CoDeFについてメモ

処理について

動画1つごとに一連のニューラルネットを1つ学習。
学習するのはEmbedding(図中の左にある立方体群), 1つ目のMLP, x'y'のEmbedding, 2つ目のMLP
(x', y')を取得するまでの処理に対応するコード deform_pts()
1つ目のMLPの処理に対応するコード
(省略)
(x', y')のEmbeddingに対応するコード
2つ目のMLPの処理に対応するコード
実行のstep
各種ニューラルネットを学習
Canonical Imageの生成
Canonical Imageは基本動画に対して1枚(?)
フレーム数分ではない
Canonical Imageは(x', y') = (x, y)として生成。(Δx=Δy=0)
Canonical Imageに対して変換処理を加える
ControlNetを使用した画像変換など
変換処理を加えたCanonical Imageから動画を再構成
各フレーム(x, y, t)について1つ目のMLPまでのニューラルネットを使用して(x', y')を得る
deform_pts() に対応
Canonical Imageから(x', y')のRGB値をサンプリングする
Lossについて


$${L_{rec}}$$ は再構成誤差。2つ目のMLPの出力と実際のrbg値とのMSE?
https://github.com/qiuyu96/CoDeF/blob/137f16c5423d484846857327597bf65c06b92994/train.py#L340-L342
$${L_{flow}}$$ について
optical flowによって推定された対応点がCanonical Fieldで同じ点になるようにする。
Corresponding points identified by flows with high confidence should be the same points in the canonical field.
optical flowが正確であれば、時刻$${t}$$における$${x}$$と時刻$${t+1}$$における$${x + F^{x}_{t \rightarrow t+1}}$$には同じモノが存在しているはず。
これらをCanonical Fieldの中で同じ座標(grid)に写像する。
つまり、$${D(\gamma_{3D}(x, t))}$$ と $${D(\gamma_{3D}(x+F^{x}_{t \rightarrow t+1}, t+1))}$$ の誤差を最小化するような学習をさせる。
(理解できていない点)
なぜ$${-F^{x}_{t \rightarrow t+1}}$$の項が含まれているのか?上述の理解が間違っている?
時刻$${t}$$における$${x}$$と時刻$${t+1}$$における$${x + F^{x}_{t \rightarrow t+1}}$$がCanonical Fieldの中でも$${F^{x}_{t \rightarrow t+1}}$$の位置関係にあるように学習している?




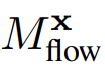
コードを見ると他にも色々lossを使用している?https://github.com/qiuyu96/CoDeF/blob/137f16c5423d484846857327597bf65c06b92994/train.py#L315-L388
この記事が気に入ったらサポートをしてみませんか?