【DLAI×LangChain講座2①】

背景
DeepLearning.aiのLangChain講座(LangChain for LLM Application Development)を受講し、講座で学んだ内容やおまけで試した内容をまとめました。
上の記事を書いている間に第2弾(LangChain Chat with Your Data)が出ていました!今回からは、この内容を同様にまとめていきたいと思います。
と思っていたら3ヶ月経っていました。その間に第3弾も出てしまった。追いつくために「おまけ」はスキップで行こうと思います。
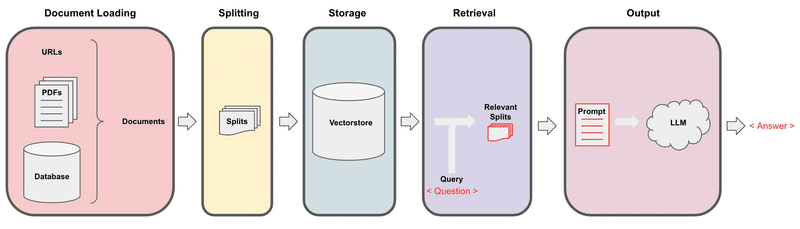
第1回は、様々なソースからのドキュメントの読み込み方法です。
この講座では、以下のソースからの読み込み方法が示されています。こんなに色々なソースから読み込めるとは、すごいですね。。
PDFs
Youtube
URLs
Notion
Document loaders | 🦜️🔗 Langchain
この下書きを書いている間にもすごく増えていました。
アプローチ
DeepLearning.aiのLangChain講座2の1の内容をまとめます。
サンプル
Document Loading
## Note to students.
During periods of high load you may find the notebook unresponsive. It may appear to execute a cell, update the completion number in brackets [#] at the left of the cell but you may find the cell has not executed. This is particularly obvious on print statements when there is no output. If this happens, restart the kernel using the command under the Kernel tab.
負荷が高い時期には、ノートブックが反応しなくなることがあります。セルの実行が行われたように見え、セルの左側の括弧[#]内の完了番号が更新されるかもしれませんが、セルが実行されていないことに気付くことがあります。これは、出力がない印刷文で特に明らかです。これが発生した場合、Kernelタブの下のコマンドを使用してカーネルを再起動してください。
このノートブックの使い方ですね。
Retrieval augmented generation
In retrieval augmented generation (RAG), an LLM retrieves contextual documents from an external dataset as part of its execution.
This is useful if we want to ask question about specific documents (e.g., our PDFs, a set of videos, etc).
#! pip install langchainimport os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']PDFs
Let's load a PDF [transcript](https://see.stanford.edu/materials/aimlcs229/transcripts/MachineLearning-Lecture01.pdf) from Andrew Ng's famous CS229 course! These documents are the result of automated transcription so words and sentences are sometimes split unexpectedly.
Andrew Ngの授業の文字起こしテキスト(PDF)です。なぜ文字起こしテキストがPDFなんだろう。文字起こしの文字認識です笑
# The course will show the pip installs you would need to install packages on your own machine.
# These packages are already installed on this platform and should not be run again.
# ! pip install pypdfPyPDFを使うようです。
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf")
pages = loader.load()Each page is a `Document`.
A `Document` contains text (`page_content`) and `metadata`.
これだけで読み込めるんですね。
len(pages)22中身はこんな感じです。
page = pages[0]
print(page.page_content[0:500])MachineLearning-Lecture01
Instructor (Andrew Ng): Okay. Good morning. Welcome to CS229, the machine
learning class. So what I wanna do today is ju st spend a little time going over the logistics
of the class, and then we'll start to talk a bit about machine learning.
By way of introduction, my name's Andrew Ng and I'll be instru ctor for this class. And so
I personally work in machine learning, and I' ve worked on it for about 15 years now, and
I actually think that machine learning ipage.metadata{'source': 'docs/cs229_lectures/MachineLearning-Lecture01.pdf', 'page': 0}ページ数も自動でメタデータに入れてくれるのすごく使えますね。
YouTube
次はYouTubeです。文字起こし精度次第ですが、便利ですね。
from langchain.document_loaders.generic import GenericLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader# ! pip install yt_dlp
# ! pip install pydub**Note**: This can take several minutes to complete.
まあまあ時間かかります。
url="https://www.youtube.com/watch?v=jGwO_UgTS7I"
save_dir="docs/youtube/"
loader = GenericLoader(
YoutubeAudioLoader([url],save_dir),
OpenAIWhisperParser()
)
docs = loader.load()[youtube] Extracting URL: https://www.youtube.com/watch?v=jGwO_UgTS7I
[youtube] jGwO_UgTS7I: Downloading webpage
[youtube] jGwO_UgTS7I: Downloading ios player API JSON
[youtube] jGwO_UgTS7I: Downloading android player API JSON
[youtube] jGwO_UgTS7I: Downloading m3u8 information
[info] jGwO_UgTS7I: Downloading 1 format(s): 140
[download] docs/youtube//Stanford CS229: Machine Learning Course, Lecture 1 - Andrew Ng (Autumn 2018).m4a has already been downloaded
[download] 100% of 69.71MiB
[ExtractAudio] Not converting audio docs/youtube//Stanford CS229: Machine Learning Course, Lecture 1 - Andrew Ng (Autumn 2018).m4a; file is already in target format m4a
Transcribing part 1!
Transcribing part 2!
Transcribing part 3!
Transcribing part 4!複数のパートに分けてWhisper APIで文字認識した結果を連結しているようです。
docs[0].page_content[0:500]"Welcome to CS229 Machine Learning. Uh, some of you know that this is a class that's taught at Stanford for a long time. And this is often the class that, um, I most look forward to teaching each year because this is where we've helped, I think, several generations of Stanford students become experts in machine learning, got- built many of their products and services and startups that I'm sure, many of you or probably all of you are using, uh, uh, today. Um, so what I want to do today was spend s"URLs
最後はURLです。結構HTMLだと構造の情報を保ちながら取り込むの難しいんですよね。どれくらいできるようになっているのか。
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://github.com/basecamp/handbook/blob/master/37signals-is-you.md")docs = loader.load()
print(docs[0].page_content[:500])handbook/37signals-is-you.md at master · basecamp/handbook · GitHub
Skip to content
{大量の空白}
Toggle navigation
{大量の空白}
Sign up
{大量の空白}
Product
{大量の空白}
Actions
Automate any workflow
{大量の空白}
Packages
Host and manage packages
{大量の空白}
Security
Find and fix vulnerabilities
{大量の空白}
Codespこれは、、できているのか、、?
Notion
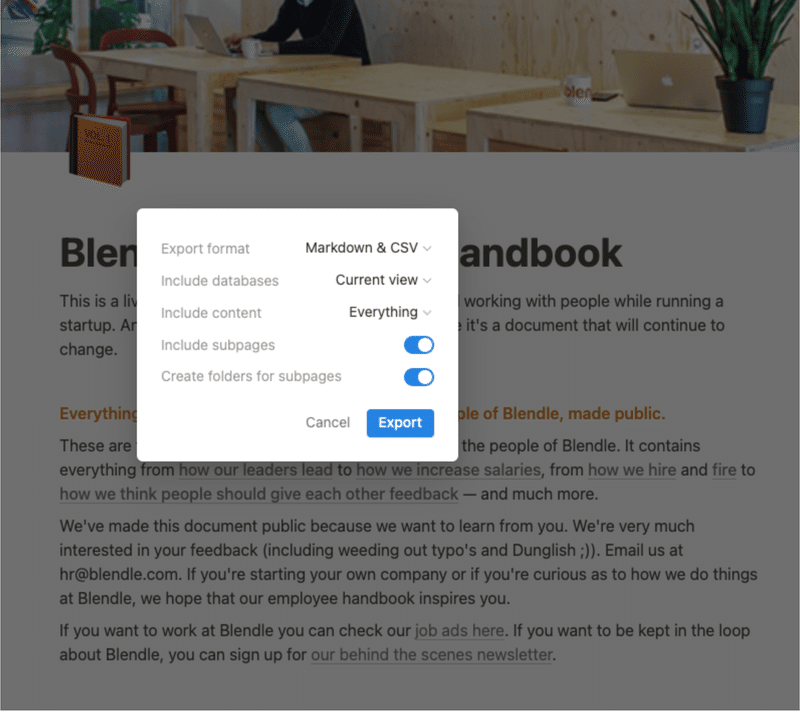
Follow steps [here](https://python.langchain.com/docs/modules/data_connection/document_loaders/integrations/notion) for an example Notion site such as [this one](https://yolospace.notion.site/Blendle-s-Employee-Handbook-e31bff7da17346ee99f531087d8b133f):
* Duplicate the page into your own Notion space and export as `Markdown / CSV`.
* Unzip it and save it as a folder that contains the markdown file for the Notion page.
まずはExportです。Markdownにすれば読み込めますもんね。
from langchain.document_loaders import NotionDirectoryLoader
loader = NotionDirectoryLoader("docs/Notion_DB")
docs = loader.load()エクスポートしたNotionのドキュメントをディレクトリで指定します。
print(docs[0].page_content[0:200]) # Blendle's Employee Handbook
This is a living document with everything we've learned working with people while running a startup. And, of course, we continue to learn. Therefore it's a document thatNotionでドキュメント管理している場合は、すごく簡単にチャットボットが作れそうですね。
docs[0].metadata{'source': "docs/Notion_DB/Blendle's Employee Handbook e367aa77e225482c849111687e114a56.md"}メタデータに、Notionのページリンクなども追加すれば、関連ドキュメントに飛ばすこともできますね。
まとめ
DeepLearning.aiのLangChain講座2の1の内容をまとめました。
今回は様々なソースからのデータ取り込み方法でした。プロジェクトでもデータの取り込みはやっていますが、実はここにあるように簡単ではないんですよね。PDFの種類によってはパワポのように図表が満載だったり、授業の文字起こしテキストと違って一般知識以外の前提知識が必要だったり。それでもLangChainがあることで、その課題まではすぐ辿り着くことができます。キャッチアップを怠らないようにしていきたいですね。
読んでいただきありがとうございます。少し空いてしまいましたが、進めていこうと思います。
参考
Document loaders | 🦜️🔗 Langchain
サンプルコード
この記事が気に入ったらサポートをしてみませんか?