CourseraMLweek9で紛らわしかったところ(Anomaly,recommendersystem)

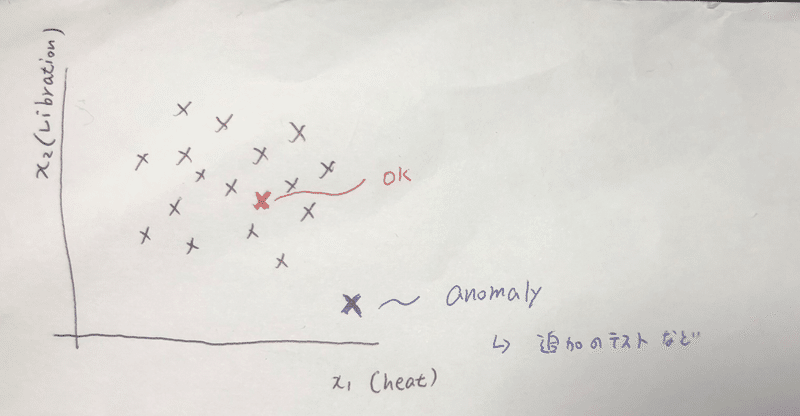
例えば、エンジンの品質管理部門で働いているとして、どうやって効率良く変なモノを見つけるか、。
x1にheat, x2にvibrationをとったとして、なんとなく集団の中にある点はOKで集団から離れているものだけ追加のテストを行うなど決めよう。
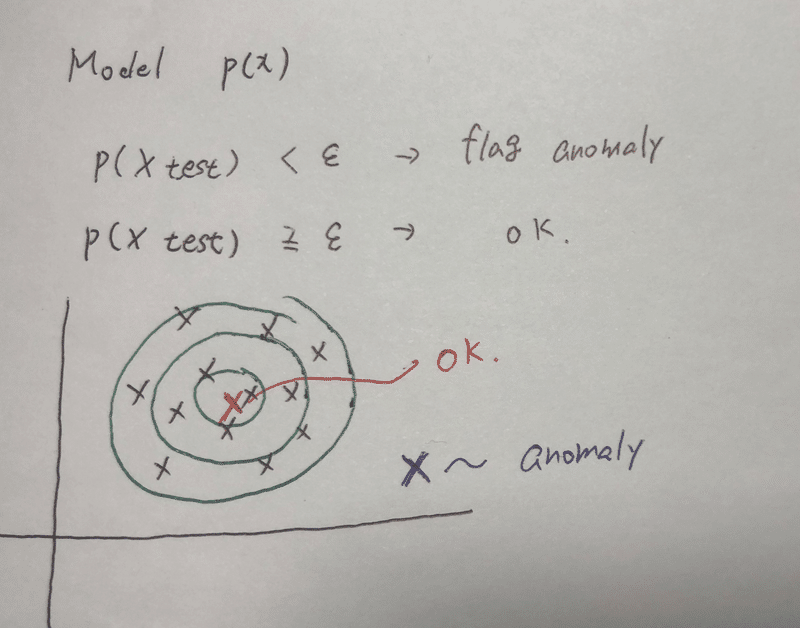
つまり、Model P(x) を算出し、それがある値εより小さければアノマリーだとフラグ付けをしよう。(帰無仮説を棄却する的な・・?)

P(x)をどうやって算出するか。
それぞれのtraining set に正規分布を仮定する。x(each) ~N ( μ(each) , σ(each)^2 )
p(x) = Π p( xj ; μj, σj^2 )
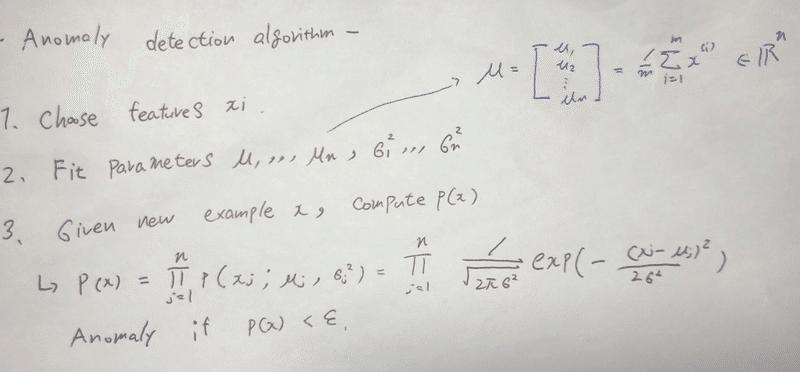
アルコリズムは、、
1.フィーチャーを決める(熱とか、回転量とか、)
2.パラメータをフィッテイングする
3.新しいexample, x についてp(x)を算出する
4.p(x) < ε の時、アノマリーだとフラグ付けする。
また、p(x) = Π 1/(√2π*σ)*exp(-(xi - μi)^2/2σ^2)
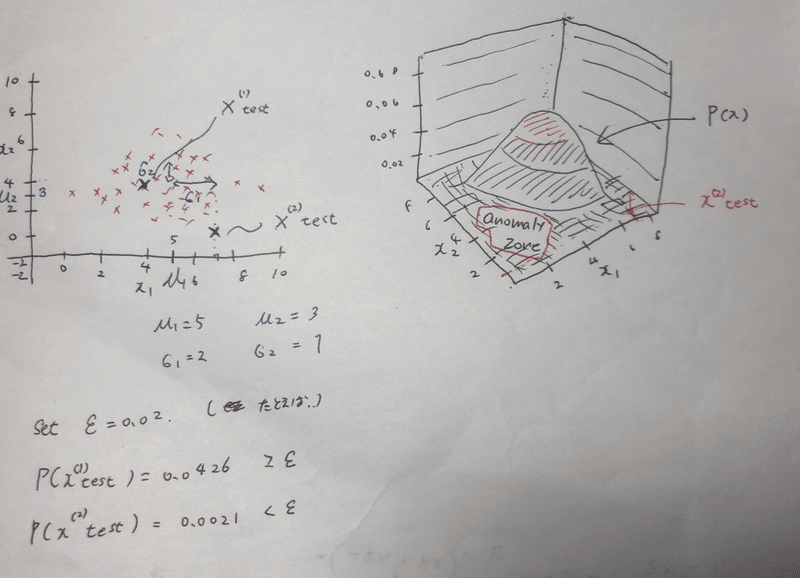
図で見ると、、
たとえば、ε = 0.02と置き、 x(1), x(2) をプロットしてみる。2次元の図では、x(1)がなんとなく集団の中心にいて、x(2)が集団から離れているように見える。
それぞれx1, x2 に対して、p(x) を算出してみると、、
P(x1) = 0.0426 > ε
p(x2) = 0.0021 < ε よって、やはりx1は正常で、x2がアノマリーだとわかる。また、p(x)の軸を追加した3次元のグラフを見ても、x2は Anomaly zone(棄却域的な?)に落ちていることが見れる。
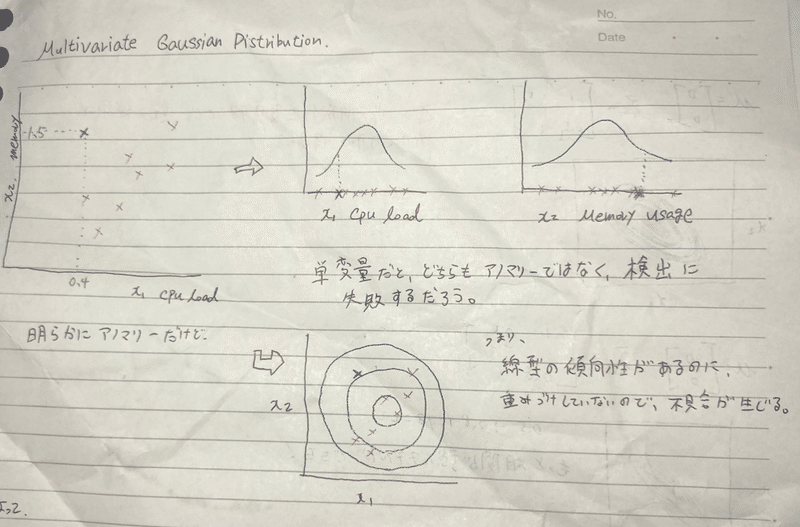
Multivariate Gaussian Distribution
なんか、上記までのフィッテイングでは不都合が起きる場合があるから、多変量verも覚えておけ!てことらしい。
左上の2次元のグラフでは、 x test は明らかにアノマリーに見える。
しかし、x1 ( cpu load ) , x2 ( memory usage ) それぞれfittingしてみると、どちらも棄却域に落ちず、アノマリーだとフラグ付けすることができない。つまり、集団に線形の傾向性がある(相関?)のに、重みづけしていないためこういった不具合が起きる。
(集団が右肩あがりになっているにも関わらず、確率の大きさを表す円が平等に?大きくなっていくことが右下の図で示されている)
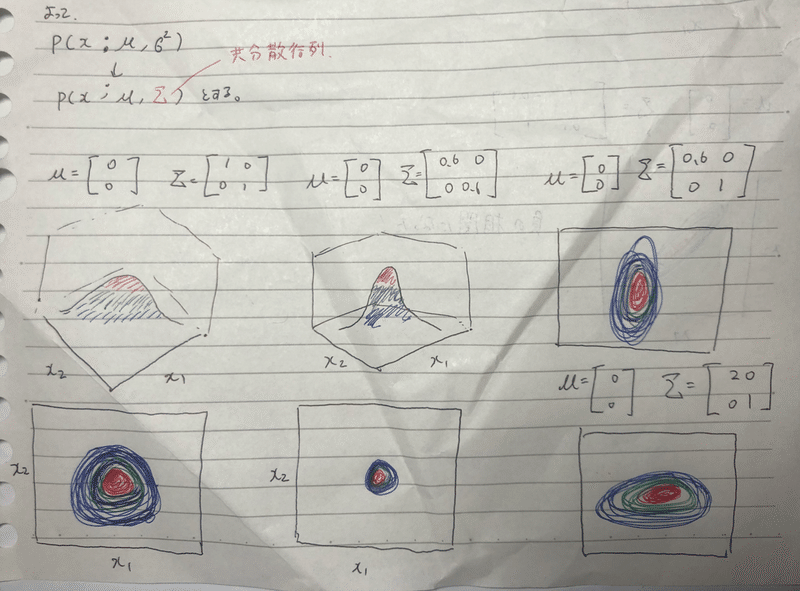
じゃあ、確率の分布の形を変えましょう。となります、
これまで、P(x ; μ, σ^2) だったものを p(x ; μ, Σ(共分散行列)) と仮定します.
μ = 1/m * Σxi
Σ(共分散行列) = 1/m * (xi – μ)(xi – μ)’
一番左が今までの分布。 真ん中、Σの対角成分を小さくすると、分布が小さく?細くなります。
右の二つ、対角成分の片方だけ増やしたり減らしたりすると、上下左右に伸びます。
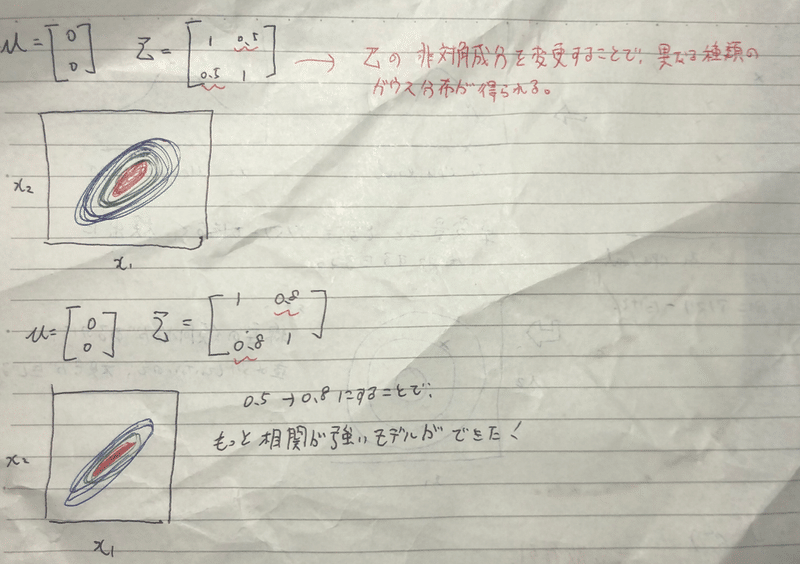
上の図、Σの非対角成分を変更することで、相関に対応したような異なるガウス分布が得られる。また、その値を大きくするとさらに相関が強いモデルが得られる。
Original model vs Multivariate model
相関がありそうなとき、オリジナルのモデルでは何となく不具合があることは分かったけど、じゃあどっちつかえばいいのよ!?という疑問、
Original model___
フューチャー同士の相関について、例えば Cpu load/ memory using とかを手動で作る必要があるが、計算が安上がりである。
また、トレーニングセットのサイズが小さくても相対的にうまくFittingしてくれる。
Multivariate model___
自動的にフィーチャー同士の相関を捕まえるが、計算量が多い。
また、フィーチャーの数より、トレーニングサイズが多くなくてはいけない。
もしそうでない場合Σが可逆じゃなくなってしまう。
また、冗長なフィーチャーがある場合(x1 = x2 のような全く同じもの)も、Σが可逆でない特異行列になってしまう。(X3 = x4 +x5とかも。;x3はなんの新しい情報ももっていない。)
Anomaly detectionを評価するには・・?
アルコリズムを開発するときに(どのフューチャーを選ぶかなど)、何か評価する数字が欲しい。
たとえば、ラベル付けされた(normal: y=0 , anomaly: y=1)のデータがあったとして、トレーニングセットにはy=0のものだけを含ませる。
CV, Test set にはy=1が含むものを割り振る。
具体的には、
10000の良いエンジン、20 のアノマリーなエンジンがあったとして、
Trainig set : 6000 good engine (y=0)
CV: 2000 good engine (y=0), 10 anomalys(y=1)
Test : 2000 good engine (y=0) , 10 anomalys(y=1) と割り振る。
ここで、Training set をP(x)をフィットするのに使う。
P(x) = Πp(xn ; μn, σn^2)
そして、CVやTest set でそのモデルを評価する。
つまり、
Y = 1 if p < ε
Y = 0 if p >= ε が正しく評価しているか。
しかし、ここで、y=0とy=1の分布はかなり歪んでいるんだから、割合でなく、F1 scoreで評価してあげる必要がある。(感度特異度的に考えるとわかるよね、)
また、εの値を選びたいときは、CVでたくさんのεの値を入れて試してみて、F1 scoreが最大化するものを選ぶ。
教師あり学習との違い。
今回の想定では、ラベル(y)があるものを使用したけど、yがあるなら、なぜ教師あり学習にしないのか疑問がでる。教師あり学習を選びyの0,1を予測してしまえばいいのではないか。
→ Anomaly detection を使用する場合。強み。
1.Very small number of positive example (y = 1) { 0 – 20 }
Large number of negative (y = 0)
(P(x)をfitting するときには、y=0の陰性のものしか使用しないため、都合がよい。)
(少しの陽性しかないから、未だ出ていない、いろんな故障のパターン(anomaly)が考えられる。また、将来、まったく想定していないAnomalyが出てくるかもしれない。)
→ Supervised learning を使用する場合。強み。
1. Large number of positive and negative example
(たくさんの陽性サンプルがあるから、 壊れ方も大体知ってるし、将来想定される陽性の種類も大体似たようなものだろうと予測される)
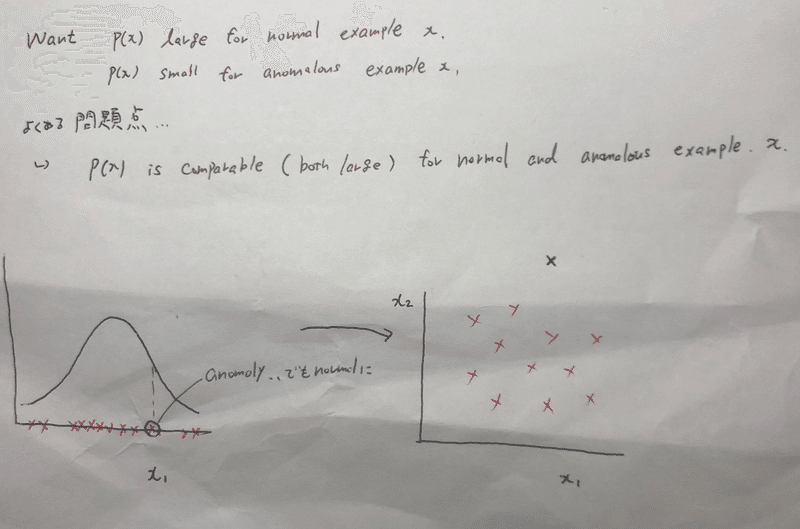
フィーチャーをどう選ぶか、
x1しかフィーチャーがない場合、あるアノマリーがあったとして、うまく検出してくれなかったりする。その場合、フィーチャーを追加してみてちゃんとアノマリーだと検出してくれるようなフィーチャーを選ぶ。
たとえばエンジンについてみているとする、
とある不良なエンジンについて、熱という一つのフィーチャーで考えると、アノマリーでなかったとして、回転数というフィーチャーを足すとアノマリーだと検出できた。それならば回転数というフィーチャーは必要である。
Recommender system
Amazonのおすすめとか。Spotifyのあなたにお勧めの音楽みたいなシステムのこと。
言葉で説明すると,,,,とあるユーザーのレートの欠損値(まだ見ていない)を埋めるとして、そのユーザーの背景(アクション映画が好きとか、恋愛映画が好きとか)によって値を決めることができる。その値が大きければ”Recommend”する。
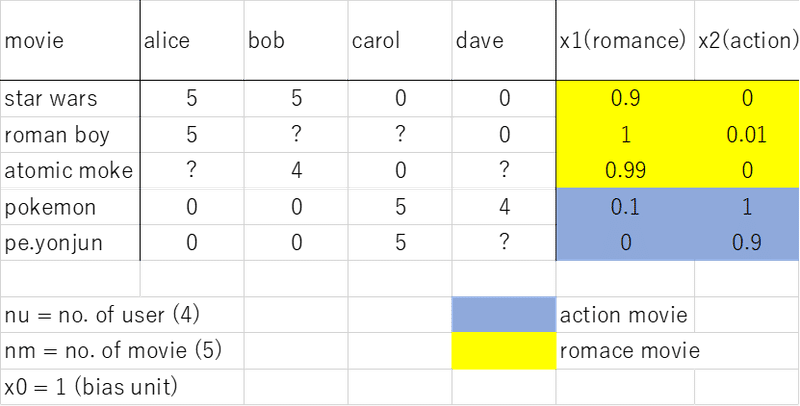
x(1) = [1 , 0.2, 1] ←Column vector (Row で書いたけど)
それぞれのユーザーjに対して、パラメータθ∈R(n+1)を学び、とあるユーザーjがある映画 i につけるレートは θ(j)'*x(i)で求められる。
たとえば、aliceのパラメータをどうにか入手したとして(あとで解説), x(3 ; atomic moke)の空欄を埋めるには
θ(1) = [ 0 5 0 ] x3 = [ 1 0.9 0 ] (本当はどちらもcolumn vec)
θ(1)’ x(3) = 4.95 より、aliceのatomic mokeに対するratingの空欄は4.95であるということがわかる(線形回帰問題として予測できる)
記法__
r(i, j) = 1 if user j has rated movie i otherwise 0
y(i, j) = rating by user j on movie i ( if defined)
θ(j) = parameter vector for user j ( どんな映画が好きか、ロマンスとかアクションとか)
x(i) = feature vector for movie i (どんな映画なのか、ロマンスとか、、)
for user j, movie i, predicted rating; θ(j)’ x(i)
m(j) = no. of movies rated by user j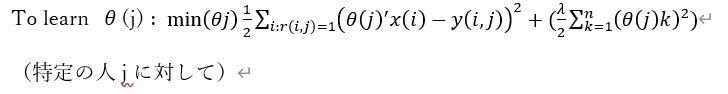
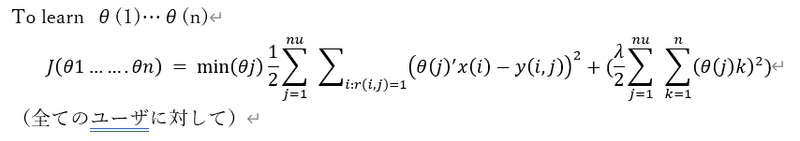
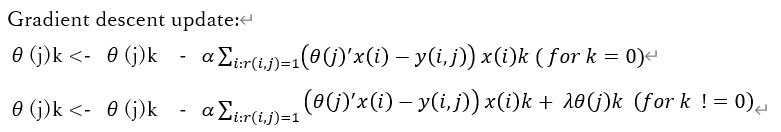
この、Σの後はただのJ (θ1 … θn)の偏微分である。
つまり、この時点では、これらの映画のコンテンツがなんなのかということを補足するフィーチャーがあることを仮定している。(ロマンスがいくつとか)
↓
フィーチャーラーニング(なんのフィーチャーを使うべきか自動で学習する)

映画のフィーチャーを集めるのは実際には困難であり、こんな可能性が高い。
しかし、Alice ~ dave のパラメータ(フィーチャーの好み:ロマンチックなものが好きとか)がわかれば推定できる。
たとえば、θ(1) =[ 0 5 0 ]のとき、アリスはとてもロマンチックな映画が好きで、アクション映画は全く好きじゃないと教えてくれる。
θ(2) =[0 5 0 ] θ(3)= [ 0 0 5 ] θ(4) = [ 0 0 5 ] 同様に、彼らも好みを教えてくれたとする。
Star warsのフィーチャーがわからなかったとして、ロマンス好きのアリス、bobが高評価。反対にアクション好きのカロル、daveが低評価だったので、ロマンスが高く、アクションが低いのだろうなと推定できる。
アルコリズムは、、

つまり、
映画のフィーチャーとそれぞれ個人がつけたratingがわかれば、それぞれ個人の趣向(パラメータ)がわかるし(推定できる)、
個人の趣向とつけたratingがわかれば、映画のフィーチャーがわかる(推定できる)
鶏卵問題だけど、、じゃあどうするか。
ランダムなθでxを出して、そのxを用いてθを出す・・以後繰り返し。。。
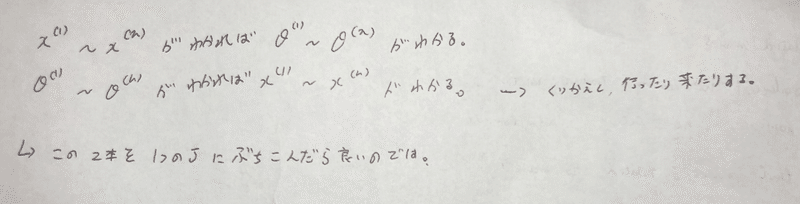
・・・繰り返しじゃなくて、同時に1つの目的関数にぶちこめないか?
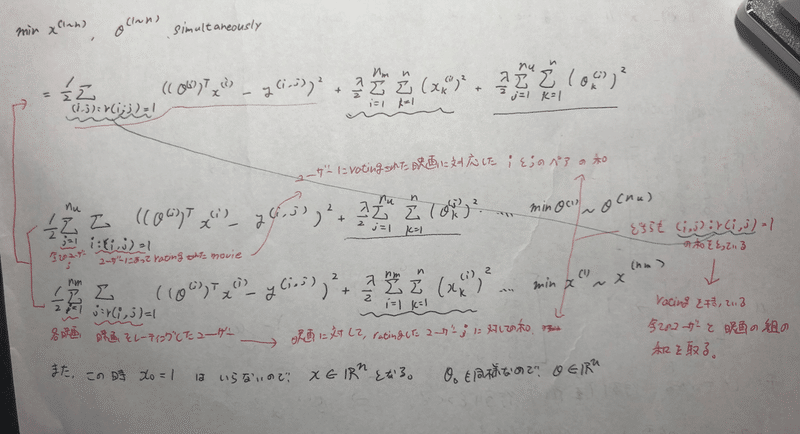
ぶち込みました。
それぞれ、xについて、θについての式が組み合わさっていることが示されています。
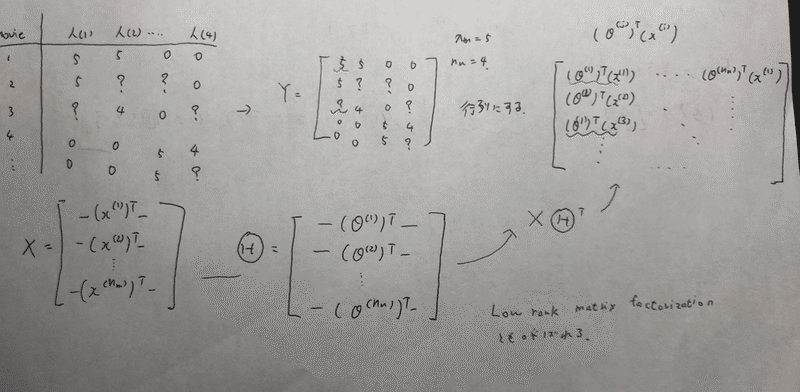
Vector ver
上記の表をYという行列にする。と、予想されるratingは右の行列で表される。θ(j)'x(i)の線形問題で予測できるからね。赤の波線は人(1)の映画(1)に対するratingを予測しているし、青の波線は人(1)の映画(3)に対するratingを予測したもの。
この行列を表すのにもっと簡単な方法が存在する。
全ての映画のフィーチャーを列として積み、行列Xを定義、ユーザー毎のパラメータを取ってきて、列として積み、行列Θを定義。
そうすると、 X * Θ' であらわすことができる。

どうやって似た映画を探して、ユーザーにリコメンドするか。
それぞれのプロダクトi(今回は映画)について、フィーチャーベクトルx∈Rnを学習した。
そこで、|| x(i) - x(j) || がちいさければ、映画 i と映画 j が似ている。よってリコメンドする
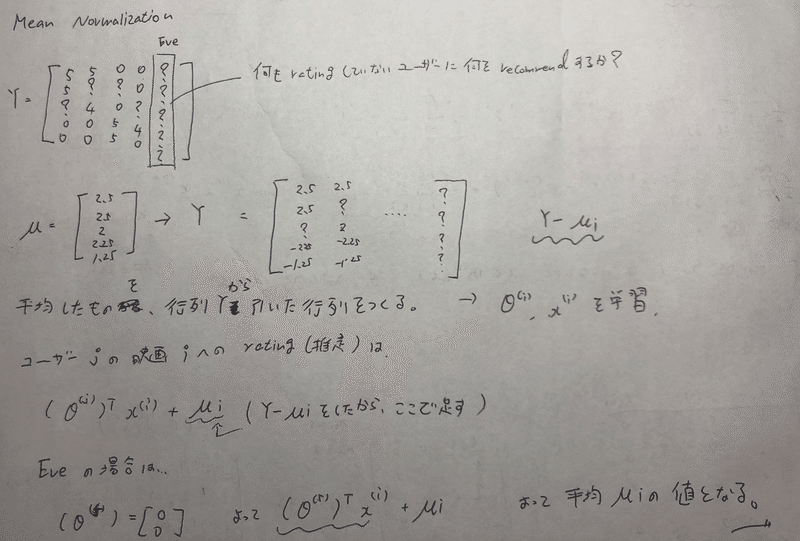
Mean Normalization
何もratingしていないユーザーに何の映画を進めるか??
行列Yを平均したμを作り、行列Yからμを引いた行列を作る。そしてθ、xを学習させる。
ユーザjの映画 i へのrating(推定)は、
(θ(j))' x(i) + μi である。
何もratingしていないEveは、 θ(5) = [ 0 0 ] だから、μi だけ残る。よって、平均値μがEVEの値になる。
課題1.
μとσ^2を計算する関数をつくる。計算するだけ
function [mu sigma2] = estimateGaussian(X)
[m, n] = size(X);
mu = zeros(n, 1);
sigma2 = zeros(n, 1);
===your code here===
for i = 1:n
mu(i, 1) = 1/m*sum(X(:, i))
sigma2(i, 1) = var(X(:, i), 1)
end
課題2.
良さげなεを探します。F1 scoreを使います。
function [bestEpsilon bestF1] = selectThreshold(yval, pval)
bestEpsilon = 0;
bestF1 = 0;
F1 = 0;
stepsize = (max(pval) - min(pval)) / 1000;
for epsilon = min(pval):stepsize:max(pval)
=== your code here ===
cvPredictions = zeros(size(pval,1), size(pval,2));
for i = 1:size(pval)
if pval(i) < epsilon
cvPredictions(i) = 1;
else
cvPredictions(i) = 0;
end
end
tp = sum((cvPredictions == 1) & (yval == 1));
fp = sum((cvPredictions == 1) & (yval == 0));
fn = sum((cvPredictions == 0) & (yval == 1));
prec = tp/(tp + fp);
rec = tp/(tp+fn);
F1 = 2*prec*rec/(prec + rec);
+======
if F1 > bestF1
bestF1 = F1;
bestEpsilon = epsilon;
end
end
end
課題3.
おすすめシステムをつくります。
% Notes: X - num_movies x num_features matrix of movie features
% Theta - num_users x num_features matrix of user features
% Y - num_movies x num_users matrix of user ratings of movies
% R - num_movies x num_users matrix, where R(i, j) = 1 if the
% i-th movie was rated by the j-th user らしいです。
function [J, grad] = cofiCostFunc(params, Y, R, num_users, num_movies, ...
num_features, lambda)
X = reshape(params(1:num_movies*num_features), num_movies, num_features);
Theta = reshape(params(num_movies*num_features+1:end), ...
num_users, num_features);
J = 0;
X_grad = zeros(size(X));
Theta_grad = zeros(size(Theta));
=== your code here ===
J = 1/2 * sum(sum(R.* ((X * Theta' - Y).^2)));
X_grad = ((X*Theta' - Y).*R)*Theta;
Theta_grad = ((X*Theta' - Y).*R)' * X;
reg = lambda/2 * (sum(sum(Theta.^2)) + sum(sum(X.^2)));
J = J + reg;
X_grad = X_grad + lambda * X;
Theta_grad = Theta_grad + lambda * Theta;
この記事が気に入ったらサポートをしてみませんか?