【DLAI×LangChain講座②】 Memory

背景
LangChainは気になってはいましたが、複雑そうとか、少し触ったときに日本語が出なかったりで、後回しにしていました。
DeepLearning.aiでLangChainの講座が公開されていたので、少し前に受講してみました。その内容をまとめています。
第1回はこちらです。
今回は第2回 Memoryについてです。
様々な種類のMemoryが用意されていて、さらに複数のMemoryを組み合わせるとか、カスタムのMemoryを開発することもできます。
アプローチ
DeepLearning.aiのLangChain講座の2の内容をまとめます。
また、講座中には基本的なConversation Memoryしか出てこなかったので、他のMemoryについても調べました。
サンプル
Conversation Memoryには、以下のような種類があります。
ConversationBufferMemory
ConversationBufferWindowMemory
ConversationTokenBufferMemory
ConversationSummaryMemory
ConversationBufferMemoryは、しっかり見てはいませんが、他のメモリーの特徴から、全てのやりとりをそのまま記憶する機能だと思います。そのため、対話が長くなるトークン制限に引っかかると思います。(実際に引っかかるかを調べるのは面倒なのでやりません)
ConversationBufferWindowMemoryは、直近k回分のやりとりを保持します。
ConversationTokenBufferMemoryは、やりとりの回数ではなく、トークン数で記憶を管理します。max_tokensを決めると、対話履歴全体がその中に収まるようにしてくれます。長い文章を使った対話を行う場合や、対話履歴に他にもプロンプトを含めたい場合などに有効そうですね。
ConversationSummaryMemoryは、max_tokensに収まるように対話履歴の要約を作成してくれます。直近の流れがわからないので、QAチャットボットなど、一問一答タイプの会話ならいいかもです。
簡単にいくつかのConversation Memoryについて説明しました。
詳しくは、ドキュメントを見てみてください。ナレッジグラフやベクトルストアを使うメモリーもあるようです。
ConversationBufferMemory
まずは、一番シンプルなConversation Memoryです。
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory以下のように`ConversationChain`に渡すことで、ステートフルな対話オブジェクトが生成できます。
llm = ChatOpenAI(temperature=0.0)
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=llm,
memory = memory,
verbose=True
)まずは自己紹介をしています。
conversation.predict(input="Hi, my name is Andrew")Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hi, my name is Andrew
AI:
Finished chain.
"Hello Andrew, it's nice to meet you. My name is AI. How can I assist you today?"Hello Andrew, it's nice to meet you. My name is AI. How can I assist you today?
`verbose=True`とすることで、ConversationChainのプロンプトがわかりますね。
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: *****
AI: *****
Human: *****
AI: "以下の会話は、人間とAIの友好的な会話です。AIはおしゃべりで、コンテキストから具体的・詳細な内容を話します。AIは質問の答えを知らない場合、正直のそう言います。"
チャットボットで扱う場合は、他にも様々な指示をする必要がありそうですね。例えば、食や献立に関するアドバイスをするチャットボットを試そうとしたときは、いきなり適当なレシピを生成し、詳細な説明を出力してしまうことがありました。そのため、「レシピ提案をしないでください。」という文言が必要です。
次に、関係のない質問をします。
conversation.predict(input="What is 1+1?")そして、最初に伝えた名前を聞いてみます。
conversation.predict(input="What is my name?")Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hi, my name is Andrew
AI: Hello Andrew, it's nice to meet you. My name is AI. How can I assist you today?
Human: What is 1+1?
AI: The answer to 1+1 is 2.
Human: What is my name?
AI:
Finished chain.
"Your name is Andrew, as you mentioned earlier."Your name is Andrew, as you mentioned earlier.
Current conversationに以前の会話が記録されているので、正しく返せています。
メモリーの情報は以下のコードで確認できます。
print(memory.buffer)Human: Hi, my name is Andrew
AI: Hello Andrew, it's nice to meet you. My name is AI. How can I assist you today?
Human: What is 1+1?
AI: The answer to 1+1 is 2.
Human: What is my name?
AI: Your name is Andrew, as you mentioned earlier.こちらのコードでも確認ができます。
memory.load_memory_variables({}){'history': "Human: Hi, my name is Andrew\nAI: Hello Andrew, it's nice to meet you. My name is AI. How can I assist you today?\nHuman: What is 1+1?\nAI: The answer to 1+1 is 2.\nHuman: What is my name?\nAI: Your name is Andrew, as you mentioned earlier."}次に、Conversation Memoryがどのように記録しているかを確認します。
memory = ConversationBufferMemory()memory.save_context()で保存できるようです。
ステートフルなAPIを構築する場合は、毎回ユーザの対話履歴を呼び出し、このようにMemoryに入れることになるのでしょうか?それならLangChainを使う必要ない気がしますが。。もし他の構築方法をご存じの方は教えてください。
ConversationBufferWindowMemory
次は、直近k回のやりとりを保存するConversation Memoryです。
from langchain.memory import ConversationBufferWindowMemoryk=1と設定すると、直近1回のやりとりのみ保存されていることが確認できます。
memory = ConversationBufferWindowMemory(k=1) memory.save_context({"input": "Hi"},
{"output": "What's up"})
memory.save_context({"input": "Not much, just hanging"},
{"output": "Cool"})
memory.load_memory_variables({}){'history': 'Human: Not much, just hanging\nAI: Cool'}では、最初の会話を`ConversationBufferWindowMemory`で行ってみましょう。
llm = ChatOpenAI(temperature=0.0)
memory = ConversationBufferWindowMemory(k=1)
conversation = ConversationChain(
llm=llm,
memory = memory,
verbose=False
)conversation.predict(input="Hi, my name is Andrew")"Hello Andrew, it's nice to meet you. My name is AI. How can I assist you today?"Hello Andrew, it's nice to meet you. My name is AI. How can I assist you today?
conversation.predict(input="What is 1+1?")'The answer to 1+1 is 2.'conversation.predict(input="What is my name?")"I'm sorry, I don't have access to that information. Could you please tell me your name?"I'm sorry, I don't have access to that information. Could you please tell me your name?
先ほどのConversationBufferMemoryと異なり、最初のやりとりで記憶した名前を覚えていません。
ConversationTokenBufferMemory
次に、トークン数によって保存するやりとりを決めるConversation Memoryです。
from langchain.memory import ConversationTokenBufferMemory
from langchain.llms import OpenAI
llm = ChatOpenAI(temperature=0.0)max_token_limitを小さく設定し、古い履歴が消えていることを確認します。
memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=30)
memory.save_context({"input": "AI is what?!"},
{"output": "Amazing!"})
memory.save_context({"input": "Backpropagation is what?"},
{"output": "Beautiful!"})
memory.save_context({"input": "Chatbots are what?"},
{"output": "Charming!"})memory.load_memory_variables({}){'history': 'AI: Beautiful!\nHuman: Chatbots are what?\nAI: Charming!'}2つ目のAIからの応答以降の対話履歴を保存しています。inputとoutputは常にセットなのかと思いましたが、そうではないようですね。
ConversationSummaryMemory
最後は、トークン数に従って、対話履歴の要約を記憶するConversation Memoryです。
from langchain.memory import ConversationSummaryBufferMemoryわかりやすいようにChatGPTで日本語に翻訳して入力しました。
# create a long string
schedule = "8時にあなたの製品チームとのミーティングがあります。\
パワーポイントのプレゼンテーションを準備する必要があります。\
午前9時から12時までは、LangChainプロジェクトに取り組む時間があります。\
LangChainは非常にパワフルなツールなので、作業はスムーズに進むでしょう。\
正午には、イタリアンレストランでお昼ご飯をお客様とともにとります。\
お客様は1時間以上かけて運転して会いに来る予定です。\
最新のAIについて理解するために、最新のLLMデモを見せるために、必ずノートパソコンを持ってきてください。"
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100)
memory.save_context({"input": "こんにちは。"}, {"output": "どうしたの?"})
memory.save_context({"input": "なんでもないよ。ただぼーっとしてるだけ。"},
{"output": "いいね。"})
memory.save_context({"input": "今日の予定は何があった?"},
{"output": f"{schedule}"})memory.load_memory_variables({}){'history': 'System: The human greets the AI in Japanese and the AI responds. The human asks about their schedule for the day and the AI provides a detailed list of tasks, including a meeting with the product team, working on the LangChain project, and having lunch with a client at an Italian restaurant. The AI reminds the human to bring their laptop to show the latest LLM demo to understand the latest AI.'}このような要約がMemoryに記録されています。このMemoryを使って、質問をしてみます。
conversation = ConversationChain(
llm=llm,
memory = memory,
verbose=True
)conversation.predict(input="どのようなデモが良いでしょうか?")Entering new chain...0m
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
System: The human greets the AI in Japanese and the AI responds. The human asks about their schedule for the day and the AI provides a detailed list of tasks, including a meeting with the product team, working on the LangChain project, and having lunch with a client at an Italian restaurant. The AI reminds the human to bring their laptop to show the latest LLM demo to understand the latest AI.
Human: どのようなデモが良いでしょうか?
AI:
Finished chain.
'最新のLLMデモです。それは、自然言語処理に基づく言語モデルであり、言語の理解と生成に使用されます。デモでは、LLMがどのように機能するかを示し、その機能を実際に体験することができます。それは非常に興味深いです!'最新のLLMデモです。それは、自然言語処理に基づく言語モデルであり、言語の理解と生成に使用されます。デモでは、LLMがどのように機能するかを示し、その機能を実際に体験することができます。それは非常に興味深いです!
これは会話風ですが、一問一答です。「何時から何時にLangChainプロジェクトに取り組みますか?」のように、要約で落ちてしまった情報は復元できませんね。
おまけ
ConversationKGMemory
ということで、ConversationKGMemoryを使ってみました。
めちゃめちゃ手こずりました。。
まず、日本語だとKGがうまく構築できなかったので注意してください。
そのため、今回の例は英語で入力しました。
from langchain.chat_models import ChatOpenAI
from langchain.prompts.prompt import PromptTemplate
from langchain.chains import ConversationChain
from langchain.memory import ConversationKGMemory
import networkx as nx
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())可視化用にnetworkxをインポートしています。
llm = ChatOpenAI(temperature=0)
template = """The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context.
If the AI does not know the answer to a question, it truthfully says it does not know. The AI ONLY uses information contained in the "Relevant Information" section and does not hallucinate.
Relevant Information:
{knowledge}
Human: {input}
AI:"""
prompt = PromptTemplate(
input_variables=["knowledge", "input"], template=template
)
memory = ConversationKGMemory(
llm=llm, input_key="input", memory_key="knowledge"
)
conversation_with_kg = ConversationChain(
llm=llm, memory=memory,
prompt=prompt, verbose=True,
)これでOKです。`input_key`はMemoryの入力、`memory_key`はMemoryの出力みたいです。PromptTemplateを渡すのが必須なのかな。PromptTemplateなしのバージョンも試したけど、今のところよくわかりません。
今回は、グローバルなKenさんの家族についてです。
シンプルに、Kenさんの家族がどこに住んでいるかを伝えます。
text = """\
I introduce you Ken's family members.
Ken's mother lives in England.\
Ken's father lives in America.\
Ken's brother lives in India.\
"""
conversation_with_kg.predict(input=text)Entering new chain...
Prompt after formatting:
mThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context.
If the AI does not know the answer to a question, it truthfully says it does not know. The AI ONLY uses information contained in the "Relevant Information" section and does not hallucinate.
Relevant Information:
Human: I introduce you Ken's family members.
Ken's mother lives in England.Ken's father lives in America.Ken's brother lives in India.
AI:
Finished chain.
"Oh, that's interesting! Ken's family is quite spread out across different countries. It must be exciting for them to have family members living in different parts of the world. I wonder how often they get to see each other and how they stay connected despite the distance."Oh, that's interesting! Ken's family is quite spread out across different countries. It must be exciting for them to have family members living in different parts of the world. I wonder how often they get to see each other and how they stay connected despite the distance.
どんなKGができたか確認してみましょう。
nx.draw(conversation_with_kg.memory.kg._graph, with_labels = True)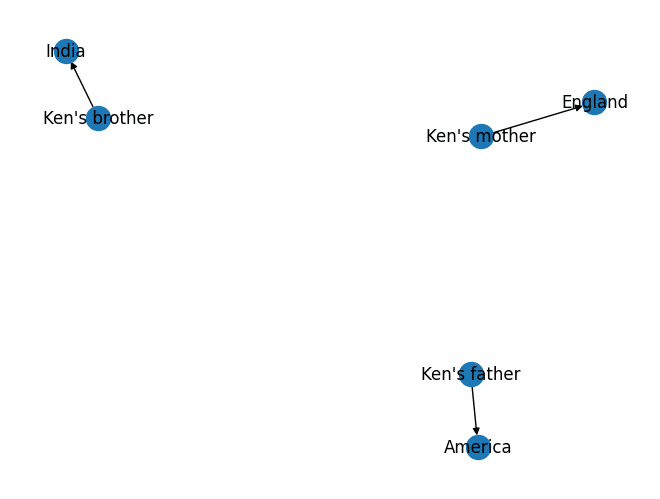
Kenは登場していませんね。"Ken - ’s - brother"のようにTripletが作られてほしいところですが。結構色々試しましたが、KGの構築がうまくない印象です。
次に、Kenさんの弟と母親の住んでいる場所の時差を聞いてみます。
text = """\
What is the time difference \
between where Ken's brother and Ken's mother live?
"""
conversation_with_kg.predict(input=text)Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context.
If the AI does not know the answer to a question, it truthfully says it does not know. The AI ONLY uses information contained in the "Relevant Information" section and does not hallucinate.
Relevant Information:
On Ken's brother: Ken's brother lives in India.
On Ken's mother: Ken's mother lives in England.
Human: What is the time difference between where Ken's brother and Ken's mother live?
AI:
Finished chain.
"The time difference between where Ken's brother lives in India and where Ken's mother lives in England is approximately 5 hours and 30 minutes."The time difference between where Ken's brother lives in India and where Ken's mother lives in England is approximately 5 hours and 30 minutes.
イギリスとインドの時差は5.5時間(現在はサマータイムで4.5時間)なので、合っています。Relevant Informationに必要な情報が載せてくれていますね。
ここでも、質問のKen'sをhisにするとRelevant Informationを入力してくれなかったりしたので、KGの構築・検索にがボトルネックになっている気がします。
Knowledge Graphはじめ、Entityリスト、VectorStoreなどは、短期メモリとしてのConversationBufferWindowMemoryと組み合わせて、長期記憶として使うのがいいかもしれません。また、会話の前に準備しておく使い方もよさそうです。
まとめ
DeepLearning.aiのLangChain講座の2の内容をまとめました。
MemoryはドキュメントではOpenAI(ChatOpenAIではなく)のサンプルコードしかない場合が多いので、難しいですね。
また、LLM特有の問題として、コードがおかしいのかプロンプトがおかしいのかの切り分けが難しい。今回も、プロンプト的に英語じゃないと動作しない場合がありました。ChatGPTを触っていると、言語は自由な感じを受けるので、引っかかるポイントですね。
次回は、LangChain講座の3のChainsです。よろしくお願いします。
参考
【DLAI×LangChain講座①】 Models, Prompts and Output Parsers|harukary
Memory | 🦜️🔗 Langchain
DLAI - Learning Platform Beta
サンプルコード
https://github.com/harukary/llm_samples/blob/main/LangChain/LangChain_DLAI_1/L2-Memory.ipynb
https://github.com/harukary/llm_samples/blob/main/LangChain/LangChain_DLAI_1/plus_L2.ipynb
この記事が気に入ったらサポートをしてみませんか?