
Real Warld HTTPを読んでみて

最近職場でAWS関連のタスクをこなしているのですが、基礎がなくして、AWSを理解して触ることはできないと思い、基礎固めを行ったいます。
そんな中、職場の先輩(インフラ知識の塊)の先輩からおすすめしていただいたのが、タイトルの書籍できした。自分のout putの為記述していきます。
・HTTPとはどんなプロトコル?
・HTTP headerとはどんなものがあるの?
・HTTP/1.0
・クッキーについて
・認証とセッション
・プロキシー
・キャッシュ
・リファラー
・HTTP/1.1とは
・keep aliveについて
・パイプラインニング
・TLSによる通信の暗号化
・HTTP/2とは
・ストリームとは
・サーバサイドプッシュとは
・ヘッダーの圧縮
・HTTP/3とは
HTTPとはどんなプロトコル?
HTTPはデータを送信するステートレスプロトコルだよ
HTTPとはOSI参照モデルではL7(レイヤー7)での通信プロトコルになります。
歴史的背景としては単純にHTMLを取得する為のプロトコルでした。
HTTPはTCP/IPのレイヤーに乗かっており、このプロトコルがなければ、目的地(クライアントやサーバー)に通信することができません。今回は割愛させていただきます。
HTTPは/0.9から始まり時代の流れに最適化するように改良が進み、テキストだけではなく様々なファイルを通信(静止画、動画、javascrpitプログラムなど、コンピューターで扱えるデータであればなんでも転送できる)できる様に改良が進みました。
そんなHTTPの基本はリクエストとレスポンスからなります。現在もHTTP/3まで改良が進んでいますが、この基本的な仕様は変わりません。
そして、レスポンスとリクエストが終了したら、そこで一旦の通信は終了する為、ステートレスな通信と言えます。
改良が進んでいく中で、リクエストのメソッド、バージョン、ヘッダー、レスポンスのヘッダー、ボディ等が追加されました。
ここまで
・HTTPはデータ転送プロトコル。
・TCP/IPのレイヤーの上にの勝手いる。実際にデータを届けているのはこの レイヤー
・リクエストとレスポンスからなる。
・ステートレスである。
HTTP headerとはどんなものがあるの?
HTTP ヘッダーにより、クライアントやサーバーが HTTP リクエストやレスポンスで追加情報を渡すことができます。
https://developer.mozilla.org/ja/docs/Web/HTTP/Headers
上記引用の通りリクエス、レスポンスの情報が記載されています。headerとは〜と限定的な内容になっていますが、基本的には下記の構成となっています。
・メソッドとパス
・ヘッダー
・ボディ
・ステータスコード

上記画像の概要は
request header
一行目:method/url/ httpバージョン
二行目以降: ヘッダ行
空白をはさんでボディとなります.
response header
一行目 :httpバージョン ステータスコード
二行目以降:ヘッダ行
空白をはさんでボディ取ります
リクエストヘッダ
主なものを紹介します。
かなり情報量が多いので少し割愛させていただきます。
詳しくは https://developer.mozilla.org/ja/docs/Web/HTTP/Headers
Authorization ユーザ認証用データ。
From 要求送信元のメールアドレス
If-Modified-Since ここに指定された日付以降に更新された情報のみを要求
Referer 現在のページを取得する前にいたページURL
User-Agent ブラウザのタイプ、ブラウザ固有のコンテンツを返すと きに有用
Accept MIMEのタイプ
Accept-Charset そのブラウザが期待する文字セット
Accept-Encoding そのブラウザがデコードできるデータのエンコーディン グ。
Accept-Language そのブラウザが予期している言語。サーバが多国語に対
応しているときなどに使う。
Host サーバーのドメイン名 (バーチャルホスト向け) および
サーバーが待ち受けている TCP ポート番号 (省略可能)
を指定します。
ETag 一意な文字列であり、リソースのバージョンを識別し ます
If-Match リクエストを条件付きにして、保存されたリソースが指 定した ETag のいずれかに一致する場合に限りメソッド
を適用します。
レスポンスヘッダ
主なものは下記になります
Server ウェブサーバの名前とバージョン情報。
Date 現在の日付(グリニッジ標準時)
Last-Modified リソースの更新日
Content-Length 出力のバイト単位の長さ。バイナリデータも含みます。
Content-Type 出力のMIMEタイプ
Expires リソースの有効期限
Location ページのリダイレクト先の URL を示します。
WWW-Authenticate 認証に必要なユーザー名やパスワードなどの情報が含
まれます。
Set-Cookie サーバサーバーからユーザーエージェントにクッキーを送
信します
Etag キャッシュに使う
Cache-Control HTTP のヘッダーで、リクエストとレスポンスの両方で
キャッシュのためのディレクティブ (指示) が格納されてい
ます。
status code
status code
情報レスポンス (100–199),
成功レスポンス (200–299),
リダイレクト (300–399),
クライアントエラー (400–499),
サーバエラー (500–599)
ざっくりとして一覧ですreal warld HTTPで紹介されている項目をピックアップしていきます。
クッキーついて
実務経験者であれば、愚問の内容かと思います。
クッキーはウェブサイトの情報をブラウザー側(localstrage)で保存する仕組みです。
状態をuserの認証状態と言った状態管理を行う為に行います。
初回レスポンス時Set-Cookieを用いてサーバー側の情報をkey=value形式で送信します。
それを受けっとクライアントは受けっとたkey=valueをCookieを用いて返却します
//レスポンスヘッダ
Set-Cookie: key=value
2回目のリクエストヘッダ
Cookie: key=valueクッキーはクライアント側で保持してもらうため、シークレットモードでそもそもクッキー保存が拒否される場合やセッション終了時にリセットされることがあり、永続性にかけます。また、検証モードから、conosle.logでdocument.cookieと入力すると簡単に値を取得することができます。その為セキュリティ面でも問題があります。状態管理という点では適した仕様ですが、こういった側面もあります。
なので、cookieを仕様する場合は「認証した」という記録や消えても問題ない情報だけを格納します。
cookieには制約をかけることもできます
Secure属性 https接続じゃないとクライアントからサーバーへcookieを
送信しない。DNSハッキングを防ぐため
httpOnly属性 javascripエンジンからクッキーを隠す。参照できないように
する
Set-Cookie: Secure; HttpOnly
認証とセッション
一般的なwebサービスが何かしらloginして認証します。
認証には歴史的にBasic認証とDigest認証(user名、passwardを用いた)の2種類があります。
・Basic認証
HTTPの認証方法。user名、passwordをbase64でエンコードした認証方式。
サーバー側でデコードする。
SSL/TLS通信を行なっていない通信だと、このuser名passwordが簡単に漏出してしまします。
下記のようにヘッダが付与される
Authorization: "Basic xxxxx"・Digest認証
Basic認証より強固な認証。ハッシュ関数を用いいて暗号化していきます。
ハッシュ関数(MD5)は割愛させてもらいます。
とここまでhttpでの認証方式を説明しましたが、現在は両方とも使用されていないです。これらの認証はwebサーバーに設定する為、明示的にログオフもできないですしログイン画面もカスタマイズできません。それにログインした端末の識別ができないからです。
現在使われているのがフォームを使ったログインとクッキーを使ったセッション管理の組み合わせです。
・クッキーを用いたセッション管理
フォームからpassword等を送信してAPサーバー側で認証を行います。問題がなければ、セッショントークン(認証したという記録)を発行してクッキーとしてクライアントに送信します。
セッショントークンは NoSqlで管理保存しておきます。
このセッショントークンを投げ返してもらうことで認証状態を確認します。
ここで注意が必要なのがフォーム送信しているので内容が参照されるリスクがあります。なのでSSL/TLS通信は必須になります。
プロキシ
プロキシはHTTPなどの通信を中継する仕組みです。
中継するだけではなく、さまざまな用途で活躍します。
1、コンテンツのキャッシュ
2、ファイヤーウォールの役割
3、コンテンツの圧縮やフィルタリング
クライアントの代わりにプロキシーサーバーがリクエストを投げてくれる。
用途にもよりますがnginxはプロキシです。もちろんリバースプロキシとしても動作します。基本的にphp rubyで見られるフロントで構えているやつです。awsのELBはnginxが裏で動いてます。(この場合L4スイッチかな)

キャッシュ
HTTPではキャッシュの支持するヘッダがあります。キャッシュの歴史は日付から始まりましたが、それではコンテンツのキャッシュコントロールが難しいこともあってETagが追加しました。Etagはファイルに特有のハッシュ値を使用してキャッシュします。if-None-MatchヘッダにダウンロードしたEtagをつけてリクエストします。それを読みっとサーバーが304 Not Modifiedとレスポンスされる。
Etagが追加された頃と同時に追加されたのが、chache-controlヘッダです。
public コンテンツを複数ユーザー間でキャッシュを利用する
private キャッシュコンテツを複数ユーザー間で共有しない。
ユーザーごとにキャッシュを適用
max-age=n キャッシュの鮮度を秒単位で設定。86400sで1日
s-maxage=n max-ageと同等。共有キャッシュに対する設定値
no-cache キャッシュが有効か毎回サーバーに問い合わせる
no-store キャッシュしない
リファラー
ユーザーがどの経路からwebサイトに到達したかをサーバーが把握するためにクライアントが送信するヘッダです。元場所がわかります
refere: https://www.example.com/link/limk.htmlHTTP /1.1とは
http/1.0の改良バージョンだよ。1.0より高速化を狙って色々機能がup dataしました。変更内容は
通信の高速化
- keep ariveがdefaultで有効
- パイプライニング 実装
TLSによる暗号化通信のサポート
新メソッドの追加
- PUT DELETメソッドの必須
- OPTION TRACE CONNECTの追加
Keep arrive
TCP/IPの通信効率を上げる仕組み。TCPに夜3ハンドコネクション(TLSもコネクションのやりとりをする)、そしてHTTPによるステートレス通信これらがもたらす弊害としては、毎回コネクションするタイミングで3ハンドコネクションを行ってしまうことです。これが通信のボトルネックなり、これを改善するためにコネクションを張りっぱなしにて3ハンドコネクションの回数を減らす。これがkeep arriveです。
//request head
connection: keep arriveこれで有効になります。keep arriveを終了するには
//クライアント、サーバーどちらかが
connection: close実際は通信がサーバーが確実に終わるっていることを判断するの難しいため、time outで判断している様です。
サーバーのデフォルトのタイムアウト時間
nginx: 75秒
apache:12秒
パイプライニング
通信の効率化の改善を行うために実装されました。
keep arriveが必須になります。
本来なら、リクエスがありレスポンスで一つの通信が終了しますが、パイプラインニングをしることで1回目のリクエスを行った際にレスポンスが帰ってくる前に次のリクエスを送ります。これによって通信のボトルネックを解消しようとしましたが、結果として対応していないwebサーバーがあったりと実際には使用はされていませんでした。ですが、このパイプライニングがHTTP/2のストリームの基盤になっています。

TLSによる暗号化通信
TLS = 共通鍵方式 + 公開鍵方式を用いた暗号化通信
TLSは通信を暗号化する仕組みです。公開鍵方式を使用して通信を行います。具体的な流れはtcpコネクションの後に、TLSコネクションを行ってサーバー側から、公開鍵と認証局が発行してサーバー証明書をクライアントに渡します。
この際に共通鍵を生成します。共通鍵でデータを暗号化し、さらに暗号化したものを公開鍵で暗号化(鍵の鍵)します。
サーバー側では秘密鍵でまず複合化を行い、その後共通鍵でデータの複合化を行います。
なお、通信規格HTTPSとなり、portは443となります。
公開鍵方式のイメージ
なかなかイメージすることが難しいと思いますが、
公開鍵は南京錠のイメージで秘密鍵は南京錠の鍵のイメージ。
南京錠でデータを暗号化して、その鍵でデータを複合化するイメージです。
XMLHttpRequest
jsからhttp通信を行うAPI。簡単にいうとブラウザーからサーバーとHTTPリクエスとを行う仕組み。レスポンスデータはjsonとして受け取る。現在jsで推奨されているのはfetch
JavaScriptなどのウェブブラウザ搭載のスクリプト言語でサーバとのHTTP通信を行うための、組み込みオブジェクト(API)である。すでに読み込んだページからさらにHTTPリクエストを発することができ、ページ遷移することなしにデータを送受信できるAjaxの基幹技術である。
HTTP/2とは
HTTP/1.1から16年後にアップグレードされたもの。基本的にHTTP/1.1の機能を継承しつつ、ストリーム、サーバーサイドプッシュ、ヘッダーの圧縮機能が追加されました。
ストリームで行っていること
HTTP/1.1のパイプライニングが抱えていた問題としてholブロッキングがありました。それを解消するため、ストリームが考案されました。
ストリームはストリームという単位で通信を行い、ストリームで送るデータを(HTTPメッセージ)フレームという。このフレームをストリーム内で直列で送信し、あたかも並列送信しているかのように見せている。
ストリーム
HTTP/2では1つのTCP接続内部に複数のストリームという仮想TCPソケットを作って通信します。ストリームはフレームに付随するフラグ(処理を識別するID)で簡単に作成したり、閉じたりすることができます。ストリームに識別子(stream indentifer)があります。直列でデータを送っているが複数のストリームがあるので並列で送信しているように見える。

フレーム
http/2通信の最小単位。http/1.1ではテキスト形式でしたが、http/2ではバイナリー形式に変換し通信をします。フレームは10種類のフレームタイプがあり通信の用途でフレームタイプが違います。またフレームはストリームIDを持っています。これによってどのストリームのフレームなのかが識別ができデータの整合性を保つことができます。(フレーム絶対を総括してみたさい各フレームはバラバラに送られるので、ストリームIDを元にデータの順番が正しいかcheckし並び替える。)
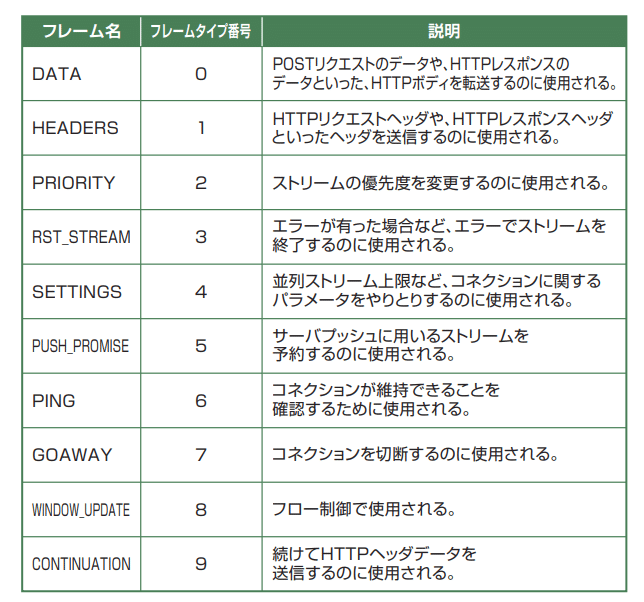
ストリームの優先順位
ストリームは1~ 256の整数のweightをつけることができ、このweightを元の依存関係を定義し優先順位を割り当てます。
サーバープッシュ
サーバープッシュは優先度が高いコンテンツをクライアントから要求される前に送信する機能です。実際はクライアントがrequestがないとクライアントは検知できません。
重要度の高いコンテンツはサーバーからpushしてキャッシュ(queueに貯めておく)することで、初回リクエスト時に高速にコンテンツを取得できるという仕組みです。
ヘッダーの圧縮
HTTP/1.xではテキストデータを送っていたため、ヘッダーの容量も大きかった。特にHTTP Cookie が使用されている場合はキロバイト以上にのぼることもあります。そこでHTTP/2ではHPACK 圧縮形式を用いいてヘッダーの圧縮を行っています。
ここまでで
ここまでHTTP/1.1が抱えていた問題が改善されたと考えられました。ですが、問題がありました。TCPが持っている機能でパケットロスした時に起こる再送処理、パケットの整合性を保つために順番の入れ替えなど、これらの機能により通信処理は止まっていました。その為googleは新たなプロトコルの作成を検討しましたが、TCPは全世界に広がり、TCPの変更は全世界の通信機器を変更しないという事実がありました。そこで考えたgoogleはTCPの代わりにUDPを用いて新たなプロトコルを作成することとなりました。
(実際にはUDPに機能を追加ついかしていく。)UDPであれば、パケットの再送や順番の入れ替えなどの機能はない為です。しかも全世界のネットワーク機器は機能を追加しただけで中身はUDPと認識してくれるため、実用的でした。
HTTP/3とは
先程の章で話した通り、HTTP/3はHTTP/2で抱えた問題を解決する為に作られました。L3レイヤーでベースとなっているプロトコルはQUICというプロトコルです。中身はUDPであり、そこにデフォルトにTLSが実装されてます。QUICはパケロスがあったても、TCPと同じでパケットの再送は行われます。TCPと何が違うかというと、パケロスして再送はするが他のパケット送信処理は止まらないという点です。これによってHoLブロッキングを予防します。さらに各種ハンドシェイクを一回に抑えてオーバーヘッドを無くしました。
さらに、HTTP/2で行っていたストリームもたQUICに取り込まれました。
そこでHTTP/2のストリームと少し違う点はQUIC Connection IDをストリームの識別子としている点です。
TCPベースだと、ユーザーが同じでも、端末を変えてIPが変わるとコネクションが切れます。QUICの場合がQUIC Connection IDによって識別するので端末が変わってもきコネクションは切れません。
HTTP/3は基本的にはHTTP/2と変わりません。何が違うかQUICとTCPの違いです。
終わりに
正直勉強不足でまだまだ、本記事に追加していかないと行けないとこは多々あると思います。学習を進める中で本記事もupdateしていきます!
この記事が気に入ったらサポートをしてみませんか?