【文系出身初心者】家賃相場を予測してみた

はじめに
持ち家(マンション一室)をそろそろ賃貸に出したいと思い、周囲の家賃相場を調べた上で家賃相場の予測を行ってみました。Mac book air、Jupyter Labを使用しています。
流れ

1.スクレイピングを用いて自動で情報を取得
2.データの前処理
3.取得した情報を元に機械学習モデルを作成
4.作成したモデルを用いて家賃を予測
5.モデルのチューニング
1.スクレイピングを用いて自動で情報を取得
スクレイピングとは、Webページから必要な情報(テキスト、画像、リンクな)を自動で抜き出す作業を言います。人の手でブラウザを開いて情報を収集する手間を省くことができ、大量のデータを集めることができます。
不動産サイトからデータの取得を行います。
ちなみに、Webサイトによってはスクレイピングを禁じていることもあるので、気を付ける必要があります。
サイトの利用規約を確認、今回は私的利用の範囲なので問題ないかと思われます。
第2条 著作権等
1.ユーザーは、本サイトを通じて提供されるすべてのコンテンツについて、当社の事前の承諾なく著作権法で定めるユーザー個人の私的利用の範囲を超える使用をしてはならないものとします。
from retry import retry
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 不動産サイトのURLbase_url = ********************************
def get_html(url):
r = requests.get(url)
soup = BeautifulSoup(r.content, "html.parser")
return soup
all_data = []
max_page = 45
for page in range(1, max_page+1):
# define url
url = base_url.format(page)
# get html
soup = get_html(url)
# extract all items
items = soup.findAll("div", {"class": "cassetteitem"})
print("page", page, "items", len(items))
# process each item
for item in items:
stations = item.findAll("div", {"class": "cassetteitem_detail-text"})
# process each station
for station in stations:
# define variable
base_data = {}
# collect base information
base_data["名称"] = item.find("div", {"class": "cassetteitem_content-title"}).getText().strip()
base_data["カテゴリー"] = item.find("div", {"class": "cassetteitem_content-label"}).getText().strip()
base_data["アドレス"] = item.find("li", {"class": "cassetteitem_detail-col1"}).getText().strip()
base_data["アクセス"] = station.getText().strip()
base_data["築年数"] = item.find("li", {"class": "cassetteitem_detail-col3"}).findAll("div")[0].getText().strip()
base_data["構造"] = item.find("li", {"class": "cassetteitem_detail-col3"}).findAll("div")[1].getText().strip()
# process for each room
tbodys = item.find("table", {"class": "cassetteitem_other"}).findAll("tbody")
for tbody in tbodys:
data = base_data.copy()
data["階数"] = tbody.findAll("td")[2].getText().strip()
data["家賃"] = tbody.findAll("td")[3].findAll("li")[0].getText().strip()
data["管理費"] = tbody.findAll("td")[3].findAll("li")[1].getText().strip()
data["敷金"] = tbody.findAll("td")[4].findAll("li")[0].getText().strip()
data["礼金"] = tbody.findAll("td")[4].findAll("li")[1].getText().strip()
data["間取り"] = tbody.findAll("td")[5].findAll("li")[0].getText().strip()
data["面積"] = tbody.findAll("td")[5].findAll("li")[1].getText().strip()
data["URL"] = "https://suumo.jp" + tbody.findAll("td")[8].find("a").get("href")
all_data.append(data)
df = pd.DataFrame(all_data)df.to_csv("minato-ku_data.csv")データ取得が完了しました。
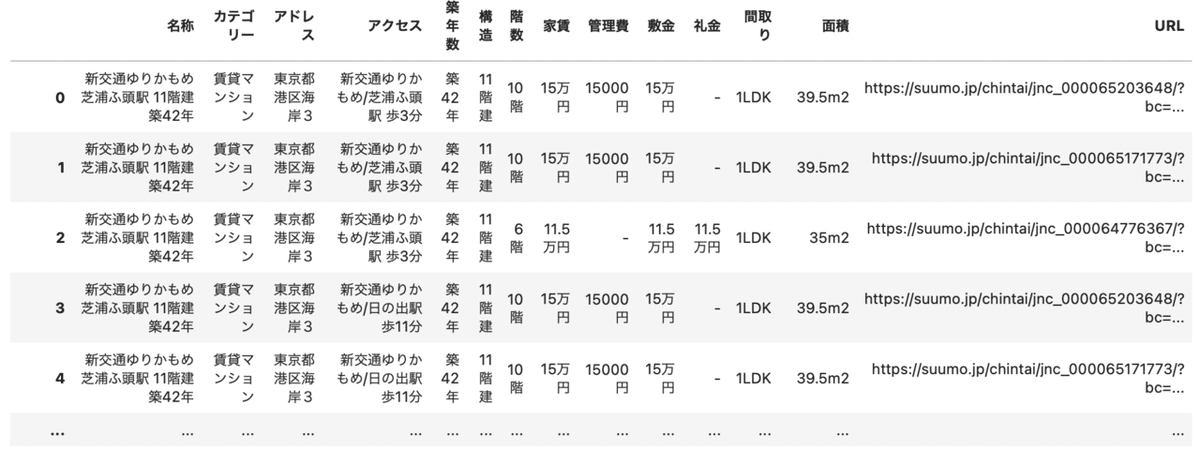
2.データの前処理
余分な文字を削除したり、欠損値の処理などを行っています。
import numpy as np
from sklearn.preprocessing import OrdinalEncoder
from sklearn import preprocessing
import pandas_profiling as pdp
import re
df = pd.read_csv("minato-ku_data.csv", index_col = 0)
#アクセスの欠損値がある箇所は行ごと削除
df.dropna(how = "any", inplace=True)
df.isnull().sum()
#アクセスを最寄駅とアクセスに分割
func_split = lambda x:x.split(" ")[0]
df["最寄駅"] = df["アクセス"].apply(func_split)
func_split2 = lambda x:x.split(" ")[1]
df["アクセス"] = df["アクセス"].apply(func_split2)
#最寄駅の沿線は削除
func_split3 = lambda x:x.split("/")[1]
df["最寄駅"] = df["最寄駅"].apply(func_split3)
#アクセス
func_split4 = lambda x:x.strip("歩分")
df["アクセス"] = df["アクセス"].apply(func_split4)
df['アクセス'] = pd.to_numeric(df['アクセス'])
#築年数
func_split5 = lambda x:x.strip("築年")
df["築年数"] = df["築年数"].apply(func_split5)
df['築年数'] = df['築年数'].replace("新","0")
df['築年数'] = pd.to_numeric(df['築年数'])
#階数
#地下はマイナス、二つの階がある場合下に合わす
func_split6 = lambda x:x.replace("階","").replace("B","-").split("-")[0]
df["階数"] = df["階数"].apply(func_split6)
df['階数'] = pd.to_numeric(df['階数'])
#家賃
func_split7 = lambda x:x.replace("万円","")
df["家賃"] = df["家賃"].apply(func_split7)
df['家賃'] = pd.to_numeric(df['家賃'])
#管理費
func_split8 = lambda x:x.replace("円","").replace("-","0")
df["管理費"] = df["管理費"].apply(func_split8)
#df['管理費'] = df['管理費'].replace("-","0")
df['管理費'] = pd.to_numeric(df['管理費'])
#敷金
func_split9 = lambda x:x.replace("万円","").replace("-","0")
df["敷金"] = df["敷金"].apply(func_split9)
#df['敷金'] = df['敷金'].replace("-","0")
df['敷金'] = pd.to_numeric(df['敷金'])
#礼金
func_split10 = lambda x:x.replace("万円","").replace("-","0")
df["礼金"] = df["礼金"].apply(func_split10)
#df['礼金'] = df['礼金'].replace("-","0")
df['礼金'] = pd.to_numeric(df['礼金'])
#面積
func_split11 = lambda x:x.replace("m2","")
df["面積"] = df["面積"].apply(func_split11)
df['面積'] = pd.to_numeric(df['面積'])
#構造
func_split12 = lambda x:x.replace("階建","").replace("地下1地上","").replace("地下2地上","")
df["構造"] = df["構造"].apply(func_split12)
df['構造'] = pd.to_numeric(df['構造'])
#アクセスの欠損値がある箇所は行ごと削除
df.dropna(how = "any", inplace=True)
df.isnull().sum()
# 管理費(円)と単位を揃える
df['家賃'] = df['家賃'] * 10000
df['敷金'] = df['敷金'] * 10000
df['礼金'] = df['礼金'] * 10000
#管理費は実質的には賃料と同じく毎月支払うことになるため、「賃料+管理費」を家賃を見る指標とする
df['家賃+管理費'] = df['家賃'] + df['管理費']
dummy_df = pd.get_dummies(df[['最寄駅']], drop_first = True)
df = pd.merge(df, dummy_df,left_index=True, right_index=True)
df = df.drop(["名称","カテゴリー","アドレス","間取り","URL","敷金","礼金","家賃","管理費","最寄駅"], axis=1)df = df.reset_index(drop=True)
df = df.reset_index(drop=True)
df.columns = ["access","age","hight","level","area","price","station_1","station_2","station_3","station_4","station_5","station_6","station_7","station_8","station_9","station_10","station_11","station_12","station_13","station_14","station_15","station_16","station_17","station_18","station_19","station_20","station_21","station_22","station_23","station_24","station_25","station_26","station_27"]
df.to_csv("minato-ku_data2.csv")これで、機械学習を行って行きます。
3.取得した情報を元に機械学習モデルを作成
目的変数:家賃 + 管理費
説明変数:築年数、面積、アクセス、最寄駅
Aidemyで習ったモデルをいくつか試してみました。
リッジ回帰、ElasticNet、サポートベクトル回帰、LightGBMを用いています。
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import make_regression
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import Ridge
from sklearn.svm import SVR
import lightgbm as lgb
from sklearn import datasets
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
#import japanize_matplotlib
#目的変数と特徴量に分ける
y = df["price"]
X = df.drop(["price"], axis=1)
# 学習用データと評価用データに分割
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.33, random_state=0)
#リッジ回帰 model_1 = Ridge()
model_1.fit(X_train, y_train)
print("リッジ回帰:{}".format(model_1.score(X_test, y_test)))
#ElasticNet model_2 = ElasticNet()
model_2.fit(X_train, y_train)
print("ElasticNet:{}".format(model_2.score(X_test, y_test)))
#サポートベクトル回帰 model_3 = SVR(kernel='linear', C=1, epsilon=0.1, gamma='auto')
model_3.fit(X_train, y_train)
print("サポートベクトル回帰:{}".format(model_3.score(X_test, y_test)))
#lightGBM lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
lgbm_params = {
'objective': 'regression',
'metric': 'rmse',
'num_leaves':60
}
model_4 = lgb.train(lgbm_params, lgb_train, valid_sets=lgb_eval, verbose_eval=-1)
y_pred = model_4.predict(X_test, num_iteration=model_4.best_iteration)
print("lightGBM:{}".format(r2_score(y_test, y_pred)))
lgb.plot_importance(model, figsize=(10, 5))
plt.show()
リッジ回帰:0.7992224838488775
ElasticNet:0.6895626131275927
サポートベクトル回帰:0.6560673771005368

特徴量の重要度(feature importance)を可視化してみました。
level:階層、age:築年数、area:地域、hight:階、access:駅からの距離、station:港区の各駅、を表しています。
LightGBMが99.49%と一番精度が良さそうでしたので、貸し出し予定の部屋を予測してみました。個人情報が含まれるため、記載はしないですが大体これくらいで貸し出せばいいのかな、という目安になりました。
終わりに
間違ってるところもあると思いますが、データ取得〜モデル作成〜予測と、一通りアウトプットして、良い勉強になりました。
今後、下記もやっていきたいと思います。
・特徴量をもっと増やす
・各駅の居住者年収データを持ってきて、駅ごとに重み付けをする
・年毎の家賃の変化率を算出
今回、プログラミングを学ぶのがほぼ初めてという状況からスタートしたのですが、そんな自分でも簡単なデータ分析ができるんだな、という励みになりました。データ分析については、売上予測など今の仕事でも活かせる部分がありそうなので、実務でも挑戦していきたいと思います。
この記事が気に入ったらサポートをしてみませんか?