python初心者による花粉飛散量の回帰分析

はじめに
このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています
本記事は花粉飛散量に与えるパラメーターの特定をpythonにて実装するものとなります。
昨今、国を挙げた花粉症対策が話題となったり、家族も花粉症に悩まされているので、関心のある分野でデータ分析を行います。
データの定義
まず、どんな数値に焦点を当てるかを検討します。
花粉飛散総量に影響を及ぼすのは下記サイトによると、気温と日照時間の長さだそうです。
気温が30℃を超え日照時間が多いと花芽が多く作られ、翌年春の花粉飛散量は多くなります。逆に最高気温が25℃程度にしかならないいわゆる「冷夏」では、木は花芽ではなく枝を伸ばすことに注力するため、翌年春の花粉飛散量は少なくなります
なので、気温30度以上の日数及び、日照平均時間を花粉総量の定義としてみます。
下記サイトよりデータセットをあらかじめ用意できました。
どうせなら、私が住んでいる大阪北部の花粉状況を調べたいと思います。
保健所によると、大阪北部の花粉は兵庫県篠山市辺りから飛来すると言われています。
篠山市のデータは取れなかったので、近隣の三田市の気象データとします。
また、花粉飛散量のデータは下記、大阪府茨木保健所のデータを参照。今回はスギ花粉のデータとします。
分析手順
分析手順は以下のような流れとなります。
データの読み込み
データの整理
データの可視化 による相関関係の確認
回帰分析
1. データの読み込み
まずは、必要なライブラリのインポートと気象データの読み込みを行います。
import pandas as pd
import matplotlib.pyplot as plt
import missingno as msno
import numpy as np
!pip install knnimpute
import knnimpute as knnimp
# データの読み込み
df = pd.read_csv("/content/2011以降気象データ.csv", encoding = "shiftJis" )2. データの整理
データの整理を行います。今回、6月~8月の30度以上の日数及び日照時間の平均値と翌年の花粉総飛散量との相関関係を調べます。花粉飛散量は大阪府保健所のデータがありますが、PDFデータしかなかったので、PDFを手入力したものとなります。2011年度から2022年度の気象データを元にそれぞれ翌年の花粉飛散総量を紐づけます。
# ヘッダーの変更
df.columns = ["年", "月" , "日照時間", "a" , "b" , "30度以上の日数" , "c" , "d" ]
# 月列が6、7、8月のいずれかである行をフィルタリング
df = df[df['月'].isin(['6', '7' , '8'])]
# 不要な列を削除
df = df.drop(["a","b","c","d"], axis=1)
#indexの修正
df =df.reset_index(drop=True)
#月列の削除
df = df.drop(columns='月')
#列を文字列からfloatへ変換
df_fcol = df.astype({'日照時間': float,'30度以上の日数': float})
#年の列を元に平均値化
df = df_fcol.groupby('年').mean()
#2024年度の花粉情報はデータがないため 、説明変数である2023年度の気象情報を削除
df = df.iloc[:12]
#花粉総量はcsvがないので 、手入力
df["花粉総量"] = [2179,2530,1405,1679,1203,1482,1563,5349,1029,3530,812,2926]
#花粉総量をfloatに変更
df = df.astype({'花粉総量': float})3. データの可視化による相関関係の確認
バブルチャートにて、可視化を行います。コードは下記です。
label=np.array(["2011","2012","2013","2014","2015","2016","2017","2018","2019","2020","2021","2022"]) #label追加
x = df["日照時間"]
y = df["30度以上の日数"]
pollen = df["花粉総量"]
fig = plt.figure()
ax1 = fig.add_subplot(1, 1, 1)
cm = plt.cm.get_cmap('rainbow') #カラーマップ
scat = ax1.scatter(x, y, c=pollen,s=pollen, alpha=0.5,cmap=cm,vmin=0, vmax=5500) #カラーバーの設定 #引数 (s)に花粉総量pollen
# カラーバーを付加
fig.colorbar(scat, ax=ax1)
for i in range(len(x)): #配列 (x)の開始から最後まで繰り返す
ax1.annotate(label[i],xy=(x[i],y[i]),size=8,color="red")#マーカーに注釈表
ax1.set_xlim(120,250) #X軸の範囲を設定
ax1.set_ylim(12,20) #Y軸の範囲を設定
ax1.set_xlabel("sunshine hours") #X軸ラベル
ax1.set_ylabel("Number of days above 30 degrees Celsius") #Y軸ラベル
ax1.set_title("Annual pollen count")#タイトル
plt.grid() #補助線の追加
plt.show()
x軸に平均日照時間、y軸に30度以上の日数を入力しており、円の大きさが花粉飛散量の大きさを表しています。一見、少しは相関があるようにも思えます。
4. 回帰分析
# 必要なモジュールのインポート
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.linear_model import ElasticNet
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
# データの生成
X = df.drop("花粉総量",axis=1)
y = df["花粉総量"]
train_X, test_X, train_y, test_y = train_test_split(X, y, random_state=42)
# 線形回帰
model = LinearRegression()
model.fit(train_X, train_y)
print("Linear regression:{}".format(model.score(test_X, test_y)))
# ラッソ回帰
model = Lasso()
model.fit(train_X, train_y)
print("Lasso regression:{}".format(model.score(test_X, test_y)))
#リッジ回帰
model = Ridge()
model.fit(train_X, train_y)
print("Ridge regression:{}".format(model.score(test_X, test_y)))
#ElasticNet回帰
model = ElasticNet()
model.fit(train_X,train_y)
print("ElasticNet regression:{}".format(model.score(test_X, test_y)))Linear regression:-0.09195339047771145
Lasso regression:-0.09154334968452149
Ridge regression:-0.09039819571619923
ElasticNet regression:-0.08592975686809057
しかし、結果は相関があるとは言えない結果となってしましました。
分析手法変更
そこで、データの数を多くすることで、別の角度から見てみることにしました。年間の数値データを月間の数値データで取得し、風速や湿度などの気象情報も加味してみます。
残念ながら、大阪の花粉飛散量は年間飛散量しかデータがなかったので、東京都千代田区の月間花粉飛散量と気象データを用いることとしました。
気象データと花粉飛散量データをマージさせたエクセルを下記に用意しました。気象データ5月~9月に対して、千代田区の花粉飛散量は翌年の1月~5月の数値を抽出しています。
今回はスギとヒノキの花粉捕獲数の累積値(単位:個/cm2)となります。
下記、相関行列のヒートマップでCHIYODA Wardに注目してもらうと、30度以上の日数が0.5と弱い相関があることがわかります。
# データの読み込み
df4 = pd.read_csv("/content/東京気象情報・花粉月間 日付調整.csv")
# 相関係数行列を計算
df4_corr = df4.corr()
# ヒートマップを描画
import seaborn as sns
sns.heatmap(df4_corr,cmap='coolwarm', annot=True, fmt='.2f')
plt.show()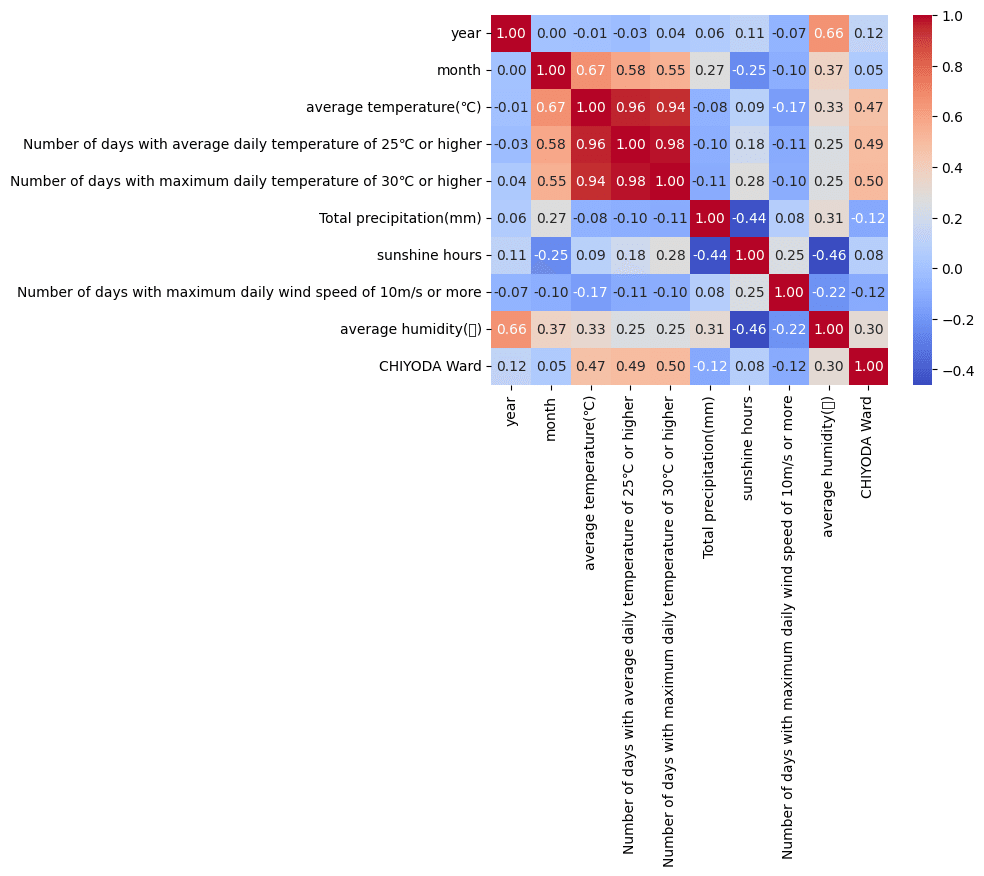
さらに、回帰分析を行うと
# データの生成
X = df4.drop("CHIYODA Ward",axis=1)
y = df4["CHIYODA Ward"]
train_X, test_X, train_y, test_y = train_test_split(X, y, random_state=42)
# 線形回帰
model = LinearRegression()
model.fit(train_X, train_y)
print("Linear regression:{}".format(model.score(test_X, test_y)))
# ラッソ回帰
model = Lasso()
model.fit(train_X, train_y)
print("Lasso regression:{}".format(model.score(test_X, test_y)))
#リッジ回帰
model = Ridge()
model.fit(train_X, train_y)
print("Ridge regression:{}".format(model.score(test_X, test_y)))
#ElasticNet回帰
model = ElasticNet()
model.fit(train_X,train_y)
print("ElasticNet regression:{}".format(model.score(test_X, test_y)))Linear regression:0.293839446945389
Lasso regression:0.29476643361237365
Ridge regression:0.29681686907553795
ElasticNet regression:0.31663251402987713
年間で行った分析よりも改善しました。
まとめ
気温と日照時間の影響が花粉総量に影響を与えるという予測は、相関行列や回帰分析により、気温に関してはある程度の正確性はあると考える。
さらに精度を上げるためには、一度地面に落ちた花粉が自動車によって、再び浮上するため、交通量の影響を加味したり、気温の上昇と湿度の低下が同時に起こる と飛散量が増加する等、複雑な条件を検討する必要があります。
初めてpythonの記事を書いたため、読みづらい所もあったかもしれませんが最後までお読みいただきありがとうございました
この記事が気に入ったらサポートをしてみませんか?