
4.AIイラスト(StableDiffusion)初心者向けのおすすめモデルの説明とか

2.インストール(https://note.com/cocoat/n/n8780c1ca3b1f)
3.Civitaiへ接続( https://note.com/cocoat/n/n3180e7c16d7d)の続きだよ
インストールの時は生成の早いLCMっていうモデルを使ったけど、
今回はより綺麗なものが作れる(かもしれない)モデルにするね

2.インストールの時に作った説明の続きと
プロンプト(指示文)の説明とかを少ししていこうかな。
使うモデルによって違うから、”これが一番いい”というのはない感じだね。
この土地ではどれが一番おいしいかっていう話と同じ感じかな。

うさぎさんによって好みの人参が違う感じですね
高級な人参をあげた後に安いニンジンを食べてくれなくなることはない
まずは起動して、ModelBrowserを押してAnimagineで検索
モデルの種類とか細かいことは下の方で書くけど、
とりあえずいつも通りStabilityMatrixを起動してComfyUIをLaunch。
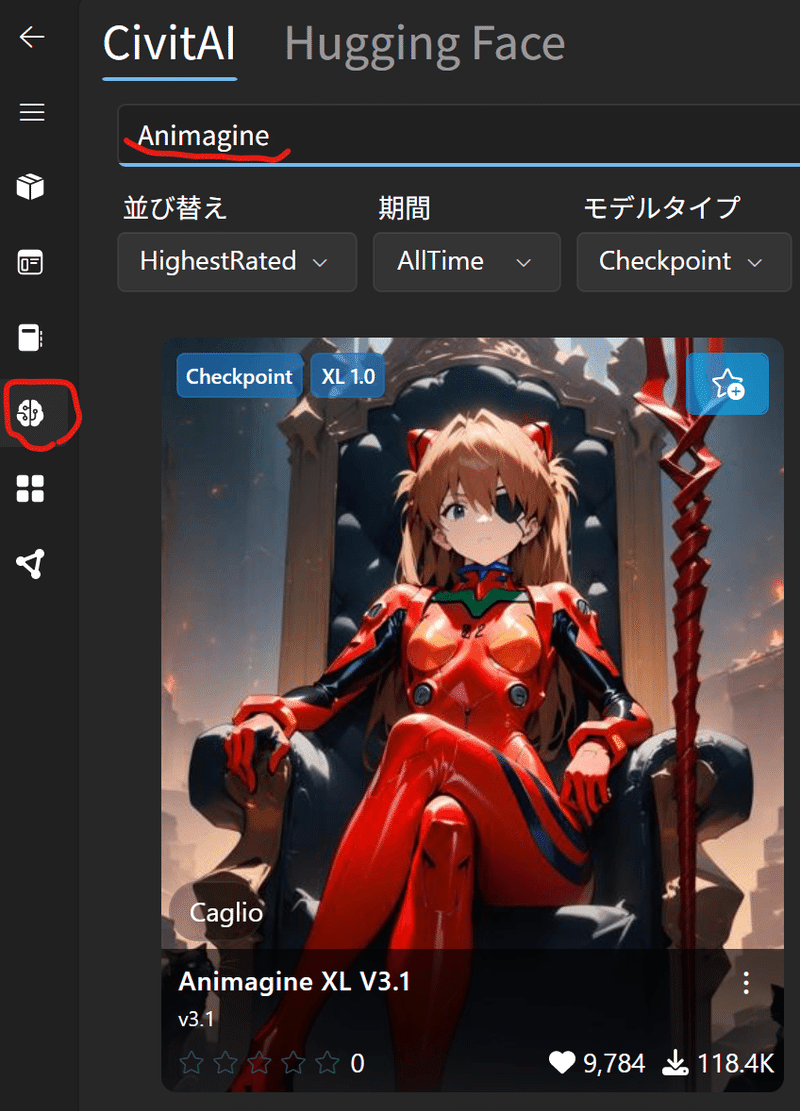
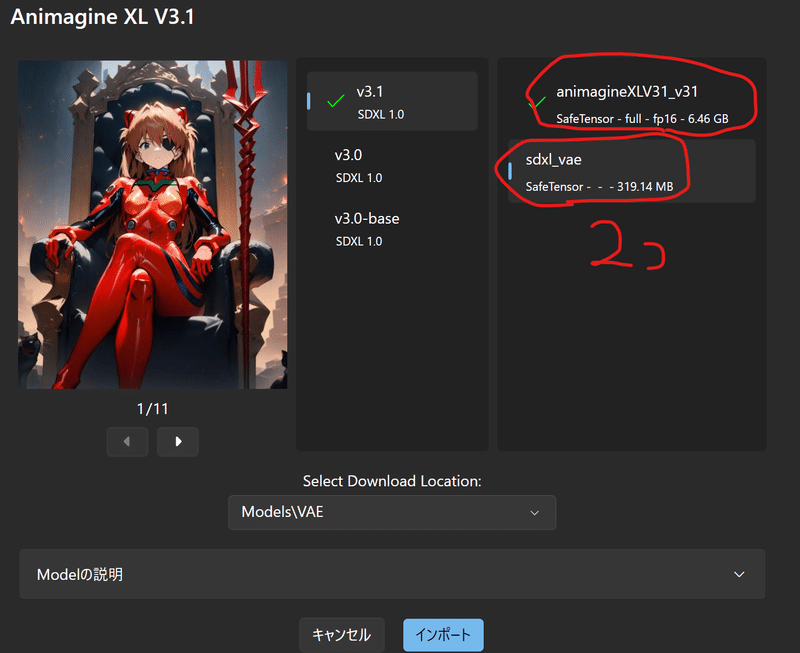
好きなモデルを使っているとは思うけど、今回は説明用にAnimagineを使うね。sdxl_vaeと2つダウンロード。

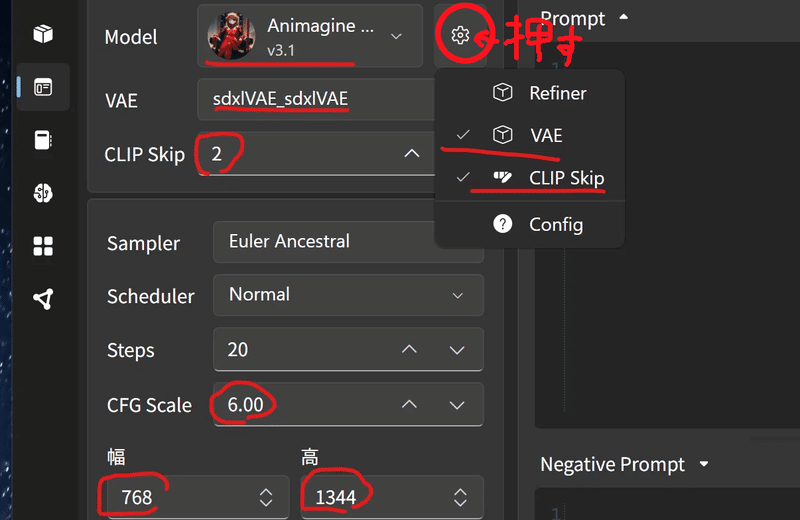
おすすめ設定。
$$
\begin{array}{|l|l|l|} \hline
\textnormal{項目} & \textnormal{設定} & \textnormal{例えて言うなら} \\ \hline
\bold{VAE} & \textnormal{sdxlVAE} & \textnormal{後処理の匠(本来はAIと人との仲介役的な存在)} \\ \hline
\bold{CLIP Skip} & \textnormal{2} & \textnormal{素直さ(プロンプトに従うかどうか)} \\ \hline
\bold{Sampler} & \textnormal{Euler Ancestral} & \textnormal{生成する職人さん(ノイズ除去のやり方)} \\ \hline
\bold{Scheduler} & \textnormal{nomal}& \textnormal{職人の手法(除去タイミング)} \\ \hline
\bold{Steps} & \textnormal{20}& \textnormal{何回仕事をするか} \\ \hline
\bold{CFG Scale} & \textnormal{6.00}& \textnormal{低いとファンタジー、高いとアメコミ(再現度)} \\ \hline
\end{array}
$$
項目の設定を変更していってね。
Animagineの推奨の画像サイズはいくつかあるけど、今回は縦長でいくね
AnimagineXL3.1推奨画像サイズ
1024 x 1024 1:1 Square
1152 x 896 9:7
896 x 1152 7:9
1216 x 832 19:13
832 x 1216 13:19
1344 x 768 7:4 Horizontal
768 x 1344 4:7 Vertical
1536 x 640 12:5 Horizontal
640 x 1536 5:12 Vertica
次はプロンプトとネガティブプロンプトだけど、
Animagineを使うならこれは入れておいた方がいいかな。
初めに言ってた、この土地ではこれを植えろっていうやつだね
Prompt(プロンプト)
masterpiece, best quality, very aesthetic, absurdresNegativ Prompt(ネガティブプロンプト)
nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract](えちえちは最初のnsfwを抜いたネガティブプロンプト↓)
lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]
ここまで出来たら設定を保存しちゃおう

これで結構なクオリティが約束されているようなものなので、
あとは翻訳先生の御出番。
Google翻訳さん
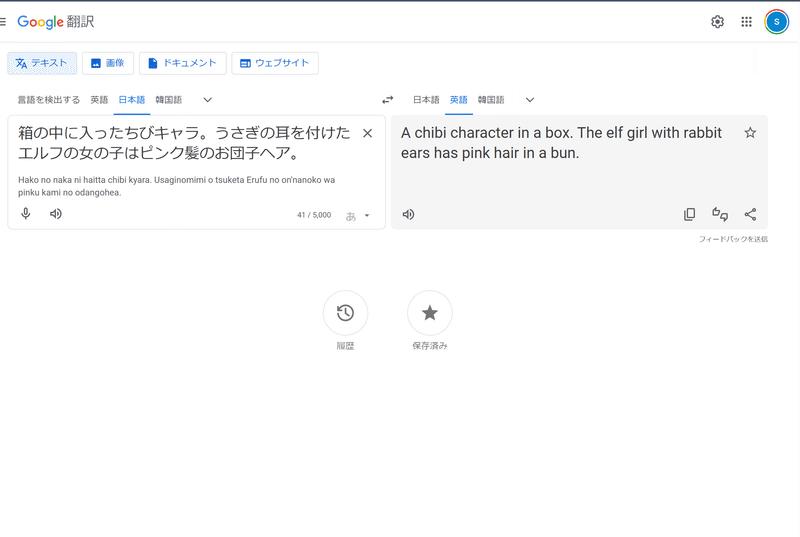
プロンプトは単語の区切りが , (カンマ) でする当たり前になってしまっているからなるべくは , で区切っていくけど
文章なら . (ピリオド/ドット)でも大丈夫だと信じてる。
日本語で言う 、(読点)。(句点)みたいなものだと。
masterpiece, best quality, very aesthetic, absurdresのあとに区切りの , を入れて
masterpiece, best quality, very aesthetic, absurdres, A chibi character in a box. The elf girl with rabbit ears has pink hair in a bun.
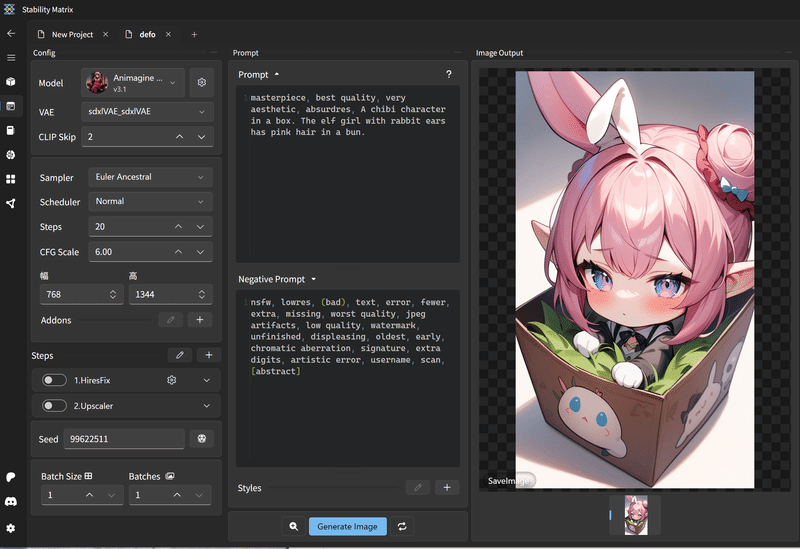
うさ耳がひとつだったり、お団子が耳になっちゃったりするのは、
頭パーツを満載にした人が悪いので処理が間に合わなかっただけで
何回か生成して成功したのを使う感じだね。

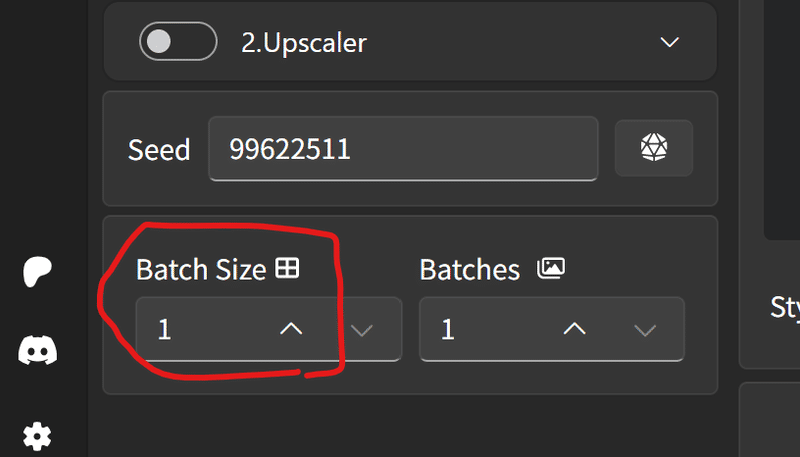
何回か生成したいときはBatchSizeを増やせばGenerateを押す手間が必要がなくなるよ。
BatchSizeというのは、同時に何枚作るかで
Batchesというのは、何回生成するかってことだけど
処理としては同時に作る方が負担が重くなるから、比率はパソコンと相談していく感じだね。
見ながら作るならBatchesを増やして良いのが出来たら止めればいいと思う

良いのが出来たらHiresでアップスケールしよう(画像を大きくする)
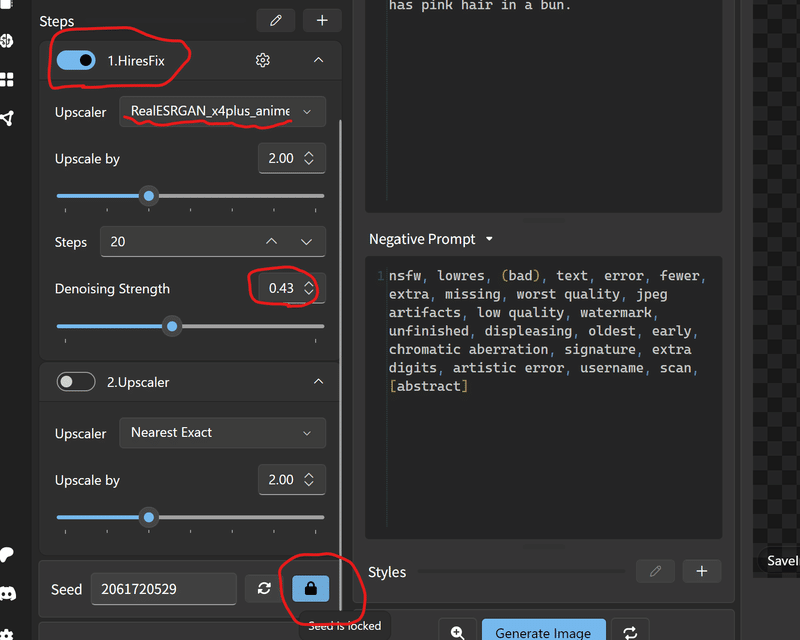
HiresFix(生成しながら拡大)と、Upscler(拡大)というのがあるけど、
HiresFixでやるよ。
UpsclerをRealESRGAN_x4plus_animeにして
Denoising Strength というのが生成する強さみたいなもので、
1だと全部描き足しで、0だとUpsclerと同じ感じかな。
今回は0.43でやってみよう。
忘れちゃいけないのがこの”Seedと呼ばれるものの固定”
Seedがは画像番号みたいなものだから同じ設定で、
Seedも同じならほぼ同じ画像が出来上がる。
$$
\begin{array}{|l|l|l|} \hline
\textnormal{項目} & \textnormal{設定} & \textnormal{例えて言うなら} \\ \hline
\bold{Hiresfix} & \textnormal{オン} & \textnormal{画像を拡大(修正しながらアップスケール)} \\ \hline
\bold{Upscler} & \textnormal{RealESRGAN x4plus anime} & \textnormal{職人さん(アップスケール処理の種類)} \\ \hline
\bold{Steps} & \textnormal{20} & \textnormal{仕事の回数(修正を重ねる回数)} \\ \hline
\bold{Denoising Strength} & \textnormal{0.43}& \textnormal{変更をどのくらい許すか(修正強度)} \\ \hline
\bold{Seed} & \textnormal{生成画像から入力}& \textnormal{出力画像の番号} \\ \hline
\end{array}
$$

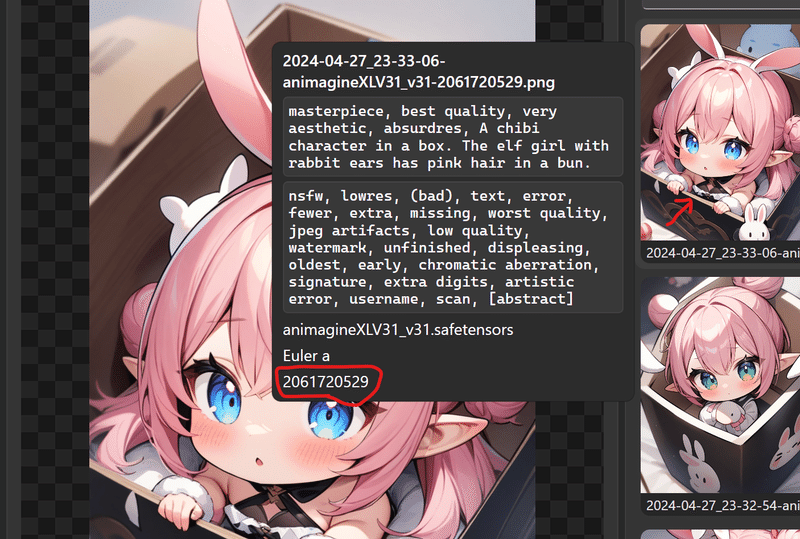
作った画像にカーソルを合わせたりしても出てくるから、これを入れてね
右クリックすると保存フォルダを開いたりExportで保存できるよ。
大きくしたいのは1枚だけだからBatchSizeとかが1になっていることを確認したらGenerate。

最近は元がきれいだからサイズを上げなくても普通に良かったりもするけど

手とか、うさぎの口元とかがよくなってるかな(あと胸の谷間が出来上がってる…)

似たようなの作ったから分からなくなってきた
ここまでできると、自分が作りたいものも作れるわけだから、
3単語くらいでやっている初心者さんと比べたら、
ほんのちょっと上かもしれない(適当)
ということでひとまず今回はここまで。
おまけの説明(後で書き足すかも)
StableDiffusionとは。stability.ai社のモデルです。
StableDiffusion WebUI、ComfyUIなどのUIとは。モデルをコマンドの操作ではなく、各項目に入れるだけなど、使いやすくするデザインされたプログラムのようなものです。
チェックポイントモデルとは。主にStableDiffusionを元にさらに訓練させたモデルです。
XLとは。StableDiffusion1.5系をより進化させたのがXLだけど、処理することも増えたため生成までに時間がかかるようになりました。
LCMとは。Step数が少なく生成でき、生成時間が短いのが特徴のチェックポイントモデルです。
VAEとは。後処理の匠のようなもの。チェックポイントモデル自体に含まれている場合もあります。
DALL・Eとは。OpenAI社のモデルです。モデルの公開はされておりませんが、ChatGPT(有料)やマイクロソフトサイト(無料)で生成することができます。生成サイト:Colpilot(英語:image-creator)
Midjournyとは。Midjournyチームが研究・発表をしているAIイラスト生成です。現在は有料でありDiscord上で生成するため、難易度は高いかもしれない。 英語(ギャラリー:Midjourney)
ここまで見て頂いた方々に感謝してます。

この記事が気に入ったらサポートをしてみませんか?