
簡単!StableDiffusionWebuiで推しポーズ画像のモデル変更方法 t2i ControlNet Tile 編

概要
皆さんは、「このモデルの雰囲気好きなんだけど、このモデルを使うとこういうポーズがなかなか出て来ないんだよね…」。「だけど、何とかしてこのモデルの子でこの画像のポーズをさせたい!」と、思うことはありませんか? 私は毎日あります!

今回は、t2i の ControlNet Tile を 使用し、任意のモデルで出来る限り指定の構図にする方法について、備忘録兼ねてまとめます。
検証に使用したモデルは、BDさんの BreakDomainAnime_a0440 と、ninekeyさんの ninekeymix12 v2.0 です。
準備
こういうポーズをさせたいと思う人物PNG画像を用意します。

表示させたい人物を生成するモデルを決めます。

以上で、準備は終了です。
しいて言えば、ポーズ画像はプロンプトデータ付きが理想です。データ付きが無い場合は、精度が落ちますが拡張機能の「タグ付け(Tigger)」を使用して、プロンプトを作成して下さい。
Tigger 拡張機能は github 上に、toriato氏によって公開されています。
Automatic1111 にインストールするには、「機能拡張」タグをクリックすると出てくる「URLからインストール」をクリックし、「拡張機能のリポジトリのURL」下のウィンドウに、githubの配布リポジトリのURL
「 https://github.com/toriato/stable-diffusion-webui-wd14-tagger 」
を入力し、「インストール」をクリックしてインストールします。
インストールしたら「インストール済」タグをクリックし、下の一覧に追加されていることを確認して、「適用してUIを再起動」をクリックしWebUIを再起動します。うまく更新が反映されない場合はブラウザを更新するか、WebUIを終了して再度起動してみて下さい。
やり方
1.ポーズ画像の下処理
用意したポーズに不要な部分や問題ある部分がある場合は、伝家の宝刀「Lama Cleaner」で先に消してしまいます。画像に問題が無ければこの作業は不要ですので次に進んで下さい。
特に手や腕、指周りは結果に大きく影響しますので丁寧に消します。ただし、綺麗に修正する必要はありません。ざっくり「この辺りが手や指になる」程度の修正で構いません。

2.ポーズ画像を「PNG内の情報を表示」へ
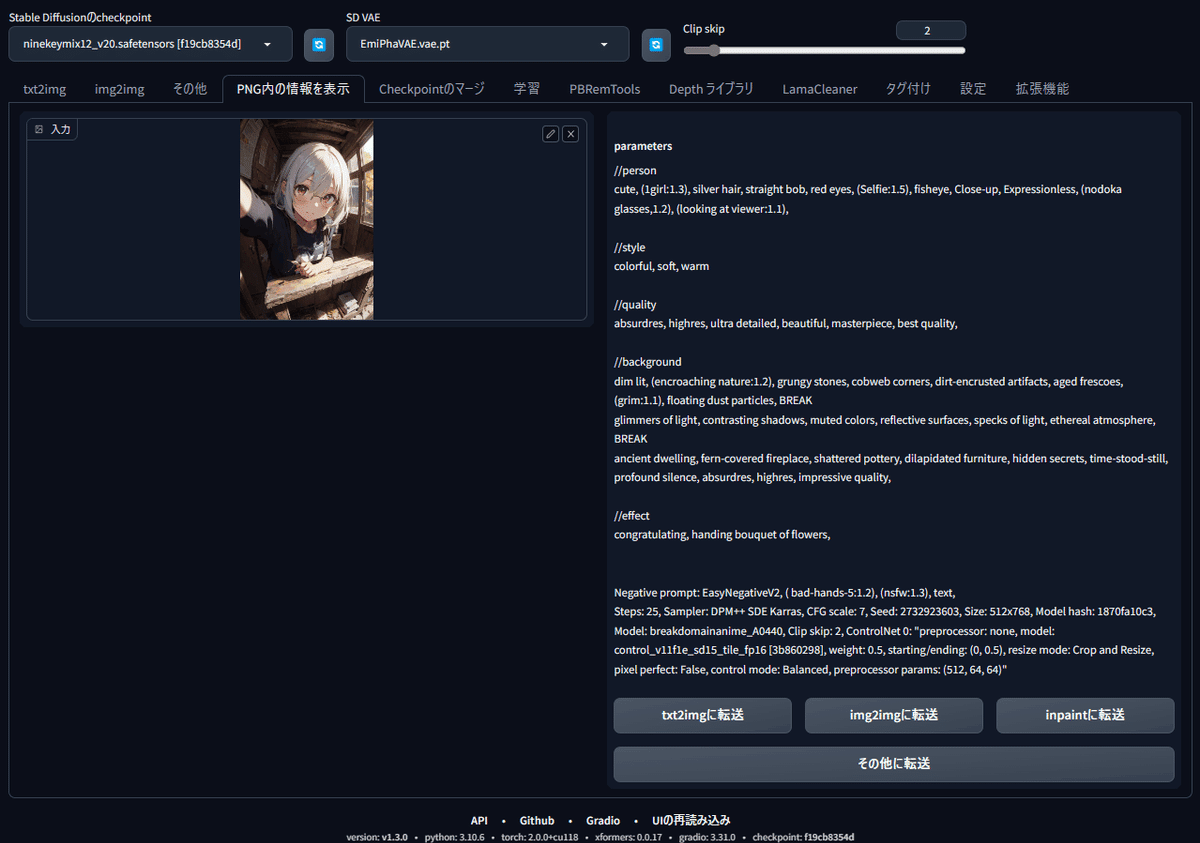
ポーズ画像を「PNG内の情報を表示」のウィンドウへドラッグ&ドロップし、「txt2imgに転送」をクリックしてプロンプトデータを「txt2img」に送ります。
3.モデルと「txt2img」の設定
「txt2img」タグをクリックし、送ったプロンプトデータの内容を確認したら、「Stable Diffusionのcheckpoint(モデル)」を表示させたい人物を生成するモデルに変更し、SD VAE と Clip skip、サンプリングステップ数、CFGスケール をモデル推奨の数値に変更します。


4.ControlNet の設定
ControlNet は「Tile」を選択し表示されたウィンドウへ、修正後のポーズ画像をドラッグ&ドロップします。

プリプロセッサは none を指定、モデルは tile を指定します。そして Control Weight と Ending Control Step はデフォ「1.0」、Control Mode を「ControlNet is more important」に設定します。それ以外の設定は画像を参照して下さい。私はVRAM6GBの低VRAMPCなので、「低VRAM」にチェックを入れていますがVRAM12GB以上の場合は不要のようです。
試しに Control Weight と Ending Control Step を「0.5」に下げて画像生成してみます。

ControlNet の影響が薄くなり、モデル本来の持ち味が強く出るようになりました。
もう一つ試しに、Control Mode はデフォの「Balanced」で、画像生成してみます。

Control Weight と Ending Control Step を「0.5」に下げた時程ではありませんが、モデル本来の持ち味が強くなり机や壁などの素材が変わりました。
以上で合成するための設定は終わりです。まずは、高解像度補助を使用しないで一度画像生成をしてみます。

指はおしいところまできていますが大変な事になっています。でもここでは気にせず次に進みます。
調整
1.「高解像度補助」の設定
最終的にもっと高解像度な画像を完成画像とすると思いますので、次は「高解像度補助」を使用した状態で調整を行っていきます。
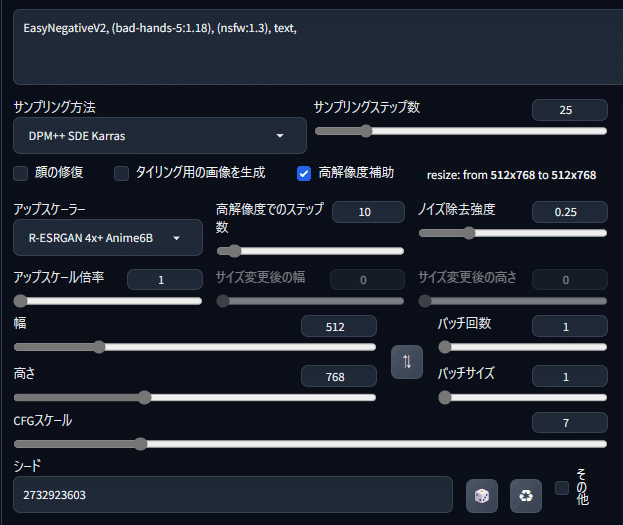
仮画像の指の状態はネガの embedding「bad-hands-5」が強く影響し過ぎているように感じた(単なる勘です)のでほんの気持ち重要度の数値を下げて、「高解像度補助」にチェックを入れ、「アップスケーラー」と「ノイズ除去強度」を設定します。「アップスケール倍率」はまだ調整段階なので、「1.0」倍にします。
なお、アップスケーラーに「R-ESRGAN 4x+ Anime6B」を、この場合のノイズ除去強度を「0.25」にしているのは、過去の経験による単なる私の好みです。皆様が普段使用されているものをご使用下さい。
2. Tiled Diffusion と Tiled VAE の設定
Tiled Diffusion と Tiled VAE も下記画像を参考にて使用するように設定します。
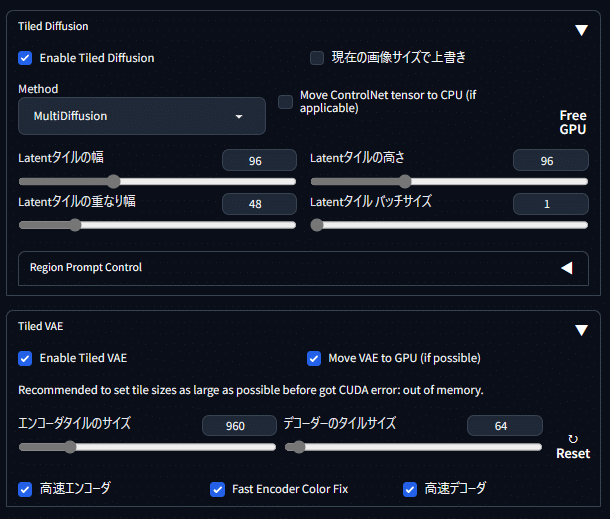
それぞれの数値は私のPC環境でのデフォ値です。VRAM容量で自動的に数値は設定されるようなので、特に変更する必要な無いと思います。ただし、高解像度時にメモリエラーで画像生成が出来ない場合は、それぞれの数値を半分程度まで下げて再挑戦してみて下さい。時間は余計に掛かるようになりますが、エラー出ずに画像生成できるようになるかもしれません。
そして「生成」をクリックして、この状態で画像の再生成を行います。何度か「bad-hands-5」の数値を調整し指の状態を確認して、問題無い(修正可能な範囲の)画像が出力されたら調整作業は終了です。

完成
アップスケール倍率を希望の倍率に設定します。
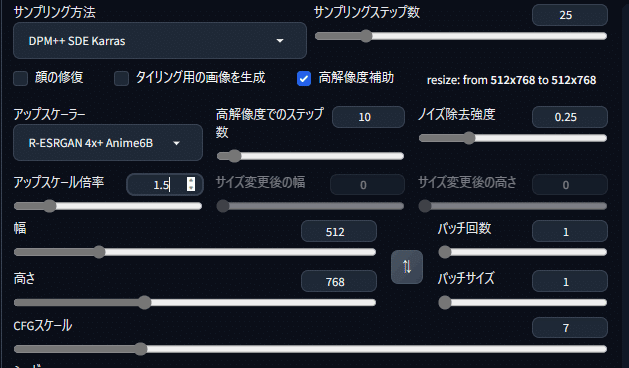
今回は私のPCが低VRAM環境である事と生成時間短縮のため「1.5」倍に設定しました。「生成」をクリックして、高解像度の画像を出力します。

出来ました!
でも、右上窓の黒染みとまだ指が少し気になります。こういう時は、また伝家の宝刀「Lama Cleaner」の登場です。気になる部分を消去した完成画像がこちらです。

余談
一応画像は完成しましたが、自分的には表情が少し物足りなく感じてきました。そこでプロンプトに「grin」を足して少し「ニカッ!」とさせてみます。

なかなか良い感じになりました。では、この画像を基に「1.5」倍したところ…、

プロンプトに表情に関する単語を入れている場合で、特に笑いや微笑みや目の開き具合に関するの単語を入れていると、高解像度時にその単語の意味も高解像度(強調?)されてしまうのか、目が見開かれて「くわっ!」っという感じの表情になる場合があります。
その際は、該当すると思われる単語を抜いてプロンプト調整を行うか、出力画像を加筆修正するしか無いかと思います。今回は「Lama Cleaner」だけを使い、「くわっ!」感を低減してみました。

「Lama Cleaner」、万能過ぎますね。