
イークラウドのデータ分析基盤の開拓

株式型クラウドファンディングを運営するイークラウドで開発に携わっているクスムレです。
イークラウドのデータの可視化(ダッシュボードの作成)には何使っていて、データソース等はどうやって集めているんだろう、について書きます。
おことわり
書くこと
・現状のデータ分析基盤構築に至った課題、背景
・構築したデータ分析基盤構築の概要
・苦労、工夫した点
・これからの取り組み
書かないこと
・具体的なコードやシステムの連携の設定など具体的な方法
課題
今年の6月17日に事前投資家登録を以てサービスローンチをしたばかりで、
まだこれから株式投資型クラウドファンディングと言う業界、イークラウドを盛り上げていくため、これからデータを分析してまだまだサービスの成長に努めていきたいと思っています。
データ分析をするにはまずは可視化する必要があります。データを可視化するに当たって、まずは課題を洗い出します。
1. データ特性によって、あちこちにデータが散在していること。
例えば、ユーザの登録状況やステータス管理はサービスのDBで全てを管理しているし、日々のPV,UU,SSなどのトラフィックデータはGoogle Analyticsだし、サービスのログは(イークラウドはAWSに乗っているので、)S3に置いていたりするので、あのデータってどこで見れたっけ?が発生し得ます。
2. メンバーの全員にとってアクセシビリティが良いこと
あちこちにデータが散在していると、こんな問題が発生します。
・あのデータってどこで見るんだっけ???
・DBやログのエンジニアしかアクセスできないデータはエンジニアに依頼して抽出する必要がある(その場合は個人情報保護のため、適切なデータ選択、マスキングを行う必要もあります)
→ 双方向のやりとりが何度か発生するので非効率的。
・その他細かなトラフィックデータなど、そこまでセンシティブでない数値は各々で確認...となって結局見ない
理想として、サービスに関わる全ての人に数値を意識できる環境であって欲しいと思います。 どこで見れるかわからないと探す手間になってしまうので、途中離脱してしまう可能性が高くなります。
なので、データは誰もが意識できるプラットフォームにしたい。と言う想いが念頭にある上で、どうあるべきか考えました。
これらをもとに要件をまとめると、
・社内の誰からでもアクセシブルであること
・故にデータはどこか一箇所に集中させる
・できるだけ属人化しない、サステイナブルなシステムを
・でもあまり面倒なことはしない(したくない)
これを元に、ダッシュボードを作成しました。
構成
ざっくりこんな構成です。

BIツールはQuickSightを採用
BIツールはAWSのQuickSightを選択しました。 採用理由としては以下が挙げられます。
・データソースが豊富、データの繋ぎ込みが楽である(RDBのデータ同士、又はRDBのデータとCSVをGUIでJOINできる)など使い勝手が良いこと
・開発者、閲覧者のアカウントを発行しても非常に安価であること
・サービスがAWS上に乗っているから(←)
ちなみに、使用できるデータソースは以下になります。

また、データのJOINは以下のように、カスタムSQLとCSVもGUIであっても簡単に行うことができます。
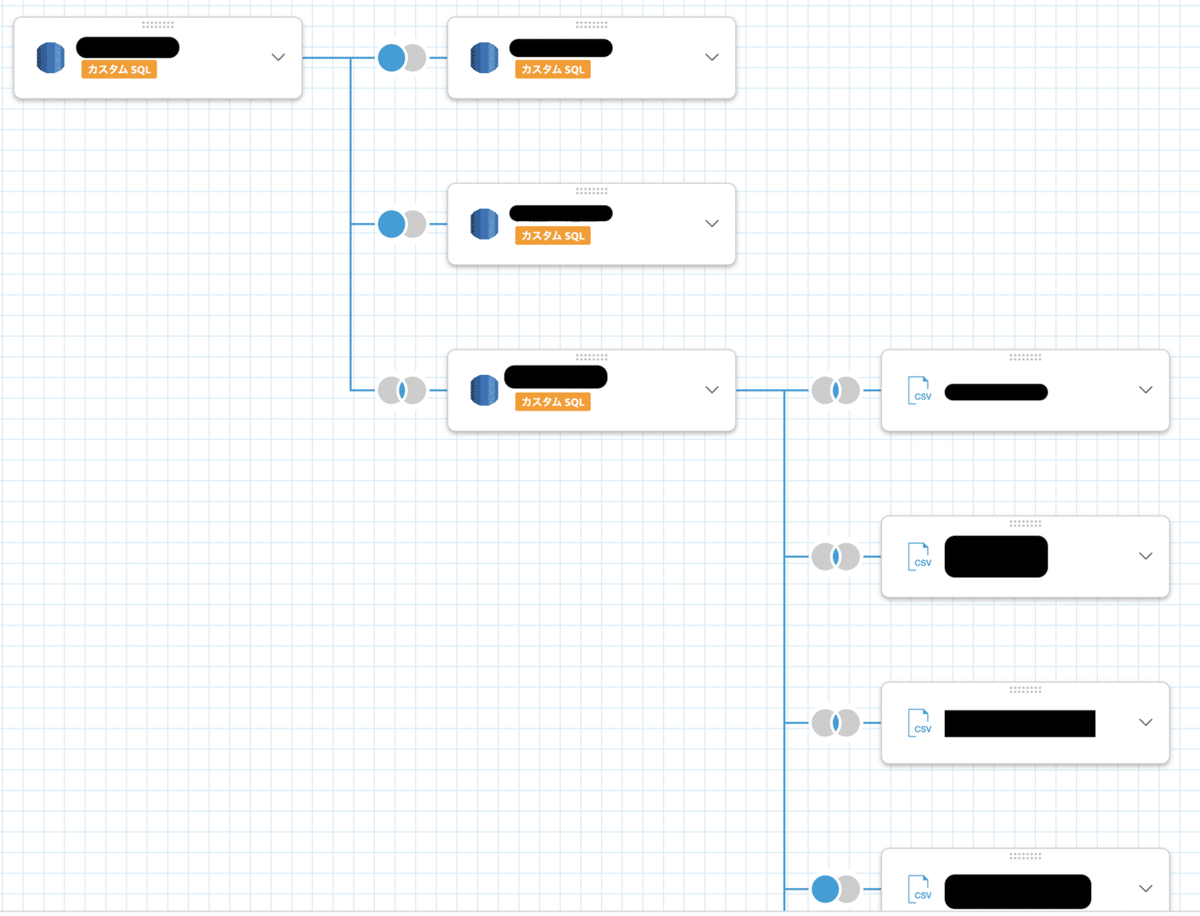
データ間の青と灰色の●がJOINのタイプを表します。INNER, LEFT, RIGHT, FULLのいろんなタイプのJOINをクエリを書くことなく設定できます。

アプリケーションログ
まず、サービスサイトのアプリケーションログですが、csv形式でS3に格納されています。基本的にログはAthenaを利用して中身を確認しています。
※なかなかマニアックなデータかつ、基本的にはエンジニアしか見ないデータになるので、これはQuickSightで可視化していませんが、Athenaとの繋ぎ込みもGUIでぽちぽちでできるので、非常に簡単です。
DB内のデータ
DBのデータは同じAWS環境にあるので、QuickSightとRDBの連携は非常に容易に行えました。 データソースとして登録しておけば、あとはSELECT文書くだけです。 可視化の際にフィルタリングしたり、計算フィールドという機能でデータ同士の四則演算やデータの細かなフォーマット、集計もGUIベースで行えるので、この段階で細かいことを考えず、クエリを書いていけるのでとても便利でした
右側に使用できる元のデータや使用できる関数などが標準で用意されており、左側のエディタで編集していく流れになります。関数の構文や詳細のリンクがヘルプで入っているので地味に助かります。w

Google Analytics
Google Analytics(GA)のデータは、スピード重視だったということもあり、元々スプレッドシートで簡易的に可視化していました。 スプレッドシートの方でGAと連携してレポートを吐き出します。 ここで、どんな数値が欲しいか、どんな条件をつけるかなど設定しておきます。
(ただし、全てのデータは厳しいのであくまでも大まかな数値、基礎的なトラフィックに関わるKPIに絞り、詳細数値は結局は各々GAで見てもらう必要があると思います。 )
これでも大きな問題はないのですが、トラフィックをみるときはスプレッドシート(GA)、その他はQuickSightでみる必要があるような構造は問題に感じていて、一つにしたいという想いがありました。
そこで、Google Apps Script(GAS)を利用して、スプレッドシートに吐き出したGAのデータをCSV化してS3に格納し、毎日更新するようにしました。
function csvUploadToS3() {
// S3ライブラリ
// MB4837UymyETXyn8cv3fNXZc9ncYTrHL9
env = {
'access_key': 'xxx',
'secret_key': 'xxx',
'backet_name': 'xxx',
'backet_dir':'hoge.csv'
}
const ss = SpreadsheetApp.openById('スプレッドシートのID');
const sheet = ss.getSheetByName('取得するスプシのタブ名');
const data = sheet.getRange('取得範囲').getValues();
let csv = '';
for ( var i = 0; i < data.length; i++ ) {
// --
// CSV化処理はデータの形式によって処理が異なるので割愛
// --
}
}
uploadExec(csv)
}
function uploadExec(csv) {
// バイナリに変換
csv = Utilities.newBlob(csv);
var s3 = S3.getInstance( env.access_key, env.secret_key );
s3.putObject( env.backet_name, env.backet_dir, csv, {logRequests:true} );
}S3のポリシーで、アップロードのみ可能にしておく必要があるのでご注意を!
マニフェストファイル(↓)でS3のどこのファイルを見にいくか定義しておくと、あとはQuickSightがいい感じにテーブル構造として解釈してくれます。
{
"fileLocations": [
{
"URIs": [
"参照するS3のURI"
]
"URIPrefixes": [
"参照するS3のURI(ディレクトリで指定すると、配下を全部見て結合までする挙動のようだった)"
]
}
],
"globalUploadSettings": {
"format": "CSV",
"delimiter": ",",
"textqualifier": "'",
"containsHeader": "true"
}
}また、データに合わせて型も自動で変換してくれます。もちろん、手動で型も変更できます。(日付のデータはうまいこと解釈できないみたいだったので、csvを作成するときにGASで整形する必要がありそうでした)
アプリケーションログのように膨大なデータになってしまう場合はAthenaを咬ませて必要なデータのみを引っ張ってくる必要があるかもしれませんが、今回はそこまでのデータ量を扱わないので、S3のCSVを直接見に行く程度で差し障りないという判断をしました。
※ 去年のアドベントカレンダー(Google AnalyticsのデータをAWSのs3に保存しQuickSightに可視化)の記事でBigQueryとLambdaを用いてGAのデータを可視化する方法が紹介されていますが、GAの360であればBigQueryが使えるのですが、そうでない場合のミニマムな手法としてご理解いただけますと幸いです。
Twitter
Twitterから特定の単語を含むツイートを検索して取得することができるので、エゴサーチに使えます。 また、そのツイートのRT数、ツイートしたアカウントの作成日、フォロワー数等も細かく取れるので、どれくらい拡散したのか推定することができます。
アカウント連携が必要ですが、GUIでぽちぽち設定するだけなので、簡単です。
Slack
これは余談なのですが、毎日使うSlackに日々追うべきデータは流しています。基本的にはこれもGASでやっています。
Slackには流せる情報に限界があるので、簡単な情報のみに限り、詳しくはこちら〜〜でダッシュボードに誘導するようにしました。

これで非エンジニアでも毎日数値を追えるようになりました!
苦労した点
クエリの管理
これまでDBの可視化に用いるBIツールはRedashを使ったことがありますが、基本的に1つのビューに1つのクエリを書いていくスタイルで、このクエリって何を表示したいんだっけ。。。?となりがちです。
しかし、QuickSightだと、関連のある複数テーブルをJOINだけしてして中間テーブルを作っておけば、あとはGUIでいい感じにできます。 クエリのソース管理も中間テーブルの数しかないので、そんなに量も多くならないですし、管理は楽でした。 最初は1つのビューに1つのクエリを書いてしまっていて、管理が大変になってしまいました。
また、元のデータが同じなので、数字がずれにくくなります。 どうしてもビュー単位でクエリを書くと、何かケアレスミスをしたりして、微妙に条件が間違っていて誤差が出ておかしくない??と問い合わせを受けることがありましたが、中間テーブルだけ管理するとそういうミスも体感値ではありますがかなり減りました。
ドキュメント不足
単純にQuickSightのドキュメントが機械翻訳したようなドキュメントが多く、理解するのに時間かかりました(笑)
慣れてくればかなり楽にBIツール作れるので、AWSを使用されているのであればおすすめのBIツールです!
今後の課題
今回はデータの可視化しかできていないので、もっとデータを貯蓄した上で本格的な分析、施策に落とし込んでいけるような体制を作っていく必要があります。 そのため、単純な数学的なアプローチだけでなく、機械学習等を用いた、より質の高い分析をしていきたいと思っています。
また、全然メトリクスも足りていないので、更に様々な指標でデータを観測できるようにし、データドリブンなサービス作りを目指していこうと思います。
今後とも株式投資型クラウドファンディング、イークラウドを盛り上げていけるよう尽力して参りますので、よろしくお願いいたします。
参考
スプレッドシートでGoogleアナリティクスレポート作成を自動化する方法
GoogleスプレッドシートのデータをS3へCSVとして保存する
この記事が気に入ったらサポートをしてみませんか?