
ComfyUI:Tiled diffusionについて:ワークフローと設定の調整を試みた話

A1111では、あまり何も考えずに「Tiled diffusion」を使用していました。
今回、comfyUIにもある、「Tiled diffusion」について、ワークフローとパラメーターの調整をしてみましたので、その内容について記事にしました。
公式のワークフローは以下です。
エラーが出ないようにするには、カスタムノードのインストールと、コントロールネットのtileモデルが必要です。
若干分かりやすく?まとめたワークフローです。以下のを参考に進めていきます。
全体のフロー説明

青枠部は、通常の生成に相当するフローになります。
赤枠部は、ポジティブプロンプトに相当するものです。上の二つはワイルドカード対応のものです。今回はポニー系のものを前提としています。
緑枠はネガティブプロンプトです。
黄色枠はチェックポイント関係の所です。
生成画像の所から進んだところです。
ここで、画像のアップスケールをしています。
この方法は、一番基本的なやつだったかと思います。これだとデフォルトのサイズと同じなので、画像サイズが変わらないので変更する必要があります。別なノードにして、アップスケールのモデルを設定するのもできます。

VAE Encodeの続きの部分です。
ここも、AYSを使うためのサンプラー設定にしています。
通常のHR Fixと違うのは、モデルのところに「Tiled diffusion」が追加しているところです。
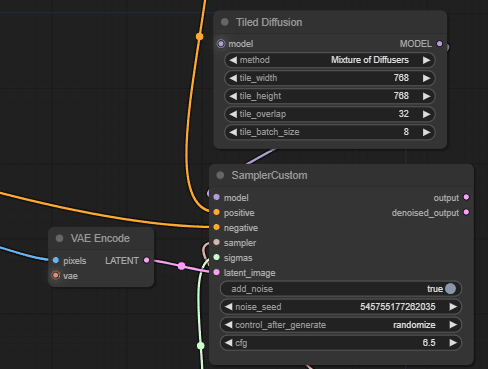
これはコントロールネットのところです。
imageはアップスケールしたものが来ています。
ここは、advanced controlnetの方に変更することも可能です。
このconditionはポジティブプロンプトがつながっています。

サンプラーにつながっているところですが、ここに「Tiled VAE Decoder」がつながっています。通常の「VAE Decoder」の代わりということでしょうか

アップスケールする画像を選択することが出来るようにするため、「Preview chooser」を間に挟んでいます。
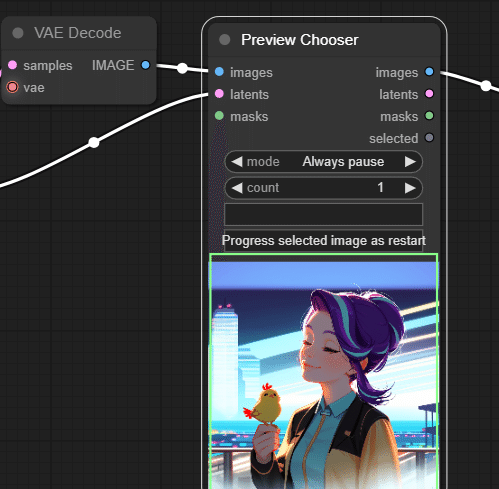



なんだかイマイチな結果です。
ここから数値を調整していきます。
CFGとデノイジングストレスの調整と、コントロールネットのウェイトなどが絵柄に影響すると感じました。
検討した設定変更項目について
①tiled widthの数値についての検討
デフォルトが768なのですが、ディスカッションやA1111を見ると、随分小さい数値の議論をしています。128、256とかにした方が良いかもと、思ったのですが、512以下だと画質が低下しました。768よりも、1024の方が良い色味になったりします。この理由は不明です。タイルが小さい方が時間がよりかかります。
②overlapについての検討
設定によって減らせる様なことが書いてあり、少ない方が処理時間が早くなるようです。デフォルトのmixtureだと16でも良いとか書いてありますが、減らそうとしても減らなかったです。そのままに・・・・
③Tiled VAE Decoderについての検討
デフォルトは1024ですが、1536にしても動きます。その方が早くなりました。
④プロンプトの編集についての検討
上のリンクにある内容で、品質系以外の内容を入れると上手くいかない場合があるとの記載がありました。
やってはみましたが、この場合は、デノイジングを低くしないと画像が劣化する印象です。タイルサイズが小さい場合は品質系のみの方が良いのかもしれません。デノイジングが高めだと、表情が消えたりします。
元のプロンプトがある方が、より雰囲気が増す場合もありました。面倒なのでこちらの方が好きですね。
④デノイジングの数値の調整についての検討
人によって数値の記載内容が違うためモデルとかの相性がありそう。0.5を超えるあたりから書き込みが増えて、元絵から変わり始める印象
0.55近辺が良さそう?
⑤CFGの調整についての検討
高く設定するのもアリとの話
やってみた感じでは、14など高い値でも可能。20だと色味が変な感じになったり、アーチファクトが加わったりする。モデルによる差もありそう。
⑥アップスケーラーの変更についての検討
今のアップスケール処理をしている所を、モデル付きのにするか、この前の記事にあったnnlatent.upscaleを入れるなど。
⑦コントロールネットのウェイトについての検討
0.5 0.49あたりにする。1だとベタッとした感じになる。
このあたりの調整で、アップスケールしたら書き込みが増えた感じがします。
参考まで。




アップスケールには時間がやはりかかってしまう問題があります。
前回記事の方法と比較すると、倍近い時間がかかりました。
ただ、使用するモデルによってはこちらの方が安定したアップスケールの効果が期待できるので使いやすいかもしれません。
<おまけ的なもの>
以下は本家のサイトにあった技術説明を翻訳してもらったものです。参考まで。
Tiled VAE
タイル化VAE(変分オートエンコーダ)は、画像をタイルに分割し、シームレスな生成を行う技術です。
タイル分割: 画像はタイルに分割され、それぞれのタイルはエンコーダやデコーダで11/32ピクセルずつパディングされます。
通常モード:
オリジナルのVAEの処理はタスクキューとタスクワーカーに分解されます。
グループ正規化(GroupNorm)が必要な場合、現在の平均と分散を保存し、RAMに送ります。
全てのグループ正規化の平均と分散を集計し、タイルに適用します。
ジグザグの実行順序を使用して不要なデータ転送を減少させます。
高速モード:
オリジナルの入力はダウンサンプリングされ、別のタスクキューに渡されます。
各タイルは個別に処理され、RAM-VRAM間のデータ転送は行われません。
全てのタイルが処理された後、タイルは結果バッファに書き込まれます。
タイル化拡散法
タイル化拡散法は、潜在画像をタイルに分割して処理する技術です。
マルチ拡散:
UNetは各タイルのノイズを予測します。
タイルは一度オリジナルのサンプラーによってデノイズされます。
タイルは加算され、各ピクセルが加算された回数で割られます。
ミクスチャオブディフューザー:
UNetは各タイルのノイズを予測します。
全てのノイズはガウシアン重みマスクで融合されます。
デノイザーは融合されたノイズを使用して全体の画像を一度デノイズします。
この過程を全てのタイムステップが完了するまで繰り返します。
メリットとデメリット
メリット:
限られたVRAMで非常に高解像度(2k~8k)の画像を生成できる。
シームレスな出力を後処理なしで実現できる。
デメリット:
通常の生成よりも大幅に遅くなる。
勾配計算はこの手法と互換性がなく、backward()やtorch.autograd.grad()が動作しなくなる。
この記事が気に入ったらサポートをしてみませんか?