
Ubuntuで構築する画像生成AI環境

どうも30後半のエンジニア、YIです。
専門はC#ですが案件によっては色々やらしてもらっています。
で、今回のネタは画像生成AIになります。
生成系AIというと
文章を入れると解釈した答えを導き出してくれる事や、
それに適した画像を生成してくれるとか。
話にはよく聞きますが実はまだ試していなかったのです。
PCをちょっとアップグレードする機会があったので、
VRAMの多いグラボが画像生成に使えるという事を発見。
で、画像生成とはなんぞやと探して見ると、
Stable Diffusionというソフトで、ローカルに環境を構築できるそうではないですか。
Ubuntuで画像生成AI用端末・・・・いけるんじゃないか。
しかしながら今まで、業務でLinuxを使用する場面は無かったというのもあり、
Linuxの知識に関しては素人レベルという所はあります。
ですが、何かを成し遂げるためには努力と根性でとりあえず何とかするをモットーに掲げて、
「Ubuntuで構築する画像生成AI環境」と題して記載します。
一応ターミナルは叩けます。
とまぁ、そんなこんなで三日三晩掛けて環境を構築してみたので、
Linux環境のレシピなどをつらつらと書いてみます。
(とはいえわざわざ構築しなくてもWeb上で試せるとか、まさかのWindowsでも動くとかあるようです。)
でグラフィックボードですが、[Cuda]を使うとして、
Geforce系がまず必須という事で、4000系かなと思ったら、
とにかくVRAMの容量で性能に差が出るそうです。
前世代のGPUですが、VRAMが12GBあるという事でGeforce3060のVRAM12GBがお勧めだそうです。
という事でチョイスしたのが、
玄人志向 NVIDIA GeForce RTX3060 GG-RTX3060-E12GB/OC/DF
ちなみに玄人志向のビデオカードはOEM品みたいですね。GalaxyやPalit製らしい。なるほど。

<マシン構成>
ケース :Thermaltake The Tower 100
電源 :ANTEC NE650(650W)
マザーボード:BIOSTAR Z490GTN(mini-itx)
CPU :Core i3-10105F(Intel 第10世代)
メモリ :DDR4 3200MHz 8GB*2
GPU :Geforce3600 VRAM12GB
ストレージ :SSD M2スロット 4TB
ストレージはNASとしても使いたいので大容量を確保してますが、
画像生成ならとりあえず2TBぐらいあれば十分かと。
[stability.ai]の画像生成AI[Stable Diffusion]は
オープンソースソフトウェア(OSS)となっています。
調べたところ著作権等については下記。
・生成した画像などについては、作成者自身が権利を持つ。
・法律に違反するものや武器など人に危害を与えるものは利用は禁止。
・誤った情報を広めるものなどの利用は禁止。
で導入するのは「Stable Diffusion web UI」でこちらもオープンソース。
[AUTOMATIC1111]さんが提供している、
[Stable Diffusion]をより手軽に直感的に使えるように開発されたツールとの事です。
で、動作としては学習済みのモデルデータを使用するという事で、
商用利用できるかどうかなどは、そのモデルデータのライセンスが影響するそうです。
インストール時に自動で落ちてくる下記標準モデルは、クレジット不要で商用利用も可との事らしいです。
・v1-5-pruned-emaonly(stable diffusionの標準のモデル)
ではここから。
■※手順についての注意。
「当記事を参考にして生じたいかなる問題も損害も自己責任でお願いします。
また手順の中には一部不正確な部分もあるかもしれませんが、自己解決でお願いします。」
なお内容についてはグーグルにて検索した内容を参考としております。
参考とさせて頂いたサイト様には感謝!
2023年11月時点の情報となります。
■
OSはUbuntu(22.04.3)を導入します。
入手性やらなんやらLinux系OSに感謝!
OSのインストールについては割愛します。
ネットワークは必須。
GUI有効。
サードパーティー製のドライバを許可すれば、インストール時に自動でnVidia製のドライバは追加されますとだけ。
デフォルトでインストールされる[Nouveau]ドライバではいろいろ機能が使えません。
ただOSのインストールと環境構築で時間がかかったので要点だけ。
・Ubuntu20.04.1を使用したところ、Cudaインストール後にカーネルとCudaのドライバの相性でクラッシュし復旧不能。
・日本語でインストール可能。(ただしブート不具合時のコンソールが文字化けでカオスになる。)
・インストール時に画面がはみ出て操作不能の場合[Alt + F7]でウインドウが動く。
・Ubuntuのプリインストールでpython3があり、OS内部で使用しているため消去または変更するとクラッシュし復旧不能。
→シ、システムの主要機能だったなんて知らなかったんだぁぁ!!
別途python3をインストールするのが正しい模様。
・Ubuntu22.04.3のインストールメディアをブートしたところ、起動しない。(グラボの影響かと)
→インストールオプションから
[try install ubuntu]にカーソルを合わせ[e]キーを押す
[quiet splash]を[nomodeset]に書き換える
[ctrl + X]でブート再開
・Cuda(11.8)から(12.1)を再インストールしようと削除処理を進めたところ、何故かリポジトリからデータが取れなくなった上にクラッシュし復旧不能。
・[Stable Diffusion web UI]のオプション指定時に[pip3]コマンドでなく[pip]と入力したら動いた。
・Stable Diffusion web UIで生成速度やらに影響する[xformers]を指定したら実行時にエラーが発生。
→
pythonのバージョンを見直してみたけど、最近のバグのようなので、
コマンドラインに指定しない。
動かして見たら使った事がないから分からないけど大して問題が無かった。
で、まさかグラボを載せただけで様々な問題が起きようとは・・・・
Windowsでなら不具合がおきた状態でもなんとかなる可能性が高いのですが、
Ubuntuで問題が起きたときは、復旧までとんでもない時間が掛かりそうなレベル。
コンソールからできる手立ては無し。
クリーンな環境のため、都度再インストールで対処しました。
学んだこととしては、
・Cuda関連のインストールを操作してる時にクラッシュし復旧不能に陥る事もある
・カーネルとドライバに相性の不具合が存在する事がある
・インストール時にブートが立ち上がらない事もある
・OSとCudaとpythonとpytorchのバージョンとかとにかく要求するバージョンの問題
・お手軽にはいかない
【使用バージョンなど】
[Stable Diffusion web UI]:v1.6
[python]v3.11.3
pythonはいろいろあって3.11.3を使用しましたが、それ以上のバージョンでも動いたかもしれません。
[Cuda]v12.1
【もろもろのバージョン確認】
1.pytorch
pytorchのバージョン確認は公式ページから
https://pytorch.org/
[Linux][Pip][Python][CUDA12.1]辺りを選択するとコンフィグに指定するべきコマンドが出力されます。
(torch torchvision torchaudioのインストールコマンド)
2.Cuda
詳細なインストール手順は下記サイトでコマンドなどを取得できます。
https://developer.nvidia.com/cuda-toolkit-archive
3.Python Japanのダウンロードページ(バージョン確認等)
本家が分かり辛いとかあるので、下記から。
「非公式」とありますが、Python Japan様が作成・運用しているサイトとの事。
Pythonの公式サイトではないですが、安全なサイト様の模様。
非公式Pythonダウンロードリンク
https://pythonlinks.python.jp/ja/index.html
【インストール手順】
①Pythonをmakeしてインストールする
②CUDAインストール
③Gitのインストール
④表示されるエラー対策のインストール
⑤通信系のソフトウェアをインストール
⑥Stable Diffusion web UIをインストール
PythonとPyTorchでソフトが動くのでもろもろをインストールします。
PyTorchって機械学習ライブラリなのか・・へぇ。
しばらく間があってから書き起こしたので抜けがあったらごめん。
■定番
作業前にまずこの辺を打っておきましょう。
sudo apt update
sudo apt upgrade -y
■①Pythonをmakeしてインストールする
①-1 現状確認
python3 -V
プリインストールのバージョン(system用)が表示される
それとは別に別バージョンのPythonをインストールします。(共存する形)
①-2 インストール
sudo apt update
sudo apt install build-essential libbz2-dev libdb-dev \
libreadline-dev libffi-dev libgdbm-dev liblzma-dev \
libncursesw5-dev libsqlite3-dev libssl-dev \
zlib1g-dev uuid-dev tk-dev
wget https://www.python.org/ftp/python/3.11.3/Python-3.11.3.tar.xz
tar xJf Python-3.11.3.tar.xz
cd Python-3.11.3
./configure
make
sudo make install
Successfullyとか出れば成功です。
上手くいかない場合は再度makeなど。
ログアウトし再度ログインしバージョン確認と配置場所を確認
python3 -V
which python3
①-3 PIP
PIPのバージョン確認し入ってないような場合は下記でインストール
pip3 -V
sudo apt install -y python3-pip
■②Cudaインストール
②-1 ドライバ確認
何かバージョンとかみれるはず
uname -r
nvidia-smi
②-2 cuda 削除
sudo apt-get --purge remove nvidia*
sudo apt-get --purge remove cuda*
sudo apt-get --purge remove cudnn*
sudo apt-get --purge remove libnvidia*
sudo apt-get --purge remove libcuda*
sudo apt-get --purge remove libcudnn*
sudo apt-get autoremove
sudo apt-get autoclean
sudo apt-get update
sudo rm -rf /usr/local/cuda*
②-3 ファイル確認
下記遷移先フォルダにnvidia関係のリポジトリの追加か何かがあると指定バージョンが入らない可能性があるため、
ファイルが無い事を確認する
cd /etc/apt/sources.list.d/
ls
②-4 Cuda(v12.1)インストール
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda-repo-ubuntu2204-12-1-local_12.1.0-530.30.02-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-12-1-local_12.1.0-530.30.02-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-1-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda
②-5 環境パス設定
export PATH="/usr/local/cuda-12.1/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH"
■③Gitのインストール
③-1
sudo apt-get install git
③-2 Gitがインストールされたか確認する
バージョンが表示されていればOK
dpkg -l git
■表示されるエラー対策のインストール
[Stable Diffusion web UI]を起動時に表示されるエラー対策
「cannot locate TCMalloc」的なエラーが表示される
下記インストール
sudo apt install python3-venv google-perftools
■⑤通信系のソフトウェアをインストール
下記インストール
sudo apt install curl gnupg2 git
■⑥[Stable Diffusion web UI]インストール
⑥-1 最新バージョン1.6をダウンロードします
wget https://github.com/AUTOMATIC1111/stable-diffusion-webui/archive/refs/tags/v1.6.0.tar.gz
tar xvf v1.6.0.tar.gz
⑥-2 コンフィグ変更
展開したディレクトリに移動しテキストエディタにより
[webui-user.sh]ファイルを編集します。
エディタは感覚的に使いやすいので[nano]を使用。
対象行のコメント[#]は外します。
自動起動とVRAMの使い方の設定
export COMMANDLINE_ARGS="--autolaunch --opt-sdp-attention --medvram "
ここで延々と悩まされましたが、pip3では無くpipと書くのが正しかったです。
なんかコマンドがpipに変わったとか経緯があるみたいだけど。
export TORCH_COMMAND="pip install torch torchvision torchaudio"
⑥-3 ファイルの権限を変更します。
chmod 755 webui-user.sh
⑥-4 起動作業
bash ./webui-user.sh
bash ./webui.sh
ここまでやると、
ネットワーク上から必要なファイルを取得してきます。
時間は結構掛かります。
起動すると自動起動のオプションによりブラウザが立ち上がります。
感動の瞬間。
使い方について調べて見るとどうやら、
positiveワードと
negativeワードがあります。
それぞれに入れる文言は「呪文」と呼ばれるとか。
positiveワードには出したい内容に関する文言を。
negativeワードに指定した文言は出力されなくなります。
ではやってみましょう。
「1robot」

こ、こいつっ動くぞっ!!


では至高の召喚呪文を。
「1girl」

「!!」
ふっふたりいるぅ!!
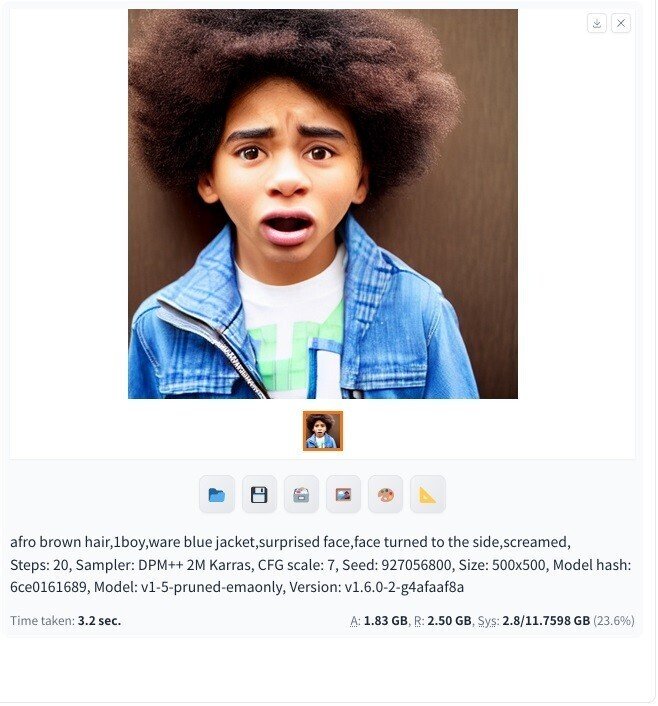
さて如何でしたでしょうか。
AIの画像生成は色々考えさせられることがありますが、
手元にローカル環境を構築できると話題の画像生成をいじれるとなると色々楽しいですね。
でもって文章の自然な解釈が凄いですね。
使用してみた感じでは、出力結果はモデルデータで学習している事が重要という事で、
パラメータに従った内容をブレンドして出力している感じがしました。
文字にしたがってあれやこれや出てくるものかと思ったら、
学習されてないデータは出てきません。
となるとモデルデータを如何にして作るかに掛かってくるわけですね。ふむむ。
(ちなみに拡張に関してはモデルデータのマージやLora等によって色々混ぜれます。)
そしてVRAM12GBでも大きい作業をすると枯渇するので欲を言うならもっとVRAMが必要。
以上、内容について楽しんで頂けたら幸いです。
この記事が気に入ったらサポートをしてみませんか?