
トヨタの月次をスクレイピング&MySQLにロードしてグラフにしてみる(python)

Python+MySQLを組み合わせるとこんなことが出来ますよって一例です.
まぁデータ集めて色々やるための材料にしてみましょうってことで.
スクレイピングってサーバに迷惑かけちゃうんで,どこのホームページがいいか悩んだけどトヨタの月次にしてみました.ログイン処理が必要なスクレイピングは有料ですがこっちに書きました.
対象はPython始めたはいいもののスクレイピングのやり方がわからないけど,MySQLのインストールは終わってるという居るかわからない奇特な人たちです.MySQLのインストール自体はググれば沢山でてくるので,まぁやってみてくださいな.
以下の流れで説明します.
1.スクレイピングの前準備
2.スクレイピングの考え方
3.MySQLとの組み合わせ
4.コード
5.MySQLであれこれ
1.スクレイピングの前準備
どうでもいいけど,今太字にしたりする方法を知りました.
対象URLの一番上の階層に『robots.txt』を付与して確認してください.
トヨタの月次(http://www.toyota.co.jp/jpn/company/about_toyota/data/)の場合だと,robots.txtのURLは『http://www.toyota.co.jp/robots.txt』になります.
中身なんですが,『User-agent(以下,UA)』が対象のUAを表しており,UAとはGoogleChrome,InternetExplorerなどのアクセスするプログラムのことです.
『Sitemap』はサイトマップ.
『Disallow』はそのUAのアクセスを拒否するURLになります.
トヨタにはないですが『Allow』,アクセスを許可するURLが書かれている場合もあります.あとはUAが*ではなく,UAごとに権限を書いてたりとか.
robotsに対するルールがここに書いてますが,ファイルが無い時もあります.まぁいつもは見ないんですけど.UAも偽装できたりします.
んでpythonですがぴっぴしましょう
『pip install beautifulsoup4』
ウェブから情報を抽出する時だいたいこれ使うんで.
『pip install mysql-connector-python-rf』
pythonでmysql操作しようと思ったらこれ入れときゃいいっす.
2.スクレイピングの考え方
んじゃ考え方に.

生産と販売と輸出があります.2018年のトヨタの自動車生産台数から.

2002年~2018年の情報が取れそうです.んでこういう時は大体最初と最後のレイアウトが変わってなけりゃ同じコードで抽出できます.
2002年の生産.
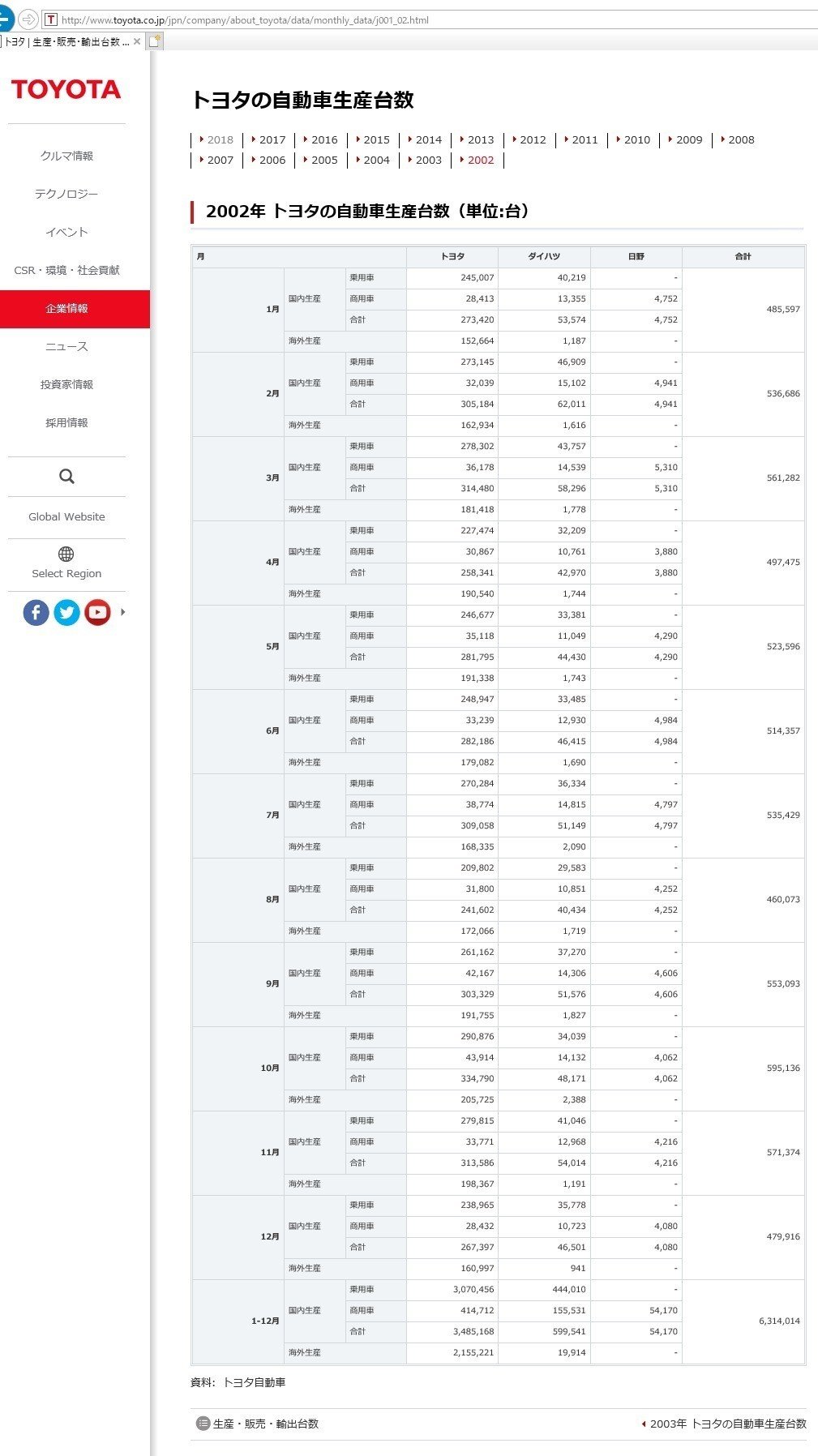
ふぁっく!いつからか世界生産という項目を追加した様で,それ用にコードを書いてやらなければいけなくなりました.2011年を見ると・・・世界生産ない.2012年を見ると・・・あった!2012年からですな.
んじゃ2002~2011年はどう抽出するか考えます.
まずURLですが,『http://www.toyota.co.jp/jpn/company/about_toyota/data/monthly_data/j001_03.html』の『.html』の前の数字が西暦の下2桁になっている様です.
西暦を利用してLOOP文書けば年ごとのURLが作成できますな.
で中身.さっきinstallしたBeautifulSoupがhtmlを解析してタグで分割してくれるライブラリです.んでどこの情報を抽出するかは指示してやんなきゃなので,結局htmlを見る事になります.大抵のブラウザなら右クリックすれば『ソースを表示』って項目があるんで表示させてください.
表の中の数字を抽出したいのでtableを探します.あ,HTMLはどっかで勉強してくだしあ.『tbl_06』ってのがそれっぽいので抜粋したのを整形してドーン!

月ごとの生産合計台数を抽出するとします.
tableは<tr>で一行になってるので,まず<tr>で分割して<td>で好きなとこアクセスって感じでいいかと.んで<tr>1つ目が表全体のタイトル行,2行目が月ごとの国内生産乗用車の行 合計もここにありますな.3行目が月ごとの商用車の行,4行目がそれらの合計行,5行目が海外生産,6行目が2月の~って並びになってる事がわかります.
ってことは2行目から5行ごとに月ごとの合計の情報があって,その情報は<td>3つめっすな.
2012年以降もそんな感じで見るのです.大差ないのです.もう面倒くさくなったのです.販売も輸出も同じなのです.コード書くより説明書く時間の方が長いのです.
3.MySQLとの組み合わせ
んでこの2002年~2018年のデータがドバーッと抽出できたとして毎回Excelなんかに貼り付けたりするのもアホくさいんでDBにぶち込みませう.ソイヤソイヤ!MySQLはインストールしてきてください.ここの『MySQL Community Server』ってのダウンロードしてポチポチすればいいっす.
んでdatabaseとテーブル作っていきましょう.Excelでいうとdatabaseがブックで,テーブルがシートみたいなもんです.微妙な例えですが.

1.『mysql -h127.0.0.1』でローカルのMySQLへ接続
2.『create database toyota_love』でデータベース作成
3.『use toyota_love』で作ったデータベースへ移動?
database名でくらいトヨタに媚びときましょう.作ったdatabaseへチェンジ.
んで生産と輸出と販売のテーブル作りませう.
年月と台数の項目があればとりあえずいいかな.だめかな.いいよ.
/*
月次生産のテーブル
*/
create table t_seisan(
year int,
month int,
car_num bigint,
primary key(
year,
month
)
) character set'utf8';
alter table t_seisan add index t_seisan_idx(
year,
month
);年月がint,台数もintでいいんだけどトヨタ様が狂った成長したら桁あふれを起こすのでbigintにしときましょ.ちなみにintの最大値は2,147,483,647で, bigintの最大値は18,446,744,073,709,551,615らしいです.bigintだと絶対桁あふれしないですな.これで安心.
primary keyってのが主キーと言われるやつで,データは主キーでユニークになる様に作らなければいけません.
『2002年1月300台,2002年1月400台』はN.G.
『2002年1月500台』はO.K.
同じ様に生産,輸出のテーブルも作ります.
/*
月次登録のテーブル
*/
create table t_touroku(
year int,
month int,
car_num bigint,
primary key(
year,
month
)
) character set 'utf8';
alter table t_touroku add index t_touroku_idx(
year,
month
);
/*
月次輸出のテーブル
*/
create table t_yusyutu(
year int,
month int,
car_num bigint,
primary key(
year,
month
)
) character set 'utf8';
alter table t_yusyutu add index t_yusyutu_idx(
year,
month
);ぺたぺた貼り付けてEnter!

4.コード
抽出するやつね.
#-*- coding:utf-8 -*-
from bs4 import BeautifulSoup
from urllib.request import urlopen
import mysql.connector
from time import sleep
import sys
def toyota_daisuki(year):
cur = conn.cursor()
url = "http://www.toyota.co.jp/jpn/company/about_toyota/data/monthly_data/j001_" + year[2:4] + ".html"
html = urlopen(url)
bsObj = BeautifulSoup(html,"lxml")
seisan_table = bsObj.find("table",{"class":"tbl_06"})
i = 1
print("自動車生産台数")
if int(year) < 2012:
for x in range(1,len(seisan_table.findAll("tr"))-4,4):
hoge = seisan_table.findAll("tr")[x].findAll("td")[-1]
month = i
if len(str(month)) == 1:
month = "0" + str(month)
print("+++ %s年%s月 %s台" % (year,month,hoge.get_text()))
i+=1
cars = hoge.get_text().replace(",","")
cur.execute("insert into t_seisan (year,month,car_num) values ('%s','%s','%s')" % ( year,month,cars))
conn.commit()
if int(year) >= 2012:
for x in range(1,len(seisan_table.findAll("tr"))-5,5):
hoge = seisan_table.findAll("tr")[x].findAll("td")[-1]
month = i
if len(str(month)) == 1:
month = "0" + str(month)
print("+++ %s年%s月 %s台" % (year,month,hoge.get_text()))
i+=1
cars = hoge.get_text().replace(",","")
cur.execute("insert into t_seisan (year,month,car_num) values ('%s','%s','%s')" % ( year,month,cars))
conn.commit()
sleep(1)
url = "http://www.toyota.co.jp/jpn/company/about_toyota/data/monthly_data/j003_" + year[2:4] + ".html"
html = urlopen(url)
bsObj = BeautifulSoup(html,"lxml")
touroku_table = bsObj.find("table",{"class":"tbl_06"})
i = 1
print("\n自動車登録台数")
i = 1
for x in range(4,len(touroku_table.findAll("tr"))-3,3):
hoge = touroku_table.findAll("tr")[x].findAll("td")[-1]
month = i
if len(str(month)) == 1:
month = "0" + str(month)
print("+++ %s年%s月 %s台" % (year,month,hoge.get_text()))
i+=1
cars = hoge.get_text().replace(",","")
cur.execute("insert into t_touroku (year,month,car_num) values ('%s','%s','%s')" % ( year,month,cars))
conn.commit()
sleep(1)
url = "http://www.toyota.co.jp/jpn/company/about_toyota/data/monthly_data/j006_" + year[2:4] + ".html"
html = urlopen(url)
bsObj = BeautifulSoup(html,"lxml")
yusyutu_table = bsObj.find("table",{"class":"tbl_06"})
i = 1
print("\n自動車輸出台数")
i = 1
for x in range(4,len(yusyutu_table.findAll("tr"))-3,3):
hoge = yusyutu_table.findAll("tr")[x].findAll("td")[-1]
month = i
if len(str(month)) == 1:
month = "0" + str(month)
print("+++ %s年%s月 %s台" % (year,month,hoge.get_text()))
i+=1
cars = hoge.get_text().replace(",","")
cur.execute("insert into t_yusyutu (year,month,car_num) values ('%s','%s','%s')" % ( year,month,cars))
conn.commit()
sleep(1)
conn = mysql.connector.connect(
host = 'localhost',
user = 'root', # 任意のユーザ
password = '', # そのパスワード
database = 'toyota_love',
charset = 'utf8'
)
for x in range(2002,2019):
seireki = str(x)
toyota_daisuki(seireki)以下がざっくりぼんやりした説明です.
defってのが関数の宣言を意味し,toyota_daisukiってのが関数名.yearは引数.
1.urlは西暦下2桁を利用して作成し,それにアクセス.
2.bsObjってのにbeautifulSoupでタグ分析した結果が入ってる.
3.テーブル部分を抽出した結果を『xx_table(xx:seisan,tourouku,yusyu)』に入れる.
4.for文で該当行を終わりまでLOOPさせながら,欲しい情報が入っている<td>部分を抽出.
5.テーブルにデータ投入
6.1.~6.を2002~2018までループさせる
ちなみに毎月実行して追加のデータのみ取得する様にするなら
try:
cur.execute("insert into t_seisan (year,month,car_num) values ('%s','%s','%s')" % ( year,month,cars))
conn.commit()
except:
passとかにしてエラー起きたら何もしない様にすればいいんかな.
for x in range(1,len(seisan_table.findAll("tr"))-4,4)seisan_table.findAll("tr")の中身はprint(seisan_table.findAll("tr"))してみれば分かるんだけど,<tr>・・・・</tr>までを1単位としてすべて配列として格納してます.
for文で1からその長さ(len)の値までループ,ただし1ずつではなく4ずつ増やしていく.
英語読めたら雰囲気は分かると思うけど,その他の細かい書き方なんかはググってちょんまげ
5.MySQLあれこれ
あ,python実行してねーや.してみよ.
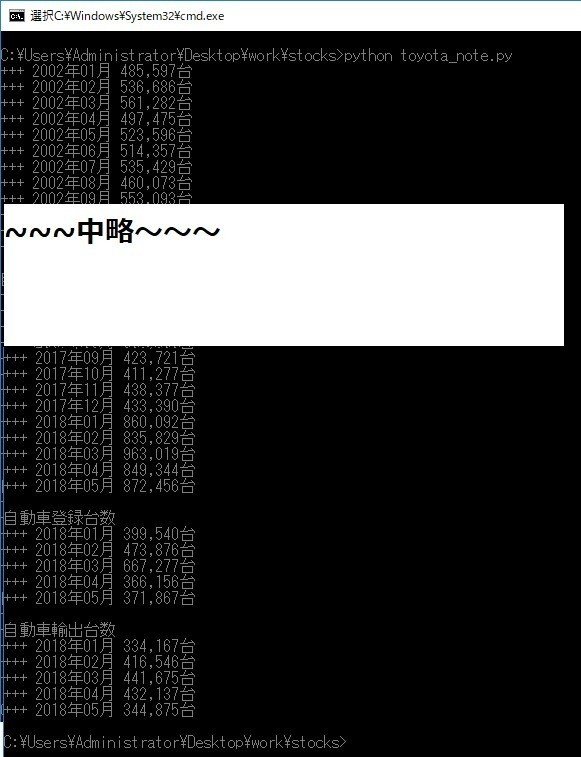
できたー(n‘∀‘)η
テーブルの中身も見ないとな.

全部確認してないけど多分うまく抽出できてるんじゃねーかな(*'ω'*)シランケド
ただこれじゃいちいち確認するの面倒くさいんでviewを作っちゃいましょう.viewってのは同じキー持ってる場合それでデータをくっつけて表示できる様にするもんです.この場合,年月がそれだな.
/*
toyota
*/
create view
t_view
(
year,
month,
seisan,
touroku,
yusyutu
)
as select
s.year,
s.month,
s.car_num,
t.car_num,
y.car_num
from
t_seisan as s
left join
t_touroku as t
on
s.year = t.year and s.month = t.month
left join
t_yusyutu as y
on
t.year = y.year and t.month = y.month
;説明いるか分からんけど.
create view
view名(
カンマ区切りで項目名
)
as select
どのテーブルのどの項目
from
テーブル名 as 別名
left join
くっつけるテーブル名 as 別名
on
どの項目でくっつけるって感じ.
それを実行して,ドーン!

はい,くっついた.外では結合って言うといいよ.
年別にまとめてみる.

2013年から安定して1,000万台超えてんだとかそんな感想がでるんかな.
どうせならグラフにしてみっかー!ってササッと書いたコードがこれ.説明はしないけど大した事してないからググッてくれめんす.
#-*- coding:utf-8 -*-
import mysql.connector
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
conn = mysql.connector.connect(
host = 'localhost',
user = 'root',
password = '',
database = 'toyota_love',
charset = 'utf8'
)
cur = conn.cursor()
cur.execute("select distinct year from t_view")
year = cur.fetchall()
cur.execute("select sum(seisan) from t_view group by year order by year")
seisan = cur.fetchall()
cur.execute("select sum(touroku) from t_view group by year order by year")
touroku = cur.fetchall()
cur.execute("select sum(yusyutu) from t_view group by year order by year")
yusyutu = cur.fetchall()
cur.close()
conn.close()
i=0
year_list=[]
seisan_list=[]
touroku_list=[]
yusyutu_list=[]
for x in year:
year_list.append(year[i][0])
seisan_list.append(seisan[i][0])
touroku_list.append(touroku[i][0])
yusyutu_list.append(yusyutu[i][0])
i+=1
fp_ipa = FontProperties(fname=r'C:/Windows/Fonts/meiryob.ttc',size=16)
plt.rcParams["figure.figsize"] = [12,8]
plt.xlim(year_list[0],year_list[-1])
plt.plot(year_list,seisan_list, label=u"生産台数", color="red")
plt.plot(year_list,touroku_list, label=u"登録台数", color="blue")
plt.plot(year_list,yusyutu_list, label=u"輸出台数", color="green")
plt.grid()
plt.xlabel(u"西暦",fontproperties=fp_ipa)
plt.ylabel(u"台数",fontproperties=fp_ipa)
plt.title(u"なんだろね",fontproperties=fp_ipa)
plt.legend(prop=fp_ipa)
plt.show()で,実行した結果のグラフがこれ.Y軸がオフセット表現になってるけど,まぁいいでしょ.別に困らないし.

2018年はまだ5月までだから無視するとして,安定して伸びてないんだなーって感じ.
で株価も並べてみる.

分かったような分からないような.テーブルにデータ投入で終わらせるつもりがやり過ぎた.もう疲れちゃったのでこの辺で終わり.
この記事が気に入ったらサポートをしてみませんか?