
日本語LLMのベンチマーク:「JGLUE」と「Rakuda Benchmark」

LINEの「japanese-large-lm-instruction-sft」リリースに関する公式ブログで「Rakuda Benchmark」という日本語LLMベンチマークがモデルの性能評価に使われていた。
これまで日本語LLMのリリースでよく見たのは「JGLUE(日本語一般言語理解評価)」というベンチマーク。何が違うのか簡単に調べてみた。
JGLUE(日本語一般言語理解評価)
「JGLUE」は、早稲田大学とYahoo! JAPANが構築・公開したベンチマーク。
ベンチマークの具体的な構成については、以下の記事に詳しい。
この「JGLUE」のスコアでLLMの日本語性能をランク付けしたリーダーボードには、「Nejumi LLMリーダーボード」や、Stability AIによる「JP Language Model Evaluation Harness」がある。
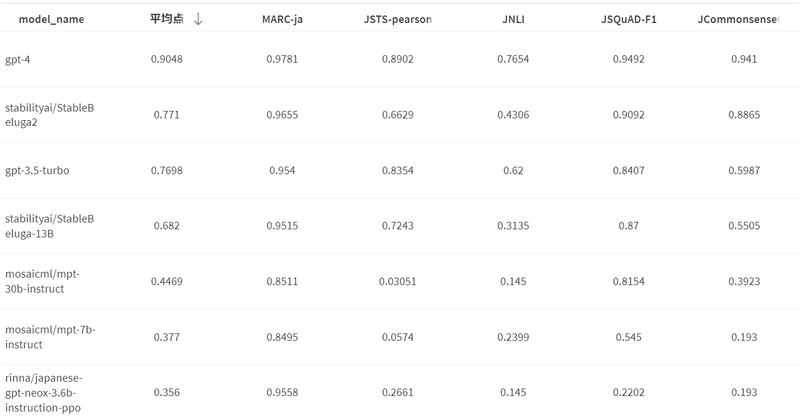
「JGLUE」では、LLMに短答式・多肢選択式で問題に回答させ、それを機械的に採点する方式をとっている(大学共通テスト/センター試験のようなイメージ)。
英語ベンチマークでも「MMLU」など似たタイプのベンチマークがあるが、この方式ではモデルの文章生成能力は測定できない(ライティングやコーディング、要約などのタスク性能が測れない)という短所がある。
Rakuda Benchmark
「Rakuda Benchmark」はYuzuAIという有志グループが考案・運用しているベンチマーク及びリーダーボード。
「JGLUE」とは違い、自由回答形式のOpen QAでモデルに質問し、その出力テキストをGPT-4によって評価させる手法をとっている。
このようなGPT-4を評価者としたベンチマーク手法は、英語LLMでは「MT-Bench」や「AlpacaEval」が有名。
Rakuda Benchmarkによる評価:

Nejumi LLMリーダーボード(JGLUE)を見比べると、例えばLlama2-70B(StableBeluga2)が相対的に低く、ja-stablelm-instruct-alpha-7bは相対的に高く評価されている。
Rakuda Benchmarkの方が、モデルのパラメータサイズの違いをより素直に反映した順位になっているように見える。
ただし、このようなGPT-4を用いた評価手法には、「冗長な(テキストの長い)回答を高く評価しやすい」「GPT-4/GPT-3.5の回答を高く評価しやすい」といった問題点がよく指摘される。
人手による評価
本来であれば、人間による出力評価がモデルの性能を計るのに最適だが、人手に頼るのは基本的にコストが嵩むという問題がある。
海外では、LMSYSによる「Chatbot Arena」が人間によるテキスト評価のプラットフォームとして運営されており有名。
なお、冒頭で言及したLINEの公式ブログでは、人手での性能評価についても紹介されていて、「Rakuda Benchmark」の傾向と一部食い違う結果が出たとしている。
ベンチマークはあくまで参考であり、自分が実際に利用する用途で性能を確かめるのが大切(だが面倒でもある)。