
A Traveler’s Guide to the Latent Space

編集および提示可能作成者: Juan Lam
実験のためのアイデアの束のサインオフ スプレッドシートを作成し、このガイドに適切な研究を行う方法に関するセクションを追加しました。Disco Diffusion だけでも、試したり、テストしたり、実験したりすることが膨大にあり、可能性は無限大です。それも楽しみの 1 つです。
質問、コメント、またはフィードバックは、discord でお気軽にメッセージを送ってください: ethansmith2000 # 1332 Wiki - 研究データベースhttps://ezcharts.miraheze.org/wiki/EZ_Chartsとにかく、ここにガイドがあります!
プロンプト テンプレート
<余談> 💡 一般的な形式: 件名、アーティスト (およびアーティスト)、修飾子 1、修飾子 2…
</aside>
簡単に参照できるように視覚化したものを次に示します
。件名 / 主なアイデア | 、 | アーティスト名別 or アーティスト名別&アーティスト名2&アーティスト名3(お好きなだけ入れられます) | 、 | 修飾子 (コンマ区切り) | | | --- | --- | --- | --- | --- | | | 緑豊かな風景の美しい写真 | 写真 、 | トーマス・キンケードとマーク・シモネッティ著 | 、 | 4k 解像度、artstation で話題 | また、 G4L44D が彼のガイドで説明し
た方法も気に入っています。

そこにリストされているプロンプトの例は、かなりきちんとしたものを提供することを保証できます。
以下は、プロンプトに追加する楽しくて一般的なもののリストです。
アーティスト モディファイアー ファンタジー ランドスケープ
Artists Modifiers Fantasy Landscapes
Tyler Edlin
Mark Simonetti
Fantasy Characters
Justin Gerard
Wayne Barlowe
Victor Adame Minguez
Jesper Ejsing
Gerald Brom
Greg Rutkowski
Classics
DaVinci
Pablo Picasso
Van Gogh
Winslow Homer
M.C. Escher
Sci-Fi
Jim Burns
John Harris
Dean Ellis
H.R. Giger
Anime
Studio Ghibli
Makoto Shinkai | 4k resolution 8k resolution Unsplash photo contest winner Trending on artstation Deviantart #pixelart 3d art Digital art Blender Octane Render Unreal engine Watercolor Oil painting Acrylic painting Shot on film 35mm lens Portrait photography Portrait Character design Cgsociety Mandelbulb 3D Trending on Flickr. Vaporwave
(You can really put anything though, don’t let this limit you) |
(実際には何でも入れることができますが、これに制限されないようにしてください) |
これらのリンクは、追加できる他のいくつかのもの、特にアーティスト
の研究についてさらに詳しく説明しています 有名な70人以上(現在650人以上のアーティスト)のアーティストの研究
** https://weirdwonderfulai.art/resources/disco-diffusion-70-plus -artist-studies/**
修飾子の研究
** https://weirdwonderfulai.art/resources/disco-diffusion-modifiers/**修飾子
の Excel シート
** https://docs.google.com/spreadsheets/d/1j7zaDi_PkndizQ2pL8B_yMcwfKUdE6tSMhL31bYtJNs /edit#gid=0** https://docs.google.com/spreadsheets/d/1_jgQ9SyvUaBNP1mHHEzZ6HhL_Es1KwBKQtnpnmWW82I/edit#gid=1637207356を求める
すべてのもの
技術的には、何でも修飾子にすることができます。AIにとって、「修飾子」などというものはありません。それらは、美的な意味を持つ言葉にすぎません。しかし、「修飾子」を追加すると、何かの外観を簡単に説明できます。不吉、悪、純粋、神聖、不気味、悲しいなどの言葉は、ある種のイメージを頭に浮かび上がらせる形容詞ですよね?ディスコにも同様の効果があります。
私は実際にあなたが使っている言葉とそれらが持つ意味について考えようとします. ここでは辞書の定義について考えているのではなく、これらの単語が私たちにとって何を意味し、それらに何を関連付けるかについて考えています。「丘の上の孤独な灯台」のように「孤独な」という言葉を使用して、レンダーで 1 つの主題だけを取得しようとする人を見てきました。「孤独」という言葉は、レンダリングで 1 つの灯台だけを与えるのに役立つかもしれませんが、その言葉が意味する他のすべてのことを想像してみてください。オブジェクトではなく生物に関連する言葉なので、擬人化された悲しい灯台が得られるか、少なくとも、意図していなかった悲しく暗いムードが出力に含まれる可能性があります。
AIの囁きにはコツがあります。
私がそれを考えるのが好きな方法は、Instagramの投稿などを作成することです. 件名部分はキャプションであり、すべてのモディファイア/アーティストはそれに追加されたハッシュタグであり、カンマはアイデアを区切る良い方法として機能します.
プロンプトを作成するときは、具体的で、一貫したスタイルの件名と修飾子を使用すると役立ちます。プロンプトの一部としてアーティストを使用することは非常に効果的です。アーティストは構成、色などに共通のパターンを持つ傾向があるためです。また、Artstationと4k 解像度の使用にも注意してください。上の例では。AI は、見た目が美しいと見なされるものを参照しない限り、画像を美しく見せる方法を知りません。Artstation は多くの偉大なコンセプト アーティストの作品のコレクションであり、4k 解像度では、画像が 4k サイズでレンダリングされることはありませんが、4k 解像度の画像が持つ外観をキャプチャしようとします。あいまいなままにしておくほど、一般的に遭遇する問題が増えます。ただし、あらゆる種類のプロンプトを試すのをためらわないでください。それは知っておくべきことです。
面白いことに、それはモデルの微調整に関係しているかもしれませんが、油絵を描くアーティストを含めることは、単に「油絵」を含めるよりもはるかにうまくいく傾向があります。油絵のスタイルは非常に多様であり、学ぶべきパターンが少ない.
もちろん、アーティスト名と「油絵」を組み合わせることで、さらに優れたガイダンスを得ることができます。
こことここは、使用できるさまざまな修飾子とアーティスト名のリストですが、セクションの最後に、より一般的なものとともに、私のお気に入りのものをいくつか挙げます。Disco のデータセットとアーキテクチャが原因で、まったくキャプチャできないアーティスト、特にデータセットに入っていない可能性があるあいまいなアーティストがいます。また、Disco が使用するデータセットは 2019 年に作成されたものであるため、その年以降に発生したものを参照するとうまくいかない可能性があることにも注意してください。
別のヒント!プロンプトで画像の主題をどのようにフレーミングするかが重要です。「スクールバスに乗った男性」と「男性が乗ったスクールバス」を考えてみましょう。おそらく、頭の中でこれら 2 つの文を想像する方法は異なり、AI も同じ違いを経験する可能性があります。2 つのプロンプトは、非常に異なるイメージを生成する可能性があります。
または、たとえば、「アイアンマンとロックマンの戦い」と「ロックマンとアイアンマンの戦い」を取り上げます。
最初の例では、2 番目の例よりも明確に、戦いの主題とイメージが強調されています。文法における能動態と受動態の違いのようなものです。正直なところ、2つの別々の人物をキャプチャすることはとにかく非常に困難です.
プロンプトを明確にすることがいかに重要かを示す例を次に示します。そうしないと、プロンプトが持つ可能性のある二重の意味を同時に描写することができます。
ディスコに宇宙の地下鉄駅をお願いしました。私はそれを手に入れましたが、レストランのサブウェイも手に入れました。
今回はChick-Fil-Aをお願いしました。確かにそれはわかりますが、SFのひよこ宇宙船のように見えます. 怒るどころか、嬉しいアクシデント。
このようなことが起こっている別の例は、誰かがトルコを国にしようとしたときに、トルコにいるように見える風景のいたるところに七面鳥 (動物) が走ってしまったときです。個人的には、どこかで鳳凰を頼んだレンダリング画像を何枚か持っていることを知っていますが、代わりにアリゾナ州フェニックスに行き着きました。
CLIP誘導拡散の法則:何らかの方法、形状、または形式で誤解される可能性がある場合、それは誤解されます。Coar
による迅速で読みやすいプロンプト エンジニアリングのガイドへのリンクもここにあります。
ディスコ・ディフュージョンの強み、弱み、限界
Disco をしばらく使ってみると、Disco には非常にうまく機能するものと、うまくいかないものがあることに気付くでしょう。これが、CLIP ガイド付き拡散の性質です。これは、システムを調整するための優れた方法を開発する開発者側と、それらの調整を利用する最善の方法を見つけるユーザー側の両方で、絶え間なく進行中の作業です。
そして、ほんの数か月前 (2022 年 6 月の時点) でさえ、Disco で通常の顔を作ることは不可能であるか、せいぜい信頼できないと考えられていたことを指摘したいと思います. コードを 1 つも変更することなく、ユーザーがこのプログラムをナビゲートするためのより良い方法を見つけたため、その信念は完全に変わりました。したがって、私が指摘する制限はせいぜい暫定的なものです。
強み
風景 - ほぼすべての種類の設定で、素晴らしい風景を得ることができます。それらは一般的に構成がかなり一貫しているため、生成が容易になる傾向があります。ご存知のように、画像の下部に土の素材があり、上部に空があります。そこに混乱することはあまりありません。
ポートレート、または単一のオブジェクト - ここでもうまくいきます。さらに設定を微調整する必要がある場合もありますが、「単一の灯台」のようなものは非常に簡単にキャプチャできます。
抽象的なもの - これは、クリップによる拡散の制限を美しいものに変える行為です。反復的な主題や歪んだオブジェクトなど、いくつかの古典的な AI の特徴または「欠陥」があります。しかし、意図的にユニークで抽象的なものを使用すると、それらすべての間違いが正常に見えるようになります。そのため、この AI 画像生成方法は、最近の他の方法の改善に比べてほとんど古風ではありますが、非常に美しいと思います。それは自信を持って間違っているという行為です。他のプログラムのミスは、画像が圧縮されている、破損している、またはブラシ ストロークが抜けているように見える場合がありますが、Disco が犯すミスは、あたかもそこにあることを意図しているかのように見え、独自の斬新な方法で組み込まれています。
弱点
残念ながら、「バットマンとスーパーマンが戦う」という複数の主題があるものは、一般的にうまくいきません。
画像内の特定の数のものを指定します。
人間の形/解剖学 - 私は人々がそれをやってのけるのを見てきましたが、それは多額の設定とせいぜい多くの試みを必要とします. また、体の特定の部分がより変化しやすいほど、それを台無しにする可能性が高くなります. 一貫性のある点では、あらゆる種類の角度、標高、方向から山の写真を撮ることができ、視覚データがかなり似ているため、風景はうまく機能します. たとえば、右手、左手、正面向き、後ろ向き、伸ばした手、握りこぶしなどがあります。それらはデータセット内であらゆる種類の方法で現れ、そのパターンを見つけるのはより困難です。 . たとえば、手で何かを生成する場合、1 種類の描写を取得して実行する代わりに、すべての描写のこの奇妙な平均を取得し、かなりめちゃくちゃに見えます。
これらの弱点に挑戦し、それを回避する方法を見つけることをお勧めします。これらは難しい制限ではありません。私が知っている限り、これらのことを行う良い方法があるかもしれません.
クリップの取得
また、この**素晴らしいツール** を使用して、CLIP が特定のフレーズを参照している画像の種類を確認することもできます。これは、AI がどの単語とどのような関連性を持つかを絞り込むのに役立ちます。デフォルトの検索「Beeple」でわかるように、すべてのキーワードが期待する画像と正しく一致するわけではなく、まったく何も表示されないものもあります。それでも、プロンプトのレンダリングに時間を費やす前に、何が用意されているかを確認するのは良い方法です。また、回避策を使用してデータセットの画像を表示しているため、100% 正確ではない可能性があります。あなたは、あなたが入力した言葉の一般的な
傾向やアイデアを理解しているかどうかをもっと見ています.** のアーティストとそれぞれの CLIP スコア。これは、CLIP が自分の作品を認識する独自の能力にどれほど自信を持っているかを示しています。ただし、画像とキャプションのペアに不一致があると、依然として不正確な結果が得られます。少なくとも、それはイメージに影響を与えます。
これで、最初のパーソナル イメージを作成できます。一番下までスクロールすると、いくつかの単語が入ったセルが表示されます。It'll look like this:

The only thing you need to worry about for now is the phrase within the quotes.
動作させるには、次の形式にする必要があります:
0: [“words words words”]
左側のインデントにも注意してください。それは重要です。
Once you type in whatever you'd like in there, go ahead go to the top header of the window, click Runtime -> Run All
Cool! すぐに最初の画像ができます。
プロンプトの作成とたくさんの画像の作成を練習するだけで、いくつかのクールなものが手に入ります。私はあなたを実験して、あなたをワクワクさせるものを作ることを勧めます! 迅速なエンジニアリングの技術を習得するだけで、Disco から素晴らしいイメージを得ることができます。
第 2 章: イメージの初期化
AI Art ツールボックスのもう 1 つの楽しい機能は、独自の画像を Disco にアップロードし、AI を使用して画像を進化させたり、画像を「ペイント」したりできることです。レンダリングをゼロから開始したくない場合は、このセクションを参照してください。
まず、ランタイムに接続した後、ファイル ディレクトリに移動します。
Then, you're going to click on this button circled in red which will prompt you to upload a file. あなたの写真をアップロードします。
これで、ファイル ブラウザーに表示されます。ファイル名の右側にある 3 つのドットをクリックし、[パスのコピー] というオプションをクリックします。
Then you're going to paste what you just copied into the text form underlined in red in the picture below. ピリオド「.」を入れる必要があるかもしれません。最初のスラッシュの直前ですが、Windows デバイスでローカルに実行している場合にのみ発生する可能性があります。./init_images/Sampleimage.jpg
この時点でほぼ完了ですが、さらにいくつかの手順があります。
解像度を、設定した初期画像解像度に比例するか、少なくともほぼ比例するように調整する必要があります。そうしないと、挿入した画像が収まるように引き伸ばされます。
たとえば、使用したい画像がある場合、それは 1000x800 です。幅と長さの比率は 5:4 または 1.25:1 です。ストレッチとサイズ変更を最小限に抑えるために、5:4 またはそれに非常に近い解像度を選択することをお勧めします。960x768 は正確に 1.25:1 になるので、レンダリングに理想的なサイズです。
<余談> 💡 幅と長さの値は両方とも 64 の倍数でなければならないことに注意してください。そうしないと、Disco 拡散によって自動的に切り捨てられます。
</脇>
Skip_Steps
Colab ノートブックの小さなツールチップが示すように、スキップ ステップを合計ステップの約 50% に設定する必要があります。したがって、設定パラメーターが 250 を示している場合は、そこに 125 を入力します。
これは主に、開始するのに適した場所です。skip_steps を低くすると、AI が出力に及ぼす影響が大きくなりますが、元の画像が失われることは少なくなります。skip_steps を高くすると、画像がより適切に保持されますが、AI からの影響も少なくなります。
スキップステップの実験 -
BellsTheorem
Pinthead
init_scale
これはちょっと厄介です。高い init_scale は、skip_steps とは異なる方法で、init イメージの色と詳細をより適切に保持します。これを行うための最良の方法は、skip_steps を AI の影響のレベルを調整する主な方法にしてから、それ自体に影響を与える init_scale の微調整を行うことだと思います。私は初期イメージをあまり使用しませんが、通常、Init Scale の範囲は 0 ~ 1000 です。
ここで init_image に関するより高度なヒントを参照してください。
第 3 章: 設定
画像を次のレベルに引き上げたい場合は、プロンプトが重要です。しかし、プロンプトはこれまでのところしか得られませんでした。Disco Diffusion にはいくつかの重要な設定があり、それらがどのように機能し、どの値が最適かを理解することで、以下に添付した 2 つの画像の違いがわかる可能性があります。これはまったく同じプロンプトで、4 か月離れています (設定の使用方法を学んだ後)。
“a computer in the renaissance, fresco, trending on artstation”
January 2022
https://lh4.googleusercontent.com/Rsf6yEDzC9l6uk37g9yxRPA7POL9LLAs76EcvxwtvY_MUOj2Fb_O0i-ixXCDui6IipjRH-9YV3Lblo-jR69wi16Q0z_AtM4_rTXKjlYLcH07yQg3foyMKhd0g6t4GROrWQ1Tx_bBpaVtfrHaEQ
May 2022
https://lh6.googleusercontent.com/eoVarABddwHvTcwEMTyaQL2HWdO_C485OsdEgdm-90aUhVpEI9Fl_auz7EroI_2A1NbZK13roe4MjPtkcn8m3ZvVusBzsAfD8PxcSko29ELoRjW_FFqOxXUHDehy6t01Id06rOlf6lMYKMqq3g
There are some pretty dramatic improvements when you get some good settings down.
ただし、プロンプトは依然として王様です。
私は、設定をプロンプトに対する乗数と考えるのが好きです。もしあなたがくだらないプロンプトを持っていても、非常によく調整された設定を持っていても、それほど遠くまでは行かないでしょう. 0 x 100 = 0.
圧倒される可能性があるため、この章ではこれらの設定について詳しく説明しません。代わりに、設定に慣れてもらい、操作するのに効果的な値を提供することに焦点を当てます。設定については、第 5 章で詳しく説明します。
<余談> 💡一度に理解するには多すぎる場合は、このドキュメントで「ベースライン設定」を検索してください。開始するのに適した場所が得られます。その後、このセクションを掘り下げながら微調整を行うことができます。
</aside>
ところで、これらの設定 (最後の設定を除く) はメモリ使用量に影響を与えないはずなので、GPU のメモリ バジェットを超えることを心配する必要はありません。そして、最後の設定でも、後でリストする設定の組み合わせは、Colab Pro で、場合によっては Colab の無料バージョンでも問題なく機能することに注意してください。
そうは言っても、設定に飛び込みましょう。
拡散モデル
[拡散およびクリップ モデル設定] タブにあり
ます。画像のレンダリングに使用するモデルは、おそらく高品質の出力を得るための最大の要素です。ただし、この品質には、メモリ使用量の増加とレンダリング時間の増加という代償が伴います。これらのモデルを高解像度で実行しようとすると、メモリ不足エラーが発生する可能性が高くなります。これについては後で詳しく説明します。今のところ、私はあなたの生産性を向上させる大きな素晴らしいモデルを1つ、そしてあなたが遊ぶことができる2つの小さなモデルをお勧めします.
開始するには、下の図のようなセルに移動します。
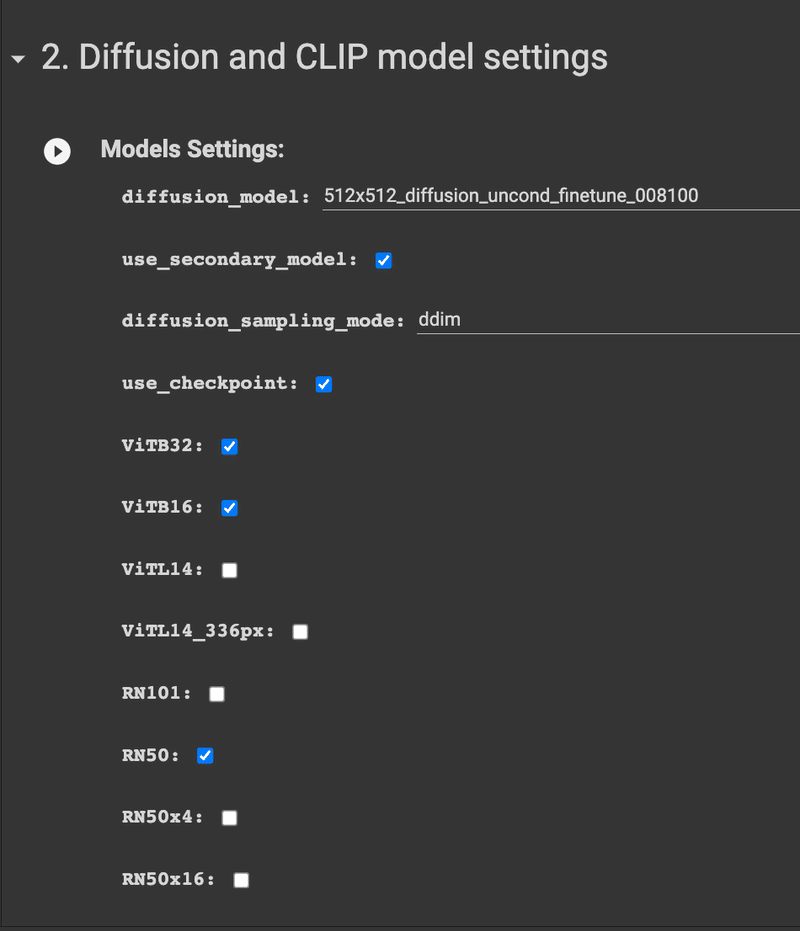
By default, you'll have these 3 checked: VITB32, VITB16 and RN50. これらが何を意味するのかについては、後で詳しく説明します。
とりあえず、メモリが許す限り、VITL14 をオンにしてみてください。ポンド対ポンドで、VITL14 は最強のモデルであり、出力品質に大きな違いをもたらします。
それ以外にも、次のことを試してみることをお勧めします。
RN50 を RN101 に交換すると、RN101 は少し大きくなり、強度も増しますが、スタイル的にはそれぞれに独自の外観があり、どちらを使用するかは好みの問題です。
RN50x4 をミックスに投入してみてください。
あなたの心が望むことは何でもします!RN50x16、RN50x64、および VITL14_336 はすべて非常に大きなモデルであり、解像度とカットと呼ばれる別の設定の両方を大幅に下げない限り実行できないことに注意してください。
デフォルト: VITB32 + VITB16 + RN50
推奨:
VITB32 + VITB16 + VITL14 + (RN50 または RN101) + RN50x4 (オプション
)
**https://www.reddit.com/r/DiscoDiffusion/comments/tbaygt/modelssteps_test_using_the_famous_atlantis_prompt/ - u/1stclaas、解像度の変更とステップの変更も混在**
**https://www.reddit.com/r/DiscoDiffusion/comments/twivva/testing_clip_models_multiple_combinations_with/ - u/guioakhouse**
**https://www.reddit.com/r/DiscoDiffusion/comments/t7p4bi/seascape_test_1_using_different_model_settings/ - u/relaxedorange**
クリップ ガイダンス スケール (CGS)
[基本設定] タブにあります
。このパラメーターは、イメージの作成中に Disco がプロンプトにどの程度忠実であるかを示します。CGS が高い = 影響力が強い。0 の場合、ガイダンスはなく、画像生成は事実上ランダムになり、AI Limbo と呼ばれるものから絶対的なナンセンスが作成されます。とはいえ、値が高すぎると、プロンプトを表示するように生成に圧力がかかりすぎて、画像が歪む可能性もあります。後で詳しく説明します。今のところ、CGS を 10k ~ 30k で開始することをお勧めします。
デフォルト値: 5000
推奨値: 10k-30k
可能な最大範囲: (-∞,∞) ただし、500k+ あたりで AI リンボに陥ります
。
Here's a little mini example I did

And some more from some **studies G4L44D did ,** which really illustrates what can happen when CGS gets too high.



300kを超えるとバラバラになる様子がわかります。その理由の一部は、すべての「スケール」変数がすべて合計され、作成時にすべてのパイが得られるためです。1 つのスケールを非常に高くすると、他のスケールが薄くなる可能性があります。
また、100 万で CGS 0 にかなり匹敵するように見えるのも面白いです。両方とも、プロンプトを完全に無視し、AI の漠然とした様子を見せてくれます。
解像度
[基本設定] タブにあります。これは
簡単です。解像度は、出力のサイズを決定します。解像度が高いほど、VRAM の使用量がより深くなります。指定した解像度は 64 の倍数でなければなりません。これは拡散モデルのルールです。それ以外の数値の場合は、最も近い 64 の倍数に切り捨てられます。つまり、767 を入力すると 704 になります。また、重要なことに、解像度は色や構図などにも影響するようです。
u/relaxedorange は、より低い解像度で発生する可能性がある品質損失の一部を示す、非常に優れた実験を行いました。
ただし、1280x768 の解像度を超えるとそれほど改善されていないことに気付くでしょう。そのため、時間とメモリの使用量のために、それよりも高い解像度で実行する必要はないと考えています。驚くほど詳細を保持するESRGANなどの AI アップスケーラーを使用して出力のサイズを変更することをお勧めします。
注意すべきもう1つのことは、選択したアスペクト比(幅と高さの比率)は、プロンプトがどのように解釈されるか/どれだけうまく表示されるかに影響するようです. 縦長の画像は縦向きの傾向があり、横向きの画像は横向きの傾向があります。アスペクト比が悪くても被写体を捉えることはできますが、難しい場合があります。
これらの設定は、use_secondary_modelで実行するためのものですそれなしでルールが変更されるため、チェックされています。
デフォルト: 1280x768
推奨:できれば 640x640 以上。1280x768 を超えると、改善は目立たないため、アップスケーラーを使用する方が適切です。
最大範囲:技術的にはありませんが、押し続けるとメモリ使用量が指数関数的に増加します。
Cut_ic_pow
[Extra Settings] → [Cutn Scheduling]に
あります。これは、理解するのが少し難しいので、ここでは、値が高いほど詳細であると言えます。DD が物事にぼかしを加えようとする傾向にも役立つかもしれませんが、構図が台無しになる可能性があります。モチーフと呼ばれる、主題の奇妙な繰り返しが増える可能性があります。また、大きな数値を使用している場合 (セカンダリ モデルをオフにして実行していると仮定) は、より高いtv_scaleを使用して、過度に激しくなる詳細を打ち消すことをお勧めします。また、ローエンド モデルや少ないカットを使用する場合に、より詳細をキャプチャするための優れた方法でもあります。ガイドの後半で、詳細と一貫性のバランスをとる行為に関するセクションを確認できます。
デフォルト値: 1
推奨値:5-10
最大範囲: 0-100、100 はカットが最小サイズ、224x224 (ほとんどの CLIP モデルの場合) に達する最大値です
。

手順
基本設定に
あります。これは、出力を生成するために必要なステップ数です。生成の開始時には、大量のノイズ/ランダム ピクセルが表示されます。すべてのステップで、そのノイズの一部が削除され、その中の画像が「明らかに」なります。250 ステップのデフォルト設定は悪くありませんが、一部のプロンプトで発生する従来の露出オーバー/コントラストが強すぎる外観になりがちです。
ただし、ステップ数の増加は、イメージのレンダリングにかかる時間に正比例します。500 歩は 250 歩の 2 倍の時間がかかります。1000 での改善は限界 (imo) であり、多くの時間がかかります。
試すことができるいくつかの代替値は、200、333、500、および 1000 です。
これらの数字にはパターンがあることにお気づきでしょう。元のプログラムは 1000 ステップ (混乱を避けるために em Dsteps と呼びます) で訓練されたので、別の数を使用するときはいつでも、その 1000 を使用している数で割ります。したがって、500 では、1 ステップあたり 2 Dstep を実行することになります。均等に分割できない場合、最後のステップが無駄になるため、これらの推奨値のいずれかを使用することをお勧めします。333 は十分に近く、1000 - 333x3 = 1 です。完全に合格できる世代の 1/1000 を失うだけです。しかし、334 では、その数 x 3 は 1000 より大きくなり、この方程式 1000 - 334x2 = 332 になり、生成の 33.2% が失われます。
1000 を超えるステップを実行することは可能ですが、有益であるとは観察されていません。
デフォルト値: 250
推奨値: 200、250、333、500、1000最大
範囲: 1 - 無限
実験:


Here's a chart that indicates the best step choices to avoid losing part of the curve . 本当に重要なのは、ステップ数が書かれた点です。そして、 G4L44D
によってもたらされたいくつかの例
これらはセカンダリ モデルがオフになっているもので、250/333 ステップを超えるとあまり改善されません。主な顕著な違いは、clamp_max とステップの関係によって仲介される可能性のある色と照明の低下です。そしておそらく、私が自分のアウトプットでも気づいた、より深い知覚の深さ.




カットバッチ
基本設定に
あります。この設定は、値を 2 倍にすると時間も 2 倍になるという点でステップに似ています。5 ~ 8 でよりきれいなテクスチャと構成が見られるかもしれませんが、個人的には、カットされたバッチよりもステップを増やしたいと考えています。そうすれば、より多くの「費用対効果」がありますが、実験を思いとどまらせないでください。8 を超えると、影響はほとんどありません。2 を試すこともできます。ほぼ 2 倍の速度になりますが、品質が低下することがあります。これは一般的に、世代を決定する設定ではありません。
デフォルト値: 4
推奨値: 2-8
最大範囲: 1-無限
実験
クランプ_最大
Clamp_max は、画像生成で行われる多くの操作のマスター ノブとして機能します。この値を大きくすると、彩度が向上し、コントラストが向上し、ディテールが向上します。ただし、画像が露出過多/過飽和になりやすくなります (プロンプトによっては、他のプロンプトよりもリスクが高くなります)。さらに、より高いクランプ値を成功させるには、より多くのステップが必要です。また、ノイズ除去がはるかに迅速に行われることにも気付くでしょう。40 ~ 50% 程度の小さなぼかしにもかかわらず、イメージは非常に完全に見えます。
デフォルト: 0.05
推奨: 0.05-0.10。特定のプロンプトが一貫して露出オーバーである場合は、0.05 よりも低い値を試すこともできます。
実験
対称スイッチ
この機能は、対称的な出力を取得するのに役立つ方法であり、特にポートレートに役立ちますが、実際にはほとんどすべての場合に役立ちます. それが機能する方法は、設定した小数点以下が実行中の % であり、現在のイメージを取得してミラーリングし、そのまま続行することです。したがって、たとえば 0.4 では、40% で画像がどのように見えるとしても、ミラーリングされ、その時点から続行されます。これはかなり新しいため、明確なデフォルト値や推奨値はまだありません。
完全な鏡面反射のように見せることなく、一般的な対称性を与えるには、0.3 ~ 0.4 が適切であると推定します。
私は個人的に、この対称性を実現する方法が非常に積極的であることに気付きました。通常、ノートブックを改造してSymmetry Lossと呼ばれる別の設定を好みます(HighDruidMotas に感謝します)。
他の「スケール」値と同様に、生成を対称に導きます。それは、完全なミラーリングではなく、対称性に影響を与えたり、対称に向けたりします。
デフォルト値:
対称損失スケール: ~160,000 (対称の強さ)
対称スイッチ: 69 (対称損失で実行するステップの数。その後、オフになり、生成に影響しなくなります。
その他の設定
範囲スケール、TV_Scale、Sat_Scale
基本設定タブにあります 正直なところ、 [✅] use_secondary モデル
がチェックされている場合、これらのどれも機能しないようです。これについては後で説明します。私と他の人々は、これらについていろいろいじりましたが、引き出せる結論を見つけられませんでした。ただし、理論的には:範囲:極端な色、特に絶対的な黒と絶対的な白を制限します。これはクリッピングとも呼ばれます (画像の一部が非常に明るくなったり暗くなったりして、その領域のすべてのピクセルが最大の白さ/黒さ、したがってそこにある詳細は失われます)。より高い数値はこれを制限するはずですが、数十億の値を試しても、二次モデルの有無にかかわらず、実際には何もしないようです. Sat_scale
ただし、範囲スケールが制限することを意図していたものの一部を制限できるようです。
数値が高いほど、これが発生するのが制限されます: **セカンダリ モデルを使用した実験 1 - Aetherial **
言い換えれば、または写真だと思いますが、一般的な目的は、画像が次のように見えるのを防ぐことです:
https://lh6.googleusercontent TV_Scale最終出力コントロールの滑らかさ
: 高い = より滑らかで、ディテールが圧倒されたりカリカリしたりする場合に適していますが、セカンダリ モデルを削除しない限り機能しないようです
**セカンダリ モデルを使用した実験1** - u/lowfuel
Sat_scale : 色の彩度のコントロール、高い = 色の彩度の制限が大きくなります
。これらすべての範囲は -∞ から ∞ です。しかし、それらはclip_guidance_scaleと同様の値で (セカンダリ モデルがオフの場合) 動作するようです。値は負になる可能性がありますが、そうしないことを強くお勧めします。制御不能になるだけです。
つまり、5k から 50k の範囲で、大きな違いに気付きました。
これらのスケールは、イメージに対して非常に強力というよりは、ソフト リミッターのように見えます。たとえば、Tv_scale で 0 から 500k にスケールアップすると、フラットラインが平滑化されるポイントがあるようです。これは、詳細/鮮明さを決定できる各プロンプト/設定の組み合わせごとに異なるポイントになる場合があります。重要なのは、この値を大きくしても滑らかさが直線的に増加するのではなく、最適なレベルの滑らかさまたは彩度をさらに押し上げるだけのように思われることです。また、これらのいくつかはしばらく横ばいであるかもしれませんが、多くの人は、これらを 100 万以上、場合によっては 10 億以上に上げると、非常に奇妙な結果が得られることに気付きました。
sat_scale と同じことです。これを説明するG4L44Dによるいくつかの研究があります. そして、彼の完全なガイドへのリンク。

satスケール


TV_スケール


レンジスケール


この中で注目すべきことは本当に何も見えません。また、注意してください: この範囲スケールは定数シードでは行われませんでした。
私の知る限り、すべての損失スケール値は解像度に依存しています。その関係の正確な比率はわかりませんが、解像度を下げるときに一部のスケールがそれをやり過ぎていると思われる場合は、覚えておくべきことがあります.
また、画像を生成するときに、すべての損失が合計されます。そのため、互いに対するスケールの相対値が役割を果たす可能性があります。私はそれについて提供することはあまりありませんが、すべての「スケール」変数で同様の値を使用する価値があるかもしれません (もちろん init_scale を除く)
Skip_steps
これは、実行を開始するときにスキップするステップの数です。したがって、250 のステップがあり、10 をスキップする場合、10 から開始して 250 に進み、240 のステップを実行します。ステップを飛ばすと、最初のカラフルなノイズはノイズが少なくなり、クレイジーなピクセル化も少なくなりますが、ターゲットに向かって移動するための意味のある方法で処理されません.
ここでの考え方は、主題を見つけるときの初期のステップはやや不安定ですが、スキップステップを少し持つことで、少しきれいなものを得ることができるかもしれないということです. ただし、これにより、画像の詳細、色、および全体的な品質が犠牲になる可能性があります。また、露出が激しい場合に緩衝材を置くのに役立つことにも気付くでしょう
デフォルト: 0
**推奨: ~** 合計の 4%、250 ステップで 10 スキップ
範囲:負にすることはできず、総歩数よりも大きくすることはできません。
実験: **KyrickYoun g** KyrickYoung
によるすばらしい実験で、Clamp_max を増やすことで、色や強度などの損失をどのように活用できるかを示しています。それでも多少の品質低下は見られますが、これは、ノイズ リザーバーの一部を犠牲にしているためです。

しかし、グレーネスの問題のいくつかは、Perlin_init を利用することで解決できると思います。AI が最終的に犠牲にしたノイズを超えて動作するための強固な基盤がまだあるからです。二次モデルを実行している間、私はそれで幸運に恵まれました.
JohnBrainArtLabs による、まさにその例を次に示します。

ここで、個人的に私のお気に入りは 30 スキップ ステップです。ここでは、clamp_max がデフォルトでした。
と
これが何をするかを説明するのはかなり難しいです。これが私の試みです。イータが高いほどダイナミックで詳細に感じられ、イータが低いほどフラットになります。設定はまったく異なりますが、より高いイータは、クランプを少し上げることに多少似ています。それが私が説明できる最善の方法ですが、写真の方がより適切です。Eta は、DDIM と DDPM という 2 つの異なるタイプのノイズ サンプリングの比率です。そうは言っても、PLMS のような別の種類のノイズ サンプリングを使用している場合、ETA は出力に影響しません。1.0 では純粋な DDPM であり、0.0 では純粋な DDIM です。DDPM (より高い値) はより多くのランダム ノイズを使用するため、通常は 250 で十分ですが、完全に見える出力にはより多くのステップが必要になります。
デフォルト: 0.8
推奨: 0.8 で十分です。0.7 ~ 1.0 は、いじるのに楽しい範囲です。しかし、それよりも低い方を好む人もいます。
範囲: -1.0 から 1.0 (これは実際には負になる可能性がありますが、それが何であるかは正確にはわかりません)
知っておく価値はあるが、一般的に触れる価値のないその他の設定
Clamp_grad : デフォルトでは on です。clamp_max を調整した結果は、この関数によって調整されます。画像が揚げ物になるので、オフにすることはお勧めしません。
Skip_Augs:デフォルトではオフで、実行を強化するいくつかの拡張/変更を実行します。楽しみのためにオンにしてみてください。私はあまり詳しくありませんが、
ファジー プロンプト + Rand_Mag:ファジー プロンプトはデフォルトでオフになっています。生成がプロンプトに固有のものではなくなります。それがどのように表現されるかについては、多少の余地があります。あいまいなプロンプトをオンにすることは、機能をオンにすることです。
これは **u/ Lowfuelの素晴らしい実験**です。
https://lh3.googleusercontent.com/fHQ_0UvNvLojfJdVrBHa6-BoBOnTp14ZYKBKEi1dzQB_bK-rcStyalg4tjmTR8nD-f87QtKOebfZ3zA_vl0i5Mqv5J7Es_fo7NBAfOuxZNrqYE7Cm_xkeQX4Am9Mmlyr3yBJorqdb3RPklIyHQ
The way I see it (and another point I'm asking to be corrected if I am wrong) is that a prompt encodes data for an image of certain traits . 異なるシードであっても、通常はかなり具体的です。ここで、原点と点の間の線が画像生成のパスであると想像してください。rand_magをオンにすると、側面に逸れるための小刻みな余裕ができました。
非常に単純化されすぎていますが、それが何をするかを理解するには十分です。
設定の基本はこれだけです。第5 章では、これらの設定についてさらに深く掘り下げ、詳しく説明します。
第 4 章: 技術サポート
Disco でしばらく遊んでその設定を試してみると、必然的にメモリ不足 (OOM) エラーが発生します。私が見た約3つの異なるタイプがあります。
ただフラットアウトすると、CUDAのメモリ不足エラーが表示されます
「畳み込みを実行するための有効な cuDNN が見つかりませんでした」についての何か
:0: cudaGetLastError(): メモリ不足
GPU メモリ割り当てと悪名高い CUDA メモリ不足エラー
CUDA のメモリ不足エラーが発生した場合は、割り当てられた GPU が処理できるよりも重いジョブを Disco が実行しようとしている可能性があります。
このエラーが発生した場合は、設定を少し下げるか、ロードするモデルを 1 つ減らす必要がある可能性があります。Disco がどのような構成を処理できるかをテストする必要があるだけです。
取得できる GPU のタイプ (最も弱いものから最も強いものまで)。
K80 - 非常に遅いです。基本設定で約 1 時間半かかることを思い出します
T4 - <16GB (明らかに約 15.2 ですが、不明) (p100 よりも少し速いかもしれません)
P100 - 16ギガバイト
V100 - 16GB (p100 と同様だが高速)
A100 - 40GB (これはユニコーンです。これはめったに見られず、おそらく pro+ でのみ見られます)
このため、ほとんどの場合、16 GB の VRAM で作業し、その制限内で予算を組む必要があります。
私が見た他のいくつかのCUDAベースのエラー
「住所のずれ」について
これは通常、T4 GPU で VITL14 を実行しようとした結果です。
メモリの不正アクセス
これらは私の理解を少し超えています。コード内の何か、または入力したパラメーターの誤りである可能性があるため、再確認してください。しかし、それはハードウェア的な問題である可能性もあり、少なくともランタイムを再起動する必要があるかもしれません。そうでない場合は、切断して新しいランタイムを取得してください。
Colab、Pro、Pro+、ランタイム タイムアウトの処理
まず、これがかなり頻繁に混同されるのを見てきましたので、明確化します。プログラムは Colab ノートブックを介して実行されます。これらのプログラムは、自分のコンピューターを動力源としていません。平均的なデバイスにはプログラムを実行する計算能力がないため、プログラムをアウトソーシングして Google のサーバーで実行しています。
いずれにせよ、Google Colab には 3 つの層があり、それぞれ異なる量のリソースと、GPU にアクセスできる時間の長さを許可します。接続時間が長すぎると、GPU ジェイルと呼ばれるものに入れられます。これは、ランタイムの開始がロックアウトされたときですが、通常は 12 ~ 24 時間で消えます。
無料利用枠
遅く、通常は Pro の ¼ - 1/5 の速度です。デフォルト設定で生成するのに 1 時間以上かかることがわかりました。(これは 2022 年 1 月の時点でのものであり、その後変更されたかどうかはわかりません。これは、他の人が私に言っていることから更新する必要があるかもしれません)
頻繁な GPU 刑務所
ディスコを始めたばかりで、これがいくらかの現金を投資したいものなのか、それとも単にカジュアルなユーザーなのかを判断する場合に役立ちます.
プロ - 10$/月
通常の速度。デフォルト設定でのレンダリングには約 20 分かかります。GPUに依存しますが、これはかなり標準的なようです
GPU 許容量の増加、p100、v100、まれに a100 へのアクセス。
1日24時間のうち約12時間は走れます。
Pro+ - 50$/月
24 時間 365 日稼働、本当に主な特典
Proと同じ速度
ハイエンド GPU の優先度を取得します (ただし、これは違いがどれほど大きいかはわかりません)。
Dicknascarsixtynine によるいくつかのガイドは、メモリの使用量の一般的なアイデアを示しています。
use_secondary_model を使用した場合のメモリ使用量
[✓] (青) と use_secondary_model を使用し
ない場合 (オレンジ)
一般に、セカンダリ モデルを使用しないで実行すると、約 2 倍のメモリが使用されます。ただし、合計 100,000 ピクセル (~320x320) では、ほぼ同じように動作します。
これらの数値は、プリセプター モデル、カットなどの固有の組み合わせを考慮していませんが、相対値 + 勾配は、使用するメモリ量を測定するのに役立つビジュアルです。
これは、特定の CLIP モデルと実行されたカット数 (セカンダリ モデルを有効にした場合) の間の関数としてのピーク メモリ使用量の測定値です。
ローカルでの実行
ローカルで実行することは非常に優れたオプションですが、実行できる GPU は非常に少なく、Colab の GPU よりも多くのメモリを使用できる商用 GPU は 1 つだけです。メモリが減っているにもかかわらず、多くは同じパフォーマンス設定で Colab よりも速く実行される傾向があり、もちろん GPU ジェイルについて心配する必要はありません。これは非常に良いことです。
これを行うにはいくつかの方法があります。
ProgRockDiffusion : コマンド ラインから実行される DD のバージョンにもいくつかのきちんとした mod がありますが、Colab インターフェイスが犠牲になっています。
JupyterNotebooks: または、Colab を外部の GPU ではなく独自の GPU に接続します。
** https://gist.github.com/MSFTserver/a05f637f32302918dd893318a4d9f62b**
これは私が使用したガイドで、かなり簡単なセットアップです。
カオスのビジョン:
これはおそらく DD をローカルで実行する最も簡単な方法であり、多くの人が気に入っています。これには、きちんとしたインターフェイスがあり、セットアップの大部分を処理するインストーラーがあります。欠点は、コードをカスタマイズしたり編集したりできるとは思えないことです。
おそらく私が気付いていない他のチュートリアルとそれを行う方法があります。
サードパーティのクラウド サービスでの実行
Vast.aiは、Colab が提供するものよりも高額な GPU を中断することなくかなりお得な価格でレンタルできる、非常に優れたサービスです。GPU 共有の Uber のようなものだと思います。これは、誰でも GPU をレンタルしたり、GPU をレンタルできるように提供したりできる市場です。Vast.AIを使い始めるのに役立つリンクをいくつか紹介します。彼らはまた、DiscoDiffusion の質問に特に対応する本当に素晴らしい FAQ を持っているので、ぜひチェックしてください!
また、サービスと互換性を持たせるには、特別バージョンの DD ノート (超小銭) が必要です。そこにあるリンクの一部には、**Vast.AI ** 互換のノートブックのコピーが含まれているはずです。これは、 Vast.ai
で動作するように改造された私のカスタム ノートブックのバージョンですhttps://drive.google.com/file/d/1d11GKmL7__053ZYuEXDR0VdJX9oedIx9/view?usp=少し古いものの共有重要: Colab とは異なり、VastAI は接続しませんGoogle ドライブに。そこで作成されたすべての画像とファイルは、ダウンロードしない限りそこに残ります。ダウンロードせずにセッションを終了すると、それらは永久に失われます。彼らの FAQ には、すべてを一度に圧縮してダウンロードする方法を説明する便利なセクションがあります。
時間を節約する良い方法: 製図
下書きとは、プロンプトがどのように見えるかを把握するためだけに実行して、すばやく低い設定を行うことです。特定のプロンプトに対して、より長く高品質の実行に時間を費やす価値があるかどうかを確認すると便利です。
通常の設定では正確には見えませんが、スタイルやプロンプトが一般的にどのように見えるかを判断するための良い方法です。
これについては、いくつかの良い方法があります。これらは、セカンダリ モデルなしで実行するように設計されています。二次モデルで製図する場合、露出オーバーになりがちなため、ステップを減らすことにはもっと躊躇します。
カット バッチ = 1 または 2、これを実行する最も簡単な方法です。4 カットバッチよりも約 2 ~ 3 倍高速で、全体的な外観は同じです。
ステップを下げる
モデルの削減 - あまりお勧めしません。これにより、レンダリングの構成とスタイルが大幅に変更される可能性があります。
時間と処理能力を節約するもう 1 つの優れた方法は、各レンダリングを 40 ~ 50% マークでバッチ停止させることです。アイデアは、約 40% で、画像がどのように見えるかにかなり近いということです。それで、それが不発であることがすでにわかっているのに、なぜ後半を記入するのに時間を無駄にするのですか?
基本的に、約 40% の時間でパーシャルのバッチ全体を作成できます。そこから、気に入らないものを放り投げて、気に入ったものを Init_images としてフィードすることができます。
同じシードを使用し、停止した % に対応するスキップ ステップ数を使用することもお勧めします。Skip_end_steps
を使用して実行を早期に停止できます。、私がノートブックに追加した変数(Zippyのクレジット)は、最後にスキップする/元に戻すステップの数を指定します。
PLMS 法:これについては、ノイズ サンプリングのセクションで詳しく説明しますが、ドラフトの興味深い方法は、PLMS サンプリングを使用することです。PLMS サンプリングは、完全に見える出力を得るのにそれほど多くのステップを必要としないという意味で、より迅速に機能すると言われています。実際、ステップやカット バッチが多すぎると、「やり過ぎ」て、グレインが強く粗いイメージになってしまうことがあります。
このメソッドを使用すると、次のようなことができます
Cutn バッチ = 1-2
ステップ = 75 ~ 150
(オプション) 最後のいくつかのステップをスキップできます。おそらく 20% で粒子の一部を回避できます。そして、それを何に使用しているかに応じて、かなり完全なイメージを提供します。つまり、スタイルを測定しようとしたり、オーバーペイントや初期イメージに使用したりするだけです。
削減されたバッチとステップを補うために、clamp_max を削減する必要がある場合があります
アップスケーリング
そのため、多くの人にとって、Disco の出力は、私たちが望むほどの高解像度ではありません。VRAM の予算による解像度の制約と、他の解像度よりも優れているように見える特定の解像度があるため、必要な鮮明な 4k 解像度に到達するのは難しいように思えるかもしれません。幸いなことに、かなり堅実な解決策がいくつか得られました。私が考えることができる少なくとも3つの堅実な選択肢があります。
AI アップスケーラー
この機能を提供するプログラムとノートブックの両方があり、Photoshop でさえこれを追加しようとしていると思います。フォト エディタでの通常の画像サイズ変更よりもはるかに優れており、余分なノイズを除去したり、エッジをシャープにしたりするのに役立ちます。また、これらについては非常に優れており、後でフォトショップに画像を入れるのがはるかに簡単になります. 定義されたエッジは、選択ツールやその他のものに役立ちます。多くの製品には、顔がかなり変形している顔であっても検出し、修正を試みる顔強調機能があります。(フェイシャル エンハンスメント モジュールは通常、人間の顔だけでトレーニングされるため、Artstation スタイルのキャラクターに超現実的な人間の顔を重ね合わせると、奇妙に見えるかもしれません) その例を次に示します。
私は本当にこれらが好きではありません。
とにかく、アップスケーラーのためのいくつかの一般的な選択肢があります
Topaz Gigapixel - 100 ドル、デバイス上で動作
多くの場合、最高と見なされており、圧縮レベルとスタイルに特化したいくつかのモデルを選択できますが、少なくとも、私はその例をあまり見たことがありません. 他のアップスケーラーよりも保守的で、信頼できる結果を提供する傾向がありますが、他のアップスケーラーはイメージに対してより大きな影響を与え、良い場合と悪い場合があります. トパーズの効果は弱いですが、少なくとも大丈夫であると期待できます. ラップトップの Intel グラフィックス プロセッサで Topaz Gigapixel を実行できます。元のサイズは、メモリ要件と実行にかかる時間を決定するものであり、目的の出力解像度ほどではありません。768x960 から 2.25 倍のサイズにリサイズすると、私のラップトップは画像あたり約 20 秒かかります。
ESRGAN - Colab ですが、よく知らないローカル オプションもあります
ローカルでセットアップしたものとは対照的に、Colab で実行するので、はるかに高速になる可能性があります。私の 768x960 では、2 秒あたり約 1 出力で 3.5 倍のサイズ変更を行うことで、バッチも実行できます。また、非常に強力な顔面強化機能も備えています。上の写真は ESRGAN のものですが、オフにすることもできます。
顔がリアルすぎる場合は、その画像を取得し、おそらく 60 ~ 70% のスキップ ステップで初期化としてディスコに戻し、もう一度実行してよりよくブレンドします。
SwinIR
**** 個人的にはこれを試したことはありませんが、ESRGAN や他のほとんどのアップスケーラーにかなり近いことがわかりました。
u/wiskkey は、これらのパフォーマンスを比較するいくつかの研究を行いましたが、一般的にはほとんど感知できません。そして、リンクされたものを超えて、彼らのプロフィールにはもっと多くのものがあります.
GoBig モード
Lowfuel による素晴らしいアイデアで、彼は ProgRockDiffusion で実装しましたが、それ以来 Colab ノートブックも作成しています。基本的には、画像の 1 つを取り、それを部分に切り取り、Disco を介してより高い解像度で init_images として実行し、それらを拡大するだけでなく、新しい詳細を追加することができます。次に、画像のアップスケールされた部分をすべて自動的に取得し、それらをきちんと元に戻します。
第 5 章: 設定 – 詳細
Clip_guidance_scale (CGS) について
CGS は、イメージがプロンプトにどれだけ似ているかで説明されているので、多いほどよいでしょうか? それをずっと上げてみませんか?クールに聞こえるかもしれませんが、それよりも少し複雑です。夕焼けの素敵な写真が撮れたとしましょう。しかし、より高いクリップ ガイダンス スケールを満たすために、さらに夕焼けのように見せたいとします。では、夕焼けをもっと夕焼けらしくするには、画像生成で何ができるでしょうか? どこにでもそれらを追加し始めます。そして、何か抽象的なものが必要でない限り、おそらくそれは望まないでしょう。そのため、その変数には健全な媒体があります。完全な数はわかりませんが、5k-20k ゾーンはかなり良いようで、依存性も非常に高いです。他の人が言ったことや他の設定からの解決策については、試行錯誤をお勧めします。
「スケール」という言葉で表示されるすべてのパラメーターは、画像生成のガバナーであり、目標を達成するために特定のパスを指示します。すべてのステップで、画像がそれらのスケールをどの程度満たしているかを表すスコアが割り当てられます。技術的には、スコアではなく、到達しようとしているハイスコアではなく、損失数であり、その数を最小限に抑えようとしていますが、どう考えても、最終的には同じポイントになります。 .
また、これを再確認する必要があります(これについてもお気軽に修正してください)が、CGSが高いほどノイズ除去プロセスが高速化され、初期のステップで画像がより鮮明になると思いますが、これは必ずしも良いことではありませんけれど。動きが速すぎると、世代の不安定さが少し増し、プロンプトを最大化しようとして、より多くの情報を表示しようとします。それがどのように機能するかは少し単純化しすぎていますが、概念的にはそう考えています.
誰もが高CGSの象徴的な強いコントラストとそれがもたらす明確に定義されたエッジとディテールを愛していますが、いくつかのエラーとのトレードオフは難しいです. 主題の問題の繰り返しを超えて、背景要素である場合、前景にあるかのように細部を与えるという奇妙な傾向もあります。これが私が意味することです
一般に、この種のことは、cut_ic_pow が高い場合にも発生する可能性があり、これらの両方が一緒にクランクアップされている場合はさらに可能性が高くなります。
追加の手順を実行する場合は、個人的には、clamp_max を上げると、制御不能になることなく鮮明な外観が得られることがわかります。
Cutn バッチ vs ステップ
これは私が最近調べていることです。ステップを 2 倍にすると、cutn_batches を 2 倍にするのとほぼ同じ時間が増加します。いずれかを 2 倍にすると、実行全体で実行されるカットの総数が 2 倍になります。
つまり、250 ステップ、16 カット、4 カット バッチです。1 ステップあたり 64 カット x 250 ステップ = 16,000 カットです。(そして、各 CLIP モデルは独自に、16k x 3 つのデフォルト モデル (vit32,16 + rn50) = 48k カットを行います)
ステップを 2 倍にすると、ステップごとに同じ数を行いますが、ステップ数は 2倍になり、
cutn を 2 倍にしますバッチ、同じステップ数でステップごとに 2 倍の数を実行します
とにかく、ポイントは、1 つを 2 倍にすることは、もう 1 つを 2 倍にすることとはまったく異なる効果を持つということです。現時点では注目すべき実験はありませんが、実験をフォローアップしたいと考えています。
逸話的に、私と他の何人かが気付いたように、より高いステップはより深い感覚を与えるようです. また、より詳細に役立つ傾向がありますが、実際にはある程度までしかありません. 2 次モデルの場合、おそらく 500 で最高になりますが、1000 はそれほど印象的ではありません。
初代モデルは200~250。より高い値はあまり詳細ではありません。私が現在調べている値には違いがあるようですが、ステップを増やすだけで達成できる詳細には限界があります. ただし、166、142、100 ステップなどでは、ディテールが失われていることに間違いなく気付くでしょう。
一方、cutn バッチを調整すると、似たような異なる結果が得られる場合があります。特に、より高いカットのバッチは、過度の露出の傾向を食い止めることができます. また、細かいディテールがより説得力があるという意味で、より詳細で滑らかなテクスチャを持つ傾向があります。それらは、より低いカットバッチよりも、途切れや広がりが少なく見えます。
ただし、cutn batches は、詳細を追加するのをいつ停止するかを知らない場合があることに気付きました。これは、他のものを犠牲にしない方法でカット パウまたはカット スケジュールを調整しても解決できないようです。もの。
これは顔で特に顕著で、4 カットバッチ (少なくとも私が実行したものでは) は二重の鼻を持つ可能性が高く、傷は必要ありません。
だから私は2つのカットバッチを試しながら、ステップを増やして、カットバッチがどれだけ画像を鈍くするかを補償しました.
2022 年 7 月 21 日更新: カット バッチとステップを比較して行った調査。黒いスペースは失敗した実行です

クランプ_最大
ディスコが利用する一種のツールボックスである pytorch にネイティブであるため、Clamp_Max は非常に興味深い変数です。すべてのスケール変数とカット変数は、種類の AI プログラムの生成に固有のものですが、clamp_max はそれよりも少し深く実行されます。その名前が示すように、clamp_grad が実行できる最大値または上限を設定します (それが何を意味するのか完全にはわかりません)。それは他の多くのものを支配しているようです。
クランプの最大値が 0 の場合、何も起こらなくなります。画像は元のノイズとはわずかに異なって見える可能性があります。
より高いレベル (0.15+) では、詳細、深さ、色など、ほぼすべての画像が得られます。その上限値を上げることで、より生き生きとしたイメージを得ることができます。しかし、ここでわかるように、物事が露出オーバーになるのも本当に簡単です. その過飽和を防ぐには、sat_scale を調整すると効果的ですが、一般的には十分ではない可能性があります。適切な数のステップとバッチを使用することもお勧めします。
セカンダリ モデルは、clamp_max の引き上げに対してより敏感です。プライマリモデルで引き出せる値のいくつかで、真っ直ぐな無地の漂白された色を超えて何かを得ることができるかどうかさえわかりません. これは、ステップ x Clamp_max (作者不明) の比較です。

フル イメージY軸、上から
下: 0.01、0.025、0.05、0.075、0.1、0.2、0.5私のモデル研究。完全な研究

値が高いほど、彩度、コントラスト、明瞭度、照明効果が著しく高くなり、色付きの光の「かすれ」またはボケのようなビットも多くなります。
確かにすべてのプロンプトがそれを行うわけではありませんが、詳細と光の増加の傾向は時々このように現れるようです. とは言え、私はこの絵がとても好きです。
さらに高い値では、非常に強いシアンやマゼンタ、その他の色がすべてを覆っていることに気付き、その象徴的な高いクランプ最大の外観を与えます
これらの 2 つは、例として使用させてもらった discord の Kai によって作成されました。たくさんの光とたくさんの CMY 種類の色。
ご覧のとおり、Clamp_max は非常に強力な設定であり、出力に大きく影響します。最適な値の一部は好みであり、その一部は目的のアートスタイルに依存する場合があります。色あせた感じの絵画は、clamp_max が高い場合に露出に影響を受ける可能性があります。
非常に興味深い戦術は、skip_steps と Clamp_max を連携させて作業することです。
後で詳しく説明しますが、初期のステップはより不安定になる可能性があるため、run にいくつかの skip_steps を追加すると役立つ場合があります。ただし、これらの手順をスキップすると、色が少し薄くなる可能性もあります.
perlin_init を使用すると、これでかなりの助けになりますが、clamp_max を上げて色の損失を補うのにも役立ちます。
2022 年 7 月 21 日更新: 2 つのパラメーターが密接に関連しているため、CGS とclamp_max を比較するいくつかの研究。技術的になりすぎることなく、CGS は次のステップを予測するために必要な値を生成するのに役立ちますが、clamp_max はその値が許容される上限または最大値として機能するため、どちらかを上げることで同様の効果が期待できます
が、はるかに同じから。
そして、追加のステップが色の問題の一部を軽減する方法を示すためのステップに対するclamp_maxの研究
フル解像度はすべてここにあります: ** https://drive.google.com/drive/folders/1JEsJcO5z40jIvBbzHU2eh5bQnP8StE89?usp=sharing**
0.45のclamp_maxで

4カットバッチ、250ステップ

2カットバッチ、250ステップ

ベルリン
これは十分に語られていない設定ですが、公平を期すために、それほど直感的ではありません。パーリン ノイズが実際に何であるかについていくつかの調査を行ったところ、より古典的な方法であるガウス ノイズとは対照的に、ノイズを生成する別の方法であることがわかりました。かなり人気
のようですウィキペディアのページより:
https://lh4.googleusercontent.com/lrkUmLXEeFxdQJj6X3l6cdbun6dstl4t-RXQroIDUHehaP7zf2UDRGUPERPSUdjabvCCaSMIKd4bQwx4ULPTtnEpY0JwnCZA3uZfMb_-NkkAOHKR_GPPQWFSSTSQjWTMJx9X9
それが AI 生成での使用にどの程度関連しているかはわかりませんが、その小さな宣伝文句は、私がそれを試してみるのに十分刺激的でした. 私が知る限り、Perlin_init をチェックしても、init** を使用する場合と同様に、いくつかのスキップ手順を実行しない限り、何の効果もありません。実際に試したのは 4% のスキップ手順** だけですが、これは私の To Do リストにあり、実験してみます。
これは、初期化なし、100 ステップ、95 スキップの生成です (99 と 100 ではクラッシュしましたが、最後の 5 ステップは画像にほとんど影響しません)
。初期化なし、100 ステップ、95 スキップ (99 と 100 でクラッシュしましたが、最後の 5 ステップは画像にほとんど影響しません)
perlin_init をチェックして実行すると、次のようになります。多かれ少なかれ、これはベースのパーリン画像が何のノイズも重ねられていない状態でどのように見えるかです。
更新 2022 年 7 月 21 日:おそらく私がしばらくの間見た中で最もクールな発見の 1 つ
です。 /1pcL-En7IowvSqpdm0ZO_C3cv3xg5apen/view?usp=sharing**

モデル パート 2
上記で推奨したモデル セットは別として、正直なところ非常に優れていますが、各モデルの固有の特性と、それらを組み合わせたときにどのように機能するかを見るのは興味深いことです。
私ができる最善の説明は、この投稿のコメントにあります。これらはすべて二次モデルで行われたため、これらの結果が一次モデルで実行したときにどれだけうまくいくかは不明です. しかし、私はそのために何かを試してみたいと思っています.おそらくプロンプトは少なくなりました. これらはすべて、レプリケーションのために、これらのパラメーターを使用して行われました
1280×768
500ステップ
4カットバッチ、
デフォルトのカット、
10カットパウ
https://www.reddit.com/r/DiscoDiffusion/comments/tv0jhj/the_fattest_model_study_i_have_to_date_and_still/
これらのモデルは何ですか? CLIPモデルとは?
それらは、データセットと画像生成の間の仲介者として機能します。多くの場合、指導者またはネットワークと呼ばれる彼らは、世代の目として機能し、各ステップでそのノイズを見て、それが私たちのプロンプトとどの程度一致しているかを判断します. 前に Clip_guidance_scale について説明したとき、損失スコアはこれらのモデルを介して生成されます。それらは非常に洗練された作品で、ファイル サイズは 300 MB から数 GB に及ぶと思いますが、4 億枚の画像のデータセットでトレーニングされています。計算し、完了するまでに数週間かかります。これらのものには通常、何百万ものパラメータがあり、それらすべてが意思決定に使用さ
れます.カットは、プログラムが画像を見る量であり、プリセプター モデルの強度が視力の質を決定します。
現在、CLIP と互換性のある 2 つの主なタイプのプリセプターを自由に使用できます。
Resnets = RNおよびVison Transformers = ViT。
しばらくの間、Ai イメージの生成は通常、1 つのプリセプターのみを単独で使用していましたが、開発者のおかげで、これらを組み合わせて組み合わせることができるようになりました。
全体的に、ViT は ResNet のパフォーマンス/メモリ使用量よりも優れているようです。
一番上の 2 本の青/紫の線がここで見ているもので、濃い紫は ViT モデルを表し、薄い紫は ResNet モデルを表しています。y 軸は、スコアまたは精度の測定値であり、高いほど優れています。x 軸では、メモリの使用量を測定しています (これが GFLOP と同じだと思います)。これは対数であり、右に移動するにつれてデータ使用量が指数関数的に増加することに注意してください。
注目すべきことは、ViT モデルのパフォーマンスはすべて RN のパフォーマンスをはるかに上回っており、多くの場合、メモリ使用量が少ない場合でも、RN が勝っていることを示しています。
ResNets はさまざまなタスクに使用されるニューラル ネットワークですが、名前のようなビジョン トランスフォーマーは視覚タスクに指定されています。
これは、それぞれがどのように「見える」かを示す画像です。ここに表示されているものは、ディスコにおける彼らの固有のスタイルをある程度示しています。ViT はより鮮明で、細部に重点を置いており、resnet が平滑化係数を与えるように見えます。それについては、個々のセクションで詳しく説明します
が、その数学的プロセスのすべての画像とそのすべてを正直に示すつもりはありません。興味のある方は、この件に関する優れた論文がいくつかあり
ます https://www.youtube.com/watch?v=TrdevFK_am4
https://theaisummer.com/vision-transformer/
https://www.youtube.com/watch?v =oDtcobGQ7xU
レスネット
自由に使用できる ResNet は次のとおりです (メモリ使用量が最も低いものから最も高いものまで)。
Rn50
RN101
RN50×4
RN50×16
RN50x64
RN の後に表示される数字は、それが使用するレイヤーの数、または私がその権利を持っている場合は「ニューロン」です。そのため、数値が大きいほど一般にパラメーターが多くなり、より強力でメモリを集中的に使用することが予想されます。これは常に当てはまるわけではありませんが、Lowfuelによるアーティスト/クリップ スコア
の調査では、rn50x4 が rn50x16 を打ち負かすかなりの回数があります。
そして、ここにそれぞれの異なる特徴のいくつかに関するオタクのためのチャートがあります. 即時の画像生成に実際に関連するものは何もありませんが、好奇心旺盛な開発者向けの製品です。
私はそれについてオンラインで何も見つけることができませんが、より大きなRNモデルにはより低いモデルが含まれているため、RN50x4にはRN50が含まれていると主張する人もいます.
RN50x16 には RN50x4 と RN50 が含まれます。
いずれにせよ、私はこの主張にかなり懐疑的であり、私のモデル研究で概説したように、他のものを含めることは間違いなくあなたの出力に影響を与えます.
スタイル評価
私は、リリースされた実験と私が台無しにした他のものとの間で、認めるよりも多くの時間をモデルに費やし、各モデルにいくつかの共通の特徴に気づきました.
一般に、RN は全体として定義が少なく、ViT の対応物よりも滑らかでぼやけています。
セカンダリーモデルでの走行評価です。これらの比較はミックス内の他のモデルで行われますが、それが最終的に実際に使用する方法なので、妥当性があると思います
RN モデル
Rn50 -
ひれの縁に苦労し、定義が不十分な太い線を描き、RN101 よりも絵画的でカラフル (xa)
https://lh5.googleusercontent.com/l2PDdV5FDFBMk47r-tj_Ydj-q_CADfIV3asTnQmz40zghZHGSRPTjALFrVwvdHO3vhzQKcpnZA26ERK80hUE1DzRMyKw-XPG2CXFsHAIW2FYrgzF1cEbqme3i0QdIANkrprF8Df5Hb6zlU1wOg
https://lh5.googleusercontent.com/y-KJMeJHWKUssx8eujyABVqC0FjswNvaBPOlGDpnoTg7fP2V5BYd7tHbG0oUtA5SvmTpFW5NUlFhJm48piNYMZs3W5nPJiZZUV5HvFWBfssFIoxb_HBKMBOkdrOKozUNzHWqUyTWUsZSMwX1Yg
https://lh3.googleusercontent.com/qQ4bJbr_mhjpLrteb8pWF1S7BuA0tM0Vn6DThkg8SEnMoJ3tuzgLmO-aXno_XjpwWvxaivJ4PPxnPpg07yI_F2Lbwkx1TJkTmN7jEzlApryd0Ir7d5LQYTYTFZXDNspBBpDhyZKhsdyRtxuhiw
RN101 -
前に述べたように、RN101 は一般的に RN50 よりも少し優れています。私にとってはどちらか一方です。色は RN50 で見たものよりもくすんでいますが、より細かいディテールを処理することもできます。小さくても、一般的に RN50 より改善されています。(ト)
https://lh3.googleusercontent.com/jLaQeWZCOmC1gRjPlU5QduG04Misi4J8c04mfQ9B6LCG-UeKFo9aJ_IhDhvJSUbidufOF_NkOpBNpHt-pS9NjMrIUkpD7NxBbue0Ncu5bNbkObkJ_vV4NWSm5ynVj6MAxlUsxY2G7wtENZ0reA
https://lh4.googleusercontent.com/LDQ37L9S6k0yNfJY0kWnHRg0cRJ4zD1Q_JQXS6DbPK1uuaMsSw3MElhI7jXQU6zSCjV0Mh1v0WpA7wbupvmcURbd5CgFlRV4f4LPtcjPcFofbn3YRDqe1f3cHHR1YhR7p0fIavdt4e5bKuiC-Q
https://lh4.googleusercontent.com/qIc8EXvnkvkAPSp3HThMRxgr-U0IEbQ2mKN5IszLV3cHASXVAaadnrzcmp8ZPqjo6sAnqeXhBxkbrHiM2ls-T586-XiexMUnQfD1-hGfiZS-uVI6rYVLbMQxNAIHHIh3o4REpOXpifuVELxMWA
Everything else は、RN50 を RN101 に交換する以外は一定に保たれました。その他のモデル: VIT32,16,14 + RN50x4 + RN50x16. 詳細については、モデル スタディを参照してください。
Disco は一般的にピンクとマゼンタに偏っているようですが、RN50 または RN101 が混在している場合は、より明白になることがよくあります。これは**モデル研究です * 気がついたところを試してみました。A&B とラベル付けされた画像にはそれらがありません。モデル、他のモデルはそうです。*
RN50×4
少し漫画/コミックブックのような見た目ですが、私はこれに気づき、他の何人かからも聞いたことがあります. これは、その兄貴である RN50x16 に関連して言及しています。常にそのような外観になるとは言いませんが、rn50x16 よりもフラットな感触です (i)
https://lh5.googleusercontent.com/IDjVI8XI3JiXsHH8FgaqwjNps9AQt34CBtjg7iDbl0ZDuBt6ZSC_XbM_qT1dXM03Us1OuQqeCLRRORzfg0l7NulRf-z6_cmVgdajxJoA5sKe6bUo6OzPzr481JzjIroI_4wRJsHAoleugmT8JA
https://lh3.googleusercontent.com/PkPToWcAKjLBHg-mtjGkocx8KrappC3RDlZDhG_746cE9JB8gfF_LtVyxfIxQtvfmNAoNlJQZrmhjnNwRmJsVQMQxRoYVVGDgugFRIqx5k5Iw4xFce5q4S7XpeLPBsNjSGEvUGvPPqsx7-nCnA
https://lh5.googleusercontent.com/rPalWmuZebnym81naFvLp9gYkaaiPc11BUf3ZTYe7xu8s6gxT0escf4BPMO1baC8U3rLE1kzjx6y84dVwO4KRKUNtaDQWYe3AwX0KUrNaOS8juCvpSYqKemlxUlplzrLH9GTPfmMoSK_4TUeGQ
https://lh3.googleusercontent.com/uNIwvU5QwYqX7IgENLVfPSehFY_OQOcSK_FI-a-VLP7Cc1eAknHSXEwFgaejwDATz_pzUIQ6JFRZyoKaQpaiszZjcErcY8QNI-F-tk5UEJMatvjvoYL2zKJvIIaEXPVLwoFar49sA-3Y8R0TIA
RN50×16
RN50x16 私が最も注目に値するのは、画像に与える深さ/空間であり、非常に明確な外観です。「アンリアル エンジン」「ボリューム ライティング」タイプのものでうまく機能し、光がどのように反射するかを認識できる方法が一貫して行われています。結構。しかし、精度や CLIP スコアの点では、RN50x4 が勝つこともあります (h)
https://lh4.googleusercontent.com/qVa-H1WVwLSykpUmVN0D1iPoJXL4hzKliWeDgz2vRN7P09EYIaK018UIWT4t3G-xFdjuFANUSGn1jpFgIBp5n1OioBUh-C8TY_CN72-7NOuDQvIxDt3i17raiKWze10ewnrbC5kh0vQdocSy-g
https://lh3.googleusercontent.com/XOW_XJXhg0EP8WZ9eGPwcyIG2uWiia7oj845X_slLDdfCj72JOfsStht0ll5spEsx5D2jqtEydR9EjdOQ_E8vTfgyRkwzDCmobHZ8E8tH2HfjtnHJYvRsnqdx3zvzWxp1XBGuSlFPWZRG-hv2g
https://lh6.googleusercontent.com/mI_tXB7Ev6-LCf4mCriGCLcQPu-tGoXM8g5RMrlE- ZPZw1pTjZC-A_Fs2H-Hxd8jCI11Bp_6QBYMvwuiIIxKqrcB_rplWgRuHtbpIEOKVbmHHKl9R3Y05Afp41Cq49nR7UNmnxM8ifGTczOKiQ
https://lh4.googleusercontent.com/E7AXVUM1Y-tQwZqHdu7KMqLwvIC35gHEy-mNvHwU5rDnDV1L4EE7vjFSNfeYTHlveDJVgVCVxe6Q1ZxXLzJEIll2jkrQMc2bY_awYLbDUJ0EjZXlGyUNXuXwDEVWYqzZA1c8jRPqfFoPZre47Q
Also, bonus pic that included rn50x16 just to show its iconic spacious look
https://lh4.googleusercontent.com/xfBuk3EXEeqSpw7yB08Cy1unqpNl_z5v-WRMncD_7PJiX-ewKnhxL_lJ3fkm_6ZJZQw5Y4XDUJA1jSJMpjvvI8a4KMpalLJgs12ETTc_gZDYyrDWg-UAxH0G1XW_5nIBZC4lCMahc88ymdD9nA
RN50x64
非常に独特の漫画的な外観で、特に私が行った VITL14_336 の比較で顕著で、気に入っています。いくつかのスタイルには本当にいいですが、それ以外の場合は、正直言って不当な量のメモリ使用量です.
rn50x64 を実行するのに十分なメモリを最近取得したばかりなので、大規模なモデル スタディでこれを比較する場合と比較しない場合の同じシードを使用しないでください。いずれにしても、画像で実行するために同じ解像度/カットを保持することはできません。あそこで。
また、最大のモデルが混在している場合、それらは多くのことを引き継ぎ、非常に多くの詳細を追加していることにも気付きました. RN50x64 と VITL14_336 を比較する方が公平な比較だと思います。
私の優先順位は高くありませんが、a100 をレンタルして、これらのプロンプトで rn50x64 と vitl14_336 を実行して、どれだけの違いが得られるかを把握することができるかもしれません。作る。
RN50 と RN101 を一緒に使用すると、どのように奇妙なことが起こるかについて述べたように、RN がどのように混ざり合うかについては、まだ把握するのに苦労しています。
ViT は、どのように連携するかという点でもう少し直感的で、かなり相乗効果がある傾向がありますが、RN が連携して連携するには、もう少し機械学習の知識が必要であり、それらを最適に組み合わせる方法について懐疑的です。
多くの人は 1 を実行し、一部は 2 を実行し、一部は 3 を実行しますが、0 を実行する人はそれほど多くありません。したがって、少なくとも文体的には、RN の存在は高く評価されているようです。
少なくともセカンダリで実行する場合、私の RN では、通常 (RN101 + RN50x16) または (RN101 + RN50x4) を使用しました。また、(RN50x4 + RN50x16) についても少し実験しましたが、これを行うと何かがおかしくなりましたか? 画像が断片的に感じられることがある
個人的には、(RN101 + RN50x4 + RN50x16) はより才能とダイナミックな深みを与えますが、リストした最初の 2 つよりも間違いやその他の傷が発生しやすいように思われます
。 、これらは最終的には非常に主観的なものですが、あなた自身の解釈と意見を作るために私の研究を一番上に置いています.
ViT モデル
私は一般的に、これらの仲間がほとんどの重さを担っている、または良い成果を生み出すものの大半を占めていると思います. 3つのViTモデルだけで作成された出力(両方を同時に使用することは想定されていないため、VIT14_336は含まれていませんか?
そして、数回述べたように、VitL14は私たちができる最も強力なモデルです。さらに、336x336 でトレーニングされたバージョンを使用します。
まず、命名システムを少し分析します
。たとえば、ViTB-16
ビジョン トランスフォーマー モデルのサイズ B = ベース、L = 大、H = 巨大 (ただし、これらのうちの 1 つ) パッチ サイズ (パッチ サイズ (この場合: 16x16 正方形) ViT b 16
最小メモリ使用量から最大メモリ使用量への順序 (および、CLIP スコアに基づく最低パフォーマンスから最高パフォーマンスへの順序)
ViTB32
ViTB16
VITL14
ここには 2 つの傾向があります
パッチ サイズが小さいほど、パフォーマンスが向上し、より多くのメモリを使用する傾向があります。
これについて私が自信を持って言える良い説明はありませんが、vitb16 と 32 を比較すると、画像/切り抜きに 4 倍の量のパッチがあると思います。さらに、メモリ集約型になると想像できます
数字はすべて興味深いサイズです。16 は 32 の半分ですが、14 はこの 2 のべき乗の規則を破っています。なぜでしょうか?
これらはすべて 224 と 336 に均等に分割されます。これがその理由だと思います。誰かが私の疑いを確認できるなら
これは、それらがどのように機能するかの簡単な概要を示す、痛々しいほど複雑ではない楽しい画像です.
https://lh3.googleusercontent.com/xL4MW0HyI7Pn8UJ9E5tQVr-RdRFNmyik_H4IK0tQrZw_bYudQFCbD639r2sFUCd0rPAnKHz3LYnhE5colVywiK3Q0KYJLzF-iKyTe-6kc-K-LvQWF7BEUGfouvt4awWgTNcu0Y2KoHYH3dmBRA
https://lh3.googleusercontent.com/HKCanIMoWlVYW8Qd90FZtUnvl_Uk8HdKMohwQvwlN4NatS-AIzrAic7MsRFH5NSEXTSpFOhn_AJ3Tod-1bi2U6mu9c_fgFoK4DBHRB0_59dvh9giuk4V6qAT8PNsoQ0HrTkdoqxzPZGdH3rtgg
And I'll leave another chart giving details on its parameters (again 、これはテストにはなりません:D)
各 ViT の文体分析…
RN に比べて「スタイル」というほどのものではありません。より正確なレベルの一貫性と詳細。
正直なところ、Vitを1つだけ実行したことがないため、これに対する優れた答えはありません。本当にメモリが不足していない限り、何の意味もありません. VITL14 が単独で動作していても、1 つの ViT だけで実行されているのを見てきました。プリセプターを組み合わせるこの美しい能力の使用しかし、大きなモデル実験(ViT16 + ViTL14) (Vit32 + ViTL14) (ViTL14)
を実行することから少し言えることがあります。
ViTb16 は間違いなく ViTb32 よりも詳細で、より多くの色も引き出します。(ニ)
https://lh3.googleusercontent.com/PnJ5oODmimSqUCYg2CqFB1a7pYGFpJMfoE2GXSjNmxYyRJkhOc70FWqlTnrIqm3NScozRxs8B7ija_V5Irnh40FIes50hUw6pUGgp-i03kYFO_Irip1pygOjzBg8ZHIUoEXXbY9b6cfYEK6Y_g
https://lh5.googleusercontent.com/YfRcCVWC8qg3REbHlS5r1ZXSM0lb6T3vLBi57vVAWQLLyaDD3LgGX2OW1eq6U8QZ8JvZV_3FhNX5unCELQx9KaO5lrHRL9834PlTT6czuh_dzYEeUXLjiffHL18zaWV5YcG_pyWym0i7aRX8fg
https://lh6.googleusercontent.com/zekleot0RyfnLXa0LwBypxKi1XSH1tCgLMqPL6szA6evgMLbYX3qLRi3E7zyQf4qZVh6ikl-Zyo43hTrQlBpuHVWMxglGJlpMWwq7lYQbFe_9ECP9DhHxARG6scHwJ0zO_OSJk3s6_ILYdbjSg
ViTb32、ディテールは少ないですが、より滑らかなテクスチャを提供できます。(a)
https://lh6.googleusercontent.com/F6GPDR3EzdMxnZg8jKX_bP59W89m3S0PI94jTXwHZ1kPOSIudt-_nbJAaasZuAzsnQR1WD82oKwnZ4dmu9yJiI-Lsnwg7JRpyhLRKaS1Ifyg3SDjT0vPf2Zfv2bdjhPbBH8O2YJswMLw005iTA
https://lh6.googleusercontent.com/Q70el4K9LUdd0Jz9KdeXdZdu3lqaCD5Bof8eheJcduu79vdy6ohCXoLzEkZOcG-q0Z4slw1plqnGfYiXTa2L-mEV681Y1soW8teodXDjhCc1VrVB-Qc_cJ-9N6u1SG-aOrsemZOZ8i5G8L00Vg
https://lh5.googleusercontent.com/jquVvRWYqwKFr-20BY4TiPmL9rBuFKZfSzG7CxT7-EUaDEmdZUou7AuvxQ2G7_fV3TxPeEI_SjBZSjZppcQOBhcqI1ymvoaHWattXhG1knbn2Eno3OVc8y2-pOFntMAxPgdAvXlP8SYtGfzRIg
VITL14、すべてが見栄えが良くなります笑。それは私が言わなければならないすべてです。
この比較では、Vit32,16,14 + rn101 + RN50x4 + rn50x16 (g) を実行します。
対 Vit32,16,14 + rn101 + RN50x4 + rn50x16 (同じもの vitl14 を削除) (xg)
1 つ目は VITL14 あり、2 つ目はなし、それはそれ自体が物語っています。
https://lh5.googleusercontent.com/tAWpXseshBQ7P3ntRtvypLGD_h09-aSZpaYAnwSOWUO3WAxEWLtI4O7osf0VagNLY6RyiwJuiOgbn65YiD5VsO446YGWXsbbiINa60qL8CgLgp08Jyn87Mh6seRfKowiSXHWTc3bhCEooTLu8w
https://lh5.googleusercontent.com/J9CRah-ZAdHQiX1iC44ZXGIELguHwziZcQLe21Hwu_ArFzx8b-4KVwzv05cxJFREWsZJ2z9E0wh8rsceJuuRSZ2fWSbSMMlizFXmICrYyr11ns9-fDqtEaUwWa9r-j9cGtPYbWr_84Xq2jsZmg
https://lh4.googleusercontent.com/wQBrVVeFI8AYaF4_PtV5kNTzDkHtMkINYdDoJbtugEvOdSadpJ-mCpb0RrgrydhnrI3qdzI-X_jf17lCaoo5OqytelDXxbx34W_9pHbfCkunZeO2UDRg-HWIon-euUNAWH3Q0_EpfFZxkaA1pw
https://lh6.googleusercontent.com/3OjZv_6HFFg321AdFVeSRdmNhyMllO1tN7G18OOJ-i5NHRPmfKtbngdTXwEhuutn2_THNYQJoRnHl1n6snRw2G_C9gqniaoR41edHosZK-xkwPQk-zN8PzDf5vV6gLqEyDuwchhMJCH4GpmMoQ
https://lh3.googleusercontent.com/yNC3CxUgJuJIVQFiKLNDFrw4nAIUt9prc1JCgEqCjK4NkEHhwfkPElS8o4z-ZK1WQs9acHKEAsrkLcUlxZvwlE00HbTJKJGl4YW2_uljyPO5Ke3CWmXF2U9TFCPM5ufZ47lFSZ45unztYxJHIQ
https://lh5.googleusercontent.com/xVVBVwhGwHggjG06fFY7lIPzENK7rakP1_epHO-LumL2JqtifShqBBFif_dx8l98bh1ubolQDe1GNAtzKXk-ylfdHBk9wB4OeOdMKMX3y7z3_euwzN1fJUegDfeBNBv7c6RxTuzL1_DMt0IFRA
I don't have any documentation to support this, but the way they stack seems to make more sense asなぜそれが有益なのか。それぞれが異なるパッチ サイズを持つため、独自の領域をカバーできます。そのため、Vitb32 は 32x32 パッチのより広いビューを持っているかもしれませんが、vitb16 はそこに 4 つのパッチを絞り込んで、その細かい詳細を取得します。あたかも相手が逃した地面をカバーするためにお互いにうまくいくようです.
成功する方法には、広いスケール ビューとクローズ アップ ビューの両方が含まれます。つまり、インナーカットを使用したオーバービュー カットです。
とにかく、そのため、私は常に3つすべてをオンにしています。
ViT モデルの 2 番目に最適な組み合わせは、(Vitl14 + Vitb16) または (VitL14 + Vitb32) のいずれかであると思います。それぞれに独自の才能があります。
–
モデルをいじる前に、CUDA のメモリ不足エラーを発生させる最も簡単な方法の 1 つであることを思い出してください。以下は、カット数に基づくメモリ使用量を示すグラフです。これらの研究のための dicknascarsixtynine に感謝します。
https://lh6.googleusercontent.com/KNB7xasugOqRxuTEbVU4_jV49GuVOwIPbDxto8Cxz3CKxXt5DUsfoco-KxOx9LhftqLGZbeTpNjjUQZvmNy2LLtSrt8XOhAEZVBAWEQ21kHjLml03wD2w9NmtuhpDsxZb6dkY7FFH4kPcRemCA
拡散モデルとクリップ モデル/ネットワーク。
そのため、前のセクションで、世代の批評家として機能するCLIPモデルについて話しました。これは、これまでの実行で何を実行しているかを見て、正しい方向に進んでいるか間違った方向に進んでいるかを評価するものであり、したがってCLIPガイドという名前が付けられました拡散
拡散モデルは、各ステップでノイズに作用し、少しずつ消去してイメージを明らかにする部分です。
ただし、CLIP のガイダンスがなければ、生成された画像はプロンプトからの順守や影響を受けません。
私は、拡散モデルを画家、CLIP モデルを批評家または教師と考えるのが好きです。CLIP は、ブラシ ストロークごとに、ペインターに良い仕事をしているか下手な仕事をしているかを伝え、ペインターはこのフィードバックに適応してエラーを最小限に抑えます。
私がそれを考えるのが好きな別の方法は、キャッチゲームのようなものです. たとえば、CLIP は入力時に、拡散モデルにスクリューボールを投げるように要求します。私たちの拡散モデルには、それを投げるスキルがありますが (それはデータセット内にあります)、それが何であるかを実際には学習していません。したがって、拡散モデルは継続的にスローを試行し、CLIP はモデルが熱くなっているか冷たくなっているかを伝えます。
CLIP ネットワークには、ViT および RN モデルが含まれます。
一方、私たちの拡散モデルには、
512x512openaiFinetune、
512x512OpenAi
256x256OpenAi
微調整モデル、および cc12m
のような他のいくつかのモデルが含まれます (ただし、これは DD ノートブックにはありません)
注意すべき重要なことであり、最初は混乱しました。512x512Openaifinetune (デフォルト オプション) と CLIP モデルは、異なるデータセットでトレーニングされます。拡散モデルは、オブジェクト認識タスクに使用される画像の広範なデータベースである
Imagenet でトレーニングされます。
CLIP ネットワークは、CLIP データセットでトレーニングされます。これは 4 億の画像のウェブスクレイプですが
、これは DALLE と Imagen に関するビデオであり、拡散がどのように機能するかについて多くの洞察を与えてくれます: ** https://www.youtube.com /watch?v=xqDeAz0U-R4&t=754s**
ノイズ サンプリング オプション
現時点では、ノイズ サンプリング方法には 2 つのオプションがありますが、他にも多くのオプションがあり、他のいくつかを統合することを期待しています. DDIM/DDPM および PLMS。PLMS は DDIM/DDPM よりも優れた代替手段であり、より少ないステップでより高い品質で画像を完成させることができますが、この主張は Disco とは少し異なる動作をするプログラムに基づいて行われました.
私が見てきたことから、私は同意することができます。しかし、Disco は非常に強烈なグレインに問題があるようです。私は現在、JAX での PLMS サンプリングを調査して、同じ問題があるかどうかを確認しています。これは、Disco に最も類似したノートブックの 1 つです。
その象徴的な粒子を示すいくつかの画像を次に示します: 左が PLMS、右が DDIM/PM
https://lh4.googleusercontent.com/w1HuzSgQyB-enci0Zj-gW48b6nHuJaJgXhxe20_E8WWBEkLGFigEBJgNOyUZW6wk8n_TbAU7QbkyfTO68EuVrm7bSi1iZNDEQ6y17WW37_OsYlz9IxvZ_YU2DQ22nOOMOC3Lh-CqDuqrvnj10A
https://lh5.googleusercontent.com/GbxHfF1j6NOfmz0dZE0k4GHhVuddeX2xVre0m4t7EJ8tt7rBFag774tPmlOgL0KflWJ0kff2JyeMHtJZJpvYsqUJn_jPX8zb8SAKYH0P78XLET7NlVC6LDhBenEamcUSL-kxYw_YUFftQoKI_w
https://lh5.googleusercontent.com/Alz1UHAoer_xnYSUVO9Xj9nToXr4B-JcNTdOJmM5nqt6fT2-HCCbmOepMkRH9GtXt-KqvFQ-7moCyncHEcLvChcxA2pLDBiGh7NmxMFbCPmxUFxNXMYB63EvI8X_xMJGYRDqzzSzXnHfvEFhIw
https://lh3.googleusercontent.com/DyRFn0EuPsjf8uX6gOECYa8eEzTIYj8h2B4xNTJm61YVaNZbn4PhJj05KzGQdKDdqsgqceJrOPEibawVLCPMlQd8-Y0KsHyLkh1NBdVSCxLJ5khbalaxk8OTzI9bj8iSO3DgLpR9YQDULJ9vsQ
https://lh3.googleusercontent.com/dh6k_zI5e3bAySZ4VZ9zWZRrdncMeAO47SdD844OET1WooFN4OZ1Fn9q2C4TD7MjUsK3qq1KfLt-Jf54faE87J06SwZk1-VFjtl4fUVG4uXVcqAlt4b6jgVqweG766IwrvsMZ8xBICTlKBfxbQ
https://lh5.googleusercontent.com/yl7aCYNJu0FjTKr3_kASBjyEJzSzDGMfewnYoBAKU2jf95GPfla8BT8Q2mmmBxux294j5PDFzBk7JZoGWlFgP82nvNrP3fTPAmabPwoupMDvQkcc5crrhFnZm3ew1mq72VEGn1Hz1bUw8Z9F9w
Sometimes it can get really bad, like this this one
But they're not exactly bad images at all, they just時々かなり船外に出ます。
これをいくつかの方法で解決しようとしました。主に、カットバッチおよび/またはステップを下げる私は限られた成功しか収めていませんが、他のそれほど素晴らしい方法ではなく、品質と構成に影響を与えると思います. tv_scale の非常に高い値を試すことも価値があるかもしれません。私が試した値はあまり役に立ちませんでしたが、もしかしたら十分に高くなっていないのでしょうか? これは 125 ステップ/1 カット バッチの画像で、通常の実行よりも約 5 倍高速です。And if you skip let's say, maybe the last 20% of the steps, you may resolve some the grain issue and that'd put you at 6x as fast almost
https://lh6.googleusercontent.com/VaM1zn47cOTOUVfmezhgoxeO6jRQR9CTgPo9CFoyeKMTvrbWJDrFwR0kxrb35M6-fulI1APcp6Ln8UhioPRi3ScGkoiJw5P6uXvXfekmzCj2lpzeidnwuZC36UxhqN8JLyP71QhRCbfKiQCJLA
https://lh6.googleusercontent.com/WOGJ9bZ6GYBYBdsXLG5o6f_R1B0oiDwQDj4YuRDV2SPZvkO1Gfd2V5ptY42KJGpGvy2xnEV3Zh5lVCNRcF8eyFi3foSAtmbadapr7bkBxB1jsjHxMVlyefsZpsGj0G2xBD8_tu8XbpPxuCMdLw
https://lh6.googleusercontent.com/cz9pMf6ypruihgoO5VsIaKc8gJZEqxPxAUZii1O9NpVxIcyUUlshlf783MdyOnu_Nuao3L-qxHtqFBh7Pm0SUoZ37TKwOabm50C2QqzatEH23LJCXODHr9LvCROjHbFP4JrYqKZI9rAkJtkQgg
https://lh5.googleusercontent.com/PXfomXtDVQonaGE5GxJQWpZ72LeGQmscSzYbUCnSdC5WJKoqX7iBJ6gvlpsK9jgoKwh00xbAL-0Adl0Ov1RbrGqY_C1aksBpAUO5HIGJam4-FreGBc2ru2KTB6dy_THTeEAlcSIYvwkJjQpseg
These were not so bad, but a lot of othersひどく歪んでいるか、詳細が欠けていることがわかりました。また、ステップ/バッチを減らすために、これにかなり高いclamp_maxを残しました。
他の人は、Resolution や RN を含むモデル セットなど、他のいくつかのものからのものである可能性があることを示唆しています。しかし、これらの可能性と、このことがより速くなるという考えを見て、もう少し調べたいと思います.
更新:何か解決策を見つけました。または、カスタム ノートブックに含めた回避策と呼んだほうがよいかもしれません。これには、実行の一部に PLMS を使用し、残りを DDIM/DDPM に切り替えることが含まれます。~50% 前後の値を試すことが私たちの関心のあるゾーンであるため、PLMS による組成ブーストの恩恵を受けることができますが、粒子の問題を回避するのに十分早い段階で DDIM/PM に切り替えることができます。
高度な Init_image のヒント
Disco での Init イメージの使用、または一般的な拡散モデルには、いくつかの問題があり、少しぎこちなくなります。
この種の AI は、特に高いスキップ ステップで、単色の画像領域に少し苦労します。これは、詳細を生成するためにノイズと色の分散に依存しているためです。そのため、そのシステムがうまく機能するように、画像の特定の部分にノイズを重ねて、AI に優位性を与えることができます。例を次に示し
ます
画像全体にノイズを重ねることも、図のように部分を選択することもできます。火にノイズを追加しませんでした。これは、火を進化させるために必要な量に十分なテクスチャがすでに十分に設定されているためです。また、エンブレムの周りに黒い輪郭があることにも注目してください。これは重要です。特にノイズを追加する場合、画像の 2 つの異なる要素は、できれば強いコントラストを成すものによって適切に分離されていないと、互いに混ざり合う傾向があります。そして、AI の影響がより強いスキップ ステップが低い場合、その問題はより一般的になります。とにかく試行錯誤の末。これが結果
です
拡大して黒の背景に配置。かなり誇りに思っていますが、11回目の挑戦でもありました。このような経験を積んだとしても、最初の試みでは決して得られません。プロンプトが何をするのか、必要なスキップステップの数などを推定するのは困難です。実際にどれだけ熟練していても、ナビゲートするにはまだ多くのばらつきがあり、試行錯誤が最善の方法です。 .
プロンプトは好きなように作成できます。それはあなたの創造的な自由ですが、多くの場合、初期イメージ自体といくつかの文体の言葉を説明するだけなので、元のイメージに似たものを作成できますが、品質が向上したバージョンになります。
別のプロンプトで別の実行を開始する前に、最初のイメージを削除するのを忘れたことがありました。ちょっと嬉しいアクシデントになりました。
https://lh3.googleusercontent.com/PZdsiMvoEFIBpaWlYemIx1ZriQapPG9QA554dgXqKY4wqgX7iyveIh-AljjI6vXwSIXremZAB2PpraRj1C32pLTnc0_6svXSBuM0KqiEG4s_E1E2GQR9Gy7ho2fVvjVIl5dlslZtdD1gYaLkAQ
Meanwhile the intended result was this
https://lh4.googleusercontent.com/VJdCgjuSKHqe-b0uD_VN01wGE1u5fzUu7Cx9h104cfhw_QQ8dfO2o2lRQxRiEiMrQ2JNn3O42h2N-askDzuizxrJqTcG1nzuarBqGfqUSUgDTjf7GgKhKy0avGWnYSKC7g28Jj70w96PtKBaWQ
私がよく使うもう 1 つのトリックは、さまざまなレベルの skip_step で init_image を数回実行することです。最も一般的なのは、40%、50%、そして 60% です。そして、Photoshop で 3 つの画像すべてをつなぎ合わせ、それぞれの好きな部分を抜き出します。40% では最もクールな独自のディテールが得られ、60% では主題がよりよく維持されます。Here's an example
https://lh5.googleusercontent.com/mZv4fUOkbXSbOvs30RilsNenVanNPPRAg63AptmvH6Pwm20DMyU56ma8fcGKFumL-dqSfWeRcaggGNfT3iIxiQRQnMtwlMmW-MYy2DbfAxzpOkuN_983FbEww3U5Z8FUT1pZFL9Gf3mOZ-MqoQ
One of my earlier works, definitely wish I could have done something about the Steve Buscemi eyes, but the concept turned out pretty cool. 顔と手は 60% のランの一部であり、ドレスの風景は 40% のランの一部です。
これが私が参考に使用したinit_imageです。
https://lh5.googleusercontent.com/EvFMNJqWl3sEZ56dOddCq0vUnIkED7i3kAMt51KQV_qrNuGNDwK-83Fkt25bcdlTIi08M1Y1JNXWL42Ly9vVXsNGFKT8N6IYNcngV0HF3aRlvNPrcm9IzkynMJrlc-v88G5MqzSpTBcN2sO1BQ
Also to note, it doesn't matter the resolution of the init image you use as it gets resize to the resolution you're running at anyways. フィッティングやストレッチなしでサイズを変更できるように、選択した解像度が設定のアスペクト比と同じではないにしても類似していることが重要です。
初期イメージとして使える超超ラフスケッチも描ける!このような場合、通常の 50% よりもさらに低いスキップ ステップを使用することをお勧めします。約 20 ~ 30% でうまくいくでしょう。初期スケールは 0 です。また、いつものように、追加のノイズを使用するのに役立ちます。This is from a long time ago, before I knew the noise trick, but check out this example
https://lh4.googleusercontent.com/7HdYJxcgEw3BsJsOXhUpNpdmPUp_m_TJyiwCgH2t5p3JsPMEV4HqEpX_rJ-TEXi9SNhl4t6xu00bEFI-j1ql8ZpXKaXuJHEsXt9sf8ms1Dtwfdw65JO_hZa-kOK29xgKVV68DgshChy0VHML8A
https://lh5.googleusercontent.com/QU9fAXU7qqUsFBiqFsnWist-u3zupYkPTd9IK5PFxRH0A0pMgPyfqijAD8xTJI7IzVVoY9mq3vTK4_7g_6S5gbwEZaboDEs40sDIZxYtJOYrcwxHciOoU1cKRvMFZrfIMHApFcKYY4ceciiXyA
二次モデルをオフにする
Use_secondary_model
(on) = secondary model
Use_secondary_model (off) = primary model
use_secondary_model をオフにすることは、出力を改善するための最大の鍵の 1 つです。ただし、VRAM を非常に消費するため、他の設定を下げる必要がある可能性があります。カット数に関連するメモリ使用量を測定するには、dicknascarsixtynine によるこのグラフを参照してください。
https://lh6.googleusercontent.com/k28hslBJ71VFxp1mfApZa-BJ-se9XmWuHjl3MnlKyOflcGqouEV-UZ6iNBu6EpM4r8D_hOUCdVwxmGQt8OPRirOfgrj587nW0b-Ceyn9ylET3bPGt3tdwLNWIzDO6A13Hz7uqz4
はどのようなセカンダリ モデルですか?
セカンダリ モデルは、少ないメモリで CLIP 誘導拡散を実行できるようにするための回避策として設計されました。しかし、それはまたかなり小さいです。それはほとんど、実際のモデルのデモまたはライト バージョンと見なすことができます。
この設定をオフにすると、OpenAIFinetune512x512 を最大限に活用できます。この世界への贈り物を Crowson と OpenAI に感謝します。
ただし、うまく機能させるには、追加の微調整と微調整が必要です。私はもともとプライマリ モデルを却下しました。これは、いくつかの非常に奇妙な結果が得られ、余分な時間がかかることにあまり満足できなかったからです。ただし
、スケール値といくつかのカット設定を調整したら、プライマリ モデルに切り替えてから、実際には元のモデルに戻っていません。
** プライマリ モードで実行した一連のプロンプト。これは、プライマリ モデルを使用するときに調整する必要があるとわかったすべてのことよりも前のことなので、一粒の塩でそれを取ってください。これは、セカンダリ モデルで行ったバージョンと比較されます。私のメインの実験
ドライブにもあります。把握するのが少し難しいので、いくつかの長所と短所、およびいくつかの例を次に示します。
主
な長所
より豊かなテクスチャ
プロンプトをより正確に反映
セカンダリではキャプチャできないアーティスト/ものをキャプチャできる
必要な手順が少ない: 125、142、166、200、250 はすべて実行可能な候補ですが、一般的には 200 または 250 を好みます
コヒーレント構造
カラーでより良い
短所
VRAM の使用率が高く、CLIP モデル、解像度、およびカット設定を犠牲にする必要があります
もっとゆっくり
プロンプトはより注意深く/具体的にする必要があります。
プライマリーモデルの方がより多くのルックスを捉えることができますが、本質的なスタイルが少ないのは良いことです! そうすれば、欲しいものをより柔軟に手に入れることができるからです。一方、二次モデルには、すべての出力で実際に見られる独自の才能があります
微調整が少し難しく、より多くの設定に敏感
一部の設定/プロンプトで空白の画像を作成する傾向があります。トラブルシューティングのガイドを参照してください
二次
的な長所
より速く、より少ないメモリ
風景、キャプチャ、広々としたエリアで非常にうまく機能します。
間違いが起こりやすいですが、トリッピさが好きな人もいます。
短所
キャプチャできるプロンプトの範囲を制限することができます
精度が低い
ナチュラルダークルック
画像の一部がぼやける傾向があり、テクスチャがあまり定義されていない
露出過度、画像のコントラスト部分の傾向
clip_guidance_scale を超える他のスケール値は役に立たないようです
より多くのステップが必要です。250 は良いですが、500 はステッチ、過度の露出を防ぎ、より良い品質をもたらすために好きなもののようです
セカンダリ モデルをオフにするのは非常に困難な場合があるため、colab で機能するはずの設定をいくつか示します。私の意見では、colab の 16 GB を最適に使用するのはこの設定です。多くの人が愛するゴールドスタンダードのようなものです。しかし、自由に遊んで、少し変更してください
範囲スケール: 10k (これは正しく機能しないため、実際には大した問題ではありません)
土のスケール: 10k-50k
テレビスケール: 10k-50k
クリップ ガイダンス スケール: 10k
クランプ_最大: 0.075-0.15
そして: 0.8
ステップ 166、200、または 250
ステップをスキップし、選択したステップの 4 ~ 6% を目指します。したがって、250 の場合は 10 スキップします。200:8、166:~6~7
これを使用する場合、perlin_init を有効にすることを強くお勧めします。混合で大丈夫です
モデル: VITb32、ViTB16、VITL14 + RN101 (または RN50) + RN50x4
言及されていないものがある場合は、デフォルトのままにしておくか、好きなように変更してみてください。
また、2ndモデルをオフにして走行すると、最適点が異なったり、逆に機能するように感じたりする設定もかなりあります。私はそれを完全に解決するためにいくつかの実験を行っています。
しかし、そのような注目すべき変更の1つは、
解像度
セカンダリ モデルを使用する場合、全体的に解像度が高いほど良くなる傾向があります (ただし、1280x768 を超えると大きな改善は見られません)。また、u/relaxed orange による実験から、解像度が特定のポイントを超えて低下すると、かなりの影響を受ける可能性があります。
プライマリーモデルでは、それはあまり当てはまらないようです
ネイティブ モデルは 512x512 サイズの画像でトレーニングされ、その解像度まで下げるか、少なくとも軸の 1 つを 512 にします (または一般的に 512x512 に近いため、これについてはわかりません)、実際にはかなりうまくやる。これは、高解像度が悪いと言っているわけではありません。私は通常 704x832 または 768x960 で実行しますが、それを少し超える解像度では、1 つの画像全体が表示されないことがあります。1280x768 で得たものには満足できませんでした。サイズを変更したり、訓練された解像度から遠く離れたりするストレスと関係があると思いますか? リストされた解像度で取得できる詳細は非常に優れているため、それらをアップスケーリングしても問題なく機能するため、それほど大したことではありません.
**これは 512x512 の例の束です、** どんな種類の最大設定も使用せずに、わずか 8 カット。これは私が今持っている多くの知識よりも前のことであり、正直なところ非常に感銘を受けました2022 年 7 月 4 日
更新: 512x512、512x768、768x960を比較すると、結果はかなり驚異的でした。もちろん、高解像度ではより詳細に取得できましたが、低解像度では非常に説得力のある画像を簡単に取得できました. ここに完全なリンクがあります。** https://drive.google.com/drive/folders/1u-Kjz7_y42C8J1FUa_-UMQ7UsuA7YH-9?usp=sharing**
右から左へ:
768x960
512x768
512x512
解決のジレンマ
これは、私が解決のジレンマと呼んでいるものにつながります。私たちは皆、自然に高解像度の画像を求めています。私がよく目にするのは、Cloud GPU を実行している人が、最大設定で大きな画像を実行しようとしているということです。それはほとんどの場合、私が見たものから失望をもたらします。では、説得力のある外観の画像を取得しながら、豊かな詳細/品質を取得するにはどうすればよいでしょうか?
解決策として 2 つのアイデアがあります。1 つはもう少し複雑ではありません。
より小さく、より安全な解像度で実行し、その出力を ~50% のスキップ ステップで初期化として使用します。それは本当にそれです、それでも完璧ではないかもしれません、そしてそれは私がこの他の潜在的な解決策で探求しているものです
より多くのカットを使用し、 cut_pow を減らします。カット スケジュールのセクションで説明したように、カットは画像全体のサイズから最小サイズ (通常は 224x224) までさまざまです。そして、cutPow を上げている場合、カットはその範囲の底に向かって強く傾向があります。1920x1080 で実行しようとしている場合、このような小さな正方形をカバーするには十分な範囲です。画像全体をカバーするだけで最大 42 のカットが必要になります。これは、そのランダムな性質上、それぞれのカットがたまたま画像全体をカバーする固有の場所にあると仮定した場合です。しかし、私たちが遭遇する問題の一部は、画像に豊かなディテールを得るためにしっかりしたカット パワー値が必要であるということです。これを達成するには、適切な種類の大小のカットが必要であり、残念ながら現在のカット パワーの計算はそうではありません。これに最適化されているようです。さらに、カットのスケジューリング セクションで、私が思いついたいくつかのアイデアについて話します。
縦横比もこれに影響します。インナーカットの最大サイズは、小さい方の寸法によって決まります。これは、 RemiDurant のノートhttps://colab.research.google.com/drive/1peZ98vBihDD9A1v7JdH5VvHDUuW5tcRK#scrollTo=NEAdjUn3RcNmを使用して作成したビジュアルです。
320x1280、このより極端なアスペクト比では、正規分布のスタイルでカットの大部分が中央に向かう傾向があり、画像の大部分が適切に注目されていません。
640x640、正方形の縦横比、インナーカットがキャンバス全体を均等に埋める
どちらも同じ合計ピクセル数ですが、カットの分布が大きく異なります。
カットとカットのスケジューリング
これは真剣に独自の章を取得します。プロンプトの次に、これはおそらくダウンする設定の最大のウサギの穴です.
カットまたはカットアウトは、画像の一部でクリップ ガイダンスを繰り返し利用する方法です。さまざまなサイズのカットアウトにより、全体像を見ることができ、細部にも注意を払うことができます。
Dango の方法のおかげで、カット システムが大幅に改善され、ジェネレーションで全体像や細部に焦点を当てたい場合に合わせて調整できるようになりました。 .
カットアウトがどのように機能するかを視覚化したビデオを次に示します。
** https://www.youtube.com/watch?v=kRhd1xEH6bQ&t=386s**
そして、何が起こっているのかを視覚化するのに役立つこれらの画像について、dicknascarsixtynine に感謝します
画像で実行された
カット すべてのカットは、224x224 (またはそのモデルのエンコーディングのサイズが何であれ) に縮小される正方形の形状である場合があります。
オーバービュー カット。画像全体が正方形に収まるように、黒いフレームのパディングが含まれていることに注意してください。
水平に反転したグレースケールのインナーカット、わずかに角度をつけたもの
典型的なインナーカット
かなり顕著な角度で水平に反転したインナー
カット サイズ、色、傾きが異なる場合があり、さまざまな状況下で画像を表示するために、向きが反転している場合もあります。
オールインワンのグラフィック。
インナーカットのカット サイズの全範囲。ただし、後で説明するように、多くの場合、サイズが小さくなる傾向にあります。
とにかく、これを有利に利用する方法について。
デフォルトでは、Disco はステップごとに 64 カット (CLIP モデルごと)
(16 同時カット) x (4 バッチ)を実行するように設定されてい
ます。少し暗い、または少なくとも露出オーバーの傾向が少ない
これは、私たちが主に話しているセクションになります.
ここのツールチップはとても役に立ちます
括弧内の数字はそのタイプ
のカットの数です * の後の数字は実行される拡散ステップの量ですが、私たちの場合、その数字を 10 で割りますパーセンテージで考えてみましょう
デフォルト
では 最初の 40% で 12 回のオーバービュー カットが実行され、その後 60% で 4 回のオーバービュー カットが実行され、最初の 40% で
4 回のインナーカットが実行され、次にバックで 12 回のインナーカットが実行されます60%
オーバービュー カット + インナーカット = トータル カット。
これらを変更するときは、同じ配列を使用することをお勧めします。これにより、生成の特定のステップで実行しているカットの数に関する混乱が少なくなります。
このような場合、予期しない CUDA のメモリ不足エラーが発生する可能性があります。
ここでは、最初の 40% に対して (12 + 4) 削減を実行し、次の 20% に対して (12 + 12) を実行し、最後の 40% に対して (4 + 12) を実行します。
(12 + 12) カットへの途中での大きなジャンプは、より多くのメモリを必要とし、十分な余裕がない場合、世代のその時点でクラッシュします。
ただし、この形式では、それが発生する可能性は少し直感的ではありません。
これはより明確な見方です。同じ正確なカット スケジュールですが、実行の最初の 40% の後に始まる (12 + 12) カットがどこで発生するかがわかります。
そのため、混乱や不要なエラーを避けるために、これらの両方のアスタリスクの後に同じ数字を使用していることを確認することをお勧めします.
また、実行を完了するには、100 の数字の合計が 1000 になる必要があります。たとえば、
**[12]400+[4]500 - これは合計で 900 になるだけで、実行の 90% に対してのみカットが確立されます。90% の完了に達すると、クラッシュします。
別のケースでは、
**[12]*400+[4]600+[2]200 - これを合計すると 1200 になり、問題なく実行できますが、1000 より後にスケジュールされたカットは使用されません。この例では、すでに終了している 100% マークから 2 カットを使用するように設定されています。
ツールチップにあるように、
オーバービュー カットは常にイメージ全体をカバーし、生成するもののシルエットや全体的な構造を決定するのに適しています。8 月には、この目的のためにさらに特化したいくつかの変更もあります。たとえば、cut_ic_grey で詳しく説明するグレースケールで画像を表示するなどです
。インナーカットは標準カットです。これらのサイズはさまざまですが、 cut_ic_powを使用して特定のサイズになるように選択することもできます。
Cut_ic_pow (cut pow と同じように参照することがよくあります)これらのカットのサイズを 0 で管理し、画像全体をカバーします (ただし、私が知る限り、これは概観カットと同じではないバリエーションなどの違いがまだあります) および 100 で最小サイズに強制します。 CLIP モデルごとに異なりますが、最小は 224x224 です。モデルの詳細に含めたグラフは、埋め込みサイズについて説明しています。
より高いカット pow = より小さなカットアウト。使用するピクセルの量が少ないため、ノイズ除去を高速化し、その小さなチャンクでかなりの詳細を引き出すことができます。
しかし、いくつかの研究で示されているように、カットパウダーが高すぎると、ディテールが過剰になったり、複数のテーマが生成されたりする可能性があります。
ここで解像度が役割を果たします。
512x512 サイズの画像では、100 の cut_ic_pow があり、少し高いと思いますが、それほど不合理ではありません。各カットは画像の約 20% を表示し、それらの CLIP モデルごとに 64 を使用すると、その地面はちょうどカバーされます細かい
1024x1024 の画像では、224x224 のサイズのカットは画像の 5% 未満しかカバーしませんが、各ステップで画像全体をカバーできるように、CLIP モデルごとに 64 個のカットが必要ですが、少し痩せています。 . この数を増やすために追加の CLIP モデルを実行することは実際には解決策ではありません。理想的には、それらが多かれ少なかれ同じ地面をカバーすることを望んでいます。
ここには逆の関係があるように見えます。「最適な cut_ic_pow」(モチーフを回避し、それでも豊かな詳細を取得することに基づく) は、解像度が低いほど大きくなるか、少なくともうまく機能する値の範囲が大きくなります。
一般に、これらのカットは互いに重なります。しかし、これは良いことです。画像の特定のスポットをかなりの回数カバーすると便利です。
一般的に、5-20は幸せな場所のようです。そして10は、そこから始めて調整するための優れたベースラインになります。
これが現在のカット パワーの計算方法です。(0-1.0)^(cut_ic_pow) の乱数を取り、カットのサイズを決定する乗数として使用されます。ランダムが 1.0 をスローする場合、最大サイズでカットを実行しますが、0 では、指定されたモデルの最小サイズ (ほとんどの場合 224x224) でカットを実行します。
このグラフから、cut_ic_pow が 10 を超えると、乱数の上位 15% を除いて、ほぼすべてのカットが最小で実行されますが、これは依然として一般的に小さいものです。私は現在、これに代わる方法を検討しており、ここで追加の分散が役立つかどうかを確認しています.
Cut_ic_greyは、インナーカットの何パーセントがグレースケールで表示されるかを制御します。したがって、0.2 では、内部カットの 20% でノイズをグレースケールで表示することを目指します。
(コードには、特定のカットに 10% のランダムなチャンスを与えてグレースケールにするビットもあります。そのため、cut_ic_grey で指定されたものはすべてそれに追加されますが、これは説明のためにあまり関係ありません。 )
なぜこれが便利なのですか?
暗視ゴーグルや赤外線カメラを考えてみてください。見ているものの詳細を確認することはできません。明るい色と暗い色を区別できるのは 2 色だけです。
私たちの世代の初期の部分では、私たちが実際に見る必要があるのはそれだけです.シルエットを取得し、オブジェクトを画像の残りの部分から分離する明確で明確なエッジを持つことを目指しています. 方程式から色を取り除くことで、より良い仕事ができるかもしれません.
これにより、画像が白黒になりますか?
いいえ、暗視の例えに戻ると、ペインターは暗視ゴーグルを着用していますが、同じ塗料で作業しています。
デフォルトは [0.2]*400+[0]*600 で、ランの最初の 40% はグレースケールで 20% カットされ、残りのランではフルカラー/グレースケールなしが続きます。しかし、生成の適切な時点で追加のグレースケール カットを使用することには、いくつかの有効な用途があることがわかりました。
これは、いじるための一種のテンプレートです。一般的な考え方は、最初は高く、実行中は低くすることです。生成率が 40 ~ 45% になるまでに cut_ic_grey を 0 にすることをお勧めします。
[0.7]*100+[0.6]*100+[0.45]*100+[0.3]*100+[0]*600
Cutn Scheduling、内面/概観のバランスをとる
特定のケースに特化したさまざまなスケジュールがあると私は信じているので、ここで遊ぶことがたくさんあります. しかし、私の意見では、まだかなり普遍的であるべきデフォルトの一般的な改善として、
Overview: [14]*200+[12]*200+[4]*400+[0]*200
Innercut: を試すことができます: [2]*200+[4]*200+[12]*400+[12]*200
デフォルトにかなり近いですが、最初の 20% のインナーカットが削減され、2 つの余分なオーバービュー カットと交換されました。画像の断片化を減らすのに役立つことがわかりました。また、最後の 20% のオーバービュー カットは、その時点では実際には何もしないため、完全に削除しました。必要に応じて、最後の 20% のインナーカット数を 12 から 16 に増やすことができます。 .
このすべてをもう少し深く掘り下げるために、画像の最初の 50% に設定したスケジュールは、そこからどこへ行くかについて非常に重要です。50% 後は、インナーカットを積み重ねるだけで、ディテールがうまく埋められます。
ただし、その前に、イメージの基盤、特に最初の 20% を決定するために多くのことを行います。実行の約 20% までに気付いたかもしれませんが、実行がどのように見えるかについてある程度のアイデアを持っています。まだ完全にはほど遠いですが、少なくとも被写体の概要はわかります。
私は、実行の少なくとも最初の 20% は同じカットを実行する必要があると考えています。切り替えすぎて混乱を避けるためです。手元に例はありませんが、最初の 10% で特定の組み合わせを実行し、そこから別の組み合わせに切り替えようとすると、常に問題が発生しました。
これはすべて解像度、モデル設定などに依存しますが、私は次のような他のカット スケジュールをいじるのが好き
です: [15]*200+[12]*200+[4]*400+[0]*200
インナーカット: [1]*200+[4]*200+[12]*400+[12]*200
概要: [16]*200+[12]*200+[4]*400+[0]*200
インナーカット: [0]*200+[4]*200+[12]*400+[12]*200
概要: [16]*300+[12]*100+[4]*400+[0]*200
インナーカット: [0]*300+[4]*100+[12]*400+[12]*200
最初のものは、私が提供した元のものとかなり似ていますが、実験するために何か違うだけです. 2 番目のものは最初の 20% に対して 0 のインナーカットを行い、3 番目のものは最初の 30% に対して 0 を行います。
この 0 インナーカットは試してみるのにかなり人気があります。でもフィギュアなどにも使えそうで、断言する人もいます。表示される次の画像はすべて VITL336 で作成されたものです。これらも公式の実験によるものではなく、設定を変更して楽しんで実行しただけであることに注意してください。シードは一定ではありませんが、その他のほとんどの設定はすべてが一定に保たれていない場合のカットの変化。
https://lh4.googleusercontent.com/rV2LeD_NU49__NSrZOG8oL1fT47w_mMXH6j3h_XoEM3yeCBibjCOzFduuCa_bjw8r7g8M_zwRb_YDN-6Gb2Dauami-Z7wedD9hKBBNoS1VOkWIw0pBnHO0GvZm385mDzhv-Id31orne3rvvqUg
This was done with 0 innercuts for the first 40% and still a nice result. (色と照明を強調するための後処理が少しあります)
とてもきれいな画像です。とても気に入っています :) が、背景もかなり静かです。
世代の 20 ~ 40% でインナーカットが 0 である他の例を次に示します。ここで傾向に気付くと思います。
いくつかの風景/場所
フィギュアはかなりうまくいっているようで、おそらく静かな背景が有利に働いていますが、風景 + ロボットがいる中世の旅館には、空のスペース、奇妙な視点、背景にあるべきかどうかについて混乱する要素の問題があります/前景。
これは、そのような画像には、すぐに細かいディテールを配置する必要があるためだと思います。最初から、これらのロボットを酒場のどこに配置するかを決定するために必要です。「シルエット」の考え方は、このような種類の画像には当てはまりません。これら
とのいくつかの比較:
左上から始めて、最初の 20% のインナーカットの数: 0、1、2。間違いなく最初のものは最も忙しくないですが、他のものに現れるクールな詳細のいくつかを見逃しています.
最初は最初の 20% の 2 つのインナーカットで行われ、他の 2 つは最初の 20% の 1 つのインナーカットで行われました。
一方、これらはすべて、最初の 20% は 0 インナーカットで行われました。一部の種子が運が良かったというランダム性の要素を却下するのは悪い研究でしょうが、これは特定の詳細、したがって早い段階でより多くの内部カットが最初から必要なケースの1つであり、ヘッドを区別するのに役立ちます.
更新: 2022 年 7 月 21 日: 最初の 20% のカット パウダーとインナーカットの数を比較した調査**
https://drive.google.com/file/d/19ekqvNRDN1U-06CvlWH9P4L4M6u1Lln1/view ? usp=sharing**
低解像度版はこちら。
独自のカット スケジュールの設計、いくつかの指針
メモリ要件に合わせてモデルや解像度をいじるとき、カット スケジュールのカット数を調整しなければならないことがよくあります。
私が行ってきた方法は、内部/概要の比率ではなく、あらゆる種類の実行にわたって設定された数の内部カットを持つことです。ここで概説したこと:
[2]*200+[4]*200+[12]*400+[12]*200
少なくとも最初の 40% はかなり一定です。ただし、作業する余分なカットがある場合。I may stack some extra innercuts post 40%
[2]*200+[4]*200+[18]*400+[18]*200
より緩やかな流れのためにいくつかの余分な配列を追加することも考えられますが、試してはいけません特に早い段階で切り替えすぎると、これは不必要に複雑になる可能性があります。
[2]*200+[4]*100+[6]*100+[10]*200+[12]*200+[12]*200
一般的に、私はこれらの一貫性を保っており、残りのメモリはすべて、だまされた概要スケジュールに入れられます
。
吹き飛ばす余分なメモリがあり、時間の増加を気にしない場合。
24 カットの最初にいくつかの概観カットを積み重ねます。おそらく次のようなものです
: 4]*200+[12]*400+[12]*200私は 40% を超えるとすぐに概要のカットをやめます。50% を超えるとかなり無意味になりますが、安心のためにいくつかは残しておきます。最後の 20% を 0 に落とす
追加の概要カットにより、構造の改善に気付くでしょう。これは、カットがどのように機能するかを本当によく理解する前に、私がずっと前に行った研究です. それ以来、設定を失いましたが、それは基本モデルであり、CGS がおそらく 15k であり、cut_pow が 10 であることを除いて、デフォルト設定です。基本的に、デフォルト カットで 1
を実行しました。 (a)概要: [12]*400+[4]*600インナーカット: [4]*400+[12]*600 1 インナーカットを 2 倍に(b)オーバービュー: [12]*400+[4]*600インナーカット: [8]*400+[24]*600 1 オーバービュー カットを使用doubled (c)概要: [24]*400+[8]*600インナーカット: [4]*400+[12]*600すべてのカットを 2 倍にした 1
(d)
概要: [24]*400+[8]*600
インナーカット: [8]*400+[24]*600
A
B
ハ
D
間違いなく、私が得たドラゴンに最も近いのは A でした。
これは KyrickYoung が行った研究で、カット数を増やすだけでなく、良いカットを行うことの重要性と、多くのインナーカットと並行してハイカット パウを使用すると、どのように奇妙なことが起こるかを示しています。** https://twitter.com/KyrickYoung/status/1502119135446245386**
注: cut_ic_pow の最大値は 100 です。1000 に設定すると、100 に戻るだけです。特に、100 回と 1000 回の実行の類似性が明らかです。
KyrickYoung による別の Cut_scheduling の研究は、カットに対する私の考え方を概説し、そこから始めるのに役立ちました。
** https://twitter.com/KyrickYoung/status/1501729296376860674**
ここでは、右上隅とその下の隅が最良の組み合わせであると信じるようになります。堅固で首尾一貫したランドスケープと、いくつかの非常に説得力のある建物があります。
ただし、これらの出力では、物事はもう少しバラバラになりました。おそらく、最初に見た改善は、アーティスト スタイルの一部として珍しい建物の形を受け入れることに加えて、一般的により多くのカットがあり、風景は一般的に「ごまかすのが簡単」であり、特にこれが行われたことに注意してください。 cut_ic_pow 1 で、インナーカットのサイズはほぼオーバービュー カットのサイズまで変動します。これをデフォルトのインナーカット スケジュールで再度実行し、余分なカットをオーバービューに再割り当てすることを望みます。
これは、私が見つけたものにあまり自信がないセクションですが、確かにいくつかのパターンがあるようです. これらを超えて他の組み合わせを使用したしっかりとした同じシードカットの研究は、私も同様に行うつもりであり、何かを実際に試して確立することができます.
いくつかの優れたベースライン設定、多くのお気に入り
設定に関するこのすべての話を締めくくるには、実証済みの設定の組み合わせをいくつか紹介する必要があると思います。これらは Colab 内に収まり、信じられないほどの費用対効果を提供します。また、個々のパラメーターをテストしてそこから変更する場合も、開始するのに適した場所です。
一般的に言及されていないパラメーターは、それほど影響が大きくないか、まったく機能しない可能性があります。好きなように自由に遊んでください。
セカンダリモデルあり
解像度: > 512x832 が望ましいです。それ以外の場合は、解像度に非常に柔軟に対応できます
1280x960 を超えると、収益が減少し、品質が停滞する可能性があります
カットバッチ: 2-4、より多くの時間を費やしたい場合: 2-8
ステップ: 250、333、500。250は、露出オーバーの問題のリスクがはるかに高くなります。
クリップモデル
ViT32b - 推奨
ViT16b - 推奨
ViT14L - 推奨
RN50 - 推奨
RN101 - rn50 用のオプションのスイッチ
RN50x4 - 推奨
RN50x16 - メモリが許す場合
クリップガイダンススケール - ~15-25k
そして: 0.7-1.0
Clamp_Max :ステップ/プロンプトに応じて0.05-0.1露出オーバーを避ける
Cut_ic_pow: 5-15
Secondary_model なし (この構成はほとんどの colab GPU の最大メモリ使用量近くで実行されるため、特定の値はより具体的になります)
解像度: 512x768
カットバッチ: 2-4、より多くの時間を費やしたい場合: 2-8
ステップ: 100、125、166、200、250
クリップモデル
ViT32b - 推奨
ViT16b - 推奨
ViT14L - 推奨
RN50 - 推奨
RN101 - rn50 用のオプションのスイッチ
RN50x4 - 推奨
RN50x16 - メモリが許す場合
クリップ ガイダンス スケール - ~10k-25k
そして: 0.7-1.0
Clamp_Max :ステップに応じて0.1 ~ 0.2
Cut_ic_pow: 20、 (5-50)
Sat_scale 10k-50k
TV_scale 10k-50k
Range_scale 10k-50k
この記事が気に入ったらサポートをしてみませんか?