MYCOEIROINK作成を自前PCのGPUで行う方法(WINDOWS限定)

初ノート書きとなりますので、いろいろ不備があればなんかこうなぁなぁに流してください。
前提
本記事は、シロワニさん 様の運営・配布されているフリーソフト「COEIROINK」の機能の一部であり、利用者が声の収録を行うことで「自分の声で喋るテキスト読み上げ音声合成」を作ることのできるサービス「MYCOEIROINK」を作る際に必要となるGoogle Colaboratory(以下colab)が使用不可になった場合の緊急手段として用意したものであり、最低限VRAM(RAMメモリでは無い)が12GB以上搭載されているかつ、AI学習に使用される「Tensorコア」が最新の「NVIDIA製GPU」が自身のPCに組み込まれていることが必要最低限となる。(VRAMの確認方法は後程紹介)
MYCOEIROINKの作り方は詳しく説明してる動画があるので、拙作ではあるけど良かったらコレ見てね。
完璧なモデルよりも簡単に、インスタントにとりあえず作ってみたい!
という方は、青トキエさんがキャラクターと茶番劇付きの動画を出してくださってるのでこちらをどうぞ。(動画の方法だと疑問文非対応のモデルになりますが速く出来る!)
最後まで見ることをお勧めします。笑えるぞ。
こっちは宣伝だけど私も音源になってるよ。
配布ページとか宣伝動画も是非見てください。
「どんなものができるのか」を確認するのにちょうどいいかも。

なお、私にはプログラミング言語を理解する脳はないため、多方面からの情報などを集めてごちゃごちゃやったらなんかできた!共有するね!のスタンスです。
個々の環境問題やできなかった!なんで!?には答えられませんので悪しからず。
はじめに
メリットとデメリットを先に明確にしておこう。
メリットに「出来ること」はたくさん書くが、今回紹介するのは必要最低限。もしメリットのすべてを享受したいという人がいれば直接聞きに来てください。もしくは何となく察してやってみて。
1対1での通話が無理なタイプなので、グループ通話にいるときにでも突撃すればいいかも。よくこのサーバーに出没するぞ。
MYCOEIROINKについてのアレコレもよく話題に出るサーバーです。
メリット
性能の良いGPUであれば、PRO+課金以上のスピードで学習できる。
時間ごとに繋ぎなおしたり、切られたりすることがない。
事前モデルを自由に変更できる。(公式用意話者三名以外を設定できる)
学習上限を変更できる。(epoch数の限界突破やepoch毎の学習量変更)
必須であった「音声の前処理」を実質スキップできる。(自動ノーマライズなどの無効化)
今回紹介する方法ではコードを書く・変更する必要がほぼない。
デメリット
GPUに負荷を与えることになる。
Gドライブと違い、版やゴミ箱の保存・バックアップ機能がないため、epochファイルの自動削除が行われると取り出しができない。エラーによるチェックポイント不良の際も前版からのやり直しができず、最初からやり直しとなる。(エポックファイルの自動削除については解決法を後述)
学習を回している間、最低でもVRAM使用率が12GB占領されるため、GPUを使用するゲームが学習進行中はほぼできない。
電気代ヤバい。
部屋が暑い。
GPUの確認
GPUに実装されているVRAMを確認しておこう。
タスクバーを右クリックし「タスクマネージャー」を開く(ctrl+shift+escでも出せる)
「パフォーマンス」タブより「GPU」を選択、「専用GPUメモリ」が実装されているVRAMの量になる。(共有GPUメモリでは無い。RAMメモリ量でもない。基本的に24GBを超えることは無い。200万クラスの学習用GPUを除けば。)
Tensorコアについては調べないとわからないため、各自でコア数や世代については調べてほしい。
コアの世代的に、最低限RTX3060が欲しいところ、(4060Tiの16GBがコスパ的に理想かもしれない。)
それでは簡単に環境を構築していきましょう。
PCへいろいろインストールが必要となりますので、ある程度の空き容量は確保しておきましょう。サブSSD1TB程度(の中に空き容量200GB程度)あれば安心です
VRAM12GB以下のGPUを使用する場合
遊牧家族 様 によりRTX 2060 SUPER(TM)(RAM 8 GBでの学習方法が紹介されています。
VRAM12GB以下での学習方法はもちろん、ノートブックに割り当てるメモリ量の変更や、一度ホストランタイムを通さず学習する(Gドライブを一度も通さずPC内のドライブだけで完結させる(実際にMYCOEIROINKを作る1~4が必要なくなる。))方法なども紹介されています。
https://voskey.icalo.net/@yuuboku/pages/1709213090852
下準備
エクスプローラー→表示→表示→ファイル名拡張子
にチェックを付け、「.txt」「.yml」などが見えるようにしておいてください。
拡張子が隠れたままだと「docker-compose.yml」をtxtから作る際、「docker-compose.yml.txt」などになる可能性があります。
ローカル環境構築
1,WSLのインストール
Windowsで動作するLinux環境らしい。知らんけど。
Windows PowerShellなどで以下コードを実行するだけでインストールされる。Cドライブ上で実行するといいかも。
wsl --install2,Docker Desktopの用意
PCとcolabをつなぐための橋らしい。知らんけど。
公式ページに飛び、左上のProducts→Download for Windows
DLしたファイルを実行し、実行環境をWSLに設定(多分デフォルトでなってる)してインストールしておく。
このあたりで一度PCの再起動を挟むこと。必須です。
3,Gドライブの代わりとなるフォルダを準備
適当な場所(空き容量をかなり食うのでDドライブなど)に適当な名前でフォルダを作る。(書き込み許可があるものがよい)
今回は参考にさせていただいているページの通り、「colab-runtime」としておく。
4,起動ファイルの準備
上で作成したフォルダ「colab-runtime」の内部に「docker-compose.yml」という名前でファイルを作成する。編集の際はメモ帳なり好きなものを使うといい。
内部に以下のコードをペーストする。
version: "3"
services:
colab:
image: asia-docker.pkg.dev/colab-images/public/runtime
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
ports:
- "127.0.0.1:9000:8080"
- "0.0.0.0:7860:7860"
environment:
- JUPYTER_TOKEN=111111111
volumes:
- ./content:/content
- ./cache:/root/.cacheペーストできたら
- JUPYTER_TOKEN=111111111
の9桁の数字を任意の数字に書き換えておく。(9桁のまま)
書き替えないと他人のものと被るかもしれないのでなるべくオリジナリティのあるものにしよう。
こちらも別の用途にコーディングされたものをそのまま使用させていただいているもので、最後の行などは必要ないかもしれない。(キャッシュフォルダなのだがMYCOE作成では使用されない)
5,起動ファイルを起動するバッチを作成
適当な名前でメモ帳を作る。「起動.txt」などでいい。
内部に以下のコードをペースト。
docker-compose up -d保存したら、ファイルの拡張子を「txt」から「bat」に変更、警告が出てもスルーしよう。
6,実際にcolabに接続してみる。
2でインストールしたDocker Desktopを起動し、5で作ったbatファイルを起動する。
初回起動ではかなりの時間がかかり、20GB以上の前提ファイルがインストールされるため、暫く待つ。
終わると自動的にCMD(コマンドプロンプト)が閉じるはず。
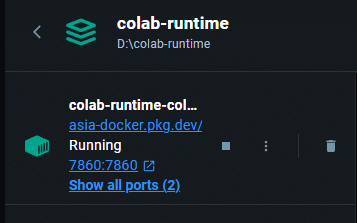
Dockerに次のような欄が追加されていたらいい。
初回起動でこれが出ない場合はもう一度起動batを起動してみるといい。
7,ColabとDockerを接続
実際にCOEIROINK公式のMYCOEIROINK作成ページの「MYCOEIROINKを作る」からノートブックを起動。
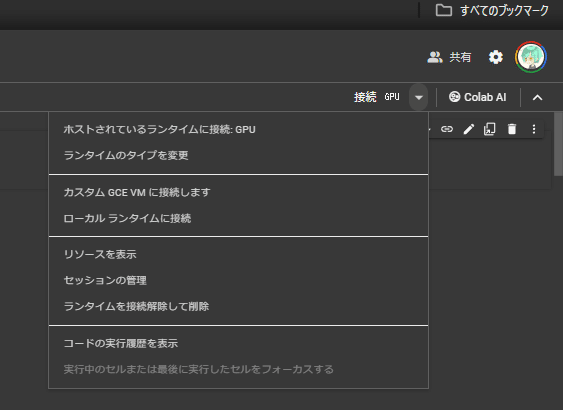
右上の「接続」右にある▽から「ローカル ランタイムに接続」
出てくるURL入力欄に「http://localhost:9000/?token=111111111」を入力(111111111は4で書き換えた数字に書き換える。)
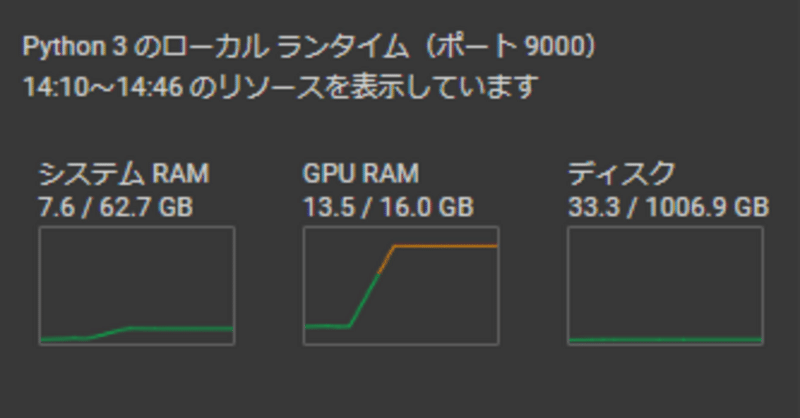
接続に成功すると以下のように三つのグラフが出てくる。
これで接続は成功だ。
今後また繋ぎたいときは6,7を再度行うといい。
実際にMYCOEIROINKを作る
これで接続できたからいつも通り行けるやろ!
と思い、ノートブックのコードを上から順に実行していくと、なぜかうまくいかない。
とりあえず下準備のため、一旦接続を切っておこう。
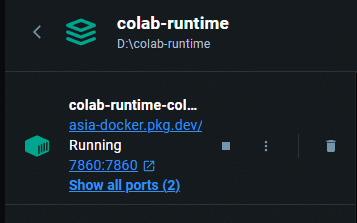
Dockerで下の画像の箇所にあるゴミ箱を押せば接続が切れる。
まず事前準備が必要となる。以下簡単な手順だ。
前提条件として、最低限ノートブックをちゃんと読めることがある。
実行するための手順などはノートブックをちゃんと読もう。
1,ノートブックをホストランタイムに繋ぎなおす。
ローカルランタイムに繋ぐ時と同じ手順で接続→ホストされているランタイムに接続(今回の手順ではGPUが必要ないため、ランタイムタイプはCPUでも構わない。)
2,ノートブックを「最後以外」すべて実行する。
Googleドライブのマウント~モデルの作成のための環境構築3
まで、ノートブックの指示に従いながら実行する。
さいごを実行しても問題ないがその際はGPUランタイムが必要になる。
自前GPUが弱い場合、こちらで回せるだけ学習を回しておいても良い。
ここで起こったエラーなどは管轄外なので開発者さんにお伝えくだされ。
3,Gドライブにある「MYCOEIROINK_WORK」をDLする。
2の手順が終わったことを確認した後にマイドライブにある「MYCOEIROINK_WORK」をダウンロードする。
この時点でのサイズは1GB程度のため、ファイルは1つでDLされるはずだ。
もしローカル以外…Colabのホストで何epochかモデルが生成されていたら2つ程度に分けてDLされるかもしれない。解凍後すべて統合すれば問題ない。
解凍したファイルの中にある「MYCOEIROINK_WORK」をコピーか切り取りしておく。(一応「MYCOEIROINK_WORK」の中が下の画像のようになっていることを確認する。)

4,「MYCOEIROINK_WORK」を指定の場所へ移動する。
ローカル環境構築3で作った「colab-runtime」から、
colab-runtime→content→drive→MyDrive
へと移動し、MyDriveの内部に3でコピーした「MYCOEIROINK_WORK」を張り付ける。
5,epochファイルの自動削除機能を切る(任意)
colab-runtime\content\espnet\egs2\mycoe\tts1\conf
の中にある、「finetune.yaml」をメモ帳などで開く。
最後の方に以下のような項目がある。
##########################################################
# OTHER TRAINING SETTING #
##########################################################
num_iters_per_epoch: 1000 # number of iterations per epoch
max_epoch: 100 # number of epochs
accum_grad: 1 # gradient accuulation
batch_bins: 10000000 # batch bins (feats_type=raw)
batch_type: numel # how to make batch
grad_clip: -1 # gradient clipping norm
grad_noise: false # whether to use gradient noise injection
sort_in_batch: descending # how to sort data in making batch
sort_batch: descending # how to sort created batches
num_workers: 4 # number of workers of data loader
use_amp: false # whether to use pytorch amp
log_interval: 50 # log interval in iterations
keep_nbest_models: 10 # number of models to keep
num_att_plot: 3 # number of attention figures to be saved in every check
seed: 777 # random seed number
patience: null # patience for early stopping
unused_parameters: true # needed for multi gpu case
best_model_criterion: # criterion to save the best models
- - train
- total_count
- max
cudnn_deterministic: false # setting to false accelerates the training speed but makes it non-deterministic
# in the case of GAN-TTS training, we strongly recommend setting to false
cudnn_benchmark: false # setting to true might acdelerate the training speed but sometimes decrease it
# therefore, we set to false as a default (recommend trying both cases)
keep_nbest_models: 10
という項目を任意の数に書き換えておく。
100にしておけば1~100までエポックファイルが削除されることなく保持される。その場合は35GBほどになるため容量に余裕がなかったり、100以外は必要ない、という場合は少なめに設定しておくといい。
なお、ここでいう削除は「完全な削除」であり、自動削除ではPC側のエクスプローラーゴミ箱に入ることはないため注意。
多分どっかをコーディングしなおせばGドライブのゴミ箱みたいなのは作れると思う。
5.5, 前回使ったデータを削除する。(2回目以降のローカル学習の場合のみ)(追記)
少しつまずいたので追記しておく。「colab-runtime\content\espnet\egs2\mycoe\tts1\downloads\wavs」内にあるwavファイル群は、ノートブック内の音声前処理を行った後の、実際に学習で使うwavファイルなのだが、ここを学習時に毎回downloadsフォルダごと消しておくことをお勧めしておく。
というのも、例えば全文収録(652文)したものを学習した後、そのファイルたちは学習を行うとここに移動、終了後も残ることになるのだが、次回以降の学習をする際、前回同様全文収録であれば「同じ名前のファイルがある!上書きするぜ!」と自動的な処理を行ってくれるが、前回と違いITAのみ(424文)だった利すると、「同じ名前のファイルがある!上書きするぜ!」でITAだけが上書きされてしまい、前回分のMANAコーパス分はそのまま残り、1回目のMANAと二回目のITAで混ざることになる。
ここで紹介する方法はGドライブでの学習を挟んでおり、ホストランタイムでの学習準備の際、「今回使うWAVファイルのリストはこれやで」と、リストを作ってくれるらしいのだが、そのあとローカルに持って行った際、前回分のWAVが残っているため、「リストにない音声あるやんけ!」と、学習を中断してしまうわけだ。
毎回全文収録ならば問題はないのだが、スタイルによって収録量を変えている者共は気を付けておこう。
というかちょっと前までは学習のたびにリセットしてくれていたはずだから、環境が変わったとかおま環だったりするのかもしれない。
「学習スタートがすぐ終わるんだけど!」という場合はここの手順を取ってみるといいかもしれない。
6,ローカルランタイムで学習を開始する。
接続時と同じ手順で一旦ホストランタイムを切断。(ランタイムを接続解除して削除)
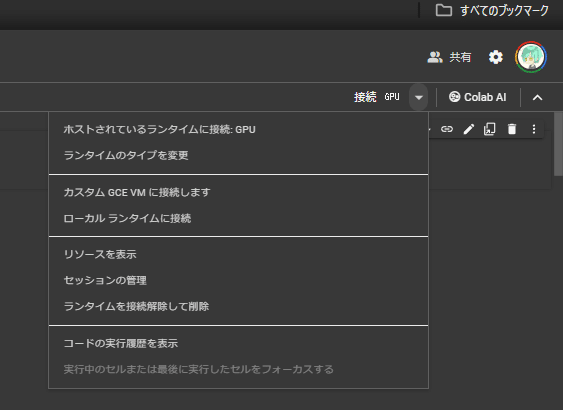
切断出来たらローカル環境構築6,7の手順でもう一度ローカルランタイムに接続。
ここまでくればあとはノートブックを、一番上の「Googleドライブのマウント」だけを除き、上から「モデルの学習スタート」までを実行し、右上のグラフの「GPU RAM」が上がり始めて安定すれば学習は開始されているはずです。
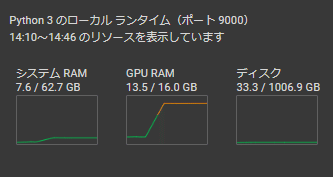
colab-runtime\content\drive\MyDrive\MYCOEIROINK_WORK\
exp\tts_mycoe_model
に、徐々にepochファイルが書き出されていくためしばらく待って確認しよう。
参考としてRTX3060(12GBモデル)であれば18分、RTX4080(16GB)であれば7分に一つ程度だ。A100とかH100、colabで使えば4080と同じ程度だけどローカルで使えばもっと早いんじゃないか疑惑が出てくる。1分に1epochとか作れそうだね。怖いね。
Tensorコアの実装数で必要時間変わるのかな?知らんけど。
上のGPU以上でepochファイルが「モデルの学習スタート」から20分程度かかる場合は一旦切って繋ぎなおし、また上から実行してみるといいかもしれない。
回線の不調とかあると切れちまうので注意。
以上。あとは完成まで放置!
おまけ1:ローカル学習応用編
⑤で紹介した「finetune.yaml」の内容を書き換えることにより、いろんなことができるようになる。大まかにできることを紹介する。
PCへの負荷とか、公式の想定していない作成方法とか、いろいろあるので自己責任でお願いします。(一応ここに書いてあることはシロワニさんに許可を取っていますが、何かあっても責任はすべてご自身で取りましょう。)
##########################################################
# OTHER TRAINING SETTING #
##########################################################
num_iters_per_epoch: 1000 # number of iterations per epoch
max_epoch: 100 # number of epochs
accum_grad: 1 # gradient accuulation
batch_bins: 10000000 # batch bins (feats_type=raw)
batch_type: numel # how to make batch
grad_clip: -1 # gradient clipping norm
grad_noise: false # whether to use gradient noise injection
sort_in_batch: descending # how to sort data in making batch
sort_batch: descending # how to sort created batches
num_workers: 4 # number of workers of data loader
use_amp: false # whether to use pytorch amp
log_interval: 50 # log interval in iterations
keep_nbest_models: 10 # number of models to keep
num_att_plot: 3 # number of attention figures to be saved in every check
seed: 777 # random seed number
patience: null # patience for early stopping
unused_parameters: true # needed for multi gpu case
best_model_criterion: # criterion to save the best models
- - train
- total_count
- max
cudnn_deterministic: false # setting to false accelerates the training speed but makes it non-deterministic
# in the case of GAN-TTS training, we strongly recommend setting to false
cudnn_benchmark: false # setting to true might acdelerate the training speed but sometimes decrease it
# therefore, we set to false as a default (recommend trying both cases)max_epoch: 100:ここの数字を変えることでepoch上限を突破可能。
batch_bins: 10000000:ここの数字を変えることで1epochあたりの学習量を変更できる。(増やすと学習時に使うVRAMの量が増える。減らすも同義)
cudnn_benchmark: false:trueに変えることで学習が速くなる可能性がある。変わらなかったり遅くなる可能性もある。
seed: 777:いわゆるシード値。ここを適当に変えると同じ音声でも出力結果の違うモデルができる。(未確認、自己責任。)
colab-runtime\content\espnet\egs2\mycoe\tts1\downloads
の内部のデータを入れ替えることにより、事前モデルや学習中の音声を変更することができる。
「wavs」=ノートブックで音声の前処理を行った後のファイルとなる。
音声の前処理は、処理以外にも「どのファイルがあるか」の確認が含まれるためスキップができず、処理が必須となっているが、こちらを処理前のwavに入れ替えることで実質的な回避が可能になる。(音声の前処理時に検出されたファイル数から数を変えないこと。)
「100epoch」=事前モデルのモデルファイル。別のモデルのepochファイルに切り替えることで、公式から用意された3種以外のモデルファイルが使用可能。(未確認。自己責任)
なお、ノートブックの規約を確認すると
「このコード内でCOEIROINK提供でない事前学習モデルを使う行為は禁止です(「自身で作成したMYCOEIROINKを事前学習モデルに使うことは例外的に許可しています。」)
MYCOEIROINKを機械学習用の事前学習モデルとして配布するのは禁止です
との記載があるため、行う場合は「自身で作ったモデルのみ」が原則となり、自分以外のモデルであれば例え「モデル作者より明確に事前学習モデルに使ってよいと許可を得たモデル」であっても基本的には作成禁止となる。
そして、自分の作ったモデルを「事前学習に使ってもいいよ!」といったような配布をすることも禁止となる。
もし「この方法であれば使ってよいか」などの疑問がある場合、独断で作成に走る前に開発者であるシロワニさんに質問を行うこと。
例外となる作業を行うときは必ずノートブックにある規約などをしっかりと読み込むこと。
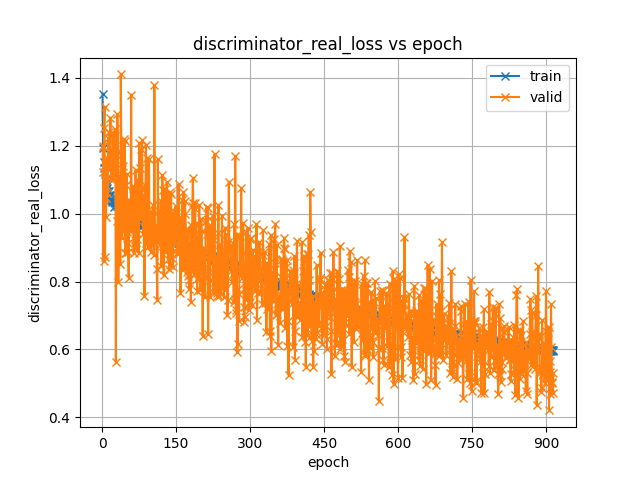
おまけ2:テンサーボードを見る
ちょっと前はいろいろ書いていたのだけれど、現在のCOEIROINKではテンサーボードを見ても過学習などは判別ができないようで、確認する意味はほとんどないらしい。
一般的にtrainは学習に使用したデータを指し、validは学習に使用していない音声データを指すらしい。(シロワニさんより。というか以下はほとんどシロワニさんの言葉そのまま引用)
しかし、MYCOEIROINK学習の環境では「validの中身はtrainの先頭か末尾の5つのデータを流用している」とのこと。
(データはすべて使いたかったがvalidを未設定にすることが不可能だったためこの処置をとっているらしい。)
つまり、「trainのlossが下がっているにもかかわらずvalidのlossが上がると過学習」という判定は、「本来学習に使われないvalidのデータも学習に使用している」現在の状況では、テンサーボードを見て過学習を検出することができないらしい。
私は以前書いたように、「generator_lossが上がっていくと過学習のため、ガクッと下がったポイントを狙って取る」が正しいと、他の音声合成を作成した時の感覚で述べていたのだけれど、シロワニさんによれば
「学習では、全体のlossを下げる方向に動くため、generator_lossが上がったとしても、全体のlossが下がっていれば良いという考えで進んでいく。 よって過学習でグラフが上昇しているわけではない。 たまにガクッとgenerator_lossが下がるのは、全体のlossを下げる動きの途中、たまたまgenerator_lossがタイミングあっただけと思われる。」
「グラフのlossから見れるのは「全体のlossが下がっているということは学習が進んでいる」ということだけで「過学習しているかどうかは判断できない」(ちゃんとしたvalidデータが設定されていないため)」
とのことだった。つまり、テンサーボード全体を見て、極端にlossが右肩上がりになっているものがなければ問題がない、ということだけ確認すればよいのかもしれない。
generator_loss以外が下がり続ける限りは学習を回し続けてもいい、ということでもある?
他にも専門的な知識があれば、何か読み取れるのかもしれないが、まぁ一般的に「MYCOEIROINKを作る際にはテンサーボードは必要ない」とされる。
それでもなんかいい感じのグラフを見たいとか、明確な目的があってテンサーボードを確認したいときは以下を使えばいいと思うよ!!

テンサーボードを使える簡単なノートブックが見つからなかったため、いろんな場所から知識をお借りしてテンサーボードを見るためだけのcolabノートブックを作っておいた。
使用方法はノートブック内に書いておいたのでそちらを参照してほしい。
実験に協力してくれた協力者/被検体/モルモットさんに感謝申し上げます。

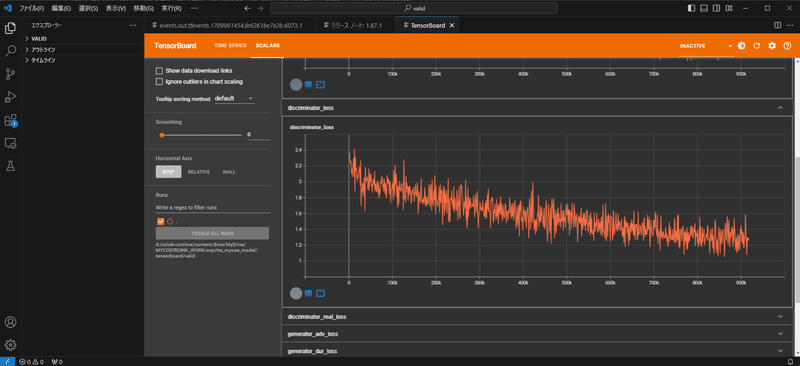
Colabを使わないテンサーボードの確認方法
visual studio codeの拡張機能Tensor boardを使用すればPCの内部だけでテンサーボードを確認できる。
利点としては、ホストランタイムで学習を回しているとき、一度ランタイムを切ることなくテンサーボードの確認ができることだ。
visual studio codeにTensor boardをインストールし、F1キーでコマンドパレットを開き、「Python: Launch Tensorboard」と入力すると、いくつかの機能が「この機能が足りないからインストールしろ」と表示される。
それをすべてインストールした後、改めてF1→「Python: Launch Tensorboard」でテンサーボードを起動すると、参照するテンサーボードの格納位置を選択しろと言われる。(フォルダを選択)
ローカル学習中であれば
”colab-runtime\content\drive\MyDrive\MYCOEIROINK_WORK\exp\tts_mycoe_model\tensorboard\valid(またはtrain)”を選択。
ホストランタイムでの学習であればGドライブの"MYCOEIROINK_WORK\exp\tts_mycoe_model\tensorboard\valid(またはtrain)"をDLし任意の位置へ置き、その位置を選択する。
こうすることでColabを通さずテンサーボードが表示される。
(情報提供:遊牧家族さん)
最後に
ハイお疲れ。解散解散…
ってな感じで、以上が簡単な方法です。
VRAM12GBが最低ライン、という時点で振り落とされる人もまだまだ多いのかな。PC、なかなか買い替えできないもんね。わかるぞ…
でも正直学習が速すぎても収録が追い付かなくなるので、RTX4090とか高望みはしなくてもいいです。4060Ti16GBモデルあたりに頑張ってもらいましょ。
弊環境は4080で回しておりますが、100epoch11時間程度なので一日に2スタイル分収録しなきゃ追いつけません。無理。
なので他の方の音声処理を承ると同時に、空いてれば学習も回そうか、とかやってます。(電気代タダじゃないのでここやるかは要相談)
良い環境持ってる人はそれこそ他人の音声の学習代行依頼なんかも受けれるだろうけど、それでお金をもらったりする場合は規約うんぬんあるだろうからシロワニさんに連絡を取って確認した方がいいかも。
後々トラブルにならないように注意しようね。お兄さんとの約束です。
追記:シロワニさんから「ローカル学習の学習代行依頼で料金を取ることは可能です。ただし自己責任でお願いします。」とのお話を伺いました。
Colab側では「Colabランタイムを中継したコーディング・学習代行での」
つたないけど必要最低限のいい記録が残せたんじゃないかな。
ではではこの辺で切りましょうか。
みんなの音声合成学習ライフがいい感じになることを祈る!
そんじゃな!風邪ひくなよ!
あと黒聡 鵜月をよろしくな!!!
おまけ
電気代の計算方法です。
まずPCの消費電力を割り出しましょう。
PCの大元コンセントに電力表示計などを取り付けるのが確実ですが、学習だけ(学習中は不必要なソフトは全て切りモニターもOFF)とすればGPUの最大電力+α位で考えればいいかもしれませんね。
例えばウチのであれば大体1時間400Wとして24時間動かせば9,600W、9.6kW×1kW料金(30円程度?)とすれば1日288円、300円程度と考えてみましょう。
それをもし毎日30日動かせば一月9,000円、学習以外もやるのでPCのみの作業でも月10,000円を切ることはないでしょうし、フルで付けっぱだとPCは直ぐに壊れます。
何が言いたいって?
あんま調子に乗らず程々に休憩しようなってことよォ
この記事が気に入ったらサポートをしてみませんか?