
[論文紹介] KNOWLEDGE FUSION OF LARGE LANGUAGE MODELS (2024)

著者:Fanqi Wan1∗, Xinting Huang2†, Deng Cai2, Xiaojun Quan1†, Wei Bi2, Shuming Shi2
機関:1School of Computer Science and Engineering, Sun Yat-sen University, China 2Tencent AI Lab
会議:ICLR2024
一言で:ソースLLMの確率分布を融合し,複数のLLMから得た知識を単一のLLMに集約

個別の機能と強みを持つを大規模言語モデル(以下,LLMとする)を一から学習することは,多大なコストがかかります.そのため,既存の事前学習済LLMを融合し,より強力なモデルを作るための手法が近年提案されています.しかし,事前学習済のモデルは(当然のことながら)モデルアーキテクチャがそれぞれ異なるため,単純に重みを混合する手法は現実的ではありません.そこで本研究では,ソースLLMの生成分布を利用し,単一のLLMに知識を転移させる「知識融合」の概念を導入します.実験の結果,LLMの融合によってターゲットモデルの推論、常識、コード生成などの様々な機能が向上することが確認されました.
イントロダクション
LLMが,さまざまな自然言語処理タスクで絶え間ない成功を収めるにつれ,企業が独自のLLMを作ることが必須課題となってきました.しかし,LLMの開発コストは天文学的な金額にのぼります.膨大な量の訓練データ,高度な手法,莫大な計算リソース,熟練した人材が必要なだけでなく,開発プロセスそのものがエネルギー消費と環境に多大な負荷をかけています.これらのLLMは構造と機能が異なりますが,様々なNLPタスクで同様の能力を有しています.そのため,従来の一からLLMを訓練するアプローチに加え,既存のLLMを組み合わせて新しく強力なモデルを作るという選択肢があり,本論文ではこれを「LLMの知識融合(Knowledge fusion of LLMs)」と呼んでいます.この融合に成功すれば,初期訓練コストを削減できるだけでなく,統合モデルがすべてのLLMの長所を活用できるようになります.この新しいモデルは,様々なダウンストリームタスクに合わせて微調整や適応が可能です.さらに,特定のタスクに特化した微調整済みLLMの間でも融合が可能になります.
複数のモデルの機能を統合する試みは長年の課題でした.アンサンブル手法では、異なるモデルの出力を直接集約して予測性能と頑健性を高めますが,推論時にすべてのモデルを維持・実行する必要があり,大規模なメモリと推論時間を要するLLMには現実的ではありません,また,多くのLLMで不可欠な微調整にも対応していません.もう1つのアプローチは,パラメータ単位の算術演算により,複数のニューラルネットワークを1つのネットワークに直接マージする方法(Wortsman et al., 2022; Jin et al., 2022)です.しかし,これは一様なネットワーク構造を前提とし,個別ネットワークの重みをマッピングする必要があり,LLMの文脈では実現が難しい.さらに、パラメータ空間に大きな違いがあると,重みのマージでは最適な結果が得られない可能性があります(Li et al., 2022).
本論文では,確率分布の観点からLLMの融合を探求します.ある入力テキストに対し,異なるソースLLMから生成された確率分布は,そのテキストを理解する際の固有の知識を反映していると考えられます.そこで提案手法FuseLLMでは,ソースLLMの生成分布を活用し,それらの集合的な知識と個別の長所を外在化し,軽量な継続的訓練によってターゲットLLMに転移させます.このため,異なるLLMのトークン化を整列させる新しい戦略を開発し,さまざまなLLMから生成された確率分布を融合する2つの手法を検討しました.継続的訓練の際,FuseLLMはターゲットLLMの確率分布とソースLLMの確率分布の divergence を最小化することを重視しています.
FuseLLMの有効性を実証するため,共通点のほとんどない複数のLLMを融合するという挑戦的で一般的なシナリオを検討しました.具体的には,アーキテクチャと機能が異なる3つの人気のオープンソースLLM,Llama-2,OpenLLaMA,MPTに着目しました.推論,常識,コード生成の合計42タスクで構成される3つのベンチマークにおいて,提案手法で訓練したターゲットモデルが,各ソースLLMとベースラインをほとんどのタスクで上回ることが確認されました.さらに,単一のベースモデルをいくつかのドメイン特化コーパスで継続的に訓練させ,機能的に異なるLLMの存在を模倣したところ,perplexityに基づく評価において,提案手法は従来のアンサンブルと重みマージ手法に比べ,構造が同一のLLMの機能を組み合わせる上で優れた潜在能力を示しました.
本研究の貢献は以下です.
簡潔で高品質なコーパスを用いた軽量な継続的訓練により,当手法の有効性を実証(ただし,訓練コーパスの慎重な選択,特にダウンストリームタスクとの関連性が重要)
ソースLLMの機能が大きく異なるシナリオにおいて,それらの長所を効果的に組み合わせるための融合関数を提案
構造とサイズが異なるLLMの分野において有望な合成手法を提案(従来のモデルアンサンブルやマージ手法に比べて)
従来手法と提案手法(FuseLLM)が異なる点を表にまとめます

IMPLEMENTATION OF FUSELLM
FuseLLMのコア技術は,Token AlignmentとFusion Strategiesです.
Token Alignment
LLMを融合するにあたり,入力テキストに対して,2つのソースLLMから得られた2つの分布行列を整列する必要があります.具体的には以下のような状況で整列が必要になります.

LLM1とLLM2の両方が”now”というトークンを含んでいる場合,これらのトークンは正しく整列され,対応する分布を整列することができます.しかし,マッピングされたトークンが異なる場合(例の”get”と”gets”など),Fu et al.(2023)の従来のEMでは,これらのトークンは整列されず,分布がone-hotベクトルに退化してしまいます.一方,提案するMinEDでは,2つのトークン(単語)の最小編集距離に基づき,”gets”を”get”と正しく整列することができます.
別の例を見ると,トークンが同一の場合(”current 0.05”と”current 0.04”)正しく整列されます.トークンが異なる場合(”immediate 0.04”と”immediately 0.03”)はEMでは値を無視します.一方MinEDでは,最小編集距離に基づき”immediately”を”immediate”にマッピングするため,これらの分布値を正しく整列することができます.
本研究では,完全一致(EM)の制約を最小編集距離(MinED)に置き換えて,トークン整列の成功率を高めています
従来手法EMは,単語の文字面が一致している場合に正しく機能しますが,そうでない場合,one-hotベクトルにマッピングされます
提案手法のMinEDでは,異なる単語間に編集距離を定義し,2つの文字列がどれくらい似ているかに基づきマッピングを行うため,多少異なる単語同士で合っても正しくマッピングできると主張しています
Fusion Strategies
LLM Fusionでは,K個のソースLLMに同じテキストを与え,確率分布行列Pをそれぞれ計算させます.そして,確率分布行列Pを融合し,表現行列Ptを得ます( tはターゲットの意味です)
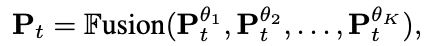
ここで,Fusion(·)は複数の行列を組み合わせる関数を表し,得られた行列Ptはソースモデルの集合的な知識を表す表現となります
本論文では以下の2つの方法を用いて複数の行列を一つに融合しています
MinCE: 正解(次の単語)との交差エントロピー損失が最小のLLMの確率分布行列を出力
AvgCE: 交差エントロピー損失に基づいて計算した重み付き平均で確率分布行列を線型結合
MinCEは文章単位でソースLLMを1つずつ切り替えながら,その都度最適なLLMを選んでいく方式です.言い換えると,複数のLLMの知識を同時に組み合わせるのではなく,文章ごとに1つのLLMを選択的に使う手法といえます(LLMを選択的に使っているため,知識融合と異なる可能性がありますが,後の実験結果によると,AvgCEよりMinCEの方が優れた性能を示します.何故なのでしょうか?)
AvgCEでは複数のソースLLMの確率分布行列を重み付き線型結合して統合します.交差エントロピーが小さい(正解に近い)LLMの確率分布に重きを置きながら,複数のLLMの知識を線型結合して統合しています
そして,ソースLLMの機能をターゲットLLMに転移させるため,ターゲットLLMの予測と融合された表現行列Ptとを用いた目的関数を定義します
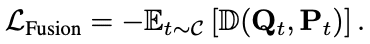
D(·, ·)は,2つの行列の距離関数を示し,KL divergenceが用いられています.
本モデルでは,以下の式で表されるロス関数を最小化します.

ここでL_CLMは,左から右に順々に単語を予測するcusal language modelという,GPTの学習で用いられるタスクを解くことに得られるロスです.FuseLLMでは,この言語モデルで一般的に用いられるCLMロスと,Fusionロスの両方を最小化するための学習が行われます.
実験結果
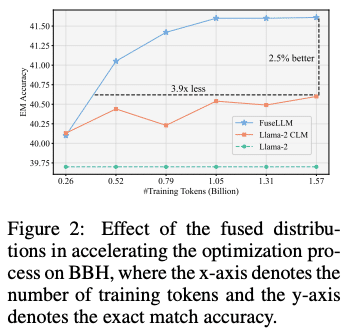
推論能力(BBH),常識推理能力(CS),コード生成能力(ME)の3つのベンチマークで評価を行った.FuseLLMは全てのベンチマークで基準モデル(Llama-2)を上回る性能を示した
BBHでは5.16%,CSでは1.25%,MEでは6.36%の相対的な性能向上が見られた(表1,2,3)
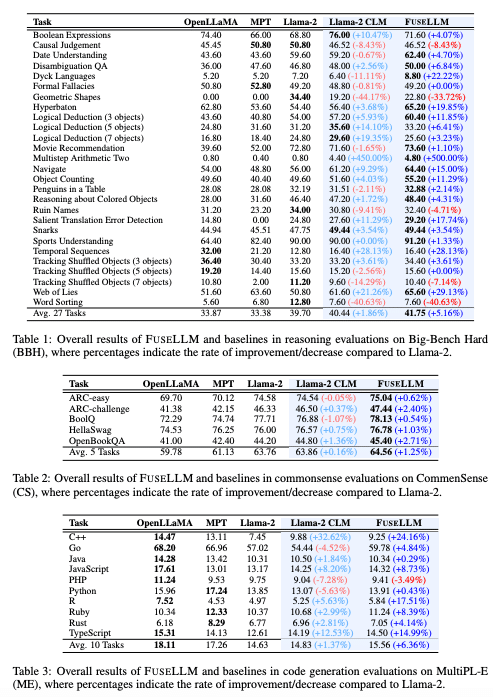
確率分布の統合によってモデル最適化が加速され,同じ性能に到達するのに3.9倍少ないトークン数で済む(図2)
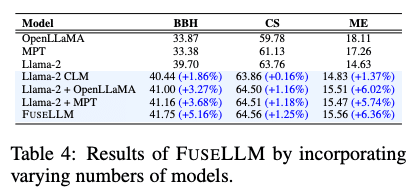
統合するLLMの数が増えるほど性能が向上する傾向があった(表4)
提案手法のMinEDによるトークンアラインメントとMinCEによる確率分布の統合が最も良い性能を示した(表5)

疑問点:表5の結果について,Fusion関数にAvgCEではなくMinCEを使用する理由について疑問があります.MinCEは単に確率分布行列を選択するだけであり,論文が述べる「融合」とは少し異なるように思われます.論文内にその説明は見当たりませんでした.表5の結果の後に,以下のように簡潔に述べられています.
“The findings demonstrate that FUSELLM with MinCE consistently outperforms AvgCE across all benchmarks. This can be attributed to the distortions introduced by the straightforward weighted summation used in AvgCE, which may diminish the distinct advantages of individual LLMs.”
ここでは,AvgCEの単純な重み付き和によってLLM個別の利点が損なわれているため,MinCEの方が全体的に優れた性能を示すと述べられていますが,深い議論は行われていないようです.
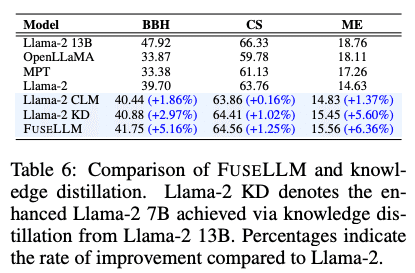
FuseLLMは従来の知識蒸留よりも優れた性能向上を実現した(表6)
LLMアンサンブルやウェイト合成よりも,FuseLLMの方が確率分布の統合においてより効果的であった(表7)

まとめ
この研究では,複数の構造的に異なるLLMの能力と長所を統合した単一のモデルを作成するための知識融合について探求しました.提案手法FuseLLMでは,ソースLLMの生成分布から知識を外在化し,ターゲットLLMの継続的学習に活用しています.一連の実験を通じて,FuseLLMが個別のソースLLMやベースラインを上回る優位性を実証しました.特に,構造が同一の複数LLMによる模擬実験では,FuseLLMがアンサンブルやウェイト合成より優れた効果を示しています.このように,LLMの融合は構造とサイズが大きく異なるLLMに対して有望な手法であり,今後の研究が期待されます.
この記事が気に入ったらサポートをしてみませんか?