AIDEMY PREMIUM データ分析講座を受講して

はじめに
この記事は私がAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています
開発環境
Windows10 Home 64 ビット オペレーティング システム、x64 ベース プロセッサ
Python 3.9.13
Google Colaboratory
自己紹介
初めまして noru です。
私は大学の薬学部(6年制)を卒業後、薬剤師として医薬品メーカーに4年半勤め、最近はDX推進や企業文化の変革などを推進する若手のリーダー的立ち位置にいます。
学習開始の背景
昨今の医薬品業界においては、コロナによる生産量の変化、生産体制の変革と法規制の変化や様々な不祥事などにより、業界全体が変革を余儀なくされています。そして医薬品業界を含む医療業界では、昔から新技術の利用が進められておらず、ここ数年で慌てて対応を進めている状況です。
一方で、世間ではAIの活躍が注目を集めており、DX人材、データドリブンな経営が話題となっています。また、人生100年時代や、副業、リスキリングといった言葉もよく聞くようになり、早期退職やリストラといった企業の選択も増えてきています。
これからの時代で自身の価値を高めていく必要があると感じ、私は『薬剤師』×『DX人材・データサイエンティスト』という進路をすすむことにきめました。
最初の半年ほどは、ExelVBA、PythonやSQLなど独学で勉強を始めましたが、個別のスキルの獲得に時間がかかり、プログラミング作業の全体像をつかむということが難しかったため、教育給付金の制度を利用して勉強を行うこととしました。
Aidemy Premiumを選択した理由としては、以下の3点です
サポート体制が手厚い
講座の種類が多数ある (データ分析講座、AIアプリ作成講座など)
期間中であれば、他の講座の講義を受講可能である
受講内容
データ分析講座
はじめてのPython
Python基礎
ライブラリ「NumPy」基礎(数値計算)
ライブラリ「Pandas」基礎(表計算)
ライブラリ「Matplotlib」基礎(可視化)
機械学習概論
教師あり学習(回帰)
教師あり学習(分類)
教師なし学習
時系列解析Ⅰ(統計学的モデル)
データクレンジング
データハンドリング
機械学習におけるデータ前処理
ディープラーニング基礎
自然言語処理基礎
感情分析/株価予測
タイタニック(kaggleのコンペ)
学習成果の実践 (本ブログ)
講座について
私はデータ分析講座を受講することで、データについての統計手法やPythonを利用した主成分の抽出、データモデルについて学ぶことができました。スクレイピングやアプリ・AI開発等は今回の講座に含まれていませんが個人的に一部を受講することができました。
E資格対策講座の追加は忘れていたのでできませんでしたが、担当者にお願いしておけば追加可能です。
学習成果の確認-プログラミングデータ分析の実践-
今回の学習成果を確認するために、Kaggle上にアップされているデータの分析を行うこととしました。
分析対象は【Lifestyle_and_Wellbeing_Data】です。
こちらを選択した理由としては、3つあります。
普遍的な幸福の価値観を評価するということに興味があった。
要素が多く分析手法の検討に価値があると推測した。
ここ数年間Lifestyleの変化を強要された (covid-19) 。
データ分析の流れ
以下に私が行ったデータの分析手順と<コード>を記載します。利用する際は順番にコードを実行することをお勧めします。
作業をトレースしやすいようにその手順ごとの思考を解説していきます。
コード内容の解説は#をご確認ください。
1.データの入手 <コードなし>
作業:最初にサイトからデータをダウンロードし、データ分析を開始します。
解説:今回はすでに存在するデータを利用します。場合によってはスクレイピングなどを利用してデータ収集をすることになります。
2.データの情報確認 <コードなし>
作業:kaggleのページ上のData Cardタブに記載されている情報を確認します。
解説:Data Cardにはどんなデータが収集されているかが記載されています。
要約すると、24項目からなるアンケートの回答15977件からなるデータである。24項目の内容は5つの要素(身体的健康、精神的健康、専門知識、社会的交流、充実度) を細分化したものである。
3.データの可視化 <コードあり>
作業:データの内容と要素がどのような出力となっているか確認します。
さらに直感的に相関を確認しやすいようにヒートマップとして出力します。
解説:NumPyライブラリは数値計算を効率的に行うためのPythonライブラリです。
pandasライブラリはデータ分析に特化したライブラリで、データの操作や分析に用いるデータフレームというデータ構造を提供します。
matplotlibはPythonのグラフ描画ライブラリで、pyplotはその中の一つのモジュールで、グラフの作成と表示に使われます。
seabornライブラリはmatplotlibに基づいたデータ可視化ライブラリで、より美しいグラフやより高度なグラフを簡単に作成するための機能を提供します。
#データ分析で必要となるライブラリを今回のコードで使用しやすい名称に短縮します
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# データの読み込み
life_df = pd.read_csv("/content/Lifestyle/Wellbeing_and_lifestyle_data_Kaggle.csv")
#データの形式を表示する。
prit("⓵データの形式を確認する")
print()
print(f"Life_df_shape:{life_df.shape}\n")
print()
plt.figure(figsize=(15,8))
sns.heatmap(data = life_df.corr(numeric_only = True), annot = True, fmt = '0.3f', cmap = 'GnBu'); 出力結果:①データの形式を確認する
Life_df_shape:(15972, 24)

判明事項:
・15972件のデータについて24列の要素で評価されている (Life_df_shape:(15972, 24))
・それぞれの要素同士にはいくつか相関が認められる (図の青くなっている部分の縦横に関係が深い)
・WORK_LIFE_BALANCEについて影響を与えている要素が多いが決定的な要素はない
発想:
・どんな要素があるか
・要素ごとに影響を調べられるか
次の行動:
・実際にデータの内容を調べたい
4.データの内容を確認
作業:実際のデータを確認します。
解説:全件をみると非常に時間がかかるため、[.head]で上部にあるデータのみを確認します。
# 基本的なデータの確認
print("⓶データの内容を確認する")
#先頭5つを可視化
print(life_df.head())
print()出力結果:②データの内容を確認する

判明事項:
・24の要素はいくつかの塊に分類できそう
発想:
・評価の指標としてWORK_LIFE_BALANCE_SCOREを用いることができるのでは
次の行動:
・データの内容が知りたい
5.データの入力形式を確認
作業:データの入力形式を確認します。
解説:データ分析には数値データの方が都合がいいために、[.info]で内部値の情報を確認します。
Column:データの要素名
Non-Null Count:欠損していないデータの個数
Dtype:入力データの形式(object:文字列や混合データ、int:整数、float:小数点あり)
#分析に入る前に内部値の形式を確認する
print("⓷データの内部値の情報を表示")
print(life_df.info())
print()出力結果:③数値データの内部値の情報を表示
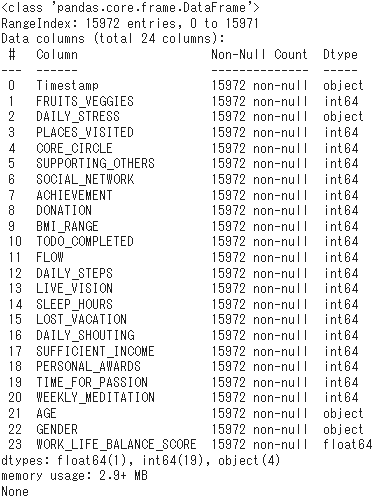
判明事項:
・データ数が15972で統一されているため、データに欠損はなし
発想:
・int64型とfloat64型は数値に基づく分析ができる
次の行動:
・object型について内部値の形式を知りたい。
6.数値で表現できないデータの確認
作業:object型データ(=カテゴリカルデータ)の内容と要素がどのようなデータで入力されているか確認します。
解説:文字列などを含むため、入力形式が多数に分布している可能性があります。そのため、[.describe]で統計的な情報として抜き出します。
# カテゴリカルデータの統計量を表示
print(⓸object型データの内部値の情報を表示")
display(life_df.describe(exclude='number'))出力結果:④object型データの内部値の情報を表示

判明事項:
・TimestampはMM/DD/YYの形式で表記されており、最頻値は7/23/18で162個あった (topとfreqの値から)
・AGEのデータは4つの分類、GENDERは男女2つのデータからなる (uniqueの値から)
発想:
・DAILY_STRESSは数値で表示されているはずだがobject型となっているため、データ入力内容にミスがあるのではないか
・無作為なアンケートのため、時系列に沿って評価しないほうがよい
・すべて数値型に変換できれば分析ができる
次の行動:
・AGEは4つの年代ごとに、GEMDERは男女それぞに数値を割り当てる
・DAILY_STRESSのデータが破損(欠損)している行を削除し、分析可能なデータへと変換する
7-1.データクレンジング①
作業:不正確なデータを削除するため、DAILY_STRESSのデータから数字として認識できないデータを削除する。
解説:利用するデータの量が増えるにつれて、同時にエラーの可能性も高まります。そのため、認識できないデータを空のデータ (NaN) に変換した後、[.dropna]で空のデータを一括で削除する。
print("⓹データクレンジングを実施する。")
# to_numericを使用して数値として認識できないものをNaNに変換
life_df["DAILY_STRESS"] = pd.to_numeric(life_df["DAILY_STRESS"], errors="coerce")
# NaNの含まれている行を削除する。
life_df = life_df.dropna()
#分析に入る前に再度、内部値の状態を確認する
print()
print("再度数値データの内部値の情報を表示")
print(life_df.info())
print()出力結果:⑤データクレンジングを実施する。

判明事項:
・DAILY_STRESSがfloat型 (数値データ) に変換されており、全体のデータ量が1行分減っている (15972 → 15971)
発想:
・ミスがあった行は1行のためデータの母数にほとんど影響を与えない
・Timestampのデータを削除しておくことで分析対象を減らす
次の行動:
・AGEは4つの年代ごとに、GENDERは男女それぞに数値を割り当てる
・Timestampの要素を削除する
7-2.データクレンジング⓶
作業:年齢や性別は、数値でないデータなので適当な数値を割り当てる。
Timestampは結果に影響を与えないので削除する。
解説:AGEのデータ内容の種類は [Less than 20, 21 to 35, 36 to 50, 51 or more]なので、[.dict] でそれぞれに適当な数字を割り当てた辞書を作成する。
辞書の値を順番に参照し、当てはまる場合は数字を代入する捜査を繰り返す。
GENDERについても同様の処理を行う。 (データ内容の種類:[Female, Male])
[.deop ]を用いてTimestampの要素を列データごと削除する。
age_dict = {"Less than 20": 1, "21 to 35": 2, "36 to 50": 3, "51 or more": 4 }
life_df["AGE"] = pd.Series([age_dict[x] for x in life_df["AGE"]], index = life_df.index)
gender_dict = {"Female" : 1, "Male" : 0}
life_df["GENDER"] = pd.Series([gender_dict[x] for x in life_df["GENDER"]], index = life_df.index)
life_df = life_df.drop("Timestamp", axis =1)
display(life_df.describe())出力結果:(変換後のデータを確認するために出力)

判明事項:
・AGEとGENDERの違いがそれぞれ数値として入力されている
発想:
・事前のデータ処理によりすべて数値データとして分析を行うことが可能になった
次の行動:
・データ分析のために訓練データと検証データに分割する
8-1.データ分析①
作業:データ分析の手法の一つであるランダムフォレスト回帰 (Random Forest Regression)を用いたモデルの構築とトレーニング、モデルの評価を行う。
解説:ランダムフォレスト回帰(Random Forest Regression)は、機械学習における強力なアンサンブル学習法の一つでこの、複数の決定木(Decision Trees)を組み合わせて、より精度の高い予測モデルを作成できます。
最終的な評価としてWORK_LIFE_BALANCEの予測値と実測値の平均二乗誤差について評価を行う。
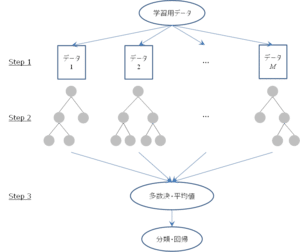
実際のコード
print("⓺WORK_LIFE_BALANCE_SCOREに対してのデータ分析")
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# 訓練データのWORK_LIFE_BALANCE_SCOREをtargetにする
target_BALANCE = life_df["WORK_LIFE_BALANCE_SCORE"]
features_BALANCE = life_df.drop("WORK_LIFE_BALANCE_SCORE", axis=1)
# 訓練データの一部を分割し検証データを作成する。
# データの2割を検証データにする。
X_train_B ,X_val_B ,y_train_B ,y_val_B = train_test_split(
features_BALANCE, target_BALANCE,
test_size=0.2, shuffle=True,random_state=0
)
# ランダムフォレスト回帰 (Random Forest Regression)によるモデルの構築とトレーニング
model = RandomForestRegressor(random_state=0)
model.fit(X_train_B, y_train_B)
# 平均二乗誤差を算出する
predictions_BALANCE = model.predict(X_val_B)
mse_BALANCE = mean_squared_error(y_val_B, predictions_BALANCE)
print("Mean Squared Error:", mse_BALANCE)出力結果:⑥WORK_LIFE_BALANCE_SCOREに対してのデータ分析
Mean Squared Error: 127.20981708294197
判明事項:
・平均二乗誤差が非常に大きい数値となっているため、モデルとしての精度は低い。(0にちかいほどよい)
発想:
・要素に重みづけやグルーピングを行うことで結果が変動するかもしれない
・分析手法を変えることでより精度の高いモデルとなることを期待する。
次の行動:
・モデルの構築手法をディープラーニングに任せる
8-2.データ分析⓶
作業:ディープラーニングを利用した分析を行う。
解説:ディープラーニングは、大規模なニューラルネットワークを使用して複雑なパターンを学習する機械学習の一形態で、非常に多くの変数を盛り込んだモデリングが可能である。
今回は学習を進めるにつれて結果 (val_loss) がより小さくなっていくことを確認する。 (epoch:試行1回ずつの結果を順番に出力する)
loss:訓練時の一致度合いを評価
val-loss:検証データでの一致度合いを評価
REG RMSE:最終的なモデルの精度を評価
#必要なライブラリモジュールを追加する
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
#乱数生成器のシードを0に設定します。(再現性のため)
tf.random.set_seed(0)
#生成されるグラフやプロットがノートブック内にインラインで表示されるようにする
%matplotlib inline
#Sequentialモデルを初期化し、モデルに全結合層(Dense層)を追加する。(32個のニューロンと入力次元(要素の数)22個)
model = Sequential()
model.add(Dense(32, input_dim=22))
#今回のモデルは非線形であるため、relu(Rectified Linear Unit)活性化関数を追加する。
model.add(Activation('relu'))
#別のDense層を追加する。こちらは128個のニューロンを持つ。
model.add(Dense(128))
model.add(Activation("relu"))
#出力層を設定する(1個のニューロンを持ち、モデルの最終出力を提供)
model.add(Dense(1))
#モデルをコンパイルする。(損失関数として平均二乗誤差(MSE)を、オプティマイザとしてAdam(最適化アルゴリズム)を使用する)
model.compile(loss='mse', optimizer='adam')
#データの訓練回数(epochs)とバッチサイズ ()
#verbose=1 で訓練の進行状況を詳細に表示する。検証データにより各エポックでの性能を評価する。
history = model.fit(X_train_B, y_train_B,
epochs=20,
batch_size=16,
verbose=1,
validation_data=(X_val_B, y_val_B) )
#検証データセットを使って予測を行う
y_pred = model.predict(X_val_B)
#計算された平均二乗誤差の平方根(RMSE: Root Mean Squared Error)を計算し、表示する。
mse= mean_squared_error(y_val_B, y_pred)
print("REG RMSE : %.2f" % (mse** 0.5))
#訓練と検証の損失の履歴を取得し、エポック数を計算する
train_loss=history.history["loss"]
val_loss=history.history["val_loss"]
epochs=len(train_loss)
#epochsの進行に伴う最適化の遷移を図としてプロットする
plt.plot(range(epochs), train_loss, marker = ".", label = "train_loss")
plt.plot(range(epochs), val_loss, marker = ".", label = "val_loss")
plt.legend(loc = "best")
plt.grid()
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()出力結果:(epochs=3)
Epoch 1/3
loss: 44809.2266 - val_loss: 3368.8376
Epoch 2/3
loss: 3073.3611 - val_loss: 2537.2898
Epoch 3/3
loss: 2511.0791 - val_loss: 2437.1780
REG RMSE : 49.37

出力結果:(epochs=20)
Epoch 1/20
loss: 43839.1875 - val_loss: 3281.4370
Epoch 2/20
loss: 3017.1284 - val_loss: 2510.4004
Epoch 3/20
loss: 2529.5498 - val_loss: 2444.3398
Epoch 4/20
loss: 2188.9580 - val_loss: 1886.5585
<中略>
Epoch 17/20
loss: 5.6861 - val_loss: 3.1181
Epoch 18/20
loss: 3.9940 - val_loss: 3.7862
Epoch 19/20
loss: 3.3061 - val_loss: 2.7315
Epoch 20/20
loss: 2.5590 - val_loss: 5.4969
REG RMSE : 2.34

出力結果:(epochs=50)
Epoch 1/50
loss: 44407.7031 - val_loss: 3356.7727
Epoch 2/50
loss: 3022.1221 - val_loss: 2476.4099
Epoch 3/50
loss: 2503.7532 - val_loss: 2375.7000
Epoch 4/50
loss: 2161.3667 - val_loss: 1850.1510
<中略>
Epoch 23/50
loss: 2.2088 - val_loss: 1.4758
Epoch 24/50
loss: 2.0652 - val_loss: 4.5163
Epoch 25/50
loss: 2.1142 - val_loss: 2.9044
Epoch 26/50
loss: 1.8267 - val_loss: 1.8781
Epoch 27/50
loss: 1.9243 - val_loss: 6.2235
Epoch 28/50
loss: 1.5872 - val_loss: 4.6783
<中略>
Epoch 48/50
loss: 1.1045 - val_loss: 6.2359
Epoch 49/50
loss: 0.9717 - val_loss: 2.5586
Epoch 50/50
loss: 1.0010 - val_loss: 0.2546
REG RMSE : 0.50

判明事項:
・モデルはepochs数を増やすにつれてval_lossが小さくなった。
・一方でepochs数を増やしすぎた結果、(25回以降から)val_lossが振動するようになった (数値が上下している)
・これは訓練データに対する過学習が起こっており、汎用性を失っていると考えられる。 (新規データを入力した場合に外れやすくなる)
・おおむねepochs数20程度でよいモデルが構築できたようである。
最終的なプログラム
今回作成したプログラムの全体像を確認されたい方は以下からご確認ください。
考察と反省
今回、ランダムフォレストによる分析結果は分析データのクレンジングなどが足りずにうまくいかなかった。
一方で、ディープラーニングを利用した分析では試行を重ねるにつれて最適なモデルが形成されている様子が見て取れた。
今回のデータは、アンケート結果であり、WORK_LIFE_BALANCE_SCOREの評価は主観的数字になっているため、別の指標による分析が良いかもしれない ( DAILY_STRESS、TIME_FOR_PASSIONやPERSONAL_AWARDSを複合して評価するべきかもしれない)。
データクレンジングで性別や年代を数値へ返還したが、大小関係や連続的な意味をもたない可能性があるため、単にモデルが複雑化してしまった可能性がある。
データの要素数と入力形式のバリエーションが豊富なため、データの正則化や項目ごとにまとめた後に分析を実施した方がよかったかもしれない。
分析手法への理解が低く、ブラッシュアップすることができなかった。
次の投稿では今回の反省を生かしたコードを作成したい。
今後の方針
WORK_LIFE_BALANCE_SCOREに対して、別の分析手法を用いて分析を実施する。
評価対象を別のデータを対象として分析する。
この記事が気に入ったらサポートをしてみませんか?