映画レビューサイトに投稿されたコメントのポジティブ/ネガティブを分類してみた

自然言語処理(Natural Language Processing)を用いて、映画レビューサイトのコメントをポジティブ/ネガティブ分類してみました。あまり綺麗なプログラムではないですが、少しでも参考になれれば幸いです。
開発環境
Google Colaboratory
ソースデータ元
大まかな流れ
上記映画レビューサイトからデータ収集
収集したデータの整形
モデル構築
分析、考察
1.上記映画レビューサイトからデータ収集
ソースデータはcocoという映画のレビューサイトを利用します。例えば以下の映画レビューのページに推移すると、ページ下部に「coco映画レビュアーの感想」というセクションがあり、こちらのテキストデータを収集していきます。
また、レビューに付随して「良い」「普通」「残念」の評価値が設けられておりますのでそちらを正解ラベルとして活用したいと思います
Webページからのデータ収集にはWebスクレイピングという手法を使います。WebスクレイピングとはWebサイトから情報(テキスト、画像、リンクな)を抽出する作業で、BeautifulSoupやrequestsといったライブラリを利用します。
import time
import requests
from bs4 import BeautifulSoup
from tqdm import tqdm
#Webページの取得
def parse_url(url, sleep_second=1):
res = requests.get(url)
time.sleep(sleep_second)
return BeautifulSoup(res.content, "html.parser")
parse_url("https://coco.to/movies")
# 収集する映画のフィルタリング
def should_crawl(score, upper_score=90, lower_score=10):
return lower_score <= int(score.replace("%", "")) <= upper_score
# URLを構築するための変数
domain = "https://coco.to/"
prefix = "movies/%s"
current_year = 2022
n = 15
checked_urls = list()
for i in range(n):
# 2008年から2022年の映画一覧ページを取得
movie_list_url = domain + prefix % (current_year - i)
soup = parse_url(movie_list_url)
print("抽出開始", movie_list_url)
# ページからスコアでフィルタした作品URLのみを抽出する
for panel in soup.find_all("div", class_="li_panel"):
score = panel.find("div", class_="li_txt").text
if should_crawl(score):
uri = panel.find("a")["href"]
checked_urls.append(domain + uri)
print("抽出終了", movie_list_url, "取得済みURL", len(checked_urls))
print("先頭の5つを表示", checked_urls[0:5])こちらを実行すると各年における映画のレビューページURLを取得します。

一番下にURLを5つ表示させておりますので、こちらから正しいページにアクセスできるか確認してみます。

問題なさそうなので次の処理に進みます。
crawled = list()
for url in tqdm(checked_urls):
# データの取得
soup = parse_url(url)
texts = soup.find_all("div", class_="tweet_text clearflt clearboth")
labels = soup.find_all("span", class_="judge_text")
title = soup.find("div", class_="title_").find("h1")
#取得したデータの解析
for t, l in zip(texts, labels):
text = t.get_text(strip=True)
metadata = t.find("span").get_text(strip=True)
stripped_text = text.replace(metadata, "").strip()
article = {
"text": stripped_text,
"label": l.get_text(strip=True),
"title": title.get_text(strip=True),
}
crawled.append(article)
print("全URLの取得完了")上記では各映画レビューサイトから
text(レビューコメント)
label(良い、普通、悪いの評価)
title(映画のタイトル)
を取得しております。筆者の実行環境では10分ほど時間がかかりました。
実行が終わりましたらdataframe型に変換して中身を確認してみましょう。
import pandas
df = pandas.DataFrame(crawled)
display(df)
無事取得できているようです。こちらでデータ収集のパートは完了です。
2. 収集したデータの整形
今回はコメントの内容からポジティブ/ネガティブを自動分類することが目的のため、正解ラベルである "label"は「良い」or「残念」のみ利用することにします。
*学習にメリハリをつけるため評価が「普通」のデータは除外
filtered_by_label = df.query("label == '良い' | label == '残念'")
display(filtered_by_label)
かなりデータ数が減りました。labelが"良い"と"残念"でそれぞれどのくらいのデータが存在するか確認します。
group_by_label = filtered_by_label.groupby("label")
labels_size = group_by_label["title"].count()
display(labels_size)
「良い」のほうがデータ数が多いことが確認できました。学習させる際は「良い」「残念」のデータ数を合わせるため、「残念」のデータ数(1210行)分、同数の「良い」データをランダムに抽出します。
n = labels_size.min()
print(n)
dataset = group_by_label.apply(lambda x: x.sample(n, random_state=0))
display(dataset)
dataset.count()
計2420行のデータを準備できました。
次に「label」の良い/残念をラベルエンコーディングをします。
from sklearn.preprocessing import LabelEncoder
label_vectorizer = LabelEncoder()
# 残念を0に、良いを1にエンコード
transformed_label = label_vectorizer.fit_transform(dataset.get("label"))
dataset["label"] = transformed_label
display(dataset)
labelが0/1で表現されました。
これらのデータを訓練データ&テストデータに分割していきます。
!pip install janomeまずは下準備としてjanomeのインストールを行います。
from janome.tokenizer import Tokenizer
from sklearn.model_selection import train_test_split
# 入力と出力に分割
x, y = dataset.get("text"), dataset.get("label")
print(x)
print(y)
# 訓練とテストデータ8:2で分割、stratify=yで訓練データ&テストデータそれぞれの各ラベルの比率を同じにする
、
X_train, X_test, y_train, y_test = train_test_split(
x, y, test_size=0.1, stratify=y, random_state=0
)
# それぞれの数があっているか確認
print([len(c) for c in [X_train, X_test, y_train, y_test]])
こちらでデータの準備は完了です。次ににモデル構築を実装していきます。
3.モデル構築
tokenizer = Tokenizer(wakati=True)
for token in tokenizer.tokenize("データ分析の勉強中です"):
print(token)janomeという日本語の形態素解析器のライブラリを利用します。試しに上記を例に形態素解析(分かち書きリストの表示)をしてみます。

今回は、取得したtextで出現する単語のカウントを特徴量にするためCountVectorizerを利用し、出現した単語を純粋にカウントします。
from sklearn.feature_extraction.text import CountVectorizer
feature_vectorizer = CountVectorizer(binary=True, analyzer=tokenizer.tokenize)
transformed_X_train = feature_vectorizer.fit_transform(X_train)
print(transformed_X_train)
データ行ごとに単語をベクトル化しました。
モデルを使ってこれらのデータを学習させていきましょう。
今回は
・ロジスティック回帰
・ランダムフォレスト
・ナイーブベイズ
を利用してそれぞれの評価を確認していきます。
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
#ロジスティック回帰モデル
model_lr = LogisticRegression()
model_lr.fit(transformed_X_train, y_train)
vectorized = feature_vectorizer.transform(X_test)
y_pred = model_lr.predict(vectorized)
print(classification_report(y_test, y_pred, target_names=label_vectorizer.classes_))
from sklearn.ensemble import RandomForestClassifier
model_rf = RandomForestClassifier(n_estimators=100)
model_rf.fit(transformed_X_train, y_train)
vectorized_test = feature_vectorizer.transform(X_test)
y_pred = model_rf.predict(vectorized_test)
print(classification_report(y_test, y_pred, target_names=label_vectorizer.classes_))
from sklearn.naive_bayes import MultinomialNB
model_nb = MultinomialNB()
model_nb.fit(transformed_X_train, y_train)
vectorized_test = feature_vectorizer.transform(X_test)
y_pred = model_nb.predict(vectorized_test)
print(classification_report(y_test, y_pred, target_names=label_vectorizer.classes_))
4.モデル適用後の分析・モデルの精度向上・考察
今回はロジスティック回帰モデルに着目して、単語がどのように重みづけ(判定)されているのか確認します。
from janome.analyzer import Analyzer
from janome.charfilter import RegexReplaceCharFilter
from janome.tokenfilter import ExtractAttributeFilter, POSKeepFilter, TokenFilter
from pandas import Series
feature_to_weight = dict()
for w, name in zip(model_lr.coef_[0], feature_vectorizer.get_feature_names()):
feature_to_weight[name] = w
se = Series(feature_to_weight)
se.sort_values(ascending=False, inplace=True)
print("Positive or Negative")
print("--Positiveの判定に効いた素性")
print(se[:20])
print("--Negativeの判定に効いた素性")
print(se[-20:])
print("--" * 50)
positive/negative、それぞれに比較的それらしき単語が含まれております
ここで精度をより向上させるため、「名詞、動詞、形容詞、形容動詞」のみにフィルタして再評価を実施します。またテキスト内には最初の部分に映画のタイトルが含まれていたり、URLが含まれているケースがありますのでそちらを削除します。
def validate():
# 学習
model_lr = LogisticRegression()
transformed_X_train = feature_vectorizer.fit_transform(X_train)
model_lr.fit(transformed_X_train, y_train)
# 評価
vectorized = feature_vectorizer.transform(X_test)
y_pred = model_lr.predict(vectorized)
print(classification_report(y_test, y_pred))
# モデルのダンプ
feature_to_weight = dict()
for w, name in zip(model_lr.coef_[0], feature_vectorizer.get_feature_names()):
feature_to_weight[name] = w
se = Series(feature_to_weight)
se.sort_values(ascending=False, inplace=True)
print("--Positiveの判定に効いた素性")
print(se[:20])
print("--Negativeの判定に効いた素性")
print(se[-20:])
print("--" * 50)
return y_pred
# 前処理
char_filters = [
RegexReplaceCharFilter("^[『「【].*[』」】]", ""),
RegexReplaceCharFilter("(https?:\/\/[\w\.\-/:\#\?\=\&\;\%\~\+]*)", ""),
]
# 後処理
token_filters = [
POSKeepFilter(["名詞", "動詞", "形容詞", "副詞"]),
ExtractAttributeFilter("base_form"),
]
# Tokenizerの再初期化
tokenizer = Tokenizer()
# 前処理・後処理が追加されたVectorizerに変更
analyzer = Analyzer(
char_filters=char_filters, tokenizer=tokenizer, token_filters=token_filters
)
feature_vectorizer = CountVectorizer(binary=True, analyzer=analyzer.analyze)
# 再評価
result = validate()

結果、「残念」側のF値は若干向上したものの、大きく改善することはできませんでした。予測が外れたものに対してデータの内容を確認してみます。
import pandas as pd
pd.set_option("display.max_colwidth", 200)
##予測が良いに対して結果が残念のものを表示
# 検証用のDataFrameを作成
validate_df = pandas.concat([X_test, y_test], axis=1)
validate_df["y_pred"] = result
# 予測とラベルが異なるものを抽出
false_positive = validate_df.query("y_pred == 1 & label == 0")
display(false_positive)
これらが「良い」と分類されてしまったのは


上記のように、逆説の文章で出てくる単語により「良い」に分類されてしまったのではないかと考察できます。
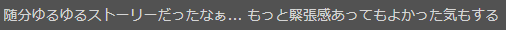
上記のように、「緊張感あってもよかった」の「よかった」が良いと分類することにつながっているのではないでしょうか。
# 検証用のDataFrameを作成
validate_df = pandas.concat([X_test, y_test], axis=1)
validate_df["y_pred"] = result
# 予測とラベルが異なるものを抽出
false_negative = validate_df.query("y_pred == 0 & label == 1")
display(false_negative)
逆のパターンも同様に「残念」などのワードが含まれていることで不正解となってしまったようです。
5.最後に
今回は自然言語処理を用いた、コメントのネガポジ分類を実装してみました。もし精度を向上させるのであれば、単語のみで判断するのではなく、文法なども特徴量に含めるといいのではないかと思いました。
また、データの前処理として、bertのようなものをつかえば精度向上を狙えるかもしれないと思いました。
データの整形→表示→解釈→特徴量の発見というサイクルがかなり大変で今後もアウトプットを出していければと思います。
ご精読いただきありがとうございました。
この記事が気に入ったらサポートをしてみませんか?