
Hugging FaceのZeroGPUspaceで画像生成環境を作る

はじめに
Hugging FaceはAI関連で有名なオープンソースプラットフォームです
モデルのダウンロードなどでお世話になったりするHugging Faceですが、
Zero GPU spaceがとても良さげだったので試してみました
なお、環境作成にあたっては、以下のあるふさんのQiitaを大変参考にしました
ほぼそのまま流用ともいう
Hugging Faceのアカウント作成
ここは省略していいかなあ
作成要望があれば書こうかなとか思っています
…ということでアカウントが出来ました!✨
Zero GPU Space?
Zero GPU SpaceはSpaceでHuggingFaceのProアカウント(有料)で使用できるようになる
Spaceで選べるGPUのことなのですが、、
とりあえず、Proアカウント→Space→ZeroGPUな感じで順に記載していきます
Proアカウント
HuggingFaceにログイン後、上の方に以下のようなバーがあります

一番右のPricingをぽちー
すると以下のような画面になります

真ん中にPro Accountの説明があり、Pro Accountの一番上に
ZeroGPUの説明があります
Pro Accountは月額$9で使用可能です
Pro Accountをぽちーするともう少し細かい(?)説明のページへ飛び
→Get Pro のボタンよりPro Account登録が可能です

Space
HuggingFaceのSpaceでは様々なデモが公開されています
また、右のほうにある Create new Space ボタンで
自分のSpaceを作成することもできます
Space作成については後程環境作りとして記載するので
ここでは省略

ZeroGPU
ZeroGPUの詳細についてはPricingのProアカウントより辿れる
ページに記載があります
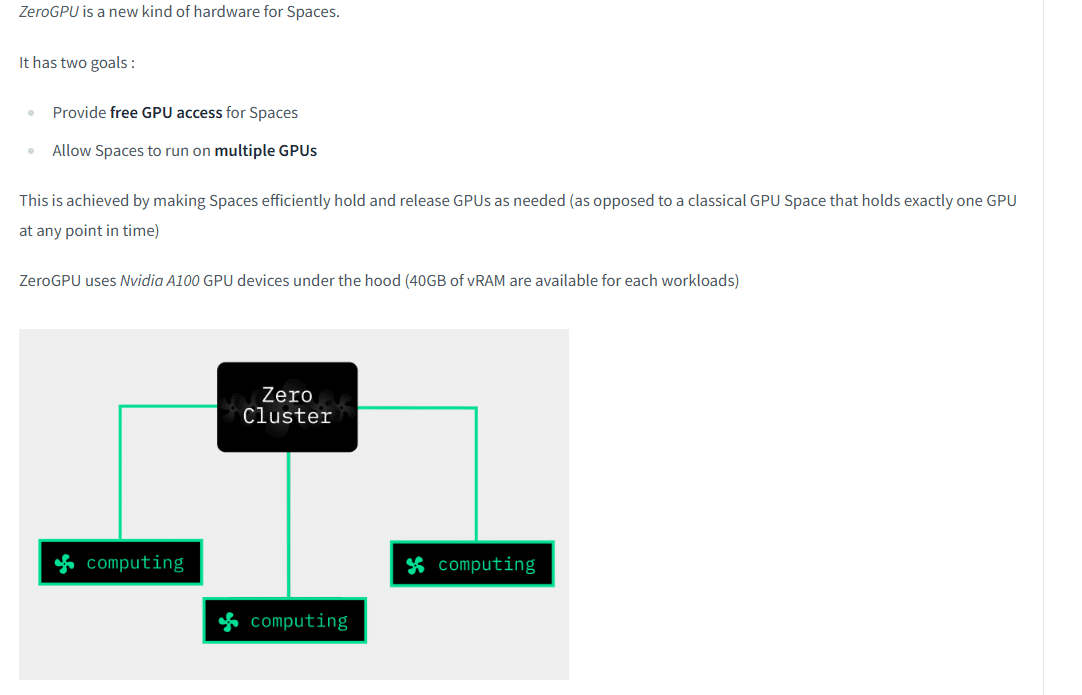
ポイントとしては、
・(Proアカウントであれば)追加コストなしでGPUを使用可能
・つよつよGPU(A100)を使用可能
といった形になります、すごー!👀✨
コスト関係の話は、Spaceのコスト一覧を見るとわかりやすいです

Proアカウントは月額$9、
A100は1時間で$4なので、2時間と少し使用できることになります
とはいえ、当然にいろいろと制限はあり、、
1)Gradioでしか使えない
2)1回で最大120秒しか使えない

といった制限があります
画像生成的には問題ない長さですが、
モデルのトレーニングとか長めの動画生成とかには使えないのかな?
環境作り
そんな感じで実際に作っていきます
まずはSpaceの Create new Spaceをぽちー

すると以下の画面に飛びます
Space nameに作りたいSpaceの名前、
Licenseに何かしらをいれます(入力なしでも作成はできます)
Licenseは使用モデルなどに左右されるのかなあ
Select the Space SDKはGradioを選択します

Gradioを選択すると、以下のテンプレート選択が追加で出てきます
今回は画像生成環境を作るので、ひとまずtext-to-imageを選択します

Space hardwareを選択するといろいろ選べるので
ZeroGPU Nvidia A100 を選択します


公開用(自分以外も使えるようにする)場合はPublic、
自分用の場合はPrivate を選択し
Create Spaceを押します
すると、なんだかセットアップが入り、、
あるふさんのQiita記載の通りエラーが発生するので修正のたFilesへ移動します

そしてapp.pyをぽちー
以下のような画面に行きます
edit をぽちーすると編集可能になります
モデルはSDXLの標準より変更したかったり
モデルのリンクを張りたかったりしたので
今回は以下の実装にしました
import gradio as gr
import numpy as np
import random
#from diffusers import DiffusionPipeline
from diffusers import StableDiffusionXLPipeline
import torch
import spaces
MAX_SEED = np.iinfo(np.int32).max
MAX_IMAGE_SIZE = 1216
#pipe = DiffusionPipeline.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16", use_safetensors=True)
pipe = StableDiffusionXLPipeline.from_pretrained(
#"yodayo-ai/kivotos-xl-2.0",
"yodayo-ai/holodayo-xl-2.1",
torch_dtype=torch.float16,
use_safetensors=True,
custom_pipeline="lpw_stable_diffusion_xl",
add_watermarker=False,
variant="fp16"
)
pipe.to('cuda')
prompt = "1girl, solo, upper body, v, smile, looking at viewer, outdoors, night, masterpiece, best quality, very aesthetic, absurdres"
negative_prompt = "nsfw, (low quality, worst quality:1.2), very displeasing, 3d, watermark, signature, ugly, poorly drawn"
@spaces.GPU
def infer(prompt, negative_prompt, seed, randomize_seed, width, height, guidance_scale, num_inference_steps):
if randomize_seed:
seed = random.randint(0, MAX_SEED)
generator = torch.Generator().manual_seed(seed)
image = pipe(
prompt = prompt+", masterpiece, best quality, very aesthetic, absurdres",
negative_prompt = negative_prompt,
guidance_scale = guidance_scale,
num_inference_steps = num_inference_steps,
width = width,
height = height,
generator = generator
).images[0]
return image
css="""
#col-container {
margin: 0 auto;
max-width: 520px;
}
"""
with gr.Blocks(css=css) as demo:
with gr.Column(elem_id="col-container"):
gr.Markdown(f"""
# Text-to-Image Demo
using [Holodayo XL 2.1](https://huggingface.co/yodayo-ai/holodayo-xl-2.1)
""")
with gr.Row():
prompt = gr.Text(
label="Prompt",
show_label=False,
max_lines=1,
placeholder="Enter your prompt",
container=False,
)
run_button = gr.Button("Run", scale=0)
result = gr.Image(label="Result", show_label=False)
with gr.Accordion("Advanced Settings", open=False):
negative_prompt = gr.Text(
label="Negative prompt",
max_lines=1,
placeholder="Enter a negative prompt",
visible=False,
)
seed = gr.Slider(
label="Seed",
minimum=0,
maximum=MAX_SEED,
step=1,
value=0,
)
randomize_seed = gr.Checkbox(label="Randomize seed", value=True)
with gr.Row():
width = gr.Slider(
label="Width",
minimum=256,
maximum=MAX_IMAGE_SIZE,
step=32,
value=832,
)
height = gr.Slider(
label="Height",
minimum=256,
maximum=MAX_IMAGE_SIZE,
step=32,
value=1216,
)
with gr.Row():
guidance_scale = gr.Slider(
label="Guidance scale",
minimum=0.0,
maximum=20.0,
step=0.1,
value=7,
)
num_inference_steps = gr.Slider(
label="Number of inference steps",
minimum=1,
maximum=28,
step=1,
value=28,
)
run_button.click(
fn = infer,
inputs = [prompt, negative_prompt, seed, randomize_seed, width, height, guidance_scale, num_inference_steps],
outputs = [result]
)
demo.queue().launch()
基本的にはあるふさんのQiita記載のコードをベースにしつつ、、
dissusers importを差し替え
from diffusers import StableDiffusionXLPipelineモデルに関連する記述を差し替え
pipe = StableDiffusionXLPipeline.from_pretrained(
#"yodayo-ai/kivotos-xl-2.0",
"yodayo-ai/holodayo-xl-2.1",
torch_dtype=torch.float16,
use_safetensors=True,
custom_pipeline="lpw_stable_diffusion_xl",
add_watermarker=False,
variant="fp16"
)
pipe.to('cuda')
prompt = "1girl, solo, upper body, v, smile, looking at viewer, outdoors, night, masterpiece, best quality, very aesthetic, absurdres"
negative_prompt = "nsfw, (low quality, worst quality:1.2), very displeasing, 3d, watermark, signature, ugly, poorly drawn"モデル設定とGradio表示関連設定を差し替え
css="""
#col-container {
margin: 0 auto;
max-width: 520px;
}
"""
with gr.Blocks(css=css) as demo:
with gr.Column(elem_id="col-container"):
gr.Markdown(f"""
# Text-to-Image Demo
using [Holodayo XL 2.1](https://huggingface.co/yodayo-ai/holodayo-xl-2.1)
""")
with gr.Row():
prompt = gr.Text(
label="Prompt",
show_label=False,
max_lines=1,
placeholder="Enter your prompt",
container=False,
)
run_button = gr.Button("Run", scale=0)
result = gr.Image(label="Result", show_label=False)
with gr.Accordion("Advanced Settings", open=False):
negative_prompt = gr.Text(
label="Negative prompt",
max_lines=1,
placeholder="Enter a negative prompt",
visible=False,
)
seed = gr.Slider(
label="Seed",
minimum=0,
maximum=MAX_SEED,
step=1,
value=0,
)
randomize_seed = gr.Checkbox(label="Randomize seed", value=True)
with gr.Row():
width = gr.Slider(
label="Width",
minimum=256,
maximum=MAX_IMAGE_SIZE,
step=32,
value=832,
)
height = gr.Slider(
label="Height",
minimum=256,
maximum=MAX_IMAGE_SIZE,
step=32,
value=1216,
)
with gr.Row():
guidance_scale = gr.Slider(
label="Guidance scale",
minimum=0.0,
maximum=20.0,
step=0.1,
value=7,
)
num_inference_steps = gr.Slider(
label="Number of inference steps",
minimum=1,
maximum=28,
step=1,
value=28,
)
run_button.click(
fn = infer,
inputs = [prompt, negative_prompt, seed, randomize_seed, width, height, guidance_scale, num_inference_steps],
outputs = [result]
)したりしています
あれ?? あらためて見ると結構変わってる…??
ベースとは??
…といった感じで変更し終わったあとは
以下のCommit changes to main をぽちーして
変更を確定させます
Commit changes(薄っすらと Update app.pyと記載の箇所)は
変更コメントを残す機能みたいなので
入れたい人は入れてcommitしましょう

Commitした後は以下の感じで再設定が入ります(青いところ)

青→緑になると、アプリが何かしら動いている状態になります

エラーの際は赤くなるので、頑張って直します。。
結果
できました!!
LinaqrufさんのHolodayo XL 2.1にモデル変更したらデモがつよつよになりました🥳 https://t.co/z1HflS8mev pic.twitter.com/F9XvIrXI84
— える (@el_el_san) June 9, 2024
そして結果として出来たデモはこちら✨
公開設定で作っているので誰でも使用可能になっているはずです(多分きっと)
まあ、Proアカウント解除したら維持は無理なので使えなくなってるかもですが。。
試してみてわかったこと(デメリット?)
画像生成だと割と
・生成→プロンプトちょっと変えて、、→生成→
ってやると思うのですが、割とすぐ上限がきます💦
割とすぐ上限が来ますね…😭 まあそれはそうか… pic.twitter.com/x0aPuaXSMu
— える (@el_el_san) June 9, 2024
これはユーザーごとに設定されているらしく
作成者(=Proアカウント登録者)でもユーザーでも変わらない(?)みたいです
ほぼ連続で60秒くらい使用すると5分程度またされる感じ?なのかな??
最初見たエラー表示は1:30だった気がするので
エラーにかかるほどWaitが伸びていくとか…?
ちょっと詳細は確認しないとわかりませんが。。
この、思った以上に上限が短い仕様は使い始めるまでわからなかったので
注意かなあと思いました
主に自分で使うように作っているひとは特に
とはいえ、公開用にも自分用にも使えて
月額固定でGPU(しかもつよつよ)が使えるのは素敵ですね…!!
この記事が気に入ったらサポートをしてみませんか?