CourseraMLweek10で紛らわしかったところ(Stochastic Gradient Descent,mini-batch,map reduce)

Stochastic Gradient Descent
大規模データを使うことができればそりゃいいが、計算量が膨大になる。
また、たとえば1億のセットがあったとして、1000くらいのセットを無作為抽出して、high variance 問題か、high bias 問題か学習曲線をプロットしてみて確認する必要がある。
(J cv と J training について、x軸をtraining size , y軸をerror)
→ high variance問題ならsetを足すことで改善が見込めるが、high bias ならそうではない、でしょ。
これまでに使用していたBatch Gradient Descent は、計算量がとても膨大なため、ビッグデータに適さない。→Stochastic Gradient Descent の出番。
何が違うか
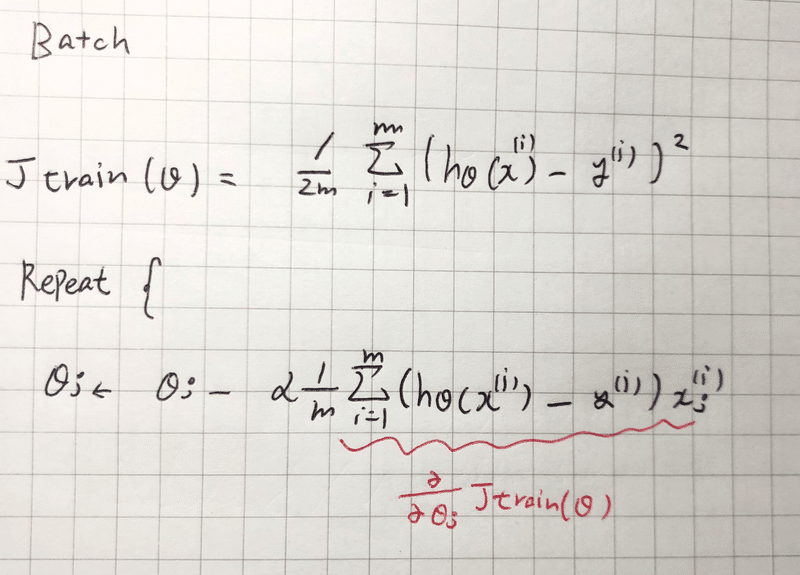
これが(従来の)Batch gradient descent。
一回の勾配(θの更新)にすべてのデータを読み込み、和をとる必要がある。そのため何億といったデータある場合、とっても計算に時間がかかる
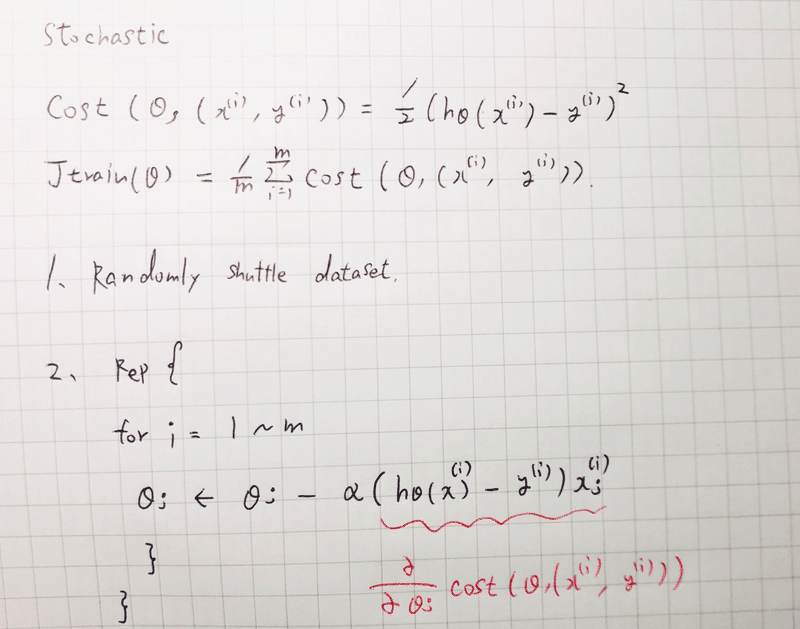
Stochastic Gradient Descent は、一つのデータ毎に勾配(θの更新)を行う。そのため、いちいち一回のiterationのために何億といったデータを読み込む必要がない。
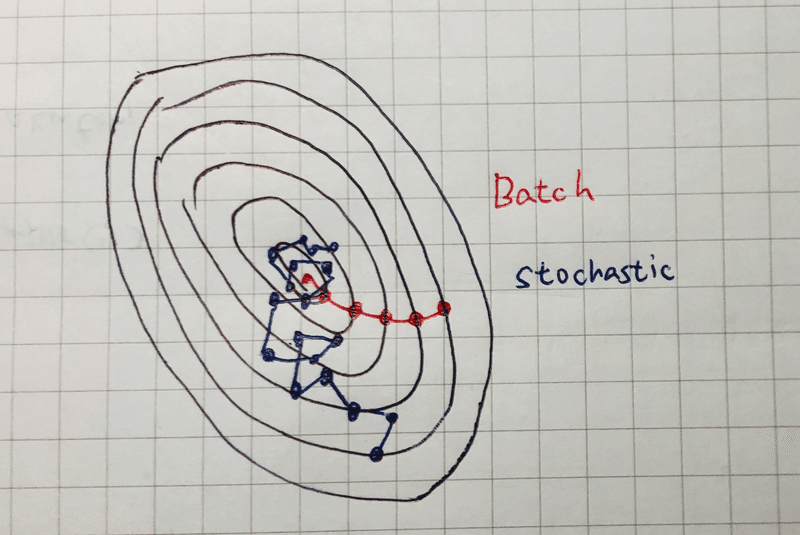
iteration毎の収束していく図
Stochastic Gradient Descent は、上記の図のように、Batchの意味するようなグローバル最小の値に収束することはない。しかし、グローバル最小のそばをうろうろし続ける。しかし、実用上その値で全く問題はない。
また、アルコリズムを何回回せばいいのか。という疑問が出る。
トレーニングセットのサイズが十分に大きければ、~10回ほどでいい。たとえば3億とかあるなら、1回でいいかもね。ということらしい
Mini -batch gradient descent
Batch gradient descent は、1回のiterationで、m個すべてのexampleを使う。
Stochastic gradient descent は、1回のiterationで、1個のexampleを使う。
Mini-batchはこの2つの中間に位置するものである。
Mini-batch gradient descent は、1回のiterationで、b個(1<b<m)のexampleを使う。
また、このbは、mini-batch sizeと呼ばれ、大体2~100くらいの間の値をとるのが典型的である。
Mini-batch gradient descent は、式を見てもBatchと比べ、早く処理が行えそうだ。
では、Stochastic と比べるとどうか?
Mini-batchがStochasticと比べて、めっちゃ良さげなのは、良いvector実装がある時だけ。
その場合、このアルコリズムはよりベクトル化した形で実装できる。それによって、良さげな並列処理のパッケージが使用できるようになったりする。
一方、Stochasticは相対的に並列化するものがない。1回に1つしかexampleを見ていないから。1個からb個に増やすことで、計算量が増えるが、逆にベクトル化できればStochasticよりも処理が高速になる可能性がある。
アルコリズムは・・・
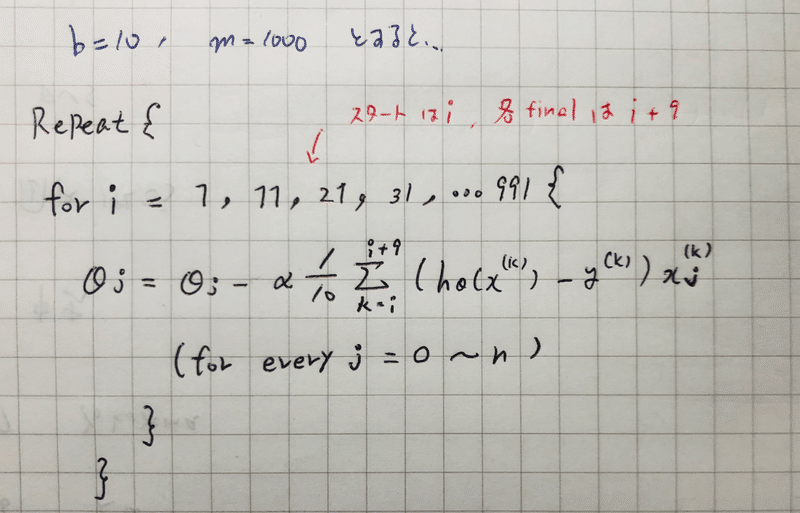
b = 10 なので、スタートが1, 11, 21, ,,, となっていくのがわかる。
どうやって収束を確認しよう?また、どうやってαの値を決めよう?
Batchの時は、iterationごとにコスト関数をプロットしてみて、iterationごとに減少しているのを確認することだった。
しかし、コスト関数を算出するには、全体のトレーニングセットを読み込む必要があった。
それは避けたい(計算量が膨大だから)、じゃあどうするか。
前に定義したコスト関数を用いる。単体のトレーニングexampleに関するパラメータθのコストは単にそのexampleにおける二乗誤差の半分である。
Stochastic gradient descentで、あるx(i),y(i)を使ってθをアップデートする直前に、そのexampleに対して仮説がどれだけ良いか計算してみる。絶対θをアップデートする前に行う、何故なら、そのexampleでアップデートした後では、そのexampleについて代表的な値よりももっと良い値になってしまうから。
→1000回のiterationごとにその前の1000ステップで計算したコスト関数の平均をプロットしていく。1-1000 average, 1001-2000average,,,,,,,
そのプロットを確認することで、収束が確認できる。
xを各1000回ごとのiterationでの平均、 yを J でプロットすると、
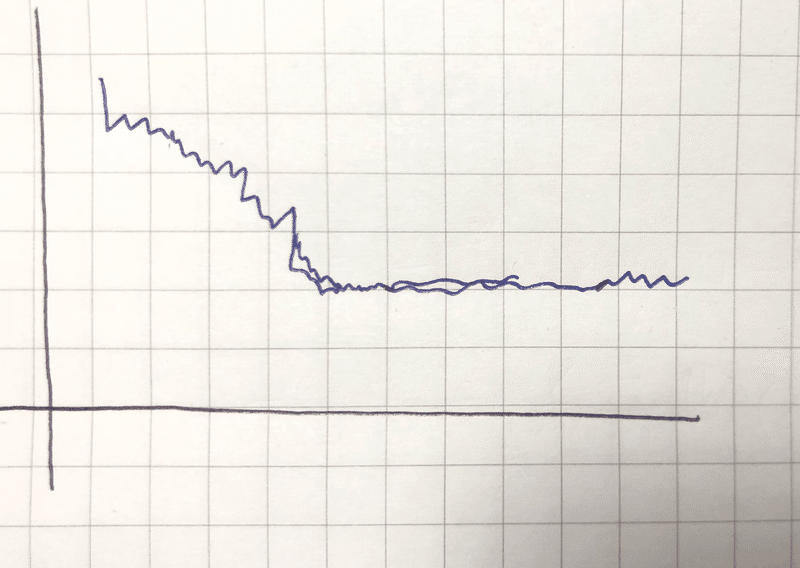
こんな図が得られたとき、うまく収束している
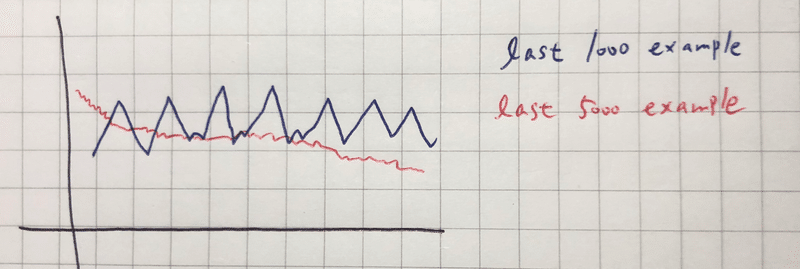
1000回の平均値で収束していないようなグラフが得られた場合に、平均を取る回数を増やし5000回とかにすると、収束していく様子がみられたりする。
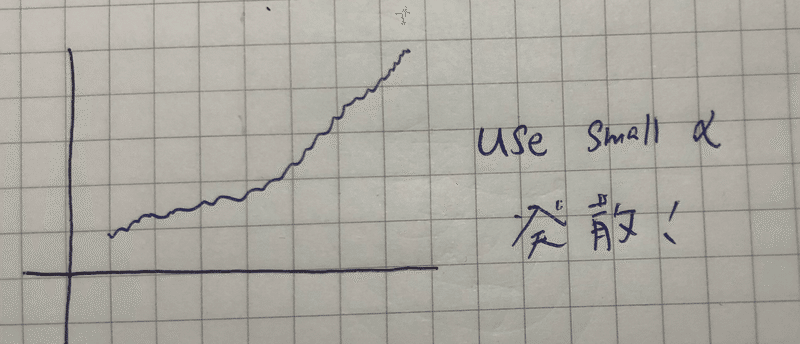
こんなグラフが得られたとき、θは収束せずに発散してしまっているので、αの値を小さくする必要がある。
Stochastic gradient descent はグローバル最小に収束せず、ずっと回りをうろちょろする。
収束させるには、αの値を徐々に下げていくというものがある。
具体的には、α= c/no.of iteration + d (c,d =定数) とかにする。
定数のc、dを決めるのが難しいが、もしうまく決めることができたら、
グローバル最小にちかづくにつれてαが小さくなり(繰り返し回数が増える→分母がでかくなる)、ふらつきが小さくなっていく。
Online Learning
連続的に流れてくるデータ1つ (x, y)に対して常にθを学習していくアルコリズム。常にθの値を更新していくため、1度使ったデータは捨て2度と使うことがない。
例えば、配達業者のwebサイトを運営しているとする。
ユーザーがやってきて、AからBまで荷物を運びたいとする。そして僕らは、何ドルで引き受けるかユーザーに返答する。その結果ユーザーは僕らのサービスを使うかどうか、y=0,1の出力を返す。
僕らは、ユーザーがy=1を返すような提示する値段の最適化を行いたい。
具体的には、提示した価格以外にも、ユーザーの特徴をとらえたフィーチャーを考え出したとして(年齢とか)ラベルが1の確率を算出する。
やりたいことは、ラベルが1でありつつ、価格をできるだけ高く設定すること。
ラベルが1(y=1)である確率をモデリングする方法として、ロジスティックやニューラルネットが考えられる。
ロジスティックの場合
Repeat forever {
Get (x , y ) corresponding to user
Update θ using (x, y)
Θj <- θj – (hθ(x) – y)*xj (j = 0~n)
}
つまり、それぞれ連続的に訪れてくるユーザー(x,y;フィーチャー,結果)に対してθを流動的にアップデートしていく。
Online learningの強み
すでに巨大な人数のデータがあるなら、従来の方式で(固定したデータセットで)やってもいい。
しかし、この方式のいいところは、ユーザーの特徴に対応できる点。
例えば、景気や季節によってユーザーの特徴は変わっていくことが想像できる(例えば季節によってもう少しお金だしてもいいかなとか)、それに対応することができる。
したがって、以前とは異なるフィーチャーが重要になった場合、online learningはそれに適応していってくれる。
別の例として、、
商品検索のアプリケーションで、ユーザーに良い検索結果のリストを与えるよう学習するため、アルコリズムを使いたい。
ユーザーが検索窓に、「Androidスマートフォン」とか、何か入力したとして、そのストアには100個スマートフォンがあったとする。
その時、どの10個をユーザーに対して表示させるか最適化したい。
具体的には、
スマホと検索ワードの近さなど、フィーチャーベクトルxを構築できる。
またその時、ラベル1(y=1)は、ユーザーのクリックで、それ以外が0
フィーチャーベクトルxが与えられたときに、y=1の確率を求めたい。
そして、算出できたなら、各スマホについて、最もクリックしてくれそうな10個をユーザーに対して表示させるってワケ。
つまり各ユーザーごとに、(x, y)のセットが10個得られる。というのも、表示した10個のスマホについて、それぞれフィーチャーベクトルがあり、クリックされたかどうか結果を返してくれるから。
よって、ユーザーが来るたびに、ユーザーが最もクリックしそうなスマホを10個表示させ、どれをクリックしたかによってθを学習していく。
Map Reduce and Data Parallelism

図はBatch Gradient Descentの時。
データがとても膨大な数存在するとき、データをいくつかに分け、それぞれの群を違うコンピュータに計算させ、出てきた値を結合させるテクニック。
( x(1), y(1) ) ~ ( x(400), y(400) ) とデータがあったとして、
Machine 1 が ( x(1), y(1) ) ~ ( x(100), y(100) ) まで使用し
temp(1) = Σ(i=1~100) ( hθ(x(i)) - y(i) ) * x(i)j を算出。
...
temp(4)まで算出。
その後、結合し
θj <- θj - α1/400 * (temp1 + temp2 + temp3 + temp4)
と、gradient descent を行う。
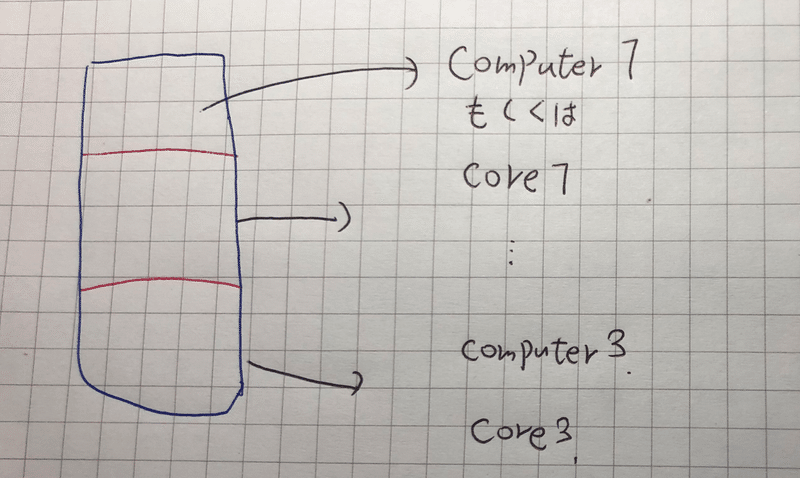
データの割り振りは、コンピュータ毎でなく、CPUのコア毎に振り分けることができる。スゲー
この記事が気に入ったらサポートをしてみませんか?