[画像生成AI]Stable Diffusionでバリエーションを増やしてみる

1.はじめに
1.1 こんな人向けの記事
・画像生成AIが好きな人
・Stable Diffusion UIを使っている人
・可愛い女の子の顔を作りたい人
など
1.2 狙い
Stable Diffusionは、絵心ゼロの人でもある程度狙った絵を描ける非常に強力なツールですが、いわゆる「AI顔」と呼ばれるような同じような顔が量産される事態に陥ります。これは、単純化して表現すると、学習ベース(統計処理)で画像を生成しているため、ある程度「平均化」された画像が生成されるものと思われます。
そこで、下記動画を真似して、自分の作りたいプロンプトに対して、顔のバリエーションを増やすべく、いろいろ試してみました
1.3 マシン環境
OS: windows10
CPU: core-i5 13500
メモリ: 32GB
GPU: NVIDIA Geforce RTX 4060Ti(16GB)
Anaconda環境でStable Diffusion UI
2.顔のバリエーションを増やす原理
2.1 step数
Stable Diffusionは、画像生成の途中で「今できた絵をキレイにしていくstepを何回か繰り返す」を工程があります。この工程の初期段階では、比較的バリエーションが多く、「原石」みたいな画像が生成されることが多いです。
このstep数はwebUIから指定できます。通常は20step程度に設定して、十分キレイにした画像を出力しますが、このパラメータを意図的に小さくして、「原石」を拾い出すことが可能になります

2.2 CFGスケール
これもwebUIで指定可能なパラメータで、値が高いほどプロンプトに忠実、低いほど独創的な絵になりやすいです。デフォルトは7前後の設定が多いですが、下げていくと、全体的にセピア調のふわっとした雰囲気の絵になることが多いです
図2に、CFGとstep数を変化させた場合の比較画像を掲示します。
・右下(CFG大, step大):同じような図に収束
・左に行く(CFGを下げる):
- 右から離れて個性的な絵になりがち
(特にCFG:1.0は我が道を行く)
- ふわっとした絵になりがち
・上に行く(stepを下げる):ふわっとした絵になりがち
今回は、左側(低CFG)を使います

2.3 サンプラー
これは呪文です。今回はこれを使います

2.4 ControlNet
2.5 Ultimate SD upscale
拡張機能からインストールしてみて下さい
2.6 プロンプト
2.7 モデル(checkpoint)
通常通りでOKです。筆者はyayoi_mix愛好家なので、それ一本で行きます
3.具体的手順
3.1 全体像
以下になります。今回はインストール系の説明が本題ではないので①は省略します。
①Stable Diffusion UI、2.4, 2.5の拡張機能、2.7のモデルを用意する
②プロンプトを決めてガチャを引き、好みの原石を引き当てる
③必要あらば、原石を磨いて好みの画像に調整する
3.2 プロンプトを決めてガチャを引き、好みの原石を引き当てる
今回は、『かすてらを持った悪魔の女の子』を作ってみます。プロンプトは以下に設定します。ネガティブプロンプトはseaArtから拝借しています
masterpiece, (a small piece of square pound cake:1.4)、 Devil costume , 20 year old girl、front、 smile
webUIを下記のように設定します。()内は先に説明した項番です
checkpoint: yayoi_mix (これに限定されません)
サンプリング方法: DPM++ 2S a (2.3)
Schedule type: Karras (2.3)
サンプリングステップ数: 6 (2.1)
幅、高さ: 512×768(とりあえず)
CFGスケール: 2
シード: -1
バッチ回数: 適当に大きな数
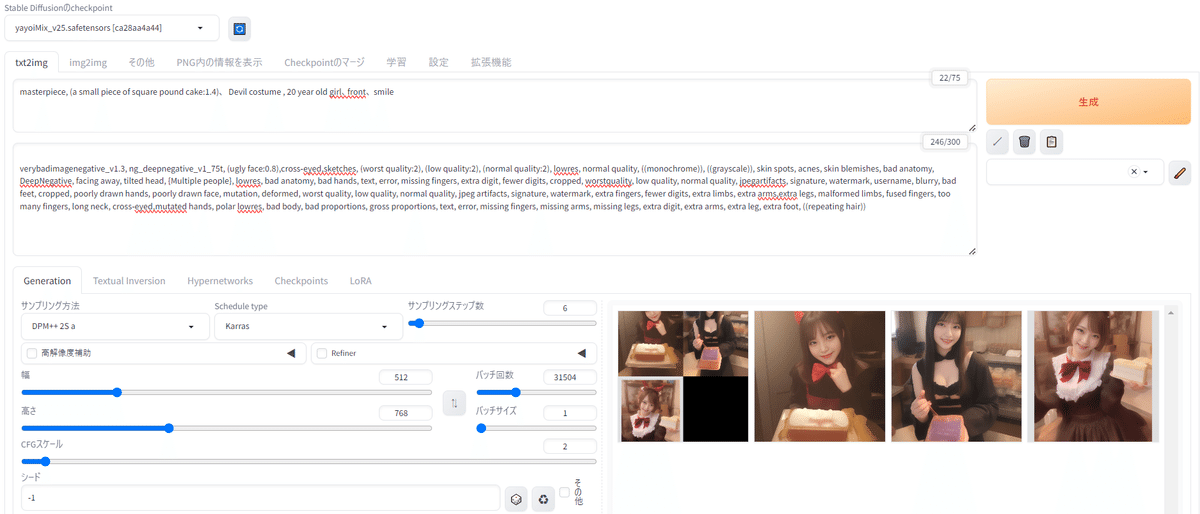
結果、下記のような画像が多数作成されます。この中からお気に入りを探します

3.3 option: 気に入った画像を作成し、Img2Imgに送る
例えば、この画像を磨き上げてみます。シード値は227431231なので、これをwebUIに入力します

webUIのシードにこの値を入力し、バッチ回数を1に戻します。
すると、先の絵が生成されます。これをImg2Imgに送るため、右側に生成された絵の下にある画像アイコンを押します

3.4 気に入った画像を磨き上げる
Img2Imgでは3つの設定を行います
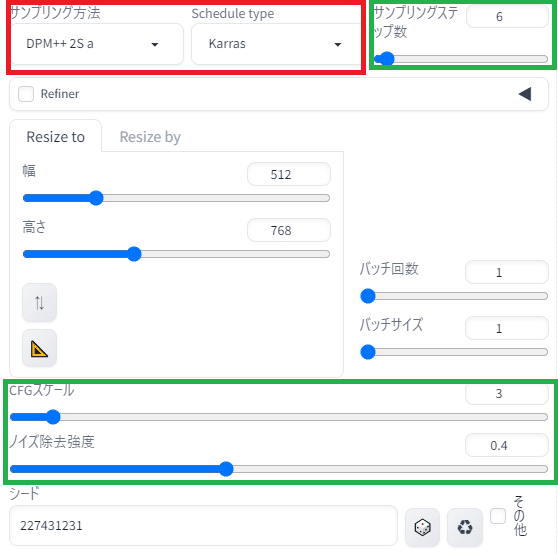
①基本設定
・赤枠は先と同じ設定に
・緑枠は、仕上がりを調整するパラメータです。
『ノイズ除去強度』が重要設定で、まず0.4前後から試します。小さいほど元画像に忠実、大きいほど元画像から変化します。体感ですが、0.7を超えると大きな変化になります。
②ControlNetの設定
有効化されていることを確認。プリプロセッサとモデルを設定します
プリプロセッサは、tile_resampleをとりあえず選びましたが、tile_colorfix+sharpや、tile_colorfixも選択肢です

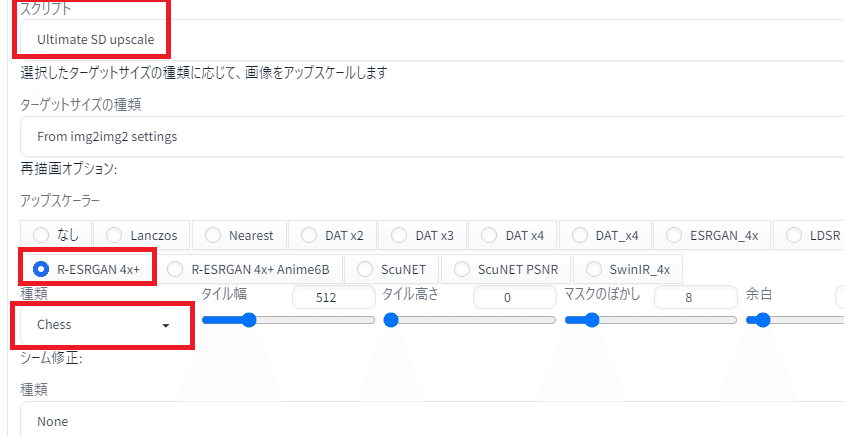
③Ultimate SD Upscalerの設定
スクリプトからUltimate SD upscaleを選びます。選択肢になければインストールしてください。
アップスケーラは、とりあえず下記のように設定しておけば問題ないです
以上、設定できたら「生成」ボタンを押してみます
下記、出来たものの一例です。左がrefine前、右がrefine後(step: 15、CFG:7、ノイズ除去強度: 0.4)。左は全体的にソフト、セピア調でぼかした絵、右はよりカチっとしてディテールが描かれた絵、女の子はお化粧ぱっちりな顔になります。どちらが良いかは好みの問題になってきます。

3.5 出来上がりを調整する
パラメータを変更して好みの仕上がりにします。
「ふんわり」したければ、CFG/step数/ノイズ低減強度 を小さく
「かっちり」したければ、その逆です。step数は20程度入れたほうが幸せになります。
人間の顔以外もこの値の影響を受けるので、お菓子や猫があるときは、適度にふんわりさせるのが良い気がします。
4. おわりに
若干面倒な手順ですが、AI画像で差別化しようとしたら有効な方法だと思います。今後も適宜、いろんな方法を仕入れていきます
この記事が気に入ったらサポートをしてみませんか?