CourseraMLweek7で紛らわしかったところ(SVM,kernel)

SVM with kernelsを五行で、、
Training setのxをランドマークl(L)として置く、カーネル関数を使い、validation set のxとlとの距離を取る。y(validation set)を使ってθを調整し、何処までの距離なら陽性、どこまで離れていたら陰性と判定すればエラーが最小になるか学習させる。あと、正則化のCも同時に。
ロジスティック回帰
min 1/m * Σ[y * (-log(h)) + (1-y)* ( ( -log ( 1-h)))] + λ/2m * Σθ.^2
Support vector machine(SVM)
min C *Σ[ y *cost1(θ’X) + (1-y)*cost0(θ’x) ] + λ/2 * Σθ.^2
mがなくなっている。しかしただの定数なので、出てくるθは変わらない。
ロジスティック回帰では、
A + λ*B を最小化するのに、λを使って調節した。
その代わり、support vector machineでは、
C * A + B という風に、Cを用いて調節する。
λを大きい値にすると、Bにとても大きい重みを加える
Cを小さい値にすると、Aに対してBにとても大きい重みを加える。同じものでしょ? ( C = 1/λ みたいな風に考えていいよ)
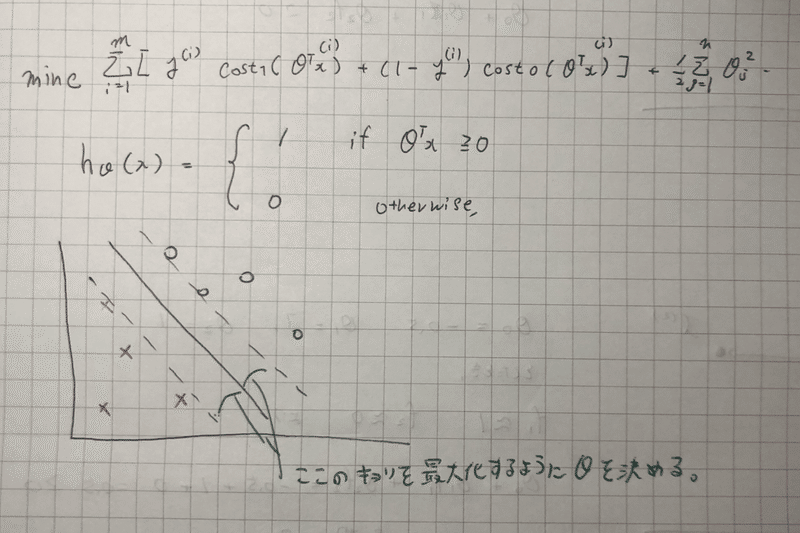
ロジスティックと比べて何が違うか。
直観的に言うと、ギリギリでなく、よりきっちり、陽性と陰性を分けるもの。よって大きなマージン分類器ともいわれる。
カーネル
複雑なバイナリー問題の時、次数を増やすのでは、計算量が膨大になるというデメリットがある。そこでほかのフィーチャーの選択肢がないか?
↓
ランドマークを置き、そこに近いかどうかで陽性/陰性を判定できないか?
Q1.ランドマークどうやって置くの?
A1.training set のxをそのまま置く( l(landmark)という記号に変える)
その後、f : 入力データxとランドマークの距離を示す f を以下の式で計算する。
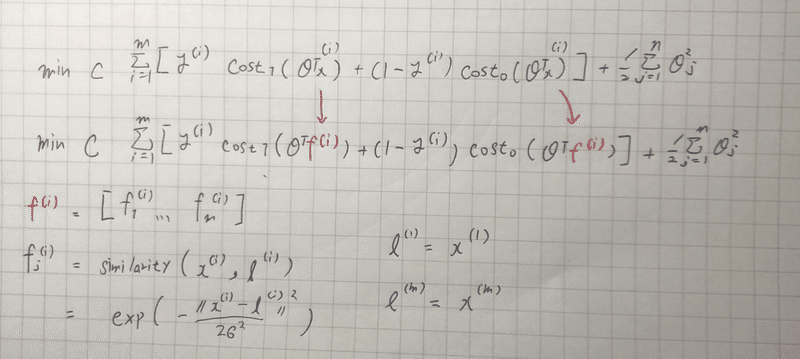
f1 = Similarity(x , l(1)) = exp(-||x-l(1)||^2/2σ^2)
|| || ←これはベクトルの距離のこと
Similarityのことをカーネル関数という。 xと l(i)の類似度を表す。
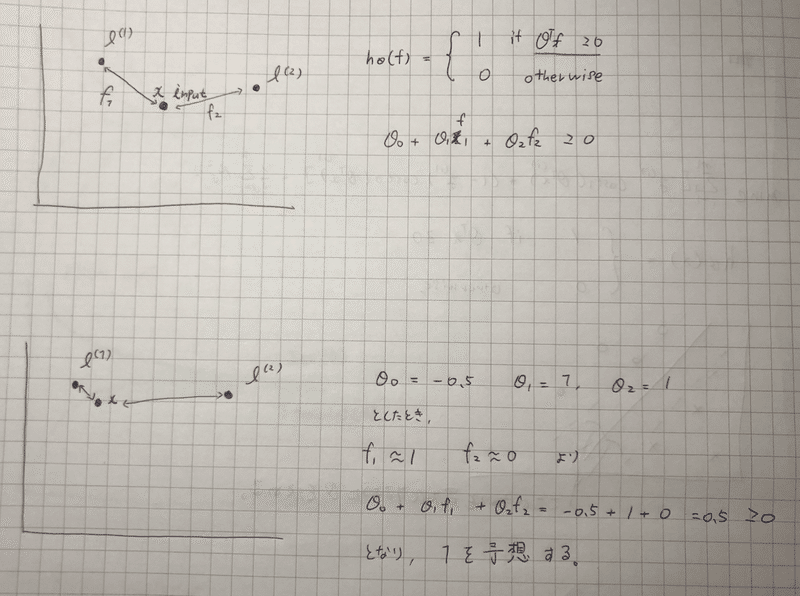
θの値によって、何処までの距離が1と判定されるか調節されているとわかる。
y=1のとき(validation setの) hが1と判定するように、エラーを少なくなるようにθを学習させる。
線形 vs 非線形
linerKernel __ 線形分離の時
C = 定数
Model = svmTrain(X, y, C, @linerKernel)
gaussianKernel__非線形分離の時
C= 定数 σ=定数
Model = svmTrain(X, y, C, @(x1, x2) gaussianKernel(x1, x2, sigma))
課題
gaussian kernel__
指令:Fill in this function to return the similarity between x1 and x2 computed using a Gaussian kernel with bandwidth sigma
らしいです。
sim = exp(-(sum((x1-x2).^2))/(2*sigma^2))
公式通りでした。
SVM with kernels で適当なσとCの値を求める問題
C_param = [0.01 0.03 0.1 0.3 1 3 10 30];
sigma_param = [0.01 0.03 0.1 0.3 1 3 10 30];
results = zeros(64,3); ←eyeでもzerosでも動いた。謎、
errorRow = 0;
for C_test = [0.01 0.03 0.1 0.3 1, 3, 10 30]
for sigma_test = [0.01 0.03 0.1 0.3 1, 3, 10 30]
errorRow = errorRow+1
model = svmTrain(X, y, C_test, @(x1, x2) gaussianKernel(x1, x2, sigma_test));
predictions = svmPredict(model, Xval);
prediction_error = mean(double(predictions ~= yval));
results(errorRow,:) = [C_test, sigma_test, prediction_error];
end
end
sorted_results = sortrows(results, 3);
C = sorted_results(1,1);
sigma = sorted_results(1,2);
sortrows(Matrix , no of 列) で、並び替えして、(今回だと列3はprediction_error)、C, σ共に最上列のもの(prediction_errorがmin)を選ぶ。
この記事が気に入ったらサポートをしてみませんか?