
画像生成AIまとめと「Stable Diffusion」の何がすごいのか解説【2024年版】

👋こんにちは!最近では、スマホからクオリティの高い画像が生成できたり、写真と見間違うようなリアルな画像がSNSで話題になったりするなど、2023年前期のブームから現在にかけて、画像や動画の生成AIは驚異的な速度で進化を遂げています。
画像生成AIに初めて触れる方、すでに使用してみたけれど他のサービスとどう違うのか気になっている方々に向けて、この記事では2024年1月時点の画像生成AIサービスの最新動向と、「Stable Diffusion」の特徴やできることをなるべくわかりやすくご紹介します。
創作活動やビジネスでの活用方法も探っていきますので、ご興味がある方はぜひ最後までお読みください。きっと驚きや新しい発見があると思います!記事がお役に立ったら、フォローやスキをいただけると励みになります。
■画像生成AIの現状と業界動向:
一言に画像生成AIといってもとても多くのサービスが存在していて、その全てを把握することは難しいため、ここでは代表的「基本モデル」と「派生サービス」に分けてご紹介していきます。
◇基本モデルについて
画像生成AIのアルゴリズムおよび学習元のデータの違いによって分けられます。基本的にココさえ抑えておけば、業界全体の動きは掴みやすいです。
以下に代表的なモデルの一覧と、最新トレンドで個人的に比較した評価を記載しておきます。共通のプロンプトで出力した画像も添えてみましたので併せてご覧ください(品質タグなどは最適化していません)
◆基本モデルの代表例と個人的な相対評価
- Midjourney (V6)

品質:★★★★★
価格:★★★★($11/月~)
簡易さ:★★★
機能性:★★
長所:
現行の画像生成AIで最高品質のリアル系画像を生成できる(V6)
ユーザーフレンドリーなDiscordベースのインターフェイス。
異なる芸術的スタイルへの画像の変換に長けている。
短所:
現在は有料利用のみで、ややコストが高め。
プラットフォーム内での編集オプションに制限。
不安定なアクセスやサーバーの問題が発生することがある。
- DALL-E(3)

品質:★★★
価格:★★(GPT PLUSまたは無料)
簡易さ:★★★★
機能性:★★★
長所:
ChatGPTやCopilotから利用でき、自然言語で指示するだけで生成と修正が可能
詳細なテキストプロンプトからの画像生成に優れています。
破綻が少なく、安定した品質
速い画像生成(約12秒)
短所:
画像サイズの指定が細かくできない
画像の編集や操作のオプションが限られている。
他の生成AIに比べて解像度が低い。
- Stable Diffusion(XL)

品質:★★★~
価格:無料
簡易さ:★
機能性:★★★★★
長所:
オープンソースであり、他のツールとの統合が可能。
画像出力の微調整に多くの設定とパラメータを提供。
img2img(画像→画像を再生成)など編集性に優れる。
短所:
インストールと設定に技術的な理解が必要。
画像生成はリソース集約型で、強力なハードウェアが必要。
- Adobe Firefly

品質:★★★★
価格:★★(680円/月)
簡易さ:★★★
機能性:★★★★
長所:
Adobeの幅広いクリエイティブツールとの統合
商業利用に安全。
100以上の言語でプロンプトをサポートし、多言語ウェブサイトにも対応
短所:
機能の種類は一般的
モデルの自由度は他の生成モデルに比べて狭い
◇派生サービスについて
基本モデルのAPIやオープンソースのソースコードを利用してユーザーが使いやすくアレンジしたものや「チェックポイント」と呼ばれる学習データを利用してサービスに独自性を出しているものがあります。
◆派生サービスの代表例(カッコ内は基本モデル)
- Niji journey (Midjourney)
- Novel AI (Stable Diffusion)
- Craiyon (DALL-E)
- Leonardo AI (Stable Diffusion)
- ちちぷい画像生成 (Stable Diffusion)
他多数
■Stable Diffusionの特徴
前置きが長くなりましたが、ここからが本題です。
Stable Diffusionの最大の特徴はカスタマイズ性に優れている点です。
ちなみにどれぐらいカスタム可能かというと、画像生成のコントロールや画像の編集の面ではできないことを探す方が難しいぐらいなんでもできます。
品質については上のリストでは★3~としましたが、その理由は個人的なカスタマイズによって上下が激しいためです。
チェックポイントや追加学習データなどの利用によって品質の振れ幅が変わります。
個人的な感覚では、Stable DiffusionXLの性能がフルに生かせたとしたらMidjourney V6にも匹敵するとは思います。
Stable DiffusionはWeb UIやComfy UIと言われるローカル環境への実装またはGoogle Colab上で動かす方法があります。
動作環境や実装方法については検索すれば分かりやすく説明している記事がたくさん見つかるかと思いますのでここでは割愛しますが、実装自体は手順に沿って行えばそれほど難しいものではありませんし30分以内ぐらいで初回起動できると思います。
◇Stable Diffusion web UIの基本機能でできること
テキストから画像を生成する
画像から画像を生成する
テキストと画像から画像を生成する
画像の一部だけを指定して(加筆も可)再生成する
出力した画像をアップスケール(高解像度化)する
出力した画像をダウンスケール(低解像度化)する
2~3つの学習モデル(checkpoint)をマージ(統合)する
入力画像からメタデータを取得
追加学習データ(LORAやEmbeddings等)を利用する
追加可能な拡張データをリストアップしてインストールする
◇オプション(拡張)機能でできること
出力画像のポーズ指定と編集
入力画像の人物からポーズを抽出
入力画像を線画データに抽出
入力画像を画像認識してプロンプトを抽出
画像にディティールを追加
入力画像の構図や特徴を参照して出力画像に影響を与える
入力画像のキャラクターの特徴を参照して出力画像に影響を与える
追加学習データ(LORA)を作成する
線画に着彩(色塗り)する
テキストや画像から動画を作成する
その他に数百種類以上ある拡張データを利用して機能をどんどん増やしていくことができます。ユーザーはニーズに応じて必要な拡張データを増やしていってどんどん利便性を追求していくことが可能です。
そのためここには挙げ切れないぐらいの多様な機能が揃っていますし、開発者によって日々新しい機能が追加され更新され続けています。
つまり、Stable Diffusionが使えるということは画像作成や編集に関するあらゆるニーズに応えることができると言えます。
もちろんまだ新しい技術で完璧ではないかもしれませんが、とてつもない速度で進歩していっていますので現時点でも始めるのに遅いということはありません。
(2週間前のトレンドはすでに古い情報という感覚です。。。)
■使い方と実践例
ここでは、具体的な例を交えてStable Diffusion web UIの様々な機能を使ってどのようにイラスト制作のタスクを進めていくかご紹介します。細かい設定方法や、クオリティを上げる方法については長くなってしまうため今回は割愛させていただきます。(もしご要望がありましたらコメントなどでご連絡下されば幸いです)
今回は「アニメ風のイラストで公園で元気に走る犬を白黒線画で描き起こしてから、着色して高画質化した後に細かい部分を修正する」というオーダーがあったと仮定して進めていきましょう。
◇画像からプロンプトを抽出して生成
いきなりですが、今回はベースとなる部分のプロンプトを自分で作成するのではなく画像認識機能を使って取得してみます。まず、アニメ風の犬の画像を用意します。

※直接画像を二次利用するわけではありません
この画像からプロンプトを抽出する拡張機能を使用します。

(翻訳:犬、人間がいない、ランニング、黒い背景、目を閉じて、動物フォーカス、シンプルな背景、舌、^_^、ソロ、横から、舌を出した、笑顔、口を開ける、動物、ハッピー、全身、赤面)
この画像に含まれる要素を解析してプロンプト化してくれました。
プロンプトから画像生成するAIなので当然と言えば当然なのですが、AIがかなり正確に画像の要素を認識できていることがわかります。
ここから不要な要素を減らし、アニメ風、背景、白黒の線画にするプロンプトを追加して生成してみます。
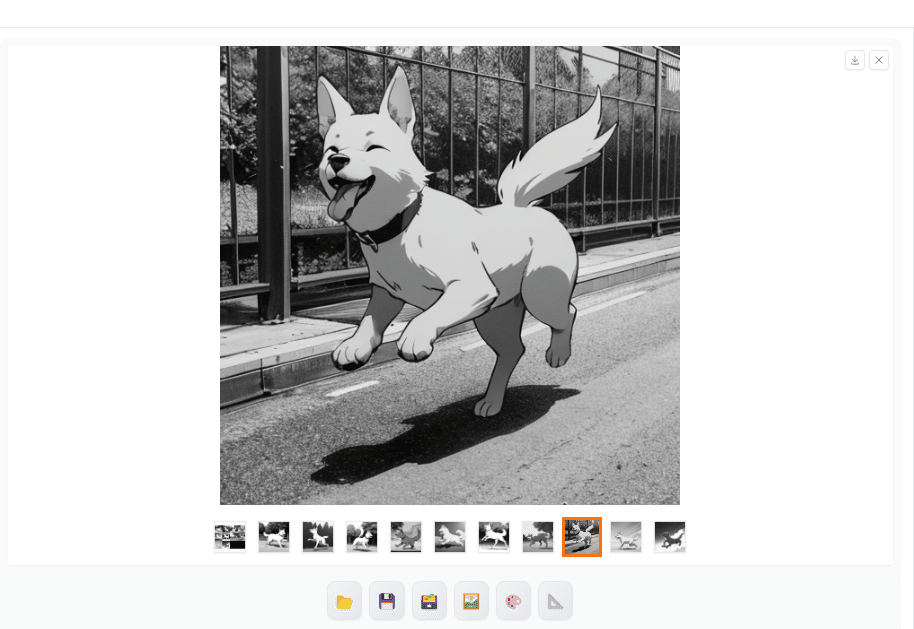
何枚か生成してみるとそれっぽい画像が出てくれました。
プロンプトを調整することでもっとリアルな感じにしたり、逆にデフォルメしたりすることもできます。
◇画像に着彩する
先ほど出力した白黒ワンちゃんの画像をimg2imgに移動して色塗りをしていきます。ここでは、拡張機能で線画データや奥行きのデータを抽出した上で固定して、プロンプトによって再生成するといった流れで着彩していきます。

色の指定は確実に反映してくれるわけではないのでプロンプトを指定した上で何度か試してみる必要はありますが、かなりきれいに塗り分けてくれています。
これらの機能を使えばイラストの制作工程で「着彩のみ」をAIに任せることもできるため、とても効率が良くなりますね。(画像の一部だけ色付けすることも可能です)
漫画のカラー化などにも使える機能だと思います。
◇アップスケールする(高解像度化)
この画像は512×512サイズで生成しているため、少し低画質になっています。大きなサイズにアップスケールして品質を上げてみます。
Stable Diffusionにはプリセットとして複数のアップスケーラーが用意されていますので、それらを使用しても問題なく綺麗になりますが、アップスケーラーを追加することもできます。
今回は、アップスケールに適した拡張機能を使ってimg2imgで2.5倍のサイズに高画質化してみます。

サイズが大きくなっただけでなく細かい補完や修正が施されています。
◇部分的に修正する
人物のイラストの場合は手の崩れが良く起こるのでそこだけ直すという工程がよく発生します。AIが得意としている分野の修正はすんなりいくことが多いのですが、手脚、指に関しては元々苦手なので、部分修正でもかなり失敗率が上がります。
手を修正するのに特化した拡張機能もいくつか存在しますが、それでも確実というわけではありません。(2024年中には解消されそうですが)
今回は、画面の手前に石を配置するように修正してみます。

プロンプトを調整して石があることを強調します。
再出力すると大きめの石が生成できました。これでタスクは完了となりますが、所要時間は合計で5分ほどです。

◇使い方まとめ
Stable Diffusionの機能を使ってテーマに沿った画像を生成し、編集する流れをご紹介しました。それぞれの編集機能に特化したAIサービスは多々ありますが、オールインワンかつ無料で無制限に利用ができることがStable Diffusionの魅力になります。しかも今後も機能改善、拡張されていくことが期待されます。
ここでご紹介した機能は、代表的な基本機能と拡張機能に限られますが、他にも様々な方法で画像や動画を作成したり編集したりすることができます。
直接イラストに関係する仕事ではない方でも、商用利用が認められたモデルを使ってプレゼン資料に活用したりもできるので、アイデア次第で活用の幅は広がっていくと思います。
■著作権と倫理的考慮
画像生成AIを使用する際、著作権や倫理的な問題は無視できません。
現状は、日本国内でも生成AIの学習や利用に関連する法整備が議論されています。
生成AIは非常に強力なツールであるがゆえに誤った使い方をすることで様々な問題の種にもなっていることも事実です。
特にStable Diffusionに関しては意図的に著作物をトレースすることも技術的に可能です。(img2imgやcontrol netの悪用など)
制作者から商用利用を認められたモデルであっても、著作権や肖像権、その他の権利を侵害しないように配慮する必要があります。
■画像生成AIの現在地と今後
ここまで、画像生成AIの優れた点についてご紹介してきました。
しかしこの記事を作成している時点では、あらゆる機能を使ったとしてもまだ破綻が多かったり、思った通りに行かない場合があったりと、プロフェッショナルな仕事と比べると一部不完全なところは否めません。
つまり作業をサポートする強力なツールという見方が一般的だと思います。
今後は、今より高画質化していくことは当然の流れとして、一貫性を保持できる機能が追加されることで同一のキャラクターや世界観、作風で連続した作品が作れるようになっていくことが予想されます。
破綻が少なく、一貫性が保持できるようになると漫画やショートムービーが作れたりするので、いよいよフルAIの商用作品が一般的になってきそうです。
いずれにしても、今後も動画や画像生成AIはトレンドとして注目されつづけると思いますので、ご興味のある方は一度触ってみてはいかがでしょうか。
■AIBridge Labについて
AIBridge Lab(エーアイブリッジ ラボ)では企業向けに生成AI(画像生成やLLM)の利用方法や導入方法に関して無料でご相談を受け付けております。
以下のメールアドレスまでお気軽にお問い合わせください。
ai_business@doerstokyo.jp
AIBridge Lab こば
皆さまの温かいサポートのおかげで、活動を続けることができています。もしよろしければ、引き続き支援をお願いできますと幸いです。より質の高い記事投稿に励みます!