
Appleによる大規模言語モデル「FERRET」を調査!他のLLMとの違い、性能を完全解説

アップルが開発した「Ferret」という新しい大規模言語モデルを紹介します。これは、画像と言語を組み合わせて理解する能力を持っているMultimodal Large Language Model(MLLM)を基盤としたモデルです。今回はこの「Ferret」に注目していきたいと思います。
「Ferret」の主な特徴は、単純な点や四角だけではなく複雑な形状や線も正確に表現することが可能になった点です。
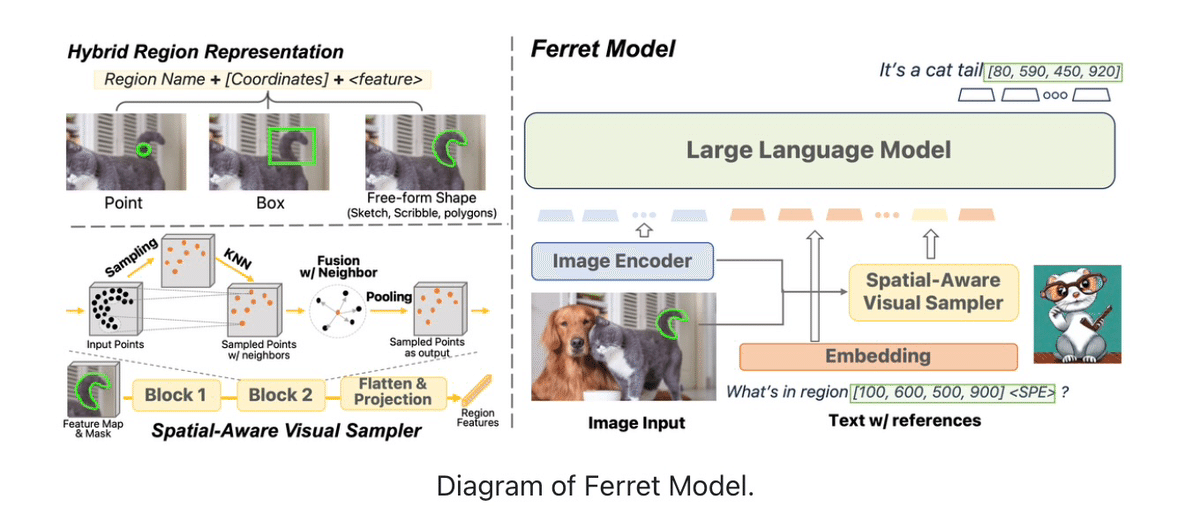
これを「ハイブリッド領域表現(Hybrid Region Representation)」として紹介されています。画像とビジュアルコンテンツ内の特定の領域を効果的に識別し、それらに関する情報を処理するための技術であり、離散座標と連続的な視覚的特徴を統合するハイブリット領域を表現できます。これにより、点、ボックス、自由形式の形状など、イメージ領域を参照する際に柔軟に対応が可能になりました。
空間的な情報を認識し解釈する能力が含まれているので画像内のオブジェクトの位置や関係性をより詳細に理解することができます。
空間認識視覚サンプラーは、画像内の領域やオブジェクトの空間的な位置を理解することで様々な形状やパターンを効率的に認識し、より洗練された画像解析とデータ処理をすることが可能になります。さらに、視覚特徴の抽出により色、形状、テクスチャなどの特徴が取得できます。
またFerretは、画像内の指定されたオブジェクトの領域を組み合わせて理解し、どんな形状でも正確に捉えることができます。このために、General Robust Image Task (GRIT)というベンチマークを使い評価できるようにしていま。
GRITは、110万のサンプルで成り立っていて、物体や場所の関係性などの情報を含んでいます。Ferretが画像内の特定の部分を指し、参照した物体の位置を特定することをより効果的に行うためにデータセットを構築しました。これらの多様な応用により、実用的なアプリケーションにおいてモデルの開発に役立つでしょう。

GRIT データセットは、画像とテキストを組み合わせた多モードのAIモデルにおいて、複雑な空間的関係と意味論を理解し、それらを応用し実世界に適用する能力を向上させるのに重要なリソースとなるでしょう。
同社は、Ferretの性能を評価するために、「Ferret-Bench」というアセスメントツールを開発した。このベンチマークは、画像とテキストを組み合わせた多モードのデータに基づいています。これにより、視覚的情報と言語情報をどのように統合し相互作用させるかを評価できます。
過去の研究やタスクから得られたデータを使用して、Ferret-Benchで既存のMLLMと比較した結果、Ferretは20.4%高い性能を示した。

Ferret-Benchにより、多くの分野でモデル性能を評価し強みと弱みを理解し改善することで、より効率的なアプリケーションを開発することが可能になりそうですね。
Ferretは、参照と基盤化に特化した多モード大規模言語モデルであり、従来のMLLMよりも画像とテキストの統合性に優れており、空間的理解と位置特定に特化しています。ハイブリット領域表現を使い、座標と視覚特徴を融合することで多様な形状の領域を効率的に処理をして、より精密な参照と基盤とタスクを実行することができるようになります。
この記事が気に入ったらサポートをしてみませんか?