【AI×読書】 読書アシスタント入門

はじめに
本記事は,拙訳「グラフ深層学習」の読者向けに用意した「読書アシスタント機能」の紹介とその使用例をまとめています.
本サービスは仕組み的に人文系の書籍などに対しても転用可能です(ご相談ください).
本書について
読書アシスタントとは
私自身理解が遅い人なので,最近は「本を読んでいく中で躓いたところをチャットAIに聞く」スタイルをとっています.
具体的には「本の内容(文章の一部)」と「質問」をプロンプトに入力し,そこからの返答を足がかりに学び進めています.
このような経験から「読んでいる本の知識(本の内容)が予めインプットされていれば質問だけで済むだろうな」と考えました.
そこで実験的な試みとして,出版に携わった本に読書アシスタント機能を取り入れてみました.
本サービスは「本の内容について直接質問し,その答えを受ける」ことが可能になっています.
つまり,近くに著者(先生)がいて,疑問やわからないところをいろんな形で教えてくれる,そんな読書体験を提供するサービスとなっています.
アクセスはこちら
Webまたはスマートフォンアプリで起動できます.
スマートフォンアプリ(ChatGPT)のダウンロードはこちら:
AppStore / Google Play
使用にあたっての注意事項
ChatGPT Plusのアカウントが必要になります
使用制限(時間あたりのクエリ回数)があるのでご注意ください
本アシスタントは間違いを犯すことがあります.自身が持つ知識領域と縫い合わせながらご活用ください
サービス元の仕様変更等により,予告なく本アプリケーションの提供を変更したり,取りやめる場合がございます.ご了承ください
質問・回答集
本サービスの雰囲気を知っていただくために,「質問とその応答」についてまとめました.
注意:同じプロンプトでも,必ずし本記事のような回答が返ってくるとは限りません.
数式の説明
本書の式にはほとんど式番号を振っていますので,式番号を指定した質問が可能です.
■ 質問(プロンプト)
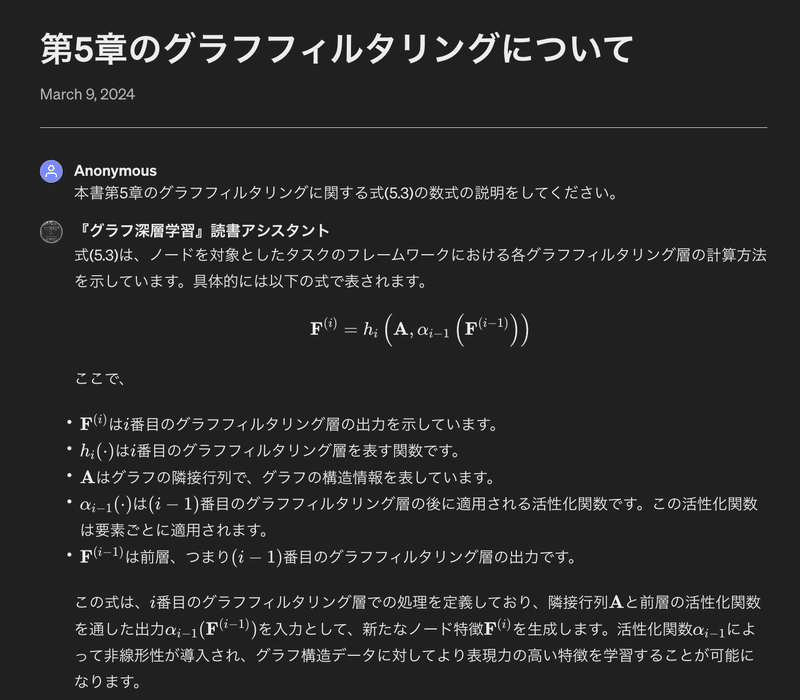
本書第5章のグラフフィルタリングに関する式(5.3)の数式の説明をしてください。
■ 回答
■ 回答リンク(全文)
追加質問しています.文脈を踏まえた上での回答が返ってきます.
定義をわかりやすく説明
「わかりやすさ」は人によって異なります.
「まずは直感的に理解したい」という方には平易な言葉で説明してもらった方がありがたいと思います.
■ 質問(プロンプト)
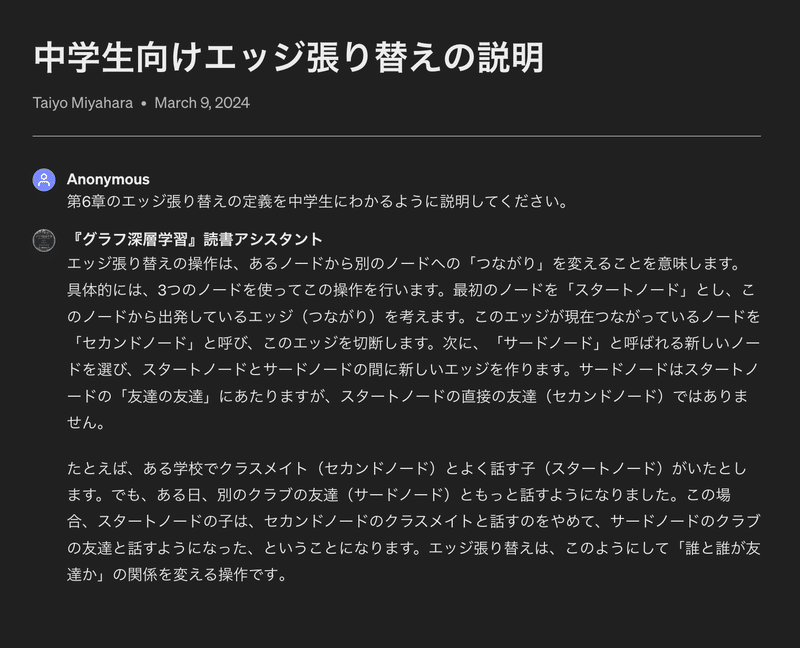
第6章のエッジ張り替えの定義を中学生にわかるように説明してください。
■ 回答
■ 回答リンク(全文)
追加質問しています.
「直感的な説明→数式的な説明」の流れで理解できるかと思います.
論文・文献情報の問い合わせ
文献情報も読み込ませているので,本書に出てきた参考文献に簡単にアクセスできます.
■ 質問(プロンプト)
5.3節にある論文Kipf and Welling (2016a)のURLをください.
■ 回答

■回答リンク(全文)
論文の内容については知識は持たせていないので限界があるかと思います.
なお,論文のPDFをアップロードしての解析には対応していません.
他の要約GPTsなどと併用すると良いでしょう.
(現在機能をオフにしていますが,要望あれば制限解除します)
Pythonコードによる実装
本書の内容をpythonコード化してくれます.
■ 質問(プロンプト)
第2章のKatz中心性をpythonコードで記述してください。
グラフの例は例2.3にある隣接行列を使ってください.
■ 回答

■ コードのみ抜粋
※ alpha = 1/5 とすると本書で述べられている計算例と一致します.
import numpy as np
# 例2.3の隣接行列
A = np.array([
[0, 1, 0, 1, 1],
[1, 0, 1, 0, 0],
[0, 1, 0, 0, 1],
[1, 0, 0, 0, 1],
[1, 0, 1, 1, 0]
])
# Katz中心性のパラメータ
alpha = 0.1
beta = 1
# 単位行列
I = np.eye(A.shape[0])
# Katz中心性の計算
c_k = np.linalg.inv(I - alpha * A) @ (beta * np.ones(A.shape[0]))
print("Katz中心性スコア:")
print(c_k)■回答リンク(全文)
追加でnetworkx(pythonライブラリ)による実装もお願いしています.
数式→Python疑似コード化
エンジニアにとっては「数式よりコードを示してくれたほうがわかりやすい」かもしれませんね.
擬似コード化することで処理の流れを理解する取っ掛かりとなります.
■ 質問(プロンプト)
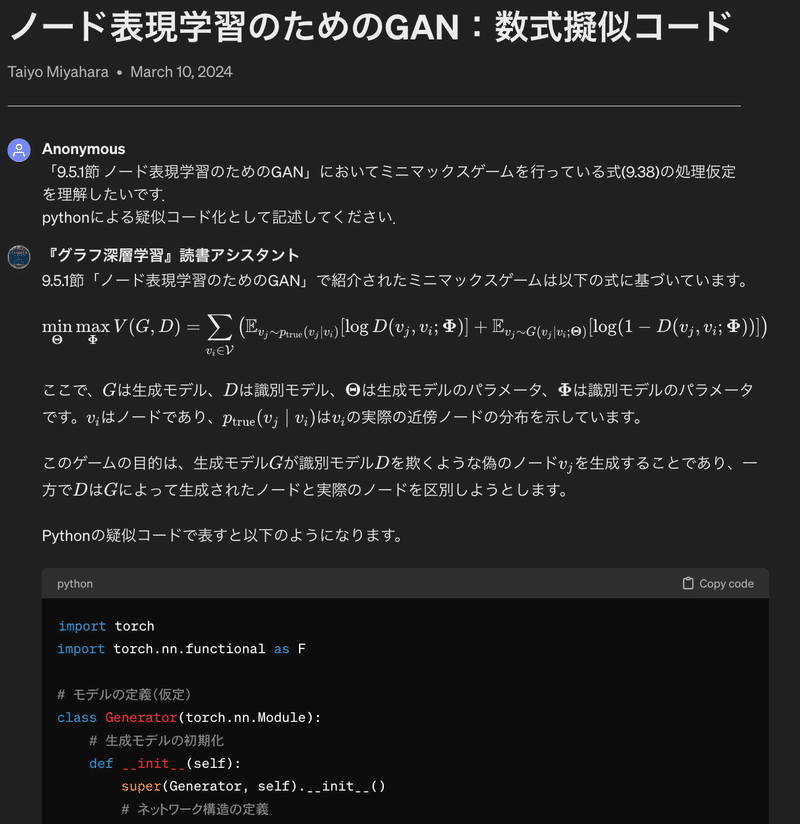
「9.5.1節 ノード表現学習のためのGAN」においてミニマックスゲームを行っている式(9.38)の処理過程を理解したいです.
pythonによる疑似コード化として記述してください.
■ 回答
■回答リンク(全文)
Pytorchによる実装が返ってきます.
全体のコードは以下のリンク先でご確認ください.
コードを通して数式が理解できるきっかけになるのではと思います.
さらにパラメータの詳細など細かく指定すればもっと具体的なコードへと仕上げてくれると思います.
将来的に,「論文上のモデルの数式 + 自分が持っている前処理後のデータ」からモデル開発が容易になりますね.
※実は式(9.38)の定義が微妙に本文と異なっています.ここらへんはモデル側の改善に期待したいです.
誤植情報の表示
現時点での誤植情報を入れているので答えてくれます.
■ 質問(プロンプト)
現時点での誤植情報をおしえてください。
■ 回答

■回答リンク(全文)
誤植をみつけたら「誤植を見つけたのですが,どこにどのように送ればいいですか?」とすると案内してもらえます.
使用上の注意
該当箇所を提示する
本書は章だけでなく,全ての節にも節番号を振っています.
本アシスタントが質問の言及箇所にアクセスしやすいように「第◯◯章」や「第◯.◯節」と丁寧に入れてあげてください.
それでも拾ってこれない場合,周辺ワードを追加してあげると良いでしょう.
周辺ワードを追記する
いろんな式が続いている文章では「式(9.12)〜〜」とだけ指定しても,その前後にある見当違いの式を拾ってきてしまう場合があります.
そこで,式についての質問は「グラフサンプリングの不偏性に関する式(9.12)〜〜」といった形で具体性をもたせると良いです.
章またぎは新スレッドで
前の入力を踏まえてくれるのはありがたいですが,章をまたぐ質問をする場合,言及箇所をうまく拾ってくれないことがあります.
(例:一度4章の質問をして,その後に12章の質問をする)
その場合は,新規スレッドを立てて改めて質問してあげるとうまくいく場合がございます.
上記の他でも何か不具合があったら,クエリ数を無駄にしないためにも,ひとまず「新スレッドの立ち上げ」や「質問文の具体化」を検討した方がいいでしょう.
ちなみにエラーの中で「言及箇所が見つかりませんでした(本当は記載があるのに・・・)」というのが最も多いです.
通常のチャットAIを併用して使う
本書を超えた知識については,出力結果をコピペして他のチャットAIで展開して質問するのも手です.
例1)論文のURLを本アシスタントでとってきて,リンク先で得た論文PDFを通常チャットに投げて要約してもらう.
対応していないこと
本アシスタントは以下の質問等に対応していません.
要望等ございましたらお問い合わせください.
図表(figureやtable)への質問
これらのデータを持たせていません.
未対応の質問例:図5.2の◯◯って何を意味していますか?
ページ番号に関する質問
テキストデータで入れているのでページ情報を保持していません.
未対応の質問例:p.254にある◯◯について説明してください.
ファイルのアップロード・解析
論文PDFなどをアップロードして読み込ませることはできません.
他のGPTsと併用しながら使用することがおすすめします.
正直この辺りは「参考文献を取得→論文をアプロードして要約させる」など需要は高いと思っており,要望あればオンにすることを検討します.
コード実行やファイル出力
プログラミングコードの実行,Jupyter Notebook形式で出力等はサポートしていません(Code Interpreter機能をオフにしているため).
Web検索
「本書の解説という役割から逸脱しない」という設計思想から,検索機能(Web Browsing)をオフにしています.
「◯◯技術の最新の進展について教えて」などには答えられません.
知りたい方向け:本アシスタントの保有情報
本アシスタントはOpenAI提供の「GPT Builder」で作成されています.
プロンプトエンジニアリングの観点から,「どのようなデータをどのような形式で入れているのか」を公開した方が良いと考えたので一部公開します.
質問の仕方や聞き方の参考にしてくれると幸いです.
設定内容(全体)
入力ファイルの構造
入力データはおおまかに「本文」,「参考文献」,「誤植」の3種類に分かれています.
本文情報(txt形式:15ファイル)
tex形式(数式の記述に特化したMicrosoft Word的な形式)で書いたファイルを,数式を含めてマークダウンに変換して載せています.
1章ずつ入れています.「第◯章の◯.◯節」と指定したほうが返答精度が良いのはそのためです.
データの内容(『第5章.txt』の冒頭一部)
# 5章 グラフニューラルネットワーク
## 5.1節 はじめに
**グラフニューラルネットワーク(GNN)**は,グラフ構造を持つデータに対して深層ニューラルネットワークを適用するものである.
グラフは一定のパターンを持つ構造ではないため,従来の深層ニューラルネットワークをグラフ構造を持つデータに一般化することは容易ではない.
グラフニューラルネットワークの研究は,21世紀初頭に最初のGNNモデル(Scarselli et al., 2005, 2008)が提案されたことが始まりとされる.
そこではノードおよびグラフを対象としたタスクの両方に対してGNNが提案された.
深層学習技術が画像処理や自然言語処理などの幅広い分野で大きな人気を博すようになると,多くの研究者はこの研究分野に力を注ぐようになった.
グラフニューラルネットワークは,グラフの特徴量学習の一過程として捉えることができる.
ノードを対象としたタスクでは,GNNは各ノードの優れた特徴を学習し,タスクの実行を容易にすることを目標にしている.
グラフを対象としたタスクでは,GNNはグラフ全体を代表する特徴を学習することを目標としており,このタスクにおいてはノードの特徴の学習は,グラフ全体を学習するための中間的なステップとなる.
ノードの特徴を学習する過程では,入力ノードの特徴とグラフ構造の両方を活用することが多い.
具体的にこのプロセスは,以下のようにまとめることができる:
\[
式(5.1) 5.1式 式5.1
\mathbf{F}^{(\mathrm{of})}=h\left(\mathbf{A}, \mathbf{F}^{(\mathrm{if})}\right) \]
ここで, \(\mathbf{A} \in \mathbb{R}^{N \times N}\) は(グラフの構造に相当する)ノード数 \(N\) 個のグラフの隣接行列を表し,
\(\mathbf{F}^{(\text{if})} \in \mathbb{R}^{N \times d_{\mathrm{if}}}\) と \(\mathbf{F}^{(\text{of})} \in \mathbb{R}^{N \times d_{\text {of}}}\) は,
それぞれ入力特徴量行列(入力表現行列)と出力特徴量行列(出力表現行列)を表す.
...参考文献のデータ(html形式:15ファイル)
サポートページのhtmlファイルを不必要部分(css周り)を除いた上で載せています.
データの内容(『参考文献_論文_書籍.html』の冒頭一部)
<table>
<thead>
<tr style="text-align: right;">
<th>タイトル</th>
<th>著者名</th>
<th>年</th>
<th>リンク</th>
</tr>
</thead>
<tbody>
<tr>
<td>TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems</td>
<td>Abadi, Martín, Agarwal, Ashish, Barham, Paul, Brevdo, Eugene, Chen, Zhifeng, et al</td>
<td>2015</td>
<td><a href="https://arxiv.org/abs/1603.04467" target="_blank">arxiv</a></td>
</tr>
<tr>
<td>Friends and neighbors on the Web</td>
<td>Adamic, Lada A, and Adar, Eytan</td>
<td>2003</td>
<td><a href="https://www.sciencedirect.com/science/article/abs/pii/S0378873303000091?via%3Dihub" target="_blank">リンク</a></td>
</tr>
...誤植情報(html形式:1ファイル)
サポートページのhtmlファイルを不必要部分(css周り)を除いた上で載せています.
データの内容(『誤植・修正情報.html』の冒頭一部)
<html lang="ja">
<body>
<h2>誤植・修正情報</h2>
日本語訳にあたっては,最大限の努力をもって取り組んでおりますが,誤植や不正確な訳などが残っている可能性もございます.
<br>
現在判っている誤植・修正箇所は以下の通りです.
<br>
他にも誤植等ございましたら下記までお問い合わせください:<br>
<a href="mailto:deeplearning.on.graphs@gmail.com?subject=誤植報告&body=「グラフ深層学習」担当者%0D%0A%0D%0A■ページ番号:p.◯◯%0D%0A■誤:%0D%0A✗✗✗✗✗✗%0D%0A%0D%0A■正(わかれば):%0D%0A◯◯◯◯◯%0D%0A%0D%0A■備考:%0D%0A特になし%0D%0A%0D%0A※訳者より%0D%0Aこの度はご迷惑をおかけしてすみません.ご協力誠にありがとうございます!%0D%0A本メールへの返信はいたしませんのでご了承ください.内容を吟味し次版への対応を検討いたします.">deeplearning.on.graphs@gmail.com</a>
<h3>1刷〜</h3>
<table>
<thead>
<tr>
<th>ページ</th><th>該当節</th><th>誤</th><th>正</th><th>備考</th>
</tr>
</thead>
<tbody>
<tr>
<td>p.8</td><td>1.4節</td><td>責任者にとっても有用であろう..</td><td>責任者にとっても有用であろう.</td><td>誤植</td>
</tr>
...おわりに
まだ返答精度は高いとはいえません.
それは今後の技術進展に期待したいところです.
どういった使い方がされるのか私自身よくわかっていないですが,次世代型の読書体験につながる小さなきっかけになると良いなと考えています.
人文系の本に対しても有効なので,試してみたい方は是非ご相談ください.
繰り返しになりますが,本モデルは虚偽の生成を行うことがあります(幻覚: Hallucination).
生成結果を十分に吟味しながらご利用ください!𓃰
おまけ
今後「プルリク的な機能(ユーザFBによる知識更新)」があるといいなと思っています:
ユーザの使用履歴解析により「よくある質問」がレポートとして受け取れる.
使用履歴自体にはアクセスできないが,それらを要約したものが与えられるという状況(「LLM Analytics」的なサービス)
本の著者がそれら「よくある質問」に対して(テキストやPDFの形で)答えを示し,そのデータを追加的にアシスタントに学習させる
多くの読者が躓くであろう箇所に対して救済の手を差し伸べられる.
GPTsには「収益化」の予定があるそうです.
技術者や人文系の研究者なども(書籍に限らず)こうした知識を共有し,それにアクセスする人に応じた収益が分配される仕組み化が進めば,知的活動と収益が結びつくことになります.
LLM関連企業にとって「専門的で質が高い情報(知識)」は垂涎の的でしょうから,収益化を浸透させて知識提供者を囲う(例えば出版社を介さなくなる)可能性があります.
このように多方面の知識共有が進めば,次世代の検索(LLMベースの検索エンジン)は仮想的に「文書(Page)ベースから人(Person)ベース」に変わるかもしれません(PersonRankというワードは物騒ですね).
知識と人が接続すると,ネット上の情報源信頼性の問題は「知識提供者を辿る(その知識をどのコミュニティが言っているか)」ことで解消に向かうように思えます.
この記事が気に入ったらサポートをしてみませんか?