
OFDB (One-instance FractalDB) - ICCV 2023 採択までの道のり

cvpaper.challenge アドベントカレンダー 20日目を担当する福岡大学博士課程3年の中村凌です.今回のアドベントカレンダーではICCV 2023採択までの話を書こうと思います.
ICCV (International Conference on Computer Vision)はCVPRやECCVと並び,コンピュータビジョン分野におけるトップ国際会議のひとつであるため,ICCV 2023採択までの話を書くと立派な感じがしますが,私は研究者としてまだ大成しているわけではなく,時の運と研究コミュニティの仲間に恵まれて採択を頂いた身分なので,ご理解頂けましたら幸いです.
ICCV 2023に採択された研究について
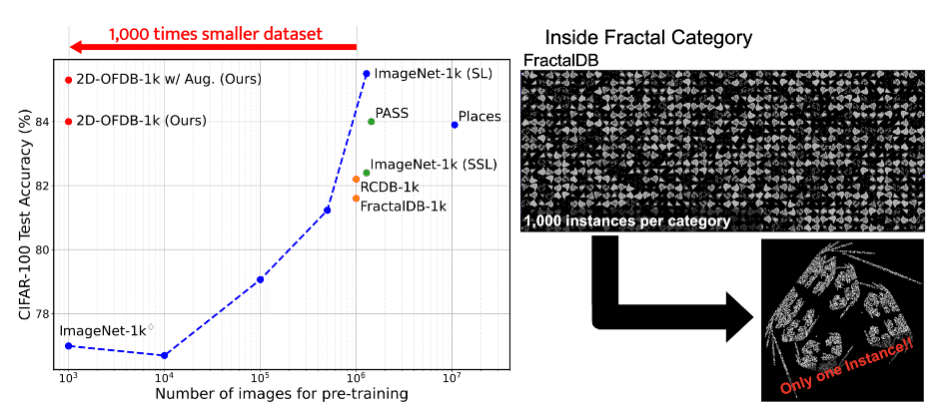
私がICCV 2023で発表した研究は,もともと1,000カテゴリ x 1,000インスタンスの100万画像により構成されていたFractalDBを,クラス内の画像の水増し(データ拡張)考慮により1,000カテゴリ x 1インスタンスの1,000画像のみで視覚的事前学習を完結しようと試みた,という内容です.カテゴリあたり1インスタンスのみで事足りるというところから,この手法はこの記事のタイトルにもあるようにOFDB (One-instance FractalDB)と名付けられました.
ICCV 2023から採択を頂くレベルに到達するためには,従来のFractalDBによる事前学習と同程度の精度では不十分だったので,論文中では,新規にデータ拡張手法の提案や,いくつかの側面から事前学習効果に関する調査を行うことで,OFDBが工学的にどのような利点があるのかを研究の重要性としてアピールしました.
研究の詳細についてはprojet pageを見ていただけますと幸いです.
テーマ選定,MIRUに向けて
ここで過去に遡ります.私が,ICCV 2023採択の研究テーマに着手したのは,2022年の1月でした.
実は,ICCV 2023採択の研究テーマに着手する前は,私は動画認識の研究を実施していたのですが,動画認識の実装と産総研保有のスパコンABCIの使い方に苦戦し,研究を上手く進められず目標としていた国際会議を断念していた,ということが続いてからの,研究テーマ変更でした.動画認識は画像認識と似ているようで異なり,画像の空間方向のみならず時間方向にも処理を展開する必要があり,実装面でも計算量の面でもとても大変な研究テーマとなっていました.
理由が落ちこぼれすぎて大変悲しい気持ちですが,理学部出身の自分が急に工学の人たちのコミュニティに入ったことや動画というモダリティの扱いの困難性もあったこと,さらには周囲の人たちと同レベルのコーディング力を持っていた訳ではなかったことが原因でした.ただ,今になって振り返ってみると,ここで画像認識(特に数式ドリブン教師あり学習)の研究にシフトして良かったと思います.
おかげさまで,画像認識に関するコードは動画認識と比較すると実装しやすく親しみやすいのと,数式ドリブン教師あり学習のチームに事前学習やファインチューニングを実施するコードのテンプレがあったため,すぐに実験を進めることができそうでした.
テーマの選択についても,チームの中で行いたい研究が複数個あり,その中から「FractalDBのクラス内画像はデータ拡張で置き換え可能か?」というOFDBの原型となる研究テーマを選択し,取り組み始めました.
取り組み始めた当初は,データ拡張によりFractalDBのデータ数を大幅に削減しただけで,工学的に何が嬉しいかなんて,全然わかりませんでした.
ただ,データ拡張を通してフラクタル画像を制御し,事前学習をコントロールできることでどのようないいことがあるのか,どんなフラクタル画像を学習すると良いか?ということが少しでも分かれば良いなという軽い気持ちでテーマを選択しました.
テーマを選んだ後,最初の目標はMIRU2022に投稿することでした.
MIRU2022に投稿するためには,早急に「FractalDBの生成時のクラス内画像の水増しが必要ないんじゃないか?」という点についての実験的根拠が必要になるので,
まずはFractalDBのクラス内画像の水増しを行ってない,One-instance FractalDB(OFDB)を作成し,どのデータ拡張を選択したらFractalDBと同等の事前学習効果を得ることができるのか?について調査を行いました.
また,この時期に,東北大学の田所くんがcvpaper.challengeに参加してくれて,コミュニティ内の研究取り組みについて学ぶため,私の研究のサポートについてくれました.
当初は全てのデータ拡張の組み合わせについて調査を行おうとしたのですが,データ拡張の種類が多すぎて実験が膨大になり,ABCIのポイントをかなり消費してしまうため,現実的なやり方ではないと判断しました.
そこで,データ拡張のサーベイ論文に倣って,データ拡張の種類を幾何学的変換,色変換,マスキングのようにグルーピングし,要素数を減らして実験を行いました.
その結果,Vision Transformerにおいては,OFDBに幾何学的変換とAuto augmentation(AA)を用いることで,カテゴリ内の水増しの有無に関わらず同程度の事前学習効果を得られることが確認できました.
その理由を調査するために「XAI(説明可能なAI):そのとき人工知能はどう考えたのか?」という本に書いてあった,LIMEと呼ばれる手法を適用していたことを覚えています.
MIRU2022では,これらの結果を4ページに収めて口頭(オーラル)発表候補論文に投稿しましたが,結果的には査読結果が思うほど良くはなく,ポスター発表としての採択にとどまりました.
2020年に私が投稿したときは引用文献を外して4ページだったはずでしたが,2021年では,引用文献込みで4ページになっていて,運営の方にご迷惑をおかけしてしまったのを覚えています.
ということもあったのですが,ロングオーラルを目指して論文を投稿したので,ポスター発表という結果は大変悔しいものでした.
一生懸命に取り組んだこともあったので,実力を測られた感じと,手伝ってくれた共著陣への申し訳なさで一杯でした.
ただ,査読のレビューは非常に親切なもので,気持ち的に救われたことを覚えています.
査読者からは,FractalDBのクラス内のデータ数を減らす事は,複数の実験により論じていかないといけないため,MIRU投稿規定の4ページで研究の魅力を伝えることがそもそも不可能だから,非常に惜しくて残念というコメントをいただきました.
このコメントを受けて,私は,やろうとしていること,その重要性や魅力みたいなものは査読者に理解してもらえたと感じ,自分の方針に自信を持つことができました.また,複数の実験により主張をサポートすれば良い研究になると確信しました.
この査読がきっかけとなり,cvpaper.challengeの大目標として掲げる「CV分野の今を映し,トレンドを創り出す挑戦」の実現のため,多くの研究メンバーが投稿を目指すCVPR 2023への投稿に向けて私も頑張ろうと思うことができました.
CVPR 2023に向けて
MIRU2022の一件が無事に終わり,CVPRに向けた体制を整えることになりました.
CVPR 2022投稿(2021年8月頃)から片岡さんを筆頭に東工大の井上中順先生,横田理央先生との連携が行われており,私もその輪の中に入って研究を進めていくことになりました.
定例打ち合わせは週に1回1時間程度で行われており,私の進捗報告だけでなく,東工大の学生さんや産総研のメンバーも研究の報告をしていたので,自分の報告の持ち時間が少なく,いかに短い時間で良い議論をするための説明と質問をできるかというのが重要になっていました.
初めてミーティングに参加したときは,産総研外の方と研究の打ち合わせをするのは初めてで緊張したのを覚えています.
最初の打ち合わせでは当然のように研究の説明をすることになるのですが,FractalDBのクラス内画像を1枚にして,事前学習に適するデータ拡張を1つ1つ検証していたため,CVPR 2023投稿のベースとなる事前学習効果まで到達しておらず,微妙といった評価になっていたのが印象に残っています.
この印象を変えるためには,OFDBの事前学習の効果をあげたベースラインを提示する必要があったため,実験設定を,当時ViTの最先端と言われていたDeiT (Data efficient image Transformer)と呼ばれる学習設定およびデータ拡張に変更しました.
実験設定を変更したことで,OFDBが1,000画像の事前学習ながら,100万画像規模のデータセットに近い事前学習効果をもたらすことが確認できたので,これは面白い研究なのでは?という空気感になって,研究に拍車がかかったことが印象に残っています.
ただ,このまま実験を進めていてもFractalDBのデータ数を(1/1000に)減らせたねという研究になってしまい,工学的貢献(どれだけ良くなるのか?)および,なぜそれで事前学習ができるのか?という問いに答えることができないと考えたため,これらの点に応えるための追加実験をできる限り行いました.
限られたデータセットにおけるViTの事前学習の比較,21,000カテゴリ(21,000画像)で構成されたOFDB-21kを構築しImageNet-21k事前学習の精度・学習時間との比較,Data pruningによる良いカテゴリとは何かについての解析,逆に実画像データセット側のImageNetを1クラスあたり1枚の画像で構成してOFDBと比較するなど,締め切りギリギリまで可能な限りの実験を重ねていきました.
CVPR 2023の締切が近づくと,執筆作業も進めなければいけません.片岡さん,先生陣も執筆に協力してくれましたが,実験と執筆の両方を高速に進めていかなければならず,とても大変でした.
特にImageNet-21kデータセットの実験は1kの実験とは異なり,データセットのサイズが大きかったため,大規模な計算資源を扱うスキルが必要になり,その実験を横田先生の学生さんである高島さん,Edgarさんに手助けしてもらいました.
私も,この会議が通らないと,博士課程における成果が全然ない状況だったので一生懸命取り組んでいました.
しかし,CVPR 2023では,事前学習結果が大規模なデータセットで事前学習を行った他の論文値より低いことを理由に不採択という結果に終わりました.
SSII 2023での発表
CVPR 2023後の2023年6月に,国内では最大規模を誇るシンポジウムであるSSII2023でポスター発表をしてインタラクティブにコメントを頂いていました。やはり,なぜ事前学習できるのか,事前学習にどの程度計算時間が削減できるのか,などを問うようなご質問が多かったことを覚えております.ポスターや配布資料など,事前準備に時間をかけていたこともあり,インタラクティブセッション・オーディエンス賞を頂くことができました。しかも,同じ研究グループからSSII2023にて発表していた速水くんたちのVisualAtomに関する発表も同時受賞していました.1件しか受賞できないオーディエンス賞を同率の得票数で2件も受賞できた,ということになります.この受賞により,私の研究の価値が少しでも認められたことを嬉しく思いました.

ICCV 2023投稿に向けて
CVPR 2023の投稿では,片岡さんとどこが悪かったのかについて議論し,合成画像でデータを減らしているにも関わらず,事前学習の最先端の研究と比較されていて,アピールポイントとは異なるところについて言及されているということが分かりました.
そのためICCV 2023に投稿するときには,最先端の事前学習研究ではなく,データを減らす研究という部分に着目してもらうために,データを減らせる理由の内容を厚くしました.特に,手法の章で「なぜ,カテゴリあたり1インスタンスのFractalDBでうまくいくのか?」に関する説明を念入りにしていました.
その他の修正点としては,CVPRの査読で指摘のあった,他の論文の実験値の引用の部分について指摘を受けないように,パラメータの詳細をサプリメンタルマテリアルに追記し,その他の査読コメントに関する部分を修正したくらいでした.
それが良い結果に繋がったかどうかは,分かりませんが,結果的にStrong accept, Weak accept, Borderline accept(初期判定ではWeak RejectだったのがRebuttalでひっくり返りました)という最終判定になって,総合的にも無事に採択という流れになりました.
採択されたのが2023年の7月だったので,国際会議採択までに1年半かかった事になり,博士課程期間の半分をこの研究に使った事になります.

終わりに
この記事を通してICCV 2023採択までについて振り返りました.
結局,「フラクタルの事前学習において重要な要素は何か?」「理想的な学習の実現のためには,どのような画像表現を満たしている必要があるか,また画像は何枚必要か?」
については,まだ明らかにすることができてないので,研究者としてはまだまだ未熟です.
今回ICCV 2023に採択されたのも,私が優秀だからではなくて,時の運と研究コミュニティのメンバーに,自分1人だともっと時間がかかった部分を補ってもらったことによるため,自分1人で進めていたらICCV 2023に採択されることはなかったと思います.
当たり前ですが,ICCV 2023に採択されたからといって,研究者として独り立ちできるだけの力がついたという訳でもないので,投稿期間中に自分でできなかったことをできるようにするための地道な努力が必要だなと感じました.
また,私はそういう地道な努力によってできることを増やしてきた人へ憧れがあるので,業績に驕らず,地道な努力を積み重ねていきたいです.
外部に向けた文章を書く経験はこれまであまりなかったのですが,ここまで読んでいただいた方,ありがとうございました.
※ cvpaper.challenge 公式からSNSに投稿されたポストは10万近くのタイムラインに表示されたようです.最初はテーマの意味が分からず,研究の価値を感じられなかったのですが,最終的には客観的にもインパクトのある研究ができたことは良い経験となりました.
この記事が気に入ったらサポートをしてみませんか?