるか分かるのに4営業日かかってしまいます。こういった広告枠の最適化はインターネットでは全て自動で行われています。アルゴリズムが最適な広告枠と広告を見せるべき最適なユーザーを見つけてきて、価格まで自動的に決まります。しかしテレビ広告だと全て人がやらなければいけない。深夜残業をしながら、テレビ広告の全体の仕組みを考えると一体自分は何をやっているんだろう、と考えどんどんモチベーションが下がっていきました。そんな時、いつも見ていたのは橋下徹さんの記者会見動画でした。自分はテレビ広告の付け替えでお客さんと社内を走り回りながら、何をやっているんだろうとどん底にいるときに、毅然とした態度で正論を言う橋下徹さんの動画に、こんなにカッコいい人がいるのか、と衝撃を受けました。この本は自然言語解析を解説する本ですが、裏テーマに橋下ファンを増やせたら、と密かに思っています。もし、今回のデータセットを使ってトピック分類を試した後、橋下徹さんの本やメルマガにも手を伸ばして頂けたら、嬉しいです。
2.1 形態素解析ツールMeCabとは
MeCabはオープンソースの形態素解析エンジンで、Google 日本語入力開発者の一人である工藤拓氏によって開発されています。自然言語解析で形態素解析する際によく使用されるメジャーなツールになります。PythonでMeCabを使用する場合は、下記のURLのようにpipにてインストールが出来ます。
2.2 分かち書きを行うClass文を解説
それでは分かち書きを行うClassモジュールを解説していきます。
まずは分かち書きを行うだけのClassモジュールを作成しました。
下記で出てくるストップワードとは、自然言語処理する際に一般的で役に立たない等の理由で処理対象外とする単語のことです。
例えば、助詞や助動詞などの機能語(「は」「の」「です」「ます」など)が挙げられます。これらの単語は出現頻度が高い割に特徴的な単語にならないので、除去することで機械学習アルゴリズムに適用するとき、
精度が上がることが多いです。また、同様の理由で分かち書きした後に抽出するデータを名詞, 動詞, 形容詞に絞ってます。
# -------------------------------
# モジュールインポート部分
# -------------------------------
import os
import time
import tqdm
import numpy as np
import pandas as pd
import MeCab
# ---------------------------------
# クラス定義や関数定義の部分
# ---------------------------------
# 単語リストを半角空白で結合された1行テキストに変換する関数
def list2line(words_list):
line = ""
for word in words_list:
line += word
line += " "
return line[:-1]
# 分かち書き用のクラス定義
class Wakati:
# コンストラクタの定義
def __init__(self, text):
self.text = text
self.tokens = None
self.targets = ["名詞", "動詞", "形容詞"]
self.stopwords = ["する", "もの", "れる", "ない", "られる",
"こと", "ある", "ため", "これ", "いる", "なる", "よる", "よう"]
# 分かち書きを行うメソッド
def tokenize(self):
words = self.get_words()
self.tokens = self.get_stopped_words(words)
return self.tokens
# テキストの形態素解析結果をDataFrameで返す関数
def get_dfw(self):
t = MeCab.Tagger("Owakati")
t.parse("")
node = t.parseToNode(self.text)
surfaces = []
stems = []
poss = []
while node:
surface = node.surface
feature = node.feature.split(",")
stem = feature[6]
pos = feature[0]
surfaces.append(surface)
stems.append(stem)
poss.append(pos)
node = node.next
df = pd.DataFrame()
df["SURFACE"] = surfaces[1:-1]
df["STEM"] = stems[1:-1]
df["POS"] = poss[1:-1]
return df
# 形態素解析から対象となる品詞の単語リストを返す関数
def get_words(self):
df = self.get_dfw()
words = []
for row in df.iterrows():
for target_pos in self.targets:
if row[1]["POS"] == target_pos:
if row[1]["STEM"] != "*":
words.append(row[1]["STEM"])
return words
# 単語リストにストップワードを適用した結果を返す関数
def get_stopped_words(self, words):
stopped_words = [word for word in words
if word not in self.stopwords]
return stopped_words
//}
上記で作成した必要な品詞・単語のみに絞って、
形態素解析を行ったClassモジュールを読み込んで分かち書きを行なっています。
//cmd{
# -------------------
# Module import
# -------------------
import re
import os
import time
import tqdm
import codecs
import pandas as pd
from libs.wakati import Wakati
# -------------------
# Class definition
# -------------------
class TokenData:
"""わかちがきした結果を出力するためのクラス."""
def __init__(self, path_dir_data):
"""コンストラクタ."""
self.path_dir_data = path_dir_data
def _get_filenames(self):
"""path_dir_data 以下の.txtファイル名リストを返す."""
filenames = os.listdir(self.path_dir_data)
filenames = [filename for filename in filenames
if ".txt" in filename]
return filenames
def _get_filepaths(self, filenames):
"""path_dir_data 以下の.txtファイルパスを返す."""
filepaths = [os.path.join(self.path_dir_data, filename)
for filename in filenames]
return filepaths
def _get_text(self, filepath):
"""テキストファイルからテキストを抽出して返す."""
f = codecs.open(filepath, "r", "cp932", "ignore")
text = f.read()
f.close()
return text
def get_df_tokenized(self):
"""テキストをわかちがきした結果をDataFrameで返す."""
filenames = self._get_filenames()
filepaths = self._get_filepaths(filenames)
texts = [self._get_text(filepath)
for filepath in tqdm.tqdm(filepaths)]
tokenized_texts = [" ".join(Wakati(text).tokenize())
for text in tqdm.tqdm(texts)]
df_tokenized = pd.DataFrame()
df_tokenized["filename"] = filenames
df_tokenized["token"] = tokenized_texts
return df_tokenized
def do(self, path_out="../tokenized_data.csv"):
"""テキストをわかちがきした結果をcsvファイルで出力する."""
self.df_tokenized = self.get_df_tokenized()
self.df_tokenized.to_csv(path_out,
encoding="utf8", index=False)
# -------------------
# Main processing
# -------------------
if __name__=="__main__":
path_dir_data = "../data/"
td = TokenData(path_dir_data)
td.do()
print(td.df_tokenized.head())3.1 分かち書きされたデータを数値ベクトルに変換する方法
分かち書きされたデータを数値ベクトルに変換する方法は様々な方法があります。今回は主要な3つの方法を解説していきます。
3.2 単語の頻度表現に落とすCountVectrizer
CountVectrizerは、文章を単語毎の出現回数の表現に変換する手法になります。単語毎の頻度を数値ベクトルへ変換し分散表現を得るという非常に単純な手法ですが、良い点は、文章の情報を出来るだけ落とさずに表現することが可能な点です。また、使用頻度という非常にシンプルな分散表現になっています。これから紹介するTF-IDFやWord2Vecは、複雑な計算方法で単語の分散表現を獲得する方法です。どの分散表現を選択するかは、対象となるデータとモデルアルゴリズムの相性をよく考慮しなければなりません。
複雑な分散表現がモデリングに有効な場合もありますが、逆にシンプルな方法の方が良い場合もあります。
(単語の頻度という非常に単純な方法が活躍するシーンは、実は非常に多いのです。)
3.3 重要な単語に重みを付けるTF-IDF
TF-IDFとは、TF(Term Frequency、単語の出現頻度)とidf(Inverse Document Frequency、逆文書頻度)
という指標によって各単語を重み付けする手法です。【ある文書で頻出する単語(TF)】と
【全ての文書の中で出現頻度が少ない単語(IDF)】は 特徴になり得るという仮定に基づいてスコアリングをします。
例えば、下記のような文書があった場合、
文書A 「私はオレンジとリンゴではリンゴが好きだ。」
文書B 「私は以前は青森に住んでいたが、今は東京都に住んでいる。」
文書C 「私は青森産のリンゴが好きだ。」
形態素解析を行い、重要な品詞のみに絞って分かち書きをすると下記のように変形できます。
⬇︎
文書A { 私,オレンジ,リンゴ,リンゴ,好き }
文書B { 私,以前,青森,今,東京都 }
文書C { 私,青森,産,リンゴ,好き }
この状態で、「私」は全文書に頻出する単語である一方、「オレンジ」は全ての文書の中で出現頻度が少ないです。
頻出する単語と、出現頻度が少ない単語を重み付けして数値化すると下記のようになります。
(下記の数値になる数式は省きます。頻出する単語には低いスコア、珍しい単語には高いスコアを付けています。)

3.4 ニューラルネットワークによる単語表現を可能にするWord2Vec
word2vecは、文章を解析し、各単語を200次元などの数値ベクトル表現に変換する手法です。
単語をベクトル化することで、単語同士の意味の近さを計算することが出来ます。
なぜこのような事が可能なのか?それはニューラルネットワークの隠れ層の重みの値を抽出し、
非常に豊かな表現が可能になったためです。これによって単語の足し算・引き算なども行えます。例えば、
フランス - パリ + 東京 = 日本
というような計算が可能になるのです。フランスから首都のパリを引いて、
日本の首都の東京を足す事で、日本という単語を得る事ができます。
デメリットとしては、裏で動いているのがニューラルネットワークのため動作保証が出来ない、という点です。
現在でもニューラルネットワークが何故、その答えを出したのか、完璧に理論を作れる人はいません。
理由は分からないけれども、何故か精度が高い予測モデルが出来てしまう、という不思議な機械学習アルゴリズムです。
逆を言えば、結果が悪いときに何故悪い結果になっているか理論立てする事が出来ないのです。
そのため、非常に大きな成果を出すときもあれば、なかなか成果を上げてくれないという事も起こり得ます。
4.1 LDAとは
LDA(Latent Dirichlet Allocation)とは、1つの文章が複数のトピックから成ることを仮定したモデルです。その潜在的なトピックの分布の事前分布にディリクレ分布を仮定しています。機械学習アルゴリズムによっては、事前分布を仮定して実データが実際はどのような分布になるのかを推定する方法が使われることがあります。複数のトピックから成ると仮定し、その各トピックはどのような分布であるか(事前分布)を仮定し、その分布がディリクレ分布ということになります。ディリクレ分布は、ベイズ統計で分布を予測する際の事前分布としてよく使われます。ディリクレ分布の説明をするには、下記のような図の通り、相互に関係している他の確率分布との関係性を説明しなければならず、冗長になってしまうためこの本ではディリクレ分布の詳細の説明は避けたいと思います。

4.2 CountVectrizerを使用し、LDAモデルを適用するClassモジュールを解説
今回は情報量を出来るだけ落とさずにLDAモデルに適用したいと考えたためCountVectrizerを使用しました。
# ------------------
# Module import
# ------------------
import os
import time
import tqdm
import pickle
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation as LDA
# ------------------
# Class definition
# ------------------
class LDAModel:
"""LDAモデル計算を行うクラス."""
def __init__(self):
"""コンストラクタ."""
self.path_csv = None
self.df = None
self.topic_number = None
self.features = None
self.Xcv = None
self.perplexity = None
self.topics = None
self.Xlda = None
self.y_topic_id = None
def dump(self, path_obj):
"""自身のオブジェクトを保存する."""
with open(path_obj, "wb") as f:
pickle.dump(self, f)
print("Object is saved as {}".format(path_obj))
def load(self, path_obj):
"""保存したオブジェクトを読み込む."""
with open(path_obj, "rb") as f:
obj = pickle.load(f)
self.path_csv = obj.path_csv
self.df = obj.df
self.topic_number = obj.topic_number
self.features = obj.features
self.Xcv = obj.Xcv
self.perplexity = obj.perplexity
self.topics = obj.topics
self.Xlda = obj.Xlda
self.y_topic_id = obj.y_topic_id
def prepare(self, path_csv):
"""LDA計算用のデータを準備する."""
dfcsv = pd.read_csv(path_csv, encoding="utf8")
self.path_csv = path_csv
self.df = dfcsv
cv = CountVectorizer(
token_pattern=u'(?u)\\b\\w+\\b'
)
cv.fit(list(self.df["token"]))
self.features = cv.get_feature_names()
Xcv = cv.transform(list(self.df["token"]))
Xcv = Xcv.toarray()
self.Xcv = Xcv
def cal(self, topic_number):
"""LDA計算を行う."""
self.topic_number = topic_number
model = LDA(
n_components=self.topic_number,
learning_method="batch",
random_state=0
)
print("********* LDA calculation is running ... ")
model.fit(self.Xcv)
self.model = model
self.perplexity = model.perplexity(self.Xcv)
self.topics = model.components_
self.Xlda = model.transform(self.Xcv)
self.y_topic_id = [np.argmax(x) for x in self.Xlda]
def get_df_topic(self, topic_id, topn=20):
"""トピック内容をDataFrameで返す."""
scores = self.topics[topic_id]
words = [self.features[i] for i in range(len(scores))]
df_topic = pd.DataFrame()
df_topic["word"] = words
df_topic["score"] = scores
df_topic = df_topic.sort_values(by="score",ascending=False)
df_topic = df_topic.head(topn)
return df_topic
def save_df_topic(self, topic_id, path_dir="../figs_topic/"):
"""トピック内容をグラフ化して保存する."""
if os.path.exists(path_dir) is False:
os.mkdir(path_dir)
df_topic = self.get_df_topic(topic_id)
df_topic = df_topic.sort_values(by="score", ascending=True)
ids = [i for i in range(len(df_topic))]
plt.figure(figsize=(12, 10))
plt.barh(
ids,
df_topic["score"],
color="blue",
alpha=0.6
)
plt.yticks(ids, df_topic["word"])
plt.xlabel("Score")
plt.ylabel("Word")
plt.title("LDA topic contents
for topic id = {}".format(topic_id))
path_fig = os.path.join(path_dir,
"topic_id_{}.png".format(topic_id))
plt.savefig(path_fig, bbox_inches="tight")
plt.close()
# ------------------
# Main processing
# ------------------
if __name__=="__main__":
path_csv = "../tokenized_data.csv"
path_obj = "../lda_model.pickle"
topic_number = 32
lm = LDAModel()
lm.prepare(path_csv)
lm.cal(topic_number)
lm.dump(path_obj)
lm.load(path_obj)
for i in range(topic_number):
df_topic = lm.get_df_topic(i)
print("++++ For topic id = {} ++++".format(i))
print(df_topic)
lm.save_df_topic(i, path_dir="../figs_topic/")
print("")
df = pd.DataFrame()
df["filename"] = lm.df["filename"]
for i in range(topic_number):
df["prob_topic_{}".format(i)] = lm.Xlda[:, i]
print(df.head())
df.to_csv("summary.csv", encoding="utf8", index=False)4.3 最適なトピックナンバーを探索するClass文を解説
クラスタリングモデルなどで事前にクラスタ数を決めなければならないのと同様に、LDAトピックモデルにおいてもトピック数を決定する必要があります。最適なトピック数を探索するためにperplexityという指標を参照しました。perplexityは、分岐数または選択肢の数を表します。分岐数が少ないほど対象を決定しやすくなるため、perplexityの小さなモデルほど当てはまりに優れていると解釈されます。必ずしもperplexityの小さなモデルが意図したトピックを抽出しやすいとは限りませんが、今回はperplexityの最小となる点を最適なトピック数と定めました。
# ----------------------
# Module import
# ----------------------
import re
import os
import time
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from libs.tokendata import TokenData
from libs.ldamodel import LDAModel
# -----------------------
# Function definition
# -----------------------
def get_dfcsv(path_csv):
"""csvファイルを読み込みDataFrameで返す関数."""
return pd.read_csv(path_csv, encoding="utf8")
def get_date(filename):
"""ファイル名から日付を抽出して返す."""
pattern = re.compile(r"\d+年\d+月\d+日")
obj = re.search(pattern, filename)
if obj is not None:
date = obj[0]
else:
date = ""
return date
def get_vol(filename):
"""ファイル名からvolume numberを抽出して返す."""
pattern = re.compile(r"Vol.\d+|vol.\d+")
obj = re.search(pattern, filename)
if obj is not None:
try:
vol = obj[0].split(".")[1]
vol = int(vol)
except:
vol = -1
else:
vol = -1
return vol
def make_tokenized_data(path_dir, path_csv):
"""dataディレクトリのテキストファイルから
学習用のデータを生成しcsvファイルで保存する."""
td = TokenData(path_dir)
td.do(path_csv)
print("Tokenized text data is saved as {}".format(path_csv))
def build_lda_model(path_csv, path_obj, topic_number):
"""LDAモデルを構築保存した上そのオブジェクトを返す."""
lm = LDAModel()
lm.prepare(path_csv)
lm.cal(topic_number)
lm.dump(path_obj)
return lm
def read_lda_model(path_obj):
"""構築したLDAモデルのオブジェクトを読み込み返す."""
lm = LDAModel()
lm.load(path_obj)
return lm
def get_topic_contents(lm, path_figs_topic):
"""LDAモデルのトピック内容をグラフで作成して保存する."""
topic_ids = [i for i in range(lm.topic_number)]
for topic_id in topic_ids:
print("********** Topic contents
for topic_id = {} **********".format(topic_id))
df_topic = lm.get_df_topic(topic_id)
lm.save_df_topic(topic_id, path_figs_topic)
print(df_topic)
print("")
def get_perplexity_dependence(path_csv, path_fig_perplexity):
"""トピック数とperplexityの関係をグラフで保存する."""
print(" Calculation for perplexity
dependence on topic number is running ... ")
topic_numbers = [2, 4, 8, 16, 24, 32, 40, 48, 64]
pps = []
for topic_number in topic_numbers:
lm = LDAModel()
lm.prepare(path_csv)
lm.cal(topic_number)
pps.append(lm.perplexity)
plt.figure(figsize=(10, 10))
plt.scatter(
topic_numbers,
pps,
color="blue",
alpha=0.6,
s=200
)
plt.plot(
topic_numbers,
pps,
color="blue"
)
plt.xlabel("Topic number")
plt.xscale("log")
plt.ylabel("LDA perplexity")
plt.title("Perplexity dependence on topic_number")
plt.savefig(path_fig_perplexity)
print("Perplexity dependence is saved as {}"
.format(path_fig_perplexity))
def get_report(lm, path_report):
"""LDAモデルのトピック所属確率に関するレポートを出力する."""
df_report = pd.DataFrame()
df_report["filename"] = lm.df["filename"]
df_report["volume"] = [get_vol(filename)
for filename in lm.df["filename"]]
df_report["date"] = [get_date(filename)
for filename in lm.df["filename"]]
topic_ids = [i for i in range(lm.topic_number)]
for topic_id in topic_ids:
df_report["prob_topic_id_{}".format(topic_id)] =
lm.Xlda[:, topic_id]
df_report = df_report.sort_values(by="volume",ascending=True)
df_report.to_csv(path_report, encoding="utf8",index=False)
print("Probability for each topic
result is saved as {}".format(path_report))
def get_figs_topic_prob(path_report, path_figs_topic_prob):
"""volume番号にトピック所属確率をトピックごとに出力する."""
if os.path.exists(path_figs_topic_prob) is False:
os.mkdir(path_figs_topic_prob)
df = get_dfcsv(path_report)
cols = df.columns[3:]
for col in cols:
print("Output topic probability graph for {}".format(col))
plt.figure(figsize=(10, 10))
plt.scatter(
df["volume"],
df[col],
color="blue",
alpha=0.6,
s=200
)
plt.plot(
df["volume"],
df[col],
color="blue"
)
plt.xlabel("Volume")
plt.ylabel("Probability")
plt.title("Topic probability for {}"
.format(col.replace("prob_", "")))
path_save = os.path
.join(path_figs_topic_prob, col + ".png")
plt.savefig(path_save)
plt.close()
# -----------------------
# Settings
# -----------------------
path_dir = "./data/"
path_csv = "./tokenized_data.csv"
path_obj = "lda_obj.pickle"
path_figs_topic = "figs_topic/"
path_figs_topic_prob = "figs_topic_prob/"
path_fig_perplexity = "topic_number_dependence.png"
path_report = "./lda_topic_prob_report.csv"
# -----------------------
# Main processing
# -----------------------
if __name__=="__main__":
make_tokenized_data(path_dir, path_csv)
get_perplexity_dependence(path_csv, path_fig_perplexity)
lm = build_lda_model(path_csv, path_obj, topic_number=32)
lm = None
lm = read_lda_model(path_obj)
get_topic_contents(lm, path_figs_topic)
get_report(lm, path_report)
get_figs_topic_prob(path_report, path_figs_topic_prob)最適なトピック数を確定する
前章でご紹介したperplexity(分岐数)の最適な値を計算した結果になります。

横軸はトピック数、単位は10です。2メモリ目が20,3メモリ目が30です。
perplexityが最も低いのはトピック数が30と少しの点であることが分かります。そのため今回はトピック数として「32」を選択しました。
5.1 メルマガVol.5〜Vol.119を32トピックに分類して成功したもの、失敗したものを解説
32のトピックに分類して、分類が成功したと筆者が考えるトピックのみを紹介していきたいと思います。全ての結果を見たい場合はgithubに格納してありますので是非ご確認ください。

【topic_id_3】は、「日本維新の会」「大阪維新の会」「希望の党」という特徴単語があります。
橋下さんは、いかに国会議員が自分のことしか考えていないかをよく嘆いていました(笑) トピック名は「地域政党から国政政党になった政党の運営課題」としましょう。

【topic_id_4】は、「意思決定」「都庁」「地下空間」という特徴単語があります。豊洲移転問題で、何週にも渡って、問題を解説されていました。
トピック名は「都政問題」としましょう。
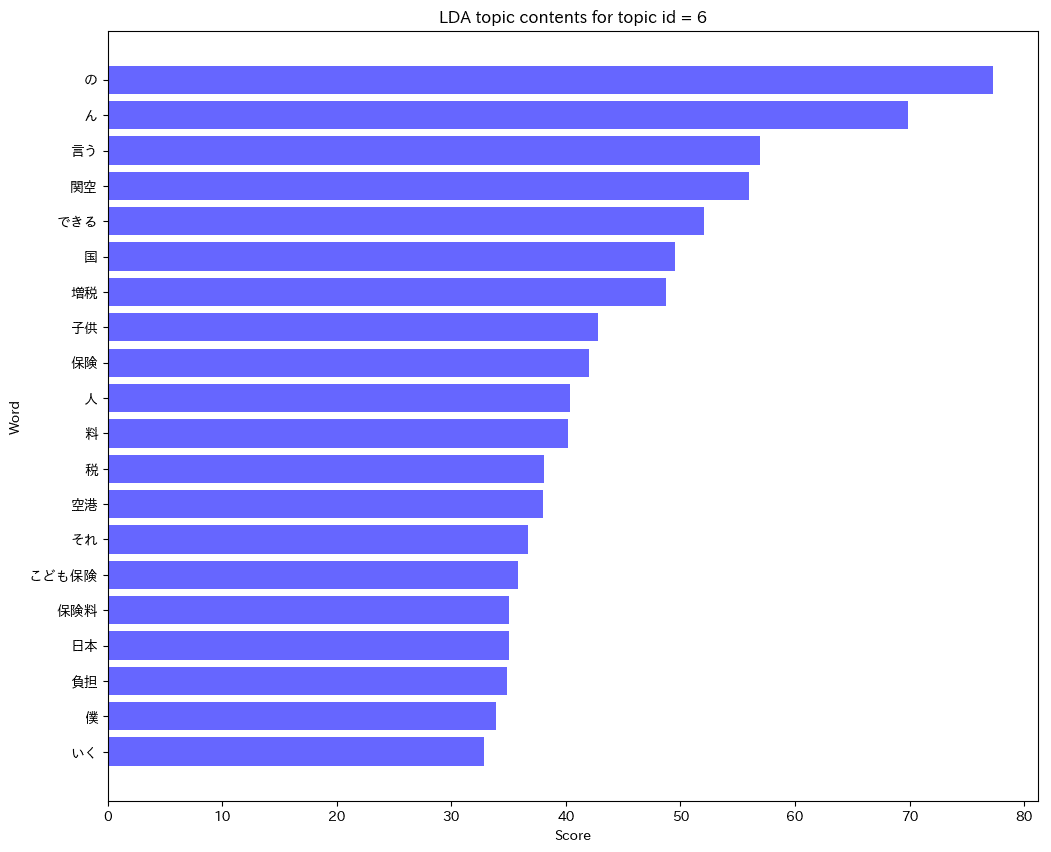
【topic_id_6】は「関空」「空港」という単語と、「子供」「保険」「増税」などの単語が特徴単語として上がっています。
経営改革によって赤字垂れ流していた関空が今や成田空港より営業利益を上げているそうです。また、小泉進次郎さんが進めていた「こども保険」について、これは保険ではない、増税だ!増税するならきちんとそれを説明すべきだ!保険なんて名前を付けるべきじゃない、と批判されていました。
関空とこども保険、本来であればトピックを分けなければいけないけれど、2つくっついてしまったようです。
理想では2つのトピックを分けて欲しかったですが、LDAは万能ではありませんので、こういったことも起こります。トピック名は「関空経営改革とこども保険の欺瞞」にしましょう!

【topic_id_7】は「指導」「学校」「相撲界」という特徴単語があります。
橋下さんは、大阪の高校で起こった体罰問題と相撲界で似た問題が起こっていると論じていました。大阪での体罰問題への対応方法は、は相撲界の問題を解決する時にも役に立つはずとの見解を示していました。
なので、トピック名は「相撲界の問題と教育改革」にしましょう。

【topic_id_8】は「ロシア」「北方領土」という特徴単語があります。
これは分かりやすいですね。安倍総理とプーチン大統領の会談について言及されたメルマガがありました。トピック名は「ロシア外交」としましょう。

【topic_id_9】は「ケンカ」「専門家」「トップ」という特徴単語があります。これは橋下さんが弁護士時代を通じて得た交渉のやり方を論じるトピックだと思います。外交は左手で銃を突きつけておいて、右手で握手するという例を出されますが、こういった厳しい交渉を弁護士の経験を通じて獲得したと書かれていました。トピック名は「交渉のやり方」とでもしましょうか。

【topic_id_11】は「核兵器」「アメリカ」「北朝鮮」「ロシア」「力の均衡」という特徴単語があります。
メルマガでは『相互確証破壊』という理論について解説されていました。
核兵器保有国同士が戦争を起こすとお互いに壊滅的な打撃を与えてしまう事が分かりきっています。今の平和は大国間の微妙な力の均衡によって成り立っていると解説されていました。
トピック名は「国際社会における核の抑止力」としましょう!

【topic_id_12】は「インテリ」「トランプ」という特徴単語があります。
橋下さんはメルマガでトランプの事態を『変える力』を非常に評価しています。インテリと呼ばれる方々はトランプの発言の細かいところを批判するだけで、トランプを正しく評価出来ていないと言います。政治家は批判されても停滞している流れを変えることこそが仕事だ、という強い信念から出る解説だと思います。
この2つの単語だけでトピックを決めてしまうのは、微妙ですが、トピック名は「橋下徹のトランプ論」とでもしましょうか。

【topic_id_14】は「組織」「森友学園」「挽回」という特徴単語があります。安倍総理は森友学園問題で対応ミスをしたと指摘されていました。
賄賂を受け取ったなどの法律を犯した失敗はしていないけど、道義的に安倍さんの奥さんが森友学園で広告塔をしてしまったことは問題だと思います。
だから辞任する必要はないけれど、潔白だと主張することは違う、という指摘をされていました。
トピック名は「安倍さんの対応ミス」としましょう。

【topic_id_19】は「日本国憲法」「国民投票」「憲法改正」という特徴単語があります。日本は戦後一度も憲法改正が行われたことが無い、非常に珍しい国です。国民投票の重要性について解説されていました。
トピック名は「憲法改正の国民投票」としましょう。

【topic_id_20】は「イタリア」「五つ星運動」という特徴単語があがります。イタリアの五つ星運動は、大阪都構想と同じく統治機構改革を目指した運動でした。大阪都構想の政策と比較しながらイタリアに起こっている問題を解説されていました。
トピック名はそのまま「イタリア五つ星運動」としましょう。

【topic_id_21】は「歴史認識」「慰安婦問題」「国際政治」という特徴単語があります。これは橋下さんが政治家の時に、日本政府の曖昧な外交戦略について問題提起した事を解説されていました。
トピック名は「慰安婦問題における歴史認識問題」としましょう。

【topic_id_27】は「森友学園」「籠池」「政治家」「大阪府」「行政」という特徴単語があります。橋下さんは大阪で既得権打破というテーマで政治を行なっていたので、新しい教育機関についてもどんどん申請を受け入れていました。森友学園の始まりは、大阪府の教育機関を新設する規制が緩くなった際に、籠池さんが申請して承認が降りてしまったことからでした。
規制を無くすことは問題ではないけれど、新しい申請に対して、
それがちゃんとしたものかチェック機能をしっかり用意しなければいけなかった、自分のミスだったと解説されていました。
トピック名は「森友学園における大阪府の対応ミス」としましょう。

【topic_id_28】は「保育所」「できる」「待機児童」「イギリス」という特徴単語があります。安倍総理が待機児童を0にする、と宣言された時、
橋下さんは待機児童問題など国会で話し合う問題ではない、と指摘されていました。待機児童問題という地域との関係が強い問題は、地方自治体が対処すべき現状、国が権力を持ち過ぎてしまい、待機児童のような問題でも国が介入する必要が出てきてしまいます。イギリスという単語は、イギリスのEU離脱について解説されていた事でしょう。ここでも待機児童問題とイギリスのEU離脱についてトピックを分けて欲しかったけど、一緒になってしまっています。トピック名は「待機児童問題からみる地方分権の必要性とイギリスEU離脱」としましょう。
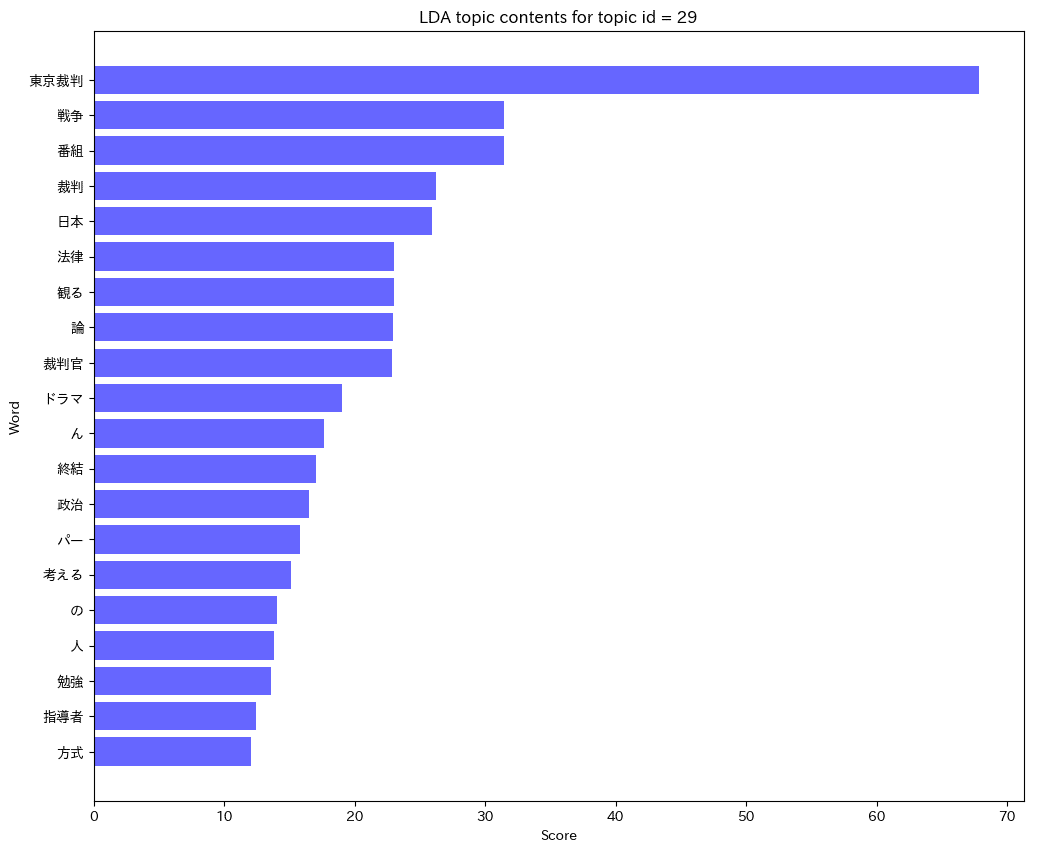
【topic_id_29】は「東京裁判」「番組」「裁判官」という特徴単語があがっています。以前NHKで放送されたドラマ東京裁判について、裁判官の人間模様という新しい観点で作られて勉強になったと言及されていました。
トピック名は「NHKドラマ東京裁判」としましょう。

【topic_id_30】は「小池さん」「地下水」「専門家会議」「環境水準」という特徴単語があがっています。
豊洲市場でベンゼンが検出された問題について、0リスク信仰は危ないと指摘されていました。
環境水準を多少超えるベンゼンが検出されたとしても、地下水はコンクリートの下にあるので市場運営には問題ないのです。
リスクを0.1から0にするために多大なコストをかけるべきなのか、
政治家は批判を恐れずメディアや市民に説明して説得していく責任がある、と主張されていました。
トピック名は「豊洲問題と環境水準」としましょう。
上記で紹介したトピックは比較的特徴的な単語からどんなトピックなのか分かりやすいものです。
何のトピックなのか特徴単語からは分からないトピックもあります。
トピックモデル(LDA)は完璧ではないので使える箇所を使っていくことが大切だと考えています。
LDAでトピックに分類できるだけでなく、各文章がどのトピックに分類されるか所属確率を算出する事が出来ます。

上記の図は【topic_id_3】トピック名「地域政党から国政政党になった政党の運営課題」です。
メルマガ80号で、所属確率がグンと上がっています。
メルマガ80号の中身を見てみると、まさに地域政党大阪維新の会を運営していた時の選挙戦略、小池都知事の選挙戦略の解説がされていました。ドンピシャで当たりです!

続いて、【topic_id_4】トピック名は「都政問題」です。
メルマガ27号と55号で所属確率が上がっています。
27号は、豊洲移転問題について解説されていてます。都政問題ですね。
メルマガ55号はこども保険と待機児童問題について解説されています。
純粋な都政問題に絞られたトピックという訳ではないですね〜。少し外している気がします。

続いて、【topic_id_6】トピック名は「関空経営改革とこども保険の欺瞞」です。
メルマガ12号、15号、58号でトピックの所属確率が上がっています。
12号と15号は、まさに関西国際空港の経営改革について書かれています。ドンピシャで当たりです!58号は、まさにこども保険の欺瞞について解説されています。当たりです!また、85号でも少し所属確率が上がっていますが、関空・こども保険の内容では無いのでハズレです。
ただ、所属確率も60%を超えていないので、ハズレても仕方ないのかな、と思います。

続いて、【topic_id_7】トピック名は「相撲界の問題と教育改革」です。
メルマガ79号と85号で所属確率が上がっています。
79号は相撲のことは一切出てこないです。教育改革について解説されています。85号では相撲業界と教育改革の問題がセットで語られています。
これはトピック名の付け方が難しいですね〜。相撲業界と教育改革がセットで語られている回もあれば、個別で語られている回もある。
両者ともこのトピックへの所属確率は上がってしまうという結果になりました。

続いて、【topic_id_8】トピック名は「ロシア外交」です。
メルマガ38号で所属確率が上がっています。38号はまさにロシア外交の問題について解説しています。ドンピシャで当たりです。

続いて、【topic_id_9】トピック名は「交渉のやり方」です。
メルマガ72号で所属確率が上がっています。
72号は北朝鮮外交を題材にした交渉のやり方について解説しています。ドンピシャで当たりです。

続いて、【topic_id_11】トピック名は「国際社会における核の抑止力」です。メルマガ39号と82号で所属確率が上がっています。
39号は核問題については触れていません。ただアメリカと北朝鮮の外交問題について解説しています。所属確率は60%を超えるくらい。「アメリカ」「北朝鮮」というワードについては非常に関係があるので、
トピック名の付け方を「アメリカ・北朝鮮が考える核の抑止力」とでもしておいた方がよかったです。82号は、まさにアメリカ・北朝鮮・ロシアの考える核についてで、ドンピシャで当たりです。

続いて、【topic_id_12】トピック名は「橋下徹のトランプ論」です。
これは非常に多くのメルマガで所属確率が高いです。
個別のメルマガの中身を確認して答え合わせをするのは辞めましょう(笑)
トランプさんの言動に関してはメルマガ開始頃の2016年4月から今に通じて
様々な話題について橋下さんが解説をしてきました。
この図を見ても、2年間を通じてメルマガでトランプさんに言及されてきた事が分かりますね。

続いて、【topic_id_14】トピック名は「安倍さんの対応ミス」です。
これも多くのメルマガで言及されていますね。安倍さんの対応ミスについては年間を通じて森友学園問題だけでなく、獣医学部新設の加計学園問題、財務省の改ざん問題など多くの問題で安倍さんの対応は最適解だったのか?と問いかけをされていました。

続いて、【topic_id_19】トピック名は「憲法改正の国民投票」です。
メルマガ33号で所属確率が上がっています。33号ではまさに憲法改正の国民投票について解説されています。ドンピシャ当たりです。

続いて、【topic_id_20】トピック名は「イタリア五つ星運動」です。
メルマガ44号で所属確率が上がっています。44号ではイタリア五つ星運動について解説されています。ドンピシャ当たりです。

続いて、【topic_id_21】トピック名は「慰安婦問題における歴史認識問題」です。メルマガ29号で所属確率が上がっています。29号では慰安婦問題における歴史認識について解説されています。
ドンピシャ当たりです。

続いて、【topic_id_27】トピック名は「森友学園における大阪府の対応ミス」です。メルマガ48号、50号で所属確率が上がっています。
48号、50号は森友学園における大阪府の対応ミスについて書かれています。ドンピシャ当たりです。

続いて、【topic_id_28】トピック名は「待機児童問題からみる地方分権の必要性とイギリスEU離脱」です。
メルマガ11号、13号、55号で所属確率が上がっています。
11号はまさに待機児童問題からみる地方分権の必要性がテーマで書かれています。13号はイギリスのEU離脱問題について書いてあります。
55号はこども保険についての解説と待機児童問題について解説しているので、ほぼ当たっています!

続いて、【topic_id_29】トピック名は「NHKドラマ東京裁判」です。
メルマガ36号で所属確率が上がっています。36号ではNHKドラマ東京裁判について解説されています。ドンピシャ当たりです。

続いて、【topic_id_30】トピック名は「豊洲問題と環境水準」です。
メルマガ21〜26号で所属確率が上がっていますね。
ここはまさに2016年豊洲移転問題について連続で解説されていました。ドンピシャで当たりです。
残念なのは27号で所属確率が下がってしまっていますが、27号も豊洲移転問題についてかなり言及されているんです。
この号はもっと所属確率が上がって欲しい、という場合も願い虚しく、下がってしまう場合もあります。
このようにLDAを使えば、文章をトピックに分類したあと、
各メルマガがどのトピックに所属しているか確率を算出する事が出来ます。
LDAのトピックモデルの使い方をお分かり頂けたかと思います。