
GPT4はMITの数学とCSの学位取得レベルの知識を持つ可能性がある

以下の論文が面白そうだったので、概要をななめ読みしてみました。
1.概要
MITの学士号取得に必要な、数学、電気工学、およびコンピューターサイエンスの中間試験、期末試験の 4,550 問の問題と解答の包括的なデータセットを使用。
gpt-3.5はMITカリキュラムの1/3程度しか正解できませんでしたが(これでは落第ですね)、一方、gpt-4は、画像に基づく問題を除けば、すべての問題に正解できる能力が確認されました。(これなら主席卒業できるかもしれませんね!?)
今回の検討で使用したデータセットで、LLaMA-30Bをファインチューニングしたモデルが公開されました。(MIT-LLM / MIT-Licence)
2.評価方法
データセット
データセットは、過去2年分の問題集、中間試験、期末試験から厳選されました。以下が対象となったカリキュラムです。
6-1: 電気科学および工学
6-2: 電気工学およびコンピューター サイエンス
6-3: コンピューター科学および工学
6-4: 人工知能と意思決定
18-1: 一般数学
18-2: 応用数学
18-3: 純粋数学
18-C:数学とコンピューターサイエンス

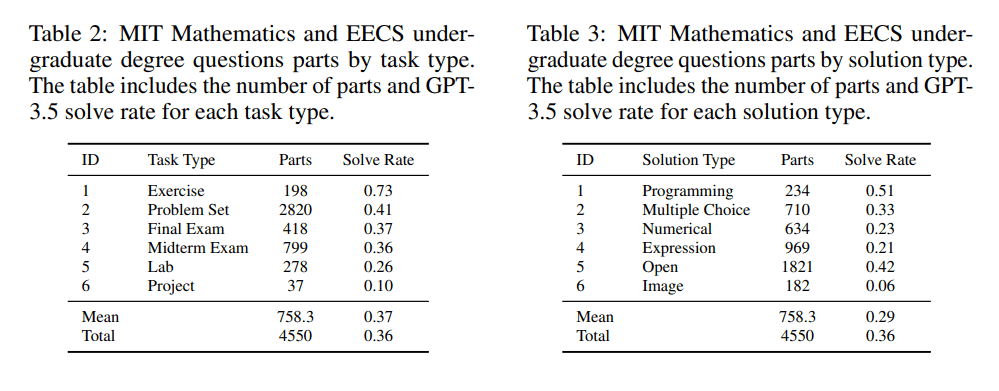
Table3: 解答方法の種類別 右列はgpt-3.5の正解率
ベンチマーク・LLMの公表
データセット公開するとLLMのトレーニングに使用できるため、ベンチマークとしての価値が失われること、その他もろもろの諸事情で生のデータセットは非公表(残念)。そのかわりにデータセットを使用してファインチューニングしたオープンソースLLM(LLaMA)を公表する。ファインチューニングの前後でLLMのパフォーマンスを比較する。
ヒューリスティックの提案(抜粋)
Few-shot学習(FS): コンテキスト内に類似の問題の解答例を示す
Chain-of-Thought(CoT): 段階的に回答するようにプロンプトを工夫
Self-Critique: 自分の解答に対して批評を繰り返して解答を改良する。
Expert Prompting: LLMに専門家として回答を生成させる。(例:あなたは、コンピュータサイエンスと微積分を教えているMITの教授です。)
3.結果

感想
やはりGPT-4の能力は驚異的です。まるで越えられない壁のようですね😅
gpt-4に限らず、FS、CoT、Expertsは自分のプロンプトにも織り込みやすいと思うので、積極的に使っていきたいです。
今後公表される予定の、gpt-4 の画像認識機能を用いて評価すると、どんな結果になるのかも楽しみですね。
ファインチューニングしたLLaMA-30Bと Stable-Vicunna-13Bがほぼ互角で頑張っているというのも地味に興味深いです。
認識の誤りや重要な点の見落としがあれば、コメントでお知らせいただけると幸いです。
現場からは以上です。
この記事が気に入ったらサポートをしてみませんか?