ラビットチャレンジレポート:ステージ4 深層学習 day4

1. 強化学習
1-1 要点
■強化学習とは
教師あり学習、教師なし学習と並ぶ、機械学習の一分野。
教師あり・なし学習は、データに含まれるパターンを見つけ出すことと、そのデータから予測を得ることを目標としている。
強化学習では、行動の結果として与えられる利益(報酬)をもとに行動を決定する原理を改善していく仕組みを用いて、環境の中で長期的に報酬を最大化できるような行動を選択できるエージェントを作ることを目標としている。

■探索と利用のトレードオフ
環境について事前に完璧な知識があれば最適な行動を予測し決定することが可能だが、強化学習ではこの仮定は成り立たないものとする。行動の中でデータを収集し、最適な行動を見つけていく。
ここで、過去のデータからベストとされる行動のみを取り続けると他のよりよい行動を見つけることができない。逆に未知の行動を取り続けると過去の経験が活かせない。この関係を探索と利用のトレードオフと言う。学習初期ではランダムな方法を多くとり、知識が蓄積されていくにつれ、経験を利用した行動を取るようにすることになる。
■強化学習の歴史
冬の時代があったが、計算速度の進展、関数近似法とQ学習を組み合わせる手法の登場により現在は急速に研究が進んでいる。
・Q学習
行動価値観数を、行動するごとに更新することにより学習を進める方法。
・関数近似法
価値観数や方策関数を関数近似する手法のこと。
■価値関数
価値を表す関数として、状態価値関数と行動価値関数の2種類がある。
・状態価値関数
ある状態の価値に注目する関数。
・行動価値関数
状態と価値を組み合わせた価値に注目する関数。
■方策関数
方策ベースの強化学習手法において、ある状態でどのような行動を採るのかの確率を与える関数。
■方策勾配法
$${J(\theta)}$$は方策を評価する関数であり、期待収益を表す。$${\theta}$$はそのパラメータであり、方策勾配法においては下記のようにパラメータを更新していくことで期待収益を最大化できる$${\theta}$$を探す。

また、$${\pi_\theta(a\mid s)}$$を方策関数、$${Q^\pi(s,a)}$$を行動価値関数として、方策勾配定理が成り立つ。

2. AlphaGo
2-1 要点
人間の棋譜を学習に使用するAlpha Goと、人間の棋譜を学習に使用しないAlpha Go Zeroがある。
■Alpha Go(Lee)
方策関数にあたるPolicyNetと行動価値関数にあたるValueNetからなり、どちらもCNNの構造になっている。


PolicyNetは次の着手予想確率を、ValueNetは現局面の勝率を-1~1で表したものを出力する。
また、探索中に高速に着手確率を出すための、線形の方策関数であるRollOutPolicyも使用される。
これらを使用し、Alpha Goの学習は以下のように進む。
1. 教師あり学習によるRollOutPolicyとPolicyNetの学習
2. 強化学習によるPolicyNetの学習
3. 強化学習によるValueNetの学習
・PolicyNetの強化学習
現状のPolicyNetとPolicyPoolからランダムに選択されたPolicyNetと対局シミュレーションを行い、その結果を用いて方策勾配法で学習を行う。対局シミュレーションではモンテカルロ木探索を使用する。
PolicyPoolとは、PolicyNetの強化学習の過程を500Iterationごとに記録し保存しておいたもの。
・ValueNetの学習
PolicyNetを使用して対局シミュレーションを行い、その結果の勝敗を教師として学習する。
■Alpha Go Zero
Alpha GoとAlpha Go Zeroの違い。
1. 教師あり学習を一切行わず、強化学習のみで作成。
2.特徴入力からヒューリスティックな要素(呼吸点、シチョウ等) を排除し、石の配置のみにした。
3. PolicyNetとValueNetを1つのネットワークに結合した。
4. Residual Netを導入した。
5. モンテカルロ木探索からRollOutシミュレーションをなくした。
Alpha Zeroのネットワーク構造

・Residual Net
ネットワークにショートカット構造を追加し、勾配の爆発、消失を抑える効果を狙ったもの。上記のResidual Blockはこのレイヤーが39層並んでいる。

・Alpha Zeroの学習法
以下の3ステップで学習が構成される。
1. 自己対局による教師データの作成
現状のネットワークでモンテカルロ木探索を用いて自己対局を行い、各局面での着手選択確率分布と勝敗を記録する。
2. 学習
自己対局した教師データを使い学習を行う。Policy部分は教師として着手選択確率分布、損失関数としてCrossEntropyを、Value部分では教師として勝敗のデータを、損失関数として平均二乗誤差を用いる。
3. ネットワークの更新
学習後、現状のネットワークと学習後のネットワークで対局テストを行い、学習後のネットワークの勝率が高かった場合、学習後のネットワークを現状のネットワークとする。
3. 軽量化・高速化技術
3-1 要点
■分散深層学習
深層学習には非常に大きな計算量を必要とし、その量は1年で10倍の速度で増えている。よって、高速に計算を行う方法が必要になる。
分散深層学習は、複数の計算資源を使用し並列的にニューラルネットを構成することで効率の良い学習を行う。
並列化の方法として、データ並列化、モデル並列化が、複数の計算資源を使用する方法としてGPU等を用いることが挙げられる。
◆データ並列化
データ並列化は各モデルのパラメータの合わせ方で同期型か非同期型かが決まる。
・同期型
各ワーカーが計算が終わるのを待ち、全ワーカーの勾配が出たところで勾配の平均を計算し、親モデルのパラメータを更新する。
・非同期型
各ワーカーはお互いの計算を待たず、各子モデルごとに更新を行う。
学習が終わった子モデルはパラメータサーバにPushされる。新たに学習を始める時はパラメータサーバからPopしたモデルに対して学習する。
◆モデル並列化
親モデルを各ワーカーに分割し、それぞれのモデルを学習させ、全てのデータで学習が終わった後で一つのモデルに復元する。
モデルが大きい時はモデル並列化を、データが大きい時はデータ並列化を行うと良い。
◆GPUによる高速化
複雑で連続的な処理が得意なCPUと比較して、GPUは簡単な並列処理を得意とする。ニューラルネットの学習は単純な行列計算が多いので、GPUを使用することで高速化が可能になる。
■モデル軽量化
モバイル、IoT機器など、パソコンに比べ性能が劣るデバイスに搭載する際に有用な手法。
◆量子化
パラメータの64bit浮動小数点を32bit等下位の精度に落とすことでメモリと演算処理の削減を行う手法。
利点
・計算の高速化
・省メモリ化
欠点
・精度の低下
・計算の高速化
倍精度(64bit)と単精度(32bit)の、NVIDIA Tesla V100とNVIDIA Tesla P100での演算速度を比較すると下表のようになり、精度を下げることで計算が高速化できることが分かる。

・省メモリ化
下図のように、精度を下げることで計算のためのメモリの使用量を抑えることができる。

・精度の低下
単精度の下限は$${1.1755494×10^{-38}}$$、倍精度の下限は$${2.225074×10^{-308}}$$になる。実際の問題では、倍精度を単精度にしてもほぼ精度は変わらない。現在のGPUでは、16bit浮動小数点の計算を非常に高速に行えるため、多少精度が落ちたとしても16bitを使用することは有効な選択肢である。
◆蒸留
既に学習済みの、規模の大きなモデル(教師モデル)の出力を教師として軽量のモデル(生徒モデル)を学習させる手法。下図のように、教師モデルの重みを固定し、教師モデルと生徒モデルそれぞれの誤差を使い、生徒モデルの重みを更新していく。

◆プルーニング
モデルの精度に寄与が少ないニューロンを削減することでモデルを軽量化、高速化する手法。ニューロンの削減には、重みが閾値以下の場合ニューロンを削減し、再学習を行う。
下記の表はOxford 102 category ower dataset をCaffeNetで学習したモデルの、プルーニングの閾値ごとの各層と全体のニューロンの削減率と精度をまとめた表。$${\alpha}$$は閾値のパラメータ、閾値は各層の標準偏差$${\sigma}$$とパラメータ$${\alpha}$$の積。結合層のパラメータを95%以上削減しても、精度90%以上を保っている。

4. 応用モデル
4-1 要点
■MobileNet
一般的な畳み込みレイヤーでは、
・入力特徴マップ:$${H×W×C}$$
・畳み込みカーネルのサイズ:$${K×K×C}$$
・出力チャネル数(フィルタ数):$${M}$$
・出力マップ(ストライド1、パディング適用):$${H×W×M}$$
の場合、計算量は$${H×W×K×K×C×M}$$となる。
MobileNetでは、Depthwise ConbolutionとPointwise Convolutionで計算を行う。
・Depthwise Convolution
入力マップのチャネルごとに畳み込みを実施し、出力マップをそれらと結合する。この場合、
・入力特徴マップ:$${H×W×C}$$
・畳み込みカーネルのサイズ:$${K×K×1}$$
・出力チャネル数(フィルタ数):$${1}$$
・出力マップ(ストライド1、パディング適用):$${H×W×C}$$
となるため、合計の計算量は$${H×W×K×K×C}$$となる。
・Pointwise Convolution
入力マップのポイントごとに畳み込みを実施する。出力マップはフィルタ数分だけ作成される。この場合、
・入力特徴マップ:$${H×W×C}$$
・畳み込みカーネルのサイズ:$${1×1×C}$$
・出力チャネル数(フィルタ数):$${M}$$
・出力マップ(ストライド1、パディング適用):$${H×W×M}$$
となるため、合計の計算量は$${H×W×C×M}$$となる。
MobileNetではこの2つの畳み込み計算を個別に行ううことで計算量が削減される。

■DenseNet
畳み込み層にDenseブロックを導入した、画像認識のモデル。
これにより、層の深いニューラルネットワークの学習が可能になっている。

Denseブロックでは、入力にBatch正規化、ReLU関数での活性化、畳み込みの後、出力層に前の層の入力を足し合わせる。


入力のチャンネル数が$${l×k}$$の場合、出力は$${(l+1)×k}$$となる。
ここで、$${k}$$をgrouth rateと呼ぶ。
Denseブロックの後、特徴マップのダウンサンプリングを行うTransition Layer(下図の青四角)と呼ばれる層で次のDenseブロックと繋ぐ。これにより、各Denseブロックで特徴マップのサイズは等しくなる。

■正規化手法
・Batch Norm
レイヤー間を流れるデータの分布と、ミニバッチ単位で平均0、分散1になるように正規化。学習時間短縮、初期値依存の低減、過学習抑制などの効果がある。
$${H×W×C}$$のサンプルがN個あった場合、Nこのサンプルの同一チャネルを正規化する。(下図)
問題点として、Batchサイズが小さい場合に学習が収束しないことがある。

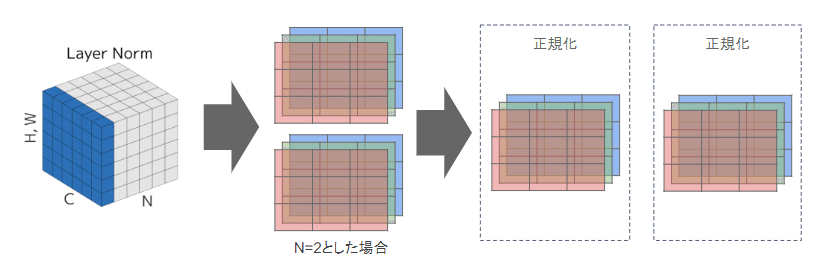
・Layer Norm
N個のサンプルのうち、1つを正規化する($${H×W×C}$$全てのピクセル)
ミニバッチの数に依存しないので、Batch Normの問題点を解消できると考えられる。
・Instance Norm
各サンプルの各チャネルごとに正規化。
コンストラクトの正規化に寄与。画像のスタイル転送やテクスチャ合成タスクなどで利用。

■Wavenet
生の音声波形を生成する深層学習モデル
Pixel CNNを音声に応用したもの。
層が深くなるにつれて畳み込むリンクを話す、Dilated convolutionを適用している。これは、受容野を簡単に増やすことができるという利点がある。
4-2 確認テスト
◆確認テスト①

回答①
入出力画像の縦サイズ:$${H}$$
入出力画像の横サイズ:$${W}$$
フィルターのサイズ:$${D_K×D_K}$$
フィルタ数:$${M}$$
とすると、
(い)$${H×W×D_K×D_K×C}$$となり、通常の畳み込み処理と比べて$${\frac 1 M}$$の計算量となる。
(う)$${H×W×C×M}$$となり、通常の畳み込み処理と比べて$${\frac 1 {D_K^2}}$$の計算量となる。
この時、合計の計算量は
$${\frac {(H×W×D_K×D_K×C)+(H×W×C×M)} {H×W×D_K×D_K×C×M} = \frac {D_K^2 + M} {D_K^2M}}$$
となる。
◆確認テスト②


回答②
(あ)Dilated causal convolution
(い)パラメータ数に対する受容野が広い
4-3 関連事項
instance normalizationについて、いったいどこで使うのだろうと気になったので調べたところ、GANの計算の安定化のため等で使われると分かった。
5. Transformer
5-1 要点
TransformerはAttention機構を利用したEncoder-Decoderモデルである。
ここではまずEncoder-Decoderモデルの1つであるseq2seqを説明し、次いで、Attention機構、Transformerについて説明する。
■seq2seq
系列データを入力に取り、別の系列データを出力するモデル。
入力はRNNによって内部状態に変換され、(Encode)内部状態はDecoderで別の系列に変換され出力される(Decode)
・RNN

RNNは、前の時刻の出力を次時刻の入力とすることで、過去の情報を内部状態に蓄える。
・言語モデル
言語の並びに対して尤度、すなわち文章として自然であるかを確率で評価するモデル。評価は時刻tでの同時確率による。これは事後確率で分解することができるため、時刻t-1までの情報で時刻tの事後確率を求めることで同時確率の計算、評価を行うことができる。

下図のように、同時確率が最も大きくなる値wを求めることができる。
(wを分布で表すことができる)

RNNと言語モデルを使用し、各時刻で次にどの単語が来れば自然であるかを出力できる。

seq2seqでは、Encoder側で文章がEncodeされ、この情報が内部状態としてDecoderに渡される。

DecoderのOutput側に正解データを与えれば教師あり学習を行うことができる。

■Attention, Transformer
seq2seqを用いた機械翻訳では、文章を一つの固定長のベクトルで表現するため、文が長くなると表現力が足りなくなる問題がある。
(BLEUは機械翻訳の評価方法の一つ)

Transformerは、RNNを使わない、Attention機構のみを使用した機械翻訳モデル。seq2seqよりも少ない計算量で高い精度を出すことができる。
・Attention
各単語の関連度に重みをつける手法。
下図のように、単語同士の関連の強さを表現できる。

Attentionの処理としては、下図のようにqueryに合致するkeyを探し、対応するvalueを取り出す操作であるとみなすことができる。

ここで、Attention weightは関連の強さを表す分布となる。
Attentionにはソース・ターゲット注意機構と自己注意機構がある。

どちらも処理としては$${\mathrm{softmax}(\bm{Q}\bm{K}^T)\bm{V}}$$だが、queryとvalueが別の系列の場合ソース・ターゲット注意機構、同じ系列の場合自己注意機構と言う。
・Transformer
TransformerはAttentionを使用したEncoderーDecoderモデルである。
構造は下図のようになっている。
左がEncoder, 右がDecoderである。
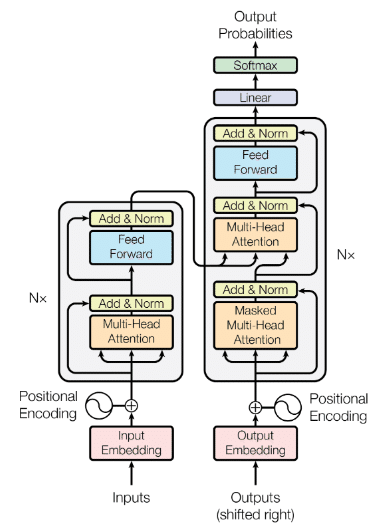
Transformerには、主要なモジュールとして以下の4つがある。
①Positional Encoding
TransformerはRNNを用いないため、語順情報を別で追加する必要がある。
Positional Encodingではposition(pos)のソフトな2進数表現を使い、入出力の単語のEmbedding時に位置情報を埋め込む。

②Scaled Dot-Product Attention
内積でAttentionを計算し、スケーリングを行う。
$${d_k}$$は内部状態の次元数。

③Multi-head Attention
Scaled Dot-Product Attentionを複数のヘッドで並列化する。
Encoderのものと、Decoderの下部のものが自己注意機構、
Decoder中間部にあるものがソース・ターゲット注意機構になっている。
④Position-Wise Feed Forward Network
位置情報を保持したまま情報を順伝播させるニューラルネットワーク
その他の層としてAdd&Normがある。
Add:出力に入力を加算することで入出力の差分を学習させる。学習、テストエラーの低減効果がある。
Norm:各層において、バイアスを除く活性化関数への入力を平均0分散1に正則化。学習高速化の効果がある。
また、DecoderのMasked Multi-Head Attention層では、未来の単語が見えないようマスクする機能も持つ。
最終的にDecoderから出力された情報はソフトマックス関数で確率値として出力される。
5-2 実装演習
seq2seqモデルの実装と学習の様子を確認した。
from os import path
!pip3 install wheel==0.34.1
from wheel.pep425tags import get_abbr_impl, get_impl_ver, get_abi_tag
platform = '{}{}-{}'.format(get_abbr_impl(), get_impl_ver(), get_abi_tag())
accelerator = 'cu80' if path.exists('/opt/bin/nvidia-smi') else 'cpu'
!pip install -q http://download.pytorch.org/whl/{accelerator}/torch-0.4.0-{platform}-linux_x86_64.whl torchvision
import torch
print(torch.__version__)
print(torch.cuda.is_available())
! wget https://www.dropbox.com/s/9narw5x4uizmehh/utils.py
! mkdir images data
# data取得
! wget https://www.dropbox.com/s/o4kyc52a8we25wy/dev.en -P data/
! wget https://www.dropbox.com/s/kdgskm5hzg6znuc/dev.ja -P data/
! wget https://www.dropbox.com/s/gyyx4gohv9v65uh/test.en -P data/
! wget https://www.dropbox.com/s/hotxwbgoe2n013k/test.ja -P data/
! wget https://www.dropbox.com/s/5lsftkmb20ay9e1/train.en -P data/
! wget https://www.dropbox.com/s/ak53qirssci6f1j/train.ja -P data/
! ls data
import random
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from nltk import bleu_score
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.nn.utils.rnn import pad_packed_sequence, pack_padded_sequence
from utils import Vocab
# デバイスの設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.manual_seed(1)
random_state = 42
print(torch.__version__)◆データセットの準備
訓練データの英文と日本語文の確認
! head -10 data/train.en
! head -10 ./data/train.ja
def load_data(file_path):
# テキストファイルからデータを読み込むメソッド
data = []
for line in open(file_path, encoding='utf-8'):
words = line.strip().split() # スペースで単語を分割
data.append(words)
return data
train_X = load_data('./data/train.en')
train_Y = load_data('./data/train.ja')
# 訓練データと検証データに分割
train_X, valid_X, train_Y, valid_Y = train_test_split(train_X, train_Y, test_size=0.2, random_state=random_state)
# まず特殊トークンを定義しておく
PAD_TOKEN = '<PAD>' # バッチ処理の際に、短い系列の末尾を埋めるために使う (Padding)
BOS_TOKEN = '<S>' # 系列の始まりを表す (Beggining of sentence)
EOS_TOKEN = '</S>' # 系列の終わりを表す (End of sentence)
UNK_TOKEN = '<UNK>' # 語彙に存在しない単語を表す (Unknown)
PAD = 0
BOS = 1
EOS = 2
UNK = 3
MIN_COUNT = 2 # 語彙に含める単語の最低出現回数 再提出現回数に満たない単語はUNKに置き換えられる
# 単語をIDに変換する辞書の初期値を設定
word2id = {
PAD_TOKEN: PAD,
BOS_TOKEN: BOS,
EOS_TOKEN: EOS,
UNK_TOKEN: UNK,
}
# 単語辞書を作成
vocab_X = Vocab(word2id=word2id)
vocab_Y = Vocab(word2id=word2id)
vocab_X.build_vocab(train_X, min_count=MIN_COUNT)
vocab_Y.build_vocab(train_Y, min_count=MIN_COUNT)◆テンソルへの変換
・文章を単語IDに変換する関数、データセットからバッチを取得するデータローダーを定義。
def sentence_to_ids(vocab, sentence):
# 単語(str)のリストをID(int)のリストに変換する関数
ids = [vocab.word2id.get(word, UNK) for word in sentence]
ids += [EOS] # EOSを加える
return ids
train_X = [sentence_to_ids(vocab_X, sentence) for sentence in train_X]
train_Y = [sentence_to_ids(vocab_Y, sentence) for sentence in train_Y]
valid_X = [sentence_to_ids(vocab_X, sentence) for sentence in valid_X]
valid_Y = [sentence_to_ids(vocab_Y, sentence) for sentence in valid_Y]
def pad_seq(seq, max_length):
# 系列(seq)が指定の文長(max_length)になるように末尾をパディングする
res = seq + [PAD for i in range(max_length - len(seq))]
return res
class DataLoader(object):
def __init__(self, X, Y, batch_size, shuffle=False):
"""
:param X: list, 入力言語の文章(単語IDのリスト)のリスト
:param Y: list, 出力言語の文章(単語IDのリスト)のリスト
:param batch_size: int, バッチサイズ
:param shuffle: bool, サンプルの順番をシャッフルするか否か
"""
self.data = list(zip(X, Y))
self.batch_size = batch_size
self.shuffle = shuffle
self.start_index = 0
self.reset()
def reset(self):
if self.shuffle: # サンプルの順番をシャッフルする
self.data = shuffle(self.data, random_state=random_state)
self.start_index = 0 # ポインタの位置を初期化する
def __iter__(self):
return self
def __next__(self):
# ポインタが最後まで到達したら初期化する
if self.start_index >= len(self.data):
self.reset()
raise StopIteration()
# バッチを取得
seqs_X, seqs_Y = zip(*self.data[self.start_index:self.start_index+self.batch_size])
# 入力系列seqs_Xの文章の長さ順(降順)に系列ペアをソートする
seq_pairs = sorted(zip(seqs_X, seqs_Y), key=lambda p: len(p[0]), reverse=True)
seqs_X, seqs_Y = zip(*seq_pairs)
# 短い系列の末尾をパディングする
lengths_X = [len(s) for s in seqs_X] # 後述のEncoderのpack_padded_sequenceでも用いる
lengths_Y = [len(s) for s in seqs_Y]
max_length_X = max(lengths_X)
max_length_Y = max(lengths_Y)
padded_X = [pad_seq(s, max_length_X) for s in seqs_X]
padded_Y = [pad_seq(s, max_length_Y) for s in seqs_Y]
# tensorに変換し、転置する
batch_X = torch.tensor(padded_X, dtype=torch.long, device=device).transpose(0, 1)
batch_Y = torch.tensor(padded_Y, dtype=torch.long, device=device).transpose(0, 1)
# ポインタを更新する
self.start_index += self.batch_size
return batch_X, batch_Y, lengths_X◆モデルの構築
Packe sequence
# 系列長がそれぞれ4,3,2の3つのサンプルからなるバッチを作成
batch = [[1,2,3,4], [5,6,7], [8,9]]
lengths = [len(sample) for sample in batch]
# 最大系列長に合うように各サンプルをpadding
_max_length = max(lengths)
padded = torch.tensor([pad_seq(sample, _max_length) for sample in batch])
padded = padded.transpose(0,1) # (max_length, batch_size)に転置
# PackedSequenceに変換(テンソルをRNNに入力する前に適用する)
packed = pack_padded_sequence(padded, lengths=lengths) # 各サンプルの系列長も与える
# PackedSequenceのインスタンスをRNNに入力する(ここでは省略)
output = packed
# テンソルに戻す(RNNの出力に対して適用する)
output, _length = pad_packed_sequence(output) # PADを含む元のテンソルと各サンプルの系列長を返すEncoder
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
"""
:param input_size: int, 入力言語の語彙数
:param hidden_size: int, 隠れ層のユニット数
"""
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size, padding_idx=PAD)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, seqs, input_lengths, hidden=None):
"""
:param seqs: tensor, 入力のバッチ, size=(max_length, batch_size)
:param input_lengths: 入力のバッチの各サンプルの文長
:param hidden: tensor, 隠れ状態の初期値, Noneの場合は0で初期化される
:return output: tensor, Encoderの出力, size=(max_length, batch_size, hidden_size)
:return hidden: tensor, Encoderの隠れ状態, size=(1, batch_size, hidden_size)
"""
emb = self.embedding(seqs) # seqsはパディング済み
packed = pack_padded_sequence(emb, input_lengths) # PackedSequenceオブジェクトに変換
output, hidden = self.gru(packed, hidden)
output, _ = pad_packed_sequence(output)
return output, hiddenDecoder
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
"""
:param hidden_size: int, 隠れ層のユニット数
:param output_size: int, 出力言語の語彙数
:param dropout: float, ドロップアウト率
"""
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.embedding = nn.Embedding(output_size, hidden_size, padding_idx=PAD)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, seqs, hidden):
"""
:param seqs: tensor, 入力のバッチ, size=(1, batch_size)
:param hidden: tensor, 隠れ状態の初期値, Noneの場合は0で初期化される
:return output: tensor, Decoderの出力, size=(1, batch_size, output_size)
:return hidden: tensor, Decoderの隠れ状態, size=(1, batch_size, hidden_size)
"""
emb = self.embedding(seqs)
output, hidden = self.gru(emb, hidden)
output = self.out(output)
return output, hiddenEncoderDecoder
class EncoderDecoder(nn.Module):
"""EncoderとDecoderの処理をまとめる"""
def __init__(self, input_size, output_size, hidden_size):
"""
:param input_size: int, 入力言語の語彙数
:param output_size: int, 出力言語の語彙数
:param hidden_size: int, 隠れ層のユニット数
"""
super(EncoderDecoder, self).__init__()
self.encoder = Encoder(input_size, hidden_size)
self.decoder = Decoder(hidden_size, output_size)
def forward(self, batch_X, lengths_X, max_length, batch_Y=None, use_teacher_forcing=False):
"""
:param batch_X: tensor, 入力系列のバッチ, size=(max_length, batch_size)
:param lengths_X: list, 入力系列のバッチ内の各サンプルの文長
:param max_length: int, Decoderの最大文長
:param batch_Y: tensor, Decoderで用いるターゲット系列
:param use_teacher_forcing: Decoderでターゲット系列を入力とするフラグ
:return decoder_outputs: tensor, Decoderの出力,
size=(max_length, batch_size, self.decoder.output_size)
"""
# encoderに系列を入力(複数時刻をまとめて処理)
_, encoder_hidden = self.encoder(batch_X, lengths_X)
_batch_size = batch_X.size(1)
# decoderの入力と隠れ層の初期状態を定義
decoder_input = torch.tensor([BOS] * _batch_size, dtype=torch.long, device=device) # 最初の入力にはBOSを使用する
decoder_input = decoder_input.unsqueeze(0) # (1, batch_size)
decoder_hidden = encoder_hidden # Encoderの最終隠れ状態を取得
# decoderの出力のホルダーを定義
decoder_outputs = torch.zeros(max_length, _batch_size, self.decoder.output_size, device=device) # max_length分の固定長
# 各時刻ごとに処理
for t in range(max_length):
decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden)
decoder_outputs[t] = decoder_output
# 次の時刻のdecoderの入力を決定
if use_teacher_forcing and batch_Y is not None: # teacher forceの場合、ターゲット系列を用いる
decoder_input = batch_Y[t].unsqueeze(0)
else: # teacher forceでない場合、自身の出力を用いる
decoder_input = decoder_output.max(-1)[1]
return decoder_outputs◆訓練
損失関数
mce = nn.CrossEntropyLoss(size_average=False, ignore_index=PAD) # PADを無視する
def masked_cross_entropy(logits, target):
logits_flat = logits.view(-1, logits.size(-1)) # (max_seq_len * batch_size, output_size)
target_flat = target.view(-1) # (max_seq_len * batch_size, 1)
return mce(logits_flat, target_flat)学習
# ハイパーパラメータの設定
num_epochs = 10
batch_size = 64
lr = 1e-3 # 学習率
teacher_forcing_rate = 0.2 # Teacher Forcingを行う確率
ckpt_path = 'model.pth' # 学習済みのモデルを保存するパス
model_args = {
'input_size': vocab_size_X,
'output_size': vocab_size_Y,
'hidden_size': 256,
}
# データローダを定義
train_dataloader = DataLoader(train_X, train_Y, batch_size=batch_size, shuffle=True)
valid_dataloader = DataLoader(valid_X, valid_Y, batch_size=batch_size, shuffle=False)
# モデルとOptimizerを定義
model = EncoderDecoder(**model_args).to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
def compute_loss(batch_X, batch_Y, lengths_X, model, optimizer=None, is_train=True):
# 損失を計算する関数
model.train(is_train) # train/evalモードの切替え
# 一定確率でTeacher Forcingを行う
use_teacher_forcing = is_train and (random.random() < teacher_forcing_rate)
max_length = batch_Y.size(0)
# 推論
pred_Y = model(batch_X, lengths_X, max_length, batch_Y, use_teacher_forcing)
# 損失関数を計算
loss = masked_cross_entropy(pred_Y.contiguous(), batch_Y.contiguous())
if is_train: # 訓練時はパラメータを更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
batch_Y = batch_Y.transpose(0, 1).contiguous().data.cpu().tolist()
pred = pred_Y.max(dim=-1)[1].data.cpu().numpy().T.tolist()
return loss.item(), batch_Y, pred
def calc_bleu(refs, hyps):
"""
BLEUスコアを計算する関数
:param refs: list, 参照訳。単語のリストのリスト (例: [['I', 'have', 'a', 'pen'], ...])
:param hyps: list, モデルの生成した訳。単語のリストのリスト (例: ['I', 'have', 'a', 'pen'])
:return: float, BLEUスコア(0~100)
"""
refs = [[ref[:ref.index(EOS)]] for ref in refs] # EOSは評価しないで良いので切り捨てる, refsのほうは複数なのでlistが一個多くかかっている
hyps = [hyp[:hyp.index(EOS)] if EOS in hyp else hyp for hyp in hyps]
return 100 * bleu_score.corpus_bleu(refs, hyps)訓練
# 訓練
best_valid_bleu = 0.
for epoch in range(1, num_epochs+1):
train_loss = 0.
train_refs = []
train_hyps = []
valid_loss = 0.
valid_refs = []
valid_hyps = []
# train
for batch in train_dataloader:
batch_X, batch_Y, lengths_X = batch
loss, gold, pred = compute_loss(
batch_X, batch_Y, lengths_X, model, optimizer,
is_train=True
)
train_loss += loss
train_refs += gold
train_hyps += pred
# valid
for batch in valid_dataloader:
batch_X, batch_Y, lengths_X = batch
loss, gold, pred = compute_loss(
batch_X, batch_Y, lengths_X, model,
is_train=False
)
valid_loss += loss
valid_refs += gold
valid_hyps += pred
# 損失をサンプル数で割って正規化
train_loss = np.sum(train_loss) / len(train_dataloader.data)
valid_loss = np.sum(valid_loss) / len(valid_dataloader.data)
# BLEUを計算
train_bleu = calc_bleu(train_refs, train_hyps)
valid_bleu = calc_bleu(valid_refs, valid_hyps)
# validationデータでBLEUが改善した場合にはモデルを保存
if valid_bleu > best_valid_bleu:
ckpt = model.state_dict()
torch.save(ckpt, ckpt_path)
best_valid_bleu = valid_bleu
print('Epoch {}: train_loss: {:5.2f} train_bleu: {:2.2f} valid_loss: {:5.2f} valid_bleu: {:2.2f}'.format(
epoch, train_loss, train_bleu, valid_loss, valid_bleu))
print('-'*80)結果

9エポック目までは順調に学習が進んでいたが、10エポック目でblueが落ちてしまっている。
評価
# 学習済みモデルの読み込み
ckpt = torch.load(ckpt_path) # cpuで処理する場合はmap_locationで指定する必要があります。
model.load_state_dict(ckpt)
model.eval()
def ids_to_sentence(vocab, ids):
# IDのリストを単語のリストに変換する
return [vocab.id2word[_id] for _id in ids]
def trim_eos(ids):
# IDのリストからEOS以降の単語を除外する
if EOS in ids:
return ids[:ids.index(EOS)]
else:
return ids
# テストデータの読み込み
test_X = load_data('./data/dev.en')
test_Y = load_data('./data/dev.ja')
test_X = [sentence_to_ids(vocab_X, sentence) for sentence in test_X]
test_Y = [sentence_to_ids(vocab_Y, sentence) for sentence in test_Y]
test_dataloader = DataLoader(test_X, test_Y, batch_size=1, shuffle=False)生成
ここでいくつかの出力例を見た。
batch_X, batch_Y, lengths_X = next(test_dataloader)
sentence_X = ' '.join(ids_to_sentence(vocab_X, batch_X.data.cpu().numpy()[:-1, 0]))
sentence_Y = ' '.join(ids_to_sentence(vocab_Y, batch_Y.data.cpu().numpy()[:-1, 0]))
print('src: {}'.format(sentence_X))
print('tgt: {}'.format(sentence_Y))
output = model(batch_X, lengths_X, max_length=20)
output = output.max(dim=-1)[1].view(-1).data.cpu().tolist()
output_sentence = ' '.join(ids_to_sentence(vocab_Y, trim_eos(output)))
output_sentence_without_trim = ' '.join(ids_to_sentence(vocab_Y, output))
print('out: {}'.format(output_sentence))



あまり自然とは言えない文章が出力される場合が多い。
# BLEUの計算
test_dataloader = DataLoader(test_X, test_Y, batch_size=1, shuffle=False)
refs_list = []
hyp_list = []
for batch in test_dataloader:
batch_X, batch_Y, lengths_X = batch
pred_Y = model(batch_X, lengths_X, max_length=20)
pred = pred_Y.max(dim=-1)[1].view(-1).data.cpu().tolist()
refs = batch_Y.view(-1).data.cpu().tolist()
refs_list.append(refs)
hyp_list.append(pred)
bleu = calc_bleu(refs_list, hyp_list)
print(bleu)
次に、配布のコードでTransformerモデルを実行した。
コードが長くなってしまうので、学習の結果とbleuの値を示す。


seq2seqよりもbleuは向上した。
テストデータの翻訳結果を見ると以下のようになった。




seq2seqに比べると分の自然さはかなり向上している。
しかし、まだまだ意味を正確に取れない場合があるようだ。
5-3 確認テスト
◆確認テスト①

回答①
このモデルでは時刻tの出力が時刻t+1の入力になるため、Decoderを学習させる際に連鎖的に誤差が多きなっていく問題が発生する。
◆確認テスト②

回答②
上記の問題を解決するための、Teacher Frocingと呼ばれる方法。入力にターゲット系列を使うことで学習が安定し、収束が早くなるメリットがあるが、評価時は前の時刻にDecoderが生成したものが使われるため、学習時と分布が異なってしまうというデメリットがある。
入力にターゲット系列を使うか、生成されたものを使うか、確率的にサンプリングするScheduled Samplingという手法がある。
5-4 関連事項
今回、評価指標にbleu scoreを用いたが、26程度のスコアのモデルでは翻訳精度に不満があった。下記のサイトに、Google翻訳とDeepLのスコアがあったので転載する。

これを見ると、30点もあればいい方なのかなと感じた。
試しに今回の実装演習で試した例文をGoogle翻訳にかけてみた。
英:i should like to see you this afternoon.
Goolgle翻訳:今日の午後お会いしましょう。
Transfomerモデル:今日の午後君に会いたくない。
英:he lived a hard life.
Goolgle翻訳:彼はつらい人生を送った
Transfomerモデル:彼は一生懸命暮らした。
こういった文をGoogle翻訳にかけた場合のスコアは不明だが、この例では明らかな差が出た。
また、単純なBleuの評価では、n-gramのnが大きくなるとスコアが急減するなど問題点も指摘されている。
6. 物体検知・セグメンテーション
6-1 要点
物体検知タスクでは、画像内の物体のクラス分類と位置情報の検知を行う。
物体検知のタスクとその出力の関係を以下に示す。

分類は物体の位置までは見ない。物体検知、意味領域分割は、物体の位置を見るがインスタンスの区別はしない。
代表的な物体検知・セグメンテーションのデータセットには以下のようなものがある。

■評価指標
通常の分類タスクのように混同行列を用いて、Precision、Recallを算出する。それぞれの定義は以下。

物体検知では、conf.とクラスが出力される。正誤の判定には、クラスの分類結果だけでなく位置情報も評価したいため、IoU(Intersection over Union)を定義する。IoUは正解バウンディングボックスと予測バウンディングボックスの重なり面積を、両者の合計面積(和集合の面積)で割ったものと定義する。

上図では、仮に二つのバウンディングボックスの左上側を正解、右下を予測とすると、重なっているところの面積がTP、左上の白い余白がFN、右下の白い余白がFPとなり、IoUの定義の分母はこれらを足し合わせた値になっている。
■Precision、Recallの計算
①ハイパーパラメータとして、conf.の閾値、IoUの閾値を決める。
②得られた予測値をconf.の大きい順に並べ、conf.が閾値より高いものを抜き出し、これらはモデルの予測がPositiveであるとする。
③予測クラスの正解バウンディングボックスとのIoUを計算し、閾値より高ければTrue、低ければFalseとする。ただし、すでに検知済み(TPが出ている)のクラスであればFalseとする。
④検知できていない(TPが出ていない)クラスがあればFNとする。
この結果をもとに、Precision、Recallを計算、PR曲線を作成する。
PR曲線を下側面積をAPといい、クラスごとのAPの平均値をmAPといい、物体検知モデルの評価指標となる。
■2段階検出器と1段階検出器
物体検知のフレームワークは、2段階検出器と1段階検出器とに分けられる。
◆2段階検出器
・RCNN、RFCN等。
・候補領域の検出とクラス推定を別々に行う。
・相対的に精度が高い傾向。
・相対的に計算量が大きく推論も遅い傾向。
◆1段階検出器
・YOLO、SSD等。
・候補領域の検出とクラス推定を同時に行う。
・相対的に精度が低い傾向
・相対的に計算量が小さく推論も早い傾向。
この記事が気に入ったらサポートをしてみませんか?