
ColabでLoRA学習~PixAI

※2024年3月24日をもってLinaqrufさんのkohya-trainerの更新が終了しました。今後はこちらのcolab notebookをお勧めされております。
この記事はLinaqrufさんのnotebookを元にした記事です。
現在ではエラーが出ると思います。ご了承ください。
時々、PixAIのDiscordでも「誰かLoRAの作り方を教えて」という声を見かけますが、画像を放り込んでクリックしたらできる、という単純な話でもないため、数行のチャットで説明するのは難しいです。
かといって説明しているサイトを紹介しようにも、LoRAはローカル版Automatic1111 WebUIで高速なGPUを使って作成する人が大半で、解説サイトもそちらが中心となっています。GPUを持たないユーザーには手が出せません。
しかしながら、LoRAを使用できるPixAIとGoogle Colaboratoryの組み合わせは、ネットに繋げる事さえできれば誰でもオリジナルのキャラクタや写真を使った画像生成ができ、中々便利だと思います。
そこでGoogle Colaboratoryを使ったLoRA作成の流れを、できるだけ簡略化し、デフォルトのパラメータからあまり触らずに説明したいと思います。
(7月6日版)
教師画像の準備
この記事では二次元イラストを前提として進めます。
学習させたい画像を12枚、JPGで用意してください。
(デフォルトのバッチ数が6なので効率が良いだけです。
枚数が前後しても問題はありません。)
縦横比やサイズはあまり気にする必要はありませんが、
~2000pixel位に抑えた方がよいかと思います。

私は歌声合成ソフト Synthesizer Vの動画で使う画像を作るのに色々LoRA化していますが、その中の一人、無料バージョンしか持ってませんが花隈千冬さんで試してみたいと思います。
公式サイトにMMDモデルがあるので、これを使わせていただきます。
TOKYO6 ENTERTAINMENT 公式サイト

一度全身像も何枚か入れたのですが、さすがに学習できず、失敗しました。はじめは上半身に絞った方が良いと思います。
作り方に慣れたら枚数を増やして全身入れていきましょう。
ZIPファイルにまとめてGoogle Driveにアップロードします。
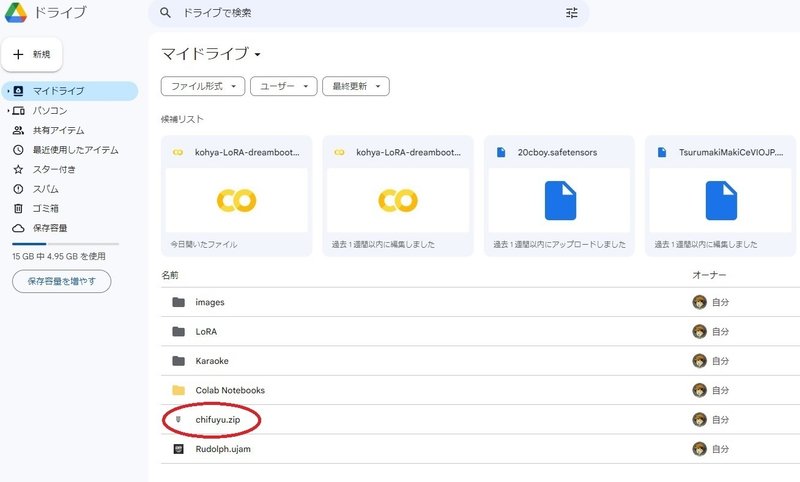
Colab用Kohya-Trainerをコピー

https://github.com/Linaqruf/kohya-trainer
上記URLへ飛び、一番上のKohya Lora Dreambooth、
Open in Colabのリンクをクリックして開きます。

ジュピターノートブックが表示されます。
「ドライブにコピー」をクリックして、自分のドライブに保存します。
新たに「kohya-LoRA-dreambooth.ipynb のコピー」というタブが起動しますのでそちらを使います。古い方のタブは閉じてください。

ジュピターノートブックはプログラムコードを実行する環境を提供する物です。基本的に左上のボタンを、上から順に実行していきます。

グーグルドライブのマウントとビルド
初期状態では自分のグーグルドライブに読み書きする事はできません。
mount_driveにチェックを入れ、ボタンをクリックして実行します。

右上のステータス表示が変わりランタイムに接続されます。
このような表示が出ますので、アカウントを選択して許可してください。


左のフォルダアイコンでノートブックのフォルダが確認できます。
drive>MyDrive が自分のグーグルドライブになります。
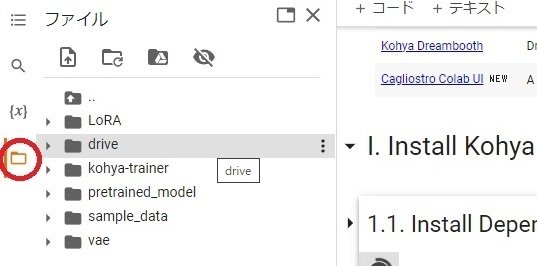
その他、このセクションは必要なファイルをダウンロードしてビルドするのに5分ほどかかります。
1.2. Start File Explorer は使いません。スキップします。
学習に使うモデルのダウンロード
デフォルトのAnyLoRAを使います。このまま実行してください。

2.2~2.3はスキップします。
3.1 トレーニングデータの入るディレクトリの指定。このまま実行します。
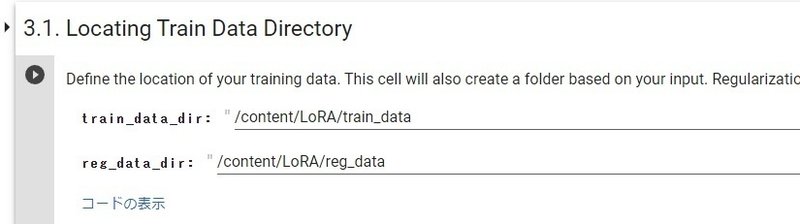
zipファイルの解凍
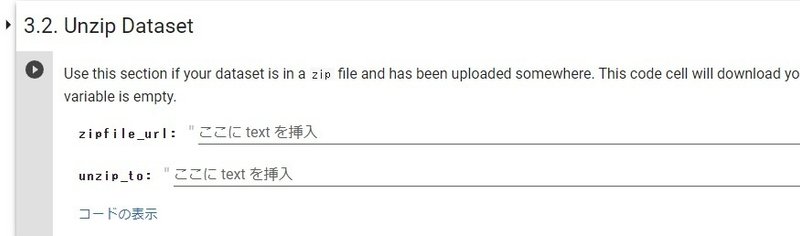
再度、左のファイルツリー「drive>MyDrive」が自分のグーグルドライブのトップとなっています。
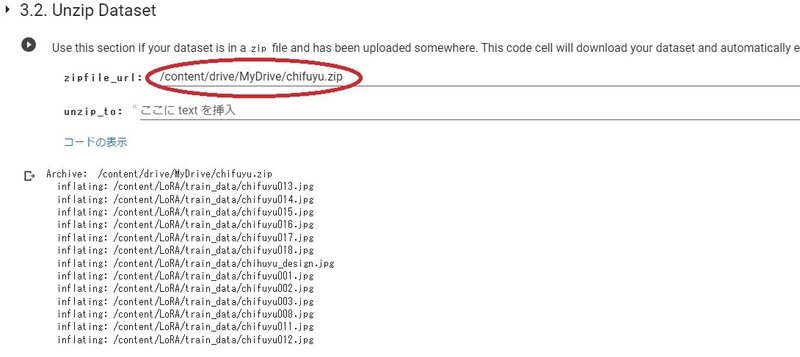
自分がアップロードしたzipファイルを見つけて、右クリックメニューで「パスをコピー」して上のzipfile_urlにペーストします。
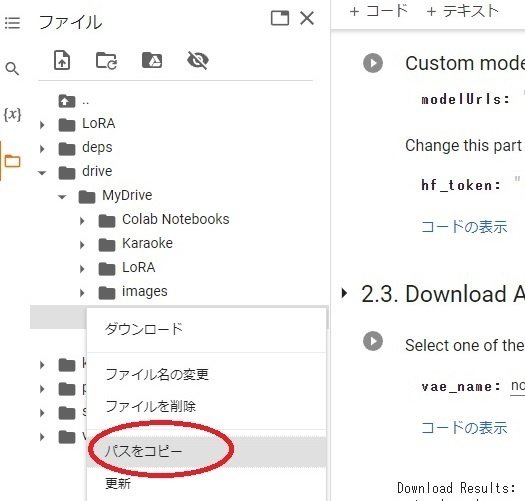
ドライブのトップに保存した場合
/content/drive/MyDrive/〇〇〇〇.zip となります。
3.3. ~ 4.1. はスキップ
タグの剪定
4.2.1はスキップしてください。
BLIPとWifeDiffusion Taggerと2種類あるのですが
Taggerでタグを整理したいと思います。
まず、4.2.2をデフォルト値で実行します。

それぞれの教師画像の説明、
キャラクターや背景に関する単語がずらっと出てきます。
1girl,long hair,school uniform,・・・
これらの中から学習させたい要素をundesired_tagsに加えていきます。
このセクションを再度実行するとそれらのタグが除去されます。
つぎのセクションで「花隈千冬」というキャラクタータグを加える事により、削除した「黒い髪」「眼鏡」「制服」といった特徴タグを「花隈千冬」というキャラクターに集約します。
表情・ポーズ・背景を消す必要はありません。

4.2.3 custom_tag に キャラクタ名などトリガーとして使う名前をいれます。

モデル設定
project_nameに作成するLoRAの名前を記入。ファイル名になります。
output_to_driveにチェックして、実行します。

5.2.そのまま実行。

5.3.そのまま実行

学習の設定
デフォルトで実行

学習開始
学習を開始する前にサンプル出力のプロンプトを変更しておきましょう。
デフォルトだと野球帽をかぶったTシャツの女の子が出てきます。
sample_promptのリンクをクリックすると画面左にテキストが開きますので書き換えてください。
masterpiece, best quality, 1girl, aqua eyes, baseball cap, blonde hair, closed mouth, earrings, green background, hat, hoop earrings, jewelry, looking at viewer, shirt, short hair, simple background, solo, upper body, yellow shirt --n lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry --w 512 --h 768 --l 7 --s 28masterpiece, best quality, 1girl, hanakuma chifuyu, solo, upper body --n lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry --w 512 --h 768 --l 7 --s 28
実行すると1エポック毎にグーグルドライブの
/LoRA/output/sample/ フォルダに画像が出力されます。

出力のテスト
VI. Testing 以降で出力テストができますが、正直私は使っていません。
特にPixAIなどはデフォルトで使えるのがオリジナルモデルで、配布はされていないため、実際にLoRA登録して出力してみた方がわかりやすいと思います。
ランタイムの切断
作業が終了したら、セッションの管理でセッションを終了しておきましょう。
PixAIでのLoRA登録。
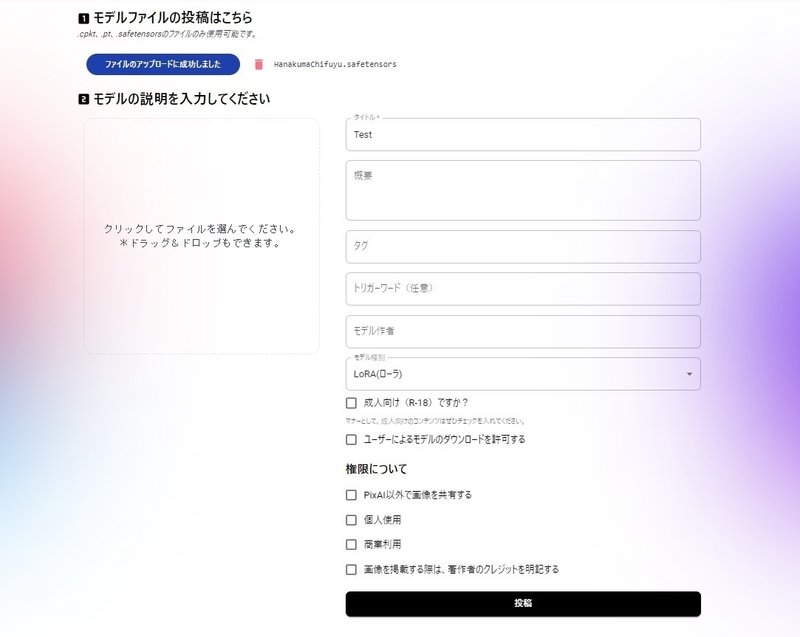
・サムネイルを設定しないと登録できません。他人に見られたくない場合には512pix × 768pix の白紙画像でも入れておきましょう。
・なぜか登録後もファイルのアップロードができるのですが、差し替えはできません。バージョンアップする時は新規に登録する事になります。※8月19日追記
LoRA、モデル複数バージョンをアップできるようになりました。
・サムネに設定する画像によってはR-18に誤判定されてしまいます。
アートワークと違って自分では修正できなくなってしまいます。
PixAIの設定をR-18設定にしてない人からは見えなくなるなど不便ですので、最初は白紙等でサムネ登録して後からサムネの差し替えをする事をお薦めします。
PixAI、Luxで出力してみました。
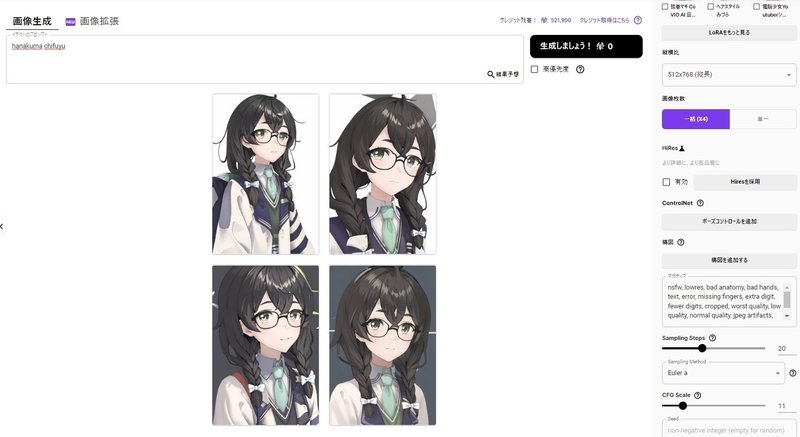
細かい説明、こうした方がいいという部分はあるのですが、
全部書くと2~3倍の量になってしまいますので、できるだけ流れがわかるようにと略しました。
LoRAの作り方として正解でも最適解でもありません。
そこはご了承ください。
この記事が気に入ったらサポートをしてみませんか?