【DLAI×LangChain講座2③】

背景
DeepLearning.aiのLangChain講座(LangChain for LLM Application Development)を受講し、講座で学んだ内容やおまけで試した内容をまとめました。
現在は、第2弾(LangChain Chat with Your Data)の内容を同様にまとめていきます。
第3回は、VectorStoreとEmbeddingsです。
この講座では、PyPDFLoaderでPDFを読み込み、RecursiveCharacterTextSplitterで分割した後にOpenAIのEmbeddingモデルを使ってベクトルを生成、Chromaに格納しています。
LangChainでは、他にも様々なVectorStoreがあります。
OSS: FAISS、Annoy、DocArray
Cloud: AWS OpenSearch、Azure AI Search、BigQuery
ドキュメントで、さらに多くのVectorStoreが確認できます。
またこちらのサイトでは、様々なVectorStoreの比較表を提供しています。
LangChainを使う場合は、これらのページが適切なVectorStoreの決定を助けてくれそうです。
アプローチ
DeepLearning.aiのLangChain講座2の3の内容をまとめます。
サンプル
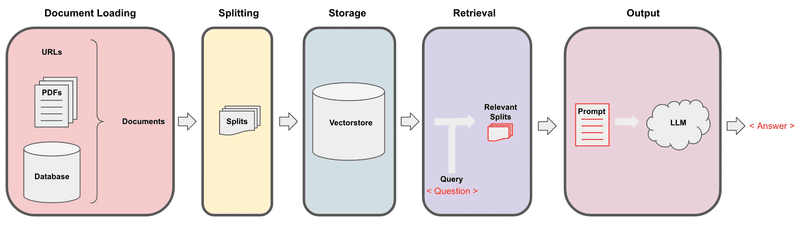
Recall the overall workflow for retrieval augmented generation (RAG):
import os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']We just discussed `Document Loading` and `Splitting`.
前回までに出てきたPyPDFLoaderとRecursiveCharacterTextSplitterを使って上図のSplits(テキストチャンク)を作成します。
from langchain.document_loaders import PyPDFLoader
# Load PDF
loaders = [
# Duplicate documents on purpose - messy data
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture02.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture03.pdf")
]
docs = []
for loader in loaders:
docs.extend(loader.load())# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 150
)splits = text_splitter.split_documents(docs)len(splits)209
Embeddings
Let's take our splits and embed them.
次にOpenAIのEmbeddingモデルを使って埋め込みを行います。Embedは「埋め込む」という意味で、ある高次元空間上のデータを別の低次元空間に”埋め込む”ことを指しています。
from langchain_openai import OpenAIEmbeddings
embedding = OpenAIEmbeddings()sentence1 = "i like dogs"
sentence2 = "i like canines"
sentence3 = "the weather is ugly outside"embedding1 = embedding.embed_query(sentence1)
embedding2 = embedding.embed_query(sentence2)
embedding3 = embedding.embed_query(sentence3)下記の操作で内積をとっています。
np.dot(embedding1, embedding2)0.9630350414845892np.dot(embedding1, embedding3)0.7701147991091337np.dot(embedding2, embedding3)0.75911300001771291と2の文の類似度が高く、3は類似度は低くなっていますね。
これだけでは判断できませんが、このEmbeddingは、言語や文章の形式によっても影響を受けます。そのため、テキストチャンク作成時に、言語や文章の形式を揃えることも必要な場合があります。
Vectorstores
次に、Chromaに格納していきます。
# ! pip install chromadbfrom langchain.vectorstores import Chromapersist_directory = 'docs/chroma/'!rm -rf ./docs/chroma # remove old database files if anyvectordb = Chroma.from_documents(
documents=splits,
embedding=embedding,
persist_directory=persist_directory
)print(vectordb._collection.count())209Document型やstring型のデータとEmbeddingモデルを渡すだけで格納されます。(string型の場合はfrom_texts())
Similarity Search
Chromaで類似度検索を行ってみます。
question = "is there an email i can ask for help"docs = vectordb.similarity_search(question,k=3)len(docs)3docs[0].page_content"cs229-qa@cs.stanford.edu. This goes to an acc ount that's read by all the TAs and me. So \nrather than sending us email individually, if you send email to this account, it will \nactually let us get back to you maximally quickly with answers to your questions. \nIf you're asking questions about homework probl ems, please say in the subject line which \nassignment and which question the email refers to, since that will also help us to route \nyour question to the appropriate TA or to me appropriately and get the response back to \nyou quickly. \nLet's see. Skipping ahead — let's see — for homework, one midterm, one open and term \nproject. Notice on the honor code. So one thi ng that I think will help you to succeed and \ndo well in this class and even help you to enjoy this cla ss more is if you form a study \ngroup. \nSo start looking around where you' re sitting now or at the end of class today, mingle a \nlittle bit and get to know your classmates. I strongly encourage you to form study groups \nand sort of have a group of people to study with and have a group of your fellow students \nto talk over these concepts with. You can also post on the class news group if you want to \nuse that to try to form a study group. \nBut some of the problems sets in this cla ss are reasonably difficult. People that have \ntaken the class before may tell you they were very difficult. And just I bet it would be \nmore fun for you, and you'd probably have a be tter learning experience if you form a"ちゃんと問い合わせができるEmailアドレスが書かれていますね。
Let's save this so we can use it later!
vectordb.persist()Failure modes
This seems great, and basic similarity search will get you 80% of the way there very easily.
But there are some failure modes that can creep up.
Here are some edge cases that can arise - we'll fix them in the next class.
基本的な類似度検索では、8割方うまくいきます。しかし、うまくいかない例もあり、その紹介をしています。
question = "what did they say about matlab?"docs = vectordb.similarity_search(question,k=5)Notice that we're getting duplicate chunks (because of the duplicate `MachineLearning-Lecture01.pdf` in the index). Semantic search fetches all similar documents, but does not enforce diversity. `docs[0]` and `docs[1]` are indentical.
ここで課題としているのは、テキストチャンクの重複です。Document Loadingの部分をよく見ると、Lecture01のPDFをわざと2つ書かれています。このような重複は、検索結果の品質、それをもとに生成する応答の品質の悪化を招きます。
この例は、単純なミスで全く同じテキストチャンクが存在する場合ですが、実際のプロジェクトでは、類似のテキストチャンクが異なるドキュメントから得られることも多くあります。そのため、重複・類似したテキストチャンクを統廃合するような仕組みも必要です。
docs[0]Document(page_content='those homeworks will be done in either MATLA B or in Octave, which is sort of — I \nknow some people call it a free ve rsion of MATLAB, which it sort of is, sort of isn\'t. \nSo I guess for those of you that haven\'t s een MATLAB before, and I know most of you \nhave, MATLAB is I guess part of the programming language that makes it very easy to write codes using matrices, to write code for numerical routines, to move data around, to \nplot data. And it\'s sort of an extremely easy to learn tool to use for implementing a lot of \nlearning algorithms. \nAnd in case some of you want to work on your own home computer or something if you \ndon\'t have a MATLAB license, for the purposes of this class, there\'s also — [inaudible] \nwrite that down [inaudible] MATLAB — there\' s also a software package called Octave \nthat you can download for free off the Internet. And it has somewhat fewer features than MATLAB, but it\'s free, and for the purposes of this class, it will work for just about \neverything. \nSo actually I, well, so yeah, just a side comment for those of you that haven\'t seen \nMATLAB before I guess, once a colleague of mine at a different university, not at \nStanford, actually teaches another machine l earning course. He\'s taught it for many years. \nSo one day, he was in his office, and an old student of his from, lik e, ten years ago came \ninto his office and he said, "Oh, professo r, professor, thank you so much for your', metadata={'page': 8, 'source': 'docs/cs229_lectures/MachineLearning-Lecture01.pdf'})docs[1]{全く同じDocument}We can see a new failure mode.
The question below asks a question about the third lecture, but includes results from other lectures as well.
次の例は、単純なベクトル検索の限界についてです。下記の質問では、3つ目の講義について聞いていますが、単純なベクトル類似度検索では、他の講義のテキストチャンクも引っかかっています。これも有益でないテキストがプロンプトに入ることになるため、応答品質の悪化につながる可能性があります。
これに対しては、通常のフィルター検索と組み合わせることで、回避する方法もあります。この例では、メタデータに講義の回数を入れておき、質問をLLMに入力し、Function Callingなどでフィルター条件を出力させることで回避できそうです。
今回の例では、各講義で一つのテーマを説明しているため簡単ですが、実際のプロジェクトでは、有益な情報が異なるドキュメントに分散していることもあるため単純にフィルターできないこともありあます。しかし、関連のない複数のテキストチャンクがプロンプトに入ると、ハルシネーションの原因になる場合もあります。
例えば、「・・・日本の首都は東京である。・・・」とチャンクと「・・・では過疎化が進んでおり、」というチャンクがプロンプトに入ると、「東京は過疎化は進んでいます。」と応答される可能性があります。
question = "what did they say about regression in the third lecture?"docs = vectordb.similarity_search(question,k=5)for doc in docs:
print(doc.metadata){'page': 0, 'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf'}
{'page': 2, 'source': 'docs/cs229_lectures/MachineLearning-Lecture02.pdf'}
{'page': 14, 'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf'}
{'page': 6, 'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf'}
{'page': 8, 'source': 'docs/cs229_lectures/MachineLearning-Lecture01.pdf'}print(docs[4].page_content)into his office and he said, "Oh, professo r, professor, thank you so much for your machine learning class. I learned so much from it. There's this stuff that I learned in your class, and I now use every day. And it's help ed me make lots of money, and here's a picture of my big house." So my friend was very excited. He said, "W ow. That's great. I'm glad to hear this machine learning stuff was actually useful. So what was it that you learned? Was it logistic regression? Was it the PCA? Was it the data ne tworks? What was it that you learned that was so helpful?" And the student said, "Oh, it was the MATLAB." So for those of you that don't know MATLAB yet, I hope you do learn it. It's not hard, and we'll actually have a short MATLAB tutori al in one of the discussion sections for those of you that don't know it. Okay. The very last piece of logistical th ing is the discussion s ections. So discussion sections will be taught by the TAs, and atte ndance at discussion sections is optional, although they'll also be recorded and televi sed. And we'll use the discussion sections mainly for two things. For the next two or th ree weeks, we'll use the discussion sections to go over the prerequisites to this class or if some of you haven't seen probability or statistics for a while or maybe algebra, we'll go over those in the discussion sections as a refresher for those of you that want one.Approaches discussed in the next lecture can be used to address both!
まとめ
DeepLearning.aiのLangChain講座2の3の内容をまとめました。
今回は、テキストチャンクをEmbeddingモデルによってベクトル化、VectorStoreに格納した上で、質問文に対して類似度検索で関連チャンクを検索する、といった内容でした。
取り組み中のプロジェクトでは、取扱説明書の他にも様々なドキュメントを取り込んでいます。今回扱っている講義のテキストのように高品質なドキュメントを用意できない場合は、単純なチャンク分割、類似度検索では精度に問題が出ることが多くあります。そのため、個々のチャンクを高品質化する工夫や、検索結果が応答生成する上で高品質化する工夫が必要になります。
それでも、LangChainのおかげで、EmbeddingモデルやVectorStoreの変更が非常に容易になっています。このようなプロジェクトごとの違いがない部分について抽象化されていることは、プロジェクトごとの課題に集中するためにありがたいですね。
読んでいただきありがとうございます。
参考
サンプルコード
この記事が気に入ったらサポートをしてみませんか?