
Stable Diffusion系のモデル性能をFIDスコアで確認する2(DaFID-512やオリジナルのFIDスコア編)

先日FIDスコアがあーだこーだどうたらしましたが、続きです。既存の画像とAIで生成した画像の分布を比較することでモデルを評価するみたいな感じです。今回は新しいスコアを2種導入するほか、サンプルサイズを1万枚以上にしています。
こんかいやることー^^^;
7つのモデルを3つのスコアで比較します。
きっかけはbirdManさんが提唱したアニメ画像特化のFIDスコアです。FIDスコアはImageNetを学習したInception-v3を使って計測するのですが、アニメ画像に対応できるかは微妙でした。そこでDanbooru2018のタグ予測モデルを利用したFIDスコア(DaFID-512)を提案されています。
私はこの発想をぱくってWD14-Taggerを利用したFIDスコアもいけんじゃね?とか思ったのでそれもやってみます。WD14-Taggerの最終層手前にある768次元ベクトルを利用してFIDスコアを計測します。名前はとりあえずWDFID-768にしておきます。実装は一番後ろに貼ります。
ようするにFID、DaFID-512、WDFID-768を様々なモデルで計測します。
さんかしゃしょうかいー!
1番、Stable Diffusion 2-1!!!!(以下SD2.1)
本家。
2番、Waifu Diffusion 1-3!!!!(以下WD1.3)
danbooruの画像68万枚くらい学習させているらしい。
3番、でりだモデル!!!!(以下Der)
モデルはこれをお借りしてVAEをマージしたあとdiffusersに変換しています。ミスってたらごめん。
4番、Cool Japan Diffusion(for learning 2.0)!!!!(以下CJD)
20万枚をRTX3090で300時間学習したらしい。気合入ってんな。おそらく計測のために既存のキャラクターを生成しちゃいますが公開しないので問題ないよね。
5番、fate-diffusion(以下FD)
自作です。fateシリーズの画像6万枚くらいを学習させてます。
6番、ucj-diffusion(以下UCJ)
自作です。13万枚くらい学習させています。画像はdanbooruの画像数上位399人のArtistタグから色々取り除きながら持ってきています。名前に意味はない。
7番、NovelAIモデル(NAI)!!!?
リークモデルで1万枚も生成することになるので、入れるか迷ったんですが、やっぱりこのモデルの数字は重要だと思うので入れます。
比較画像
既存画像
danbooruから「1girl order:score rating:general age:<1years」で検索した上位10526枚利用します。正方形にするために、これを利用しました。
生成画像
上で用意した画像にたいして、WD14 Taggerを適用して作ったタグ+キャラクタータグをプロンプトとして使って生成します。SD2.1、FD、UCJは768×768、他は512×512で生成します。でりだは知らんけど他はデフォルトで想定していると思われる解像度に合わせています。設定はstep=20、guidance scale=7.5でやります。
余談:1万枚の生成なんて無理や・・・と思ってましたがxformersの適用をすっかり忘れていました。diffusersのpipelineでやってましたが
pipe.unet.enable_xformers_memory_efficient_attention()を追加するだけです(version 0.7以降)。たった一行でめちゃくちゃ早くなります。webUIを使っている人は3割くらい早くなるイメージだと思いますが、batch sizeをとんでもなくあげられるのでそんなレベルではないです。
注意点
モデルの優劣を決定するものではありません。生成方法によりdanbooruタグを学習に利用していないSD1.4、CJDは不利になると思われます。danbooruのタグ通りに生成できるかどうかが評価点となります。
FIDスコアの計測には画像をリサイズする必要がありますが、そのリサイズ方法としてPillowのresize関数が推奨されているそうです。そこでDaFID-512のresize関数をtorchvisionからPillowに置き換えています。
WDTaggerのタグ付け閾値は0.5にしていますが、トークン数が77を超えてしまうことがあります。その辺の処理をさぼっています。
結果
実画像との比較

マイナスかけて偏差値とってグラフにしてみました。

SD2.1やCJDの評価が低く(danbooruタグを使っていないモデルだから)、WDやでりだ、NAIが高いという予想通りの結果になりました。三種のスコア間でもそんなに傾向が変わらないですね。あまり面白くないです。NAIはDaFIDスコアだけが低く、逆にUCJは高いといった差はありますが、理由まではわかりません。
UCJを作ったのは、loraとかいろいろ実験するために、SD2系のアニメ特化モデルで、なおかつFDのような特定のコンテンツに偏らないモデルが欲しかったからなのですが、スコア的には微妙ですね。
人間の目で見るとSD2.1以外は割とできてます。つまりどれがいいとかわかんないですね。
モデル間での比較
モデル間で比較して似ているモデル等を調査してみます。これはWDFID-768のみでやります。上の結果からどれでやってもそこまで差が出なさそうですしね。
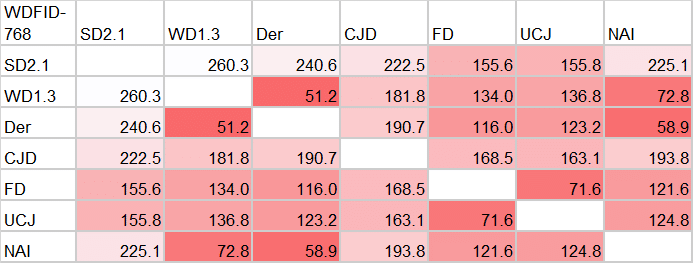
でりだ・WD・NAI(SD1系danbooru三銃士)は相互に似ていて、私が作ったFDとUCJ同士も似ているという結果になってますね。
SD2.1は他のモデルとかけ離れていますが、SD2系から学習したFDとUCJは他よりはまだ似ています。
CJDは他のどのモデルにも似ていません。独自のデータや学習法を行っていることが結果に現れていますね(唯一のSD2-base系という理由もありそうですが・・・)
モデル間の比較という意味ではかなりしっくりくる結果になりました。
課題
確率分布からサンプルするだけの生成モデルと違って、text2imgモデルではプロンプトをどうすればいいかわかりません。birdManさんがやっているような一つのプロンプトで1万枚作るやり方は、そのプロンプトがたまたま得意なモデルが勝つだけですし、だからといって大量のプロンプトを作ろうとしたら、danbooruタグやclip interrogateに頼ることになり、それを学習時に使っているモデルが有利になります。そもそも各モデルに合ったプロンプトを入力することで、はじめて本来のモデルの実力が分かるのだから、ランダムなプロンプトを使って生成すること自体が意味ないことかもしれませんしね。
また解像度の違いも課題です。各モデルで一番得意な解像度は違いますが、生成解像度がFIDスコアに影響する可能性はあります。
ただしモデル間の比較という需要あるかよく分からない目的には使えそうということが分かりました。
付録:WDFID-768の実装
数字出したからには実装も貼るべきだと思うので、おいておきます。keras使うのにtorchのデータローダーを使っていたりとめちゃくちゃですが何かミスがあれば教えてください。モデルのダウンロードと画像が正方形のRGB(透過無し)でjpgかpngであることを前提にしています。必要な環境はよく分かってない^^
<フォルダ名>.npyファイルを勝手に作るので注意してください。(何度もやる必要ないように計算結果を保存することにしています。)
A100 80GBのbatch size=64で2分かかります。
#python <ファイル名>.py <画像ディレクトリ1> <画像ディレクトリ2> -b <vram次第>
#画像ディレクトリの代わりに保存した計算結果:"piyomiyahogetaro.npy"を渡すことができます。
import os
from PIL import Image
import numpy as np
from tqdm import tqdm
from scipy.linalg import sqrtm
from tensorflow.keras.models import load_model, Model
from torch.utils.data import Dataset, DataLoader
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('target', type=str)
parser.add_argument('output', type=str)
parser.add_argument('--image_size', '-i', required=False, default=448, type=int)
parser.add_argument('--batch_size', '-b', required=False, default=64, type=int)
args = parser.parse_args()
class ImageDataset(Dataset):
def __init__(self, file_list):
self.file_list = file_list
def __len__(self):
return len(self.file_list)
def __getitem__(self, i):
img = Image.open(self.file_list[i])
img = img.resize((args.image_size,args.image_size))
return np.array(img)[:, :, ::-1] #cv2形式に変換(RGBtoBGR)
def collate_fn(batch):
return np.array(batch) #batchをnumpyでまとめる
#WD 1.4 tagger
def main():
#モデルパスをべたうち(https://huggingface.co/SmilingWolf/wd-v1-4-vit-tagger)
model = load_model("wd-v1-4-vit-tagger")
#最終層手前のプール層でとめる
model = Model(model.layers[0].input, model.layers[-3].output)
embs = []
for path in [args.target,args.output]:
#.npyじゃなかったら計算
if not ".npy" in path:
files = [os.path.join(path,file) for file in os.listdir(path) if "png" in file or "jpg" in file]
dataset = ImageDataset(files)
dataloader = DataLoader(dataset,batch_size=args.batch_size,num_workers=8,collate_fn=collate_fn)
emb = []
for data in tqdm(dataloader):
probs = model(data, training=False)
emb.append(probs.numpy())
emb = np.concatenate(emb)
#フォルダ名.npyで保存
np.save(path+".npy",emb)
#.npyだったらロード
else:
emb = np.load(path)
print(emb.shape)
embs.append(emb)
#fid計算の実装はhttps://data-analytics.fun/2021/12/31/understanding-fid/からもってきました
real_mu = embs[0].mean(axis=0)
real_sigma = np.cov(embs[0], rowvar=False)
fake_mu = embs[1].mean(axis=0)
fake_sigma = np.cov(embs[1], rowvar=False)
covmean = sqrtm(real_sigma.dot(fake_sigma)).real
fid = np.sum((real_mu - fake_mu)**2.0) + np.trace(real_sigma + fake_sigma - 2.0 * covmean)
print(fid)
if __name__ == "__main__":
main()おまけ、Chatgptに上のコードをべたうちしてみた。
このスクリプトは、次のステップを実行しているようです:
ImageDatasetというクラスを定義して、ファイル名のリストを取り込み、インデックスを指定すると画像データを返すものです。
"wd-v1-4-vit-tagger"というファイルから事前に学習された機械学習モデルをロードし、ターゲット画像データセットと出力画像データセットに対して埋め込みを生成します。
2つのデータセットの埋め込み間のFrechet Inception Distance (FID)を計算し、それらのデータセットのネットワークの特徴空間間の距離を測定する。
埋め込みが存在しない場合は、.npy形式で保存する
Tensorflow, Pillow, Numpy, torchなどのライブラリを使っているようです。また、ArgumentParserを使用しているようです。
だそうですすごいなあ