【ローカルLLM】Llamaモデルのコンテキスト拡張について整理する

「LLongMA 2」という長いコンテキストに対応したLlama-2派生モデルが話題になっていたので、Google Colabで試した。
特徴は以下の通り。
Llama-2の7BベースモデルをRed Pajamaデータセットを利用して学習。
8Kのコンテキスト長に対応させてトレーニング。
4K超の長いコンテキストでもパフォーマンスを維持する(下図参照)
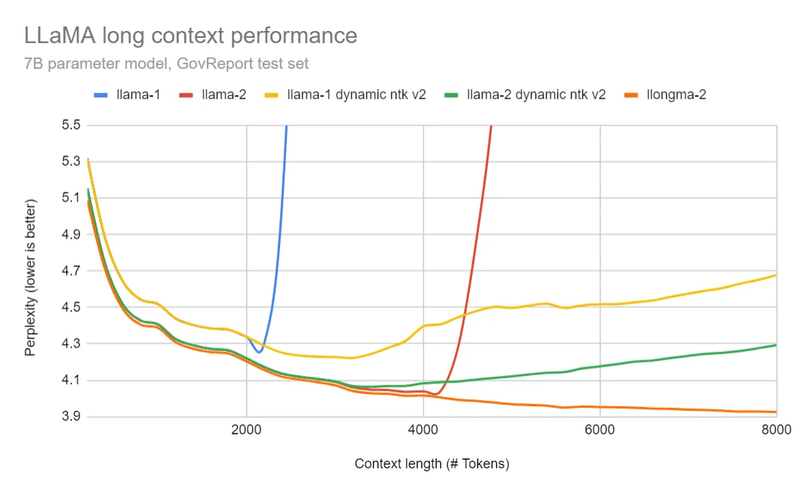
コンテキストが伸びてもPerplexity(当惑度)が反転増加しない
Llamaのコンテキスト拡張の整理
そもそもLlamaのコンテキスト拡張の使い方がいまいち分からないので、情報を整理してみた。
モデル本来のコンテキスト長:もともとLlama-1では2048トークン、Llama-2では4096トークンが上限。これを超えると、先ほどの図の青線・赤線で示されるようにパフォーマンスが急速に悪化してしまう。
"compress_pos_emb"によるコンテキスト拡張:6月下旬に「SuperHOT」なる技術が現れ、GPTQローダーのExllamaにも実装された。これにより"compress_pos_emb"というパラメータを調整することでコンテキストを拡張できるようになった。これはLlamaモデル全般に有効だが、長いコンテキスト用に微調整したモデルに使うのが望ましい。
"alpha_value"によるコンテキスト拡張:7月に入って「NTK RoPEスケーリング」と呼ばれる別の拡張手法が提案された。先の図の黄・緑線にあたる。正確には"Static NTK"と"Dynamic NTK"があるようで、前者がExllamaに実装されている。NTK RoPEでは"alpha_value"パラメータを操作する。同じく8K超のコンテキストに対応し、Llamaモデル全般に適用できる。
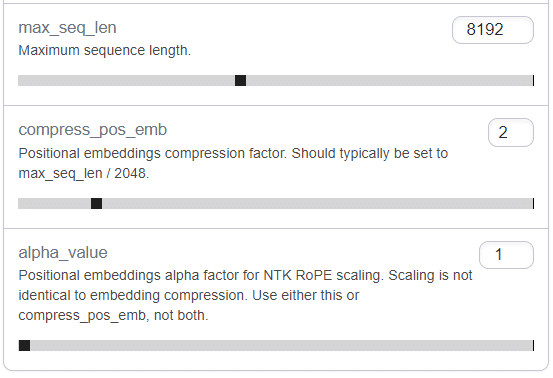
こういう経緯で、Exllama/text-generation-webUIでコンテキスト長を広げる場合は"compress_pos_emb"と"alpha_value"の2つのパラメータが存在する。おおまかに言うと、長いコンテキストで追加学習済みのモデルでは"compress_pos_emb"、そうでないモデルでは"alpha_value"を調整してコンテキストを拡張するのが推奨される。
Llama.cppにおけるコンテキスト拡張:「Llama.cpp」においても、同等のコンテキスト拡張手法が"Custom RoPE"として実装された。llama-cpp-pythonとtext-generation-webUIもサポート済みらしい。よって、GPTQだけでなくGGMLでもコンテキスト拡張を適用できるようになった(はず)。素のLlama.cppでは、コマンドラインパラメータに「-c 8192 --rope-freq-base 10000 --rope-freq-scale 0.5」等と指定して使う。Exllamaのパラメータとは以下のように対応する。なんか面倒くさi。
・ rope-freq-scale = 1/compress_pos_emb
・ rope-freq-base = 10000 * alpha_value ^ (64/63)
これらのコンテキスト拡張はTransformersでも対応している。それ以外のAutoGPTQやGPTQ-for-LLaMAでは使えなさそう。
Google ColabでLLongMA 2 を試す
Google Colab上で「LLongMA-2-7B-GPTQ」をダウンロードし、text-generation-webuiで試した。8Kコンテキストで会話してもGPU RAM 9GBくらい、フリーのColabで問題なかった。
#Text Generation WebUIのインストール
!git clone https://github.com/oobabooga/text-generation-webui
%cd text-generation-webui
!pip install -r requirements.txt
#モデルのダウンロード
%cd /content/text-generation-webui
!python download-model.py TheBloke/LLongMA-2-7B-GPTQ
#WebUIの起動
!python3 server.py --chat --share --loader exllama --max_seq_len 8192 --compress_pos_emb 2 --model TheBloke_LLongMA-2-7B-GPTQ 上記の通りmax_seq_len(コンテキスト長) = 8192、compress_pos_emb = 2で実行。「LLongMA 2」は長いコンテキストで追加学習したモデルなので"alpha_value"ではなく"compress_pos_emb"を使うのがよい。
なお"compress_pos_emb"の数値は「拡張後のコンテキスト長 ÷ 本来のコンテキスト長(Llama-2なら4096)」を目安に設定する。"alpha_value"を使う場合も基本的には同じ目安でよいとのこと。どちらもデフォルトは1。
あと(たぶん変えなくてもよさそうだが)WebUIのParametersタブにある「Truncate the prompt up to this length」も一応8192に上げておく。
使用実感
前回同様、MetaのLlama 2論文から約8000トークン分の文章を切り出してコンテキストに放り込み、その内容について「LLongMA-2-7B-GPTQ」に質問してみた。
試した範囲では、コンテキストをおおむね問題なく参照していて、すぐに気づくレベルの大きな幻覚は無い。
比較のため「Llama-2-7B-Chat-GPTQ」を8Kコンテキストで試すと、前回の16Kのケースと同じく、論文タイトルを間違えて答えるなど分かりやすいミスがすぐ起こる("compress_pos_emb"でも"alpha_value"でも特に違いは見られない)。なので、確かにLLongMA-2のファインチューンの効果はありそう。
なお「LLongMA-2」では、13Bモデルのリリースや16Kコンテキストへの対応も近日予定しているとのこと。