
Img2Imgで元画像に似せた絵を描く

事の発端
普段、尋ねられてもいないのに進んで他人に何かを教える事はしてないのですが、たまたま他人に説明する機会があったので、せっかくなのでまとめてみます。(Stable Diffusion webui / Automatic1111版前提です)
元は合成音声、CeVIO使いの仲間たちの会話
秋はぬくぬく・・其の肢体豊満にして
— のすじい(おっホイカバー隠居戯れ絵じじい) (@tubaman14) October 13, 2022
何処となくあどけなきは言う術(すべ)もあらず。
容貌幼げでこころ無垢ならば勝るものなし。
枕草子もじって呟く親父の戯言、
枕絵草子とでも名付けて全編もじって
絵を付けて放流しようか春はあけぼの(笑) pic.twitter.com/9YLba1T4VE
こちらのイラストを元にAIによる画像生成を行いました。
— ただの隠居人 (@asty2000) October 15, 2022
現在の技術では、のすじいさんの絵は、のすじいさんしか描けないのでしょう。 pic.twitter.com/oaDVwwmnkB
・・・ちょっと待って、ちょっと待って。
それって「AIが色鉛筆で描いた女の子」ってだけの話で、のすじいさんの元絵は関係ないやん。その程度の認識で冗談でも「現在の技術」なんて語るのはさすがにやめて欲しい。開発者の方々に対しても凄く失礼だし、私らユーザーとしてもそんな単純な話のために試行錯誤してる訳じゃない。
以前、さとうささらをAIで描いてみようなんて遊んでたので、そういうノリなのでしょうが。

そんな訳で、今回はtextual inversion のようなモデルの学習は使わず、Img2Imgだけでどこまで元絵を残したまま別の画像にできるか試してみようと思います。
デノイズによる変化
以前映画「ダーククリスタル」の画像をイラスト調にできないかと試行錯誤してました。

この数値の変化による比較画像は、スクリプトのX/Y plot で作成できます。

画像生成AIはノイズを元に画像を作成し、ノイズが細かいほど元の絵に忠実になります。デノイズというのはそのノイズを削減する処理です。
BlenderのCyclesのようなレンダラーにもデノイズ処理は入ってますので聞きなれた方も多いでしょう。
同じ処理をのすじいさんの画像でやってみます。
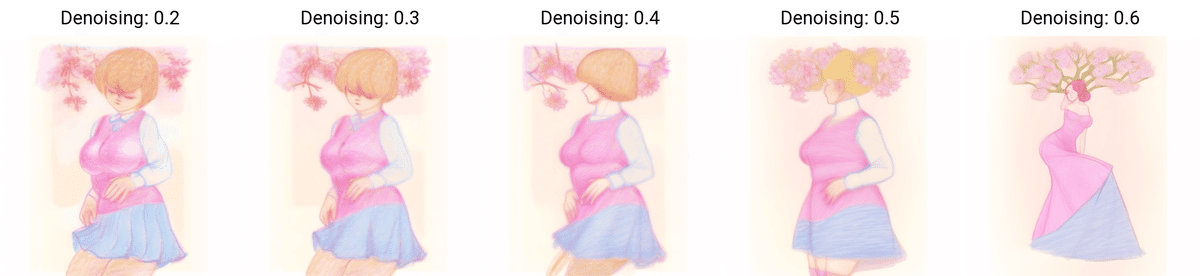
使う人の判断によりますが、元絵はのすじいさんの絵だと判別できるのは0.3ぐらいかなぁっと。
その上で、CFG Scale (プロンプト・呪文の強度)をMAXまで上げて、
プロンプトにplaying guitar、japanese kimono など書き換えると下記のように。
元絵の影響力残ってる所を見極めてプロンプトで物持たせたり、服変えたり。描き足さなければこんな感じ?
— マーマレード@男爵 (@Baron_Marmalade) October 15, 2022
膝上のショットなのに顔のアップになってる時点で「AIが色鉛筆スタイルで描いた女の子」ってだけの話で、のすじいさんの元絵はほとんど関係ないですやん。 pic.twitter.com/ONI6kxhUtv
さらに、元絵に何かを描き足して生成すればまた違う物もできるでしょうが、今回はやりません。
ついでに
反対に先日、自分の絵のキャラクター属性だけを残して別のタッチに変えてみる実験をしていたので。
この場合はいかにプロンプトでキャラクターの特徴を説明するかが重要なので、デノイズとかCFG Scaleとか気にしなくても良いでしょうが。
右の4つはCFG Scale上げているのでポーズ・構図もガン無視。

ゆるキャラやマスコットぽい画像って・・・
で、人型はいいのですが、こういった擬人化したマスコットって作ってみると難しいんですよね。画家AIでご当地キャラなどのゆるキャラを中心にやっている人って誰かいるだろうか?
なぜだか、ポケモンっぽい画像ばかりになってしまう

この記事が気に入ったらサポートをしてみませんか?