
ComfyUI で複数キャラLoRA

Automatic1111版での Latent Couple, Composable LoRA 的な事。
画像のロボット君と少年は別々のLoRAで、インペインティングで
ロボット君を描き直しています。足元の影がなかったりしますが。

インペイント前の元絵がこうだったり
LoRAが混じってしまい、大半が人造人間となってしまいます。
ある程度枚数を作ったらLoRAを作り直そうとは思っているのですが、
暫定的な処置。

インペイントも思った形のロボットが中々出なかったり、本当は少年に虫眼鏡を持たせたかったのですが、それすら中々描いてくれなかったり。
何度も出力していると、「あれ?ラフで描いた方が早くね?」
一応、同時進行でスクリブ機能を使ってスケッチから起こしたり、と色々なアプローチで試してはいます。
その中で、ComfyUIで Automatic1111版での Latent Couple, Composable LoRA 相当の機能を探ってみようと。
検索してみるとRedditに下記のようなサブレが。
https://www.reddit.com/r/comfyui/comments/15idm8k/help_connecting_multiple_loras_to_same_ksampler/
Inuya5haSama氏がワークフローを貼られています。
同じようにやってみます。

・普通はLoRAを直列に繋ぎますが、今回は並列に。
それぞれにCLIP TEXT Encode(Prompt)をつけます。

この時のプロンプトですが、AND表記にすると
masterpiece, best quality, 2girl, beach,
AND 1girl, satou sasara
AND 1girl, suzuki tsudumi
うちはこれで安定していますが、人によって分割エリアの方にも2girls入れたりしているみたいで正直わからないです。
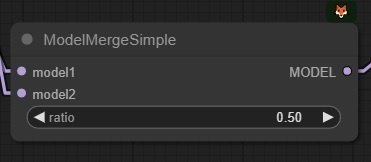
・modelは標準ノードのModelMergeSimpleで ratio 0.50 でマージ。
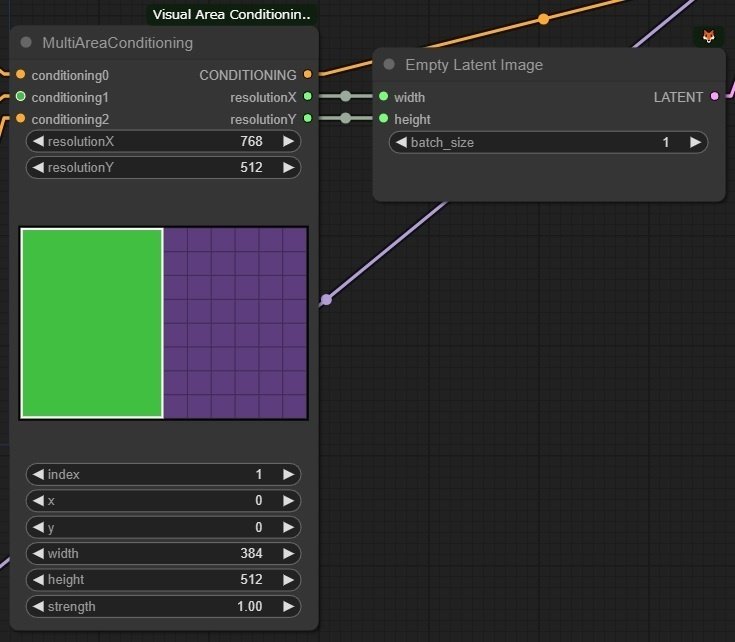
エリア指定に使っているのは Davemane42 さんのカスタムノード
Visual Area Conditioning / Latent composition から MultiAreaConditioning

右クリックメニュー、insert input で領域の数を増やせます。
indexを切り替えて領域の位置、サイズ、強度を調整します。

index 0, 全体のプロンプト
index 1, 左のキャラクタのプロンプト
index 2, 右のキャラクタのプロンプト
に繋ぎます。
右は解像度をEmpty Latent Image の width , height を切り替えて接続。

と、簡単にできているように見えるのですが・・・
実は最初 Youtuber シロさんとアカリさんでやっていたら結構混ざる&
衣装パーツが欠ける・・・


LoRAの学習率による物なのか(つづみさん以外はほぼ同時期作成)
衣装の複雑さによる物なのか。
次にエリアの strength による違いなどをもう少し調べたいと思います。
そちらを書いてたのですが、ちょっと長くなったので。
この記事が気に入ったらサポートをしてみませんか?