ChatGPT(GPT-4o)とPythonで野球のデータを図示してみよう

こんにちは。B-Cat(@BreakingBallCat)です。
この記事を書き始めたのは5月頃で、完成までに時間がかかっている間にいつの間にかSEAはプレーオフ進出が厳しい位置に立っていました。助けてください。
この記事を書き始めたきっかけは大略下記のとおりです。
FFの方に「せっかくですしPython学んで業務の自動化に勤しむのはどうですか?」とおすすめしたのですが、しばらくして「やっぱPythonわかんね」という状態になっていました。
(それはプログラミングを学び始めた段階において、むしろ自然な状態であるとは思います)
私個人としても、教材やサイトを紹介しただけで投げっぱなしにするのは不誠実かなと思ったので、この記事を書くに至りました。
なお、この記事の文字数はかなり多めです。(途中のコードで2000字くらい稼いでいますが、それを除いても1万字以上です)
そのため読むのが面倒だと思った場合は、太字になっている部分を拾いながら読んでいってください。
この記事を書く理由:
TwitterのFFの方が「Pythonわかんね~」と言っていたこと
Pythonの知識をほとんど前提とせずに、GPT-4oを用いてどこまでデータの分析が可能かを調査するため
この記事が対象とする読者層(目安):
MLBの試合を定期的に観ている
セイバーメトリクスに関心があり、よく用いられている指標(wOBA、FIP、f/rWARなど)の内容をある程度理解している
自分でも色々データを分析したり表を作ったりしてみたいが、どうしたら作れるかイマイチ分からない
Baseball Savantで示されていないような内容について、自分で分析したり図示してみたいと思っている
プログラミング(Python)やChatGPTについて、聞きかじったり自分で触ってみたりしたことはある
この記事を読むことによるメリット:
煩雑な環境構築なしで、Pythonを使える体制を整えることができる
GPT-4oを用いて、プログラミングしたコードや画像を元に改善していき、自分の目的に沿った野球の分析を目指せる
Matplotlibを用いた図表の作り方について学べる
この記事で書かないこと:
Rによる分析(筆者はRを書いたことがないため)
Excelによる分析(筆者はデータ分析目的でExcelを用いたことがほぼないため)
ローカル環境でのPythonの使い方(ローカル環境の整備が煩雑でつまづきやすいため)
有料のChatGPT、およびAPIを用いる方法(APIを使うための環境構築、特にAPIキー周りが面倒なため)
NPBに関する分析(そもそもデータ取得に手間がかかるため)
この記事の要約:
Google Colabを用いることで、Pythonの煩雑な環境構築をせずにPythonを使うことができる環境を整える。
Playgroundを用いることで、無料でGPT-4oを使うことができる環境を整える。
図表を作成するためのライブラリであるMatplotlibを使って、どのような分析や図表の示し方ができるかを確認する。
また、GPT-4oを用いてコードや図表を改善する方法を学ぶ。
応用編として、Matplotlibの公式ドキュメントや、Qiitaなどによる情報の調べ方を学ぶ。
Pythonを使う環境を整える:Google Colab
Google Colab(以下Colabと表記)とは、Googleが提供している、ブラウザ上でPythonの環境が使えるものです。PythonとはRと同様にプログラミング言語の一つで、データ分析等によく用いられています。
Colabのメリット
Colabのメリットは下記のとおりです。
Pythonの環境を整備する必要がない
ブラウザ上で使える(スマホやタブレット等からでもアクセスできる)
「Google Colab」で検索する
Google Colabを使用するには、Google検索からアクセスすればよいです。「Colaboratoryへようこそ」をクリックします。

ここで、画像左下の青い「ノートブックを新規作成」のボタンを押しましょう。
すると下記のような画面が出てきます。

基本的には画面のうち灰色になっている部分に、Pythonのコードを入力してから左側の再生ボタンのようなものを押すと、コードが実行されるという形になっています。
これによって、「ブラウザからアクセスできるGoogle Colab上でPythonを実行できる」という目的が達成できました!
次に、Pythonのコードを生成・改善するために必要な、GPT-4oを使う環境を整えていきましょう。
GPT-4oを使う環境を整える
おそらくChatGPTについてはほとんどの方が聞いたことがあり、使ってみた方も多いかと思われます。
ChatGPTは基本的に無料で使えるGPT-3.5と有料で使えるGPT-4があり、GPT-3.5とGPT-4には歴然とした性能差があります。そのため、プログラミング等に使用する場合は基本的に有料のGPT-4を使用するのが前提でした。
(ChatGPTをご自身でも使われて「ChatGPT、言われてる割にショボいじゃん」と思われた方もいるかもしれません。しかしそれは「無料版のGPT-3.5を使っていたからだった」という方も割と多くいらっしゃいます)
さらに最近、GPT-4oという新しいモデルが登場し、特に画像を用いた指示や分析などにおける性能が大幅に向上しました。
これまでですと、例えばPythonでコードを書いて図表を作った時に、自分が作りたい図表を実現するためにどうしたらいいかを全て文章でChatGPTに質問する必要がありました。
しかしGPT-4oを使えば、出力された図表をそのままGPT-4oにアップロードして、「この図表に○○を追加するコードになるように改善してください」と指示することによって、Pythonのコードを改善することができるようになりました。
GPT-4oは下記の「Playground」にて、無料で使うことができます。(ただし回数制限があります)
https://platform.openai.com/playground/chat?mode=chat&model=gpt-4o&models=gpt-4o

ここで設定するにあたって、注意する点が2点あります。
モデルがgpt-4oになっているか確認する
Maximum Tokensを最大にする
まず大前提として、モデルがgpt-4oになっていないと十分な性能を発揮することができません。
そのため、画面左上の灰色の部分を見て、gpt-4oになっていることを確認してください。
そして、画面右側にある設定のうち、Maximum Tokensが最大になるように調整してください。
Maximum TokensはGPT-4oが出力する内容の長さの上限にかかわるもので、これが小さいと短い内容しか返してくれなくなります。
GPT-4oに質問するには、画像下部分の「Enter your message…」の部分に質問の内容を記述します。
試しに「MLBの歴史上で最も本塁打を打った選手は誰ですか?」と聞いてみましょう。
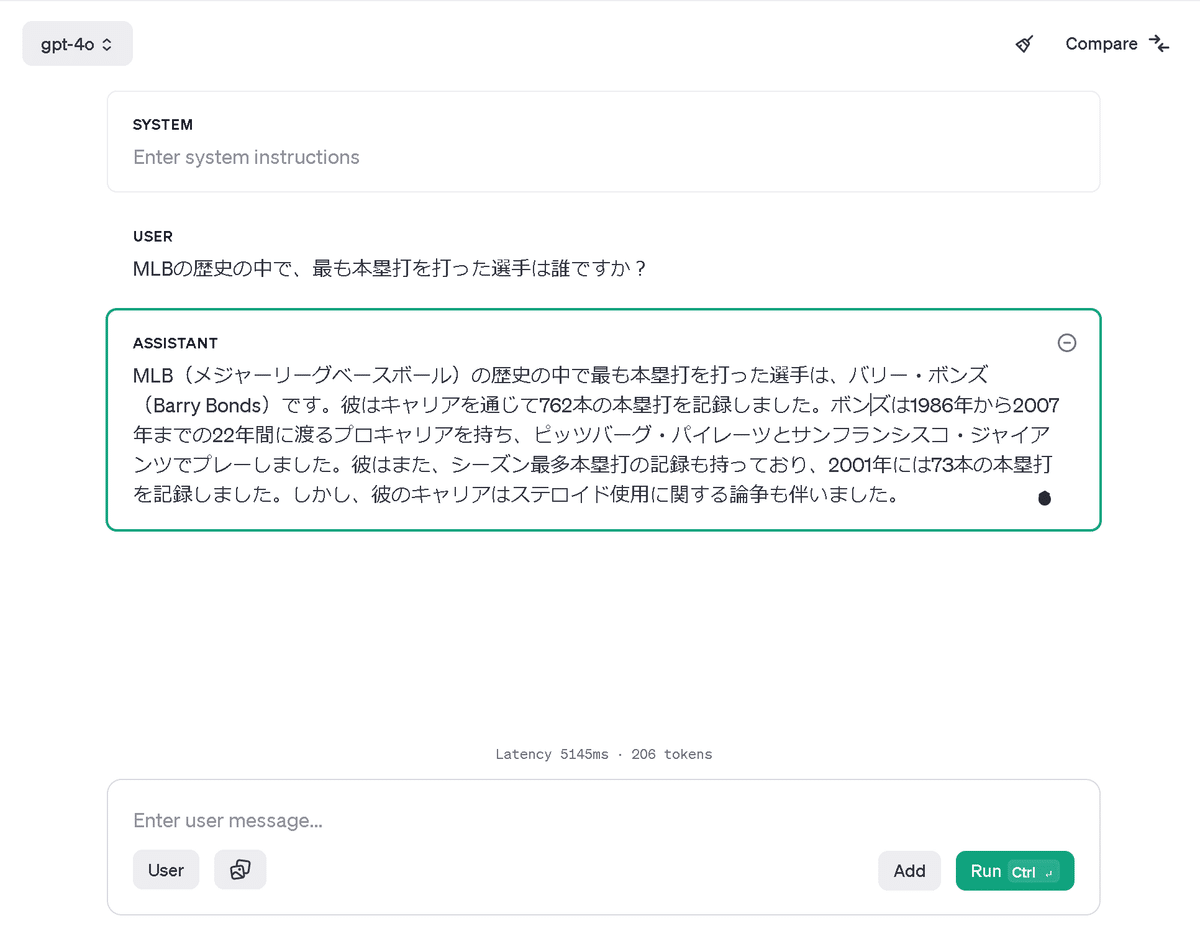
確かにバリー・ボンズと答えてくれました。また、彼のステロイド使用に関することについても付記してくれています。
では次に、画像を用いて質問する方法も確認してみましょう。画面下部分の「User」の右側に、画像のアイコンがあります。ここからLuis CastilloのBaseball Savantのトップページ画像をアップロードし、「この画像の内容について要約してください。」と質問してみます。


いいですね!画像の内容を読み込めていることが分かります。
後ほど、この画像を用いて質問する機能を使うことで、自分が作りたい図表を実現するためのPythonのコードをどのようにして作ればいいかについて確認していきます。
注意事項:AIは常に正しいとは限らない
ここで重要な注意事項として、「AIは常に正しい出力をするとは限らない」という点があります。
また非常にそれっぽい情報を出しているけれども間違っている、という場合もあります。これは「ハルシネーション」と呼ばれるものです。
MLBに関する知識の間違いであればまだよいですが、これがプログラミングのコードで間違いが出力されていたらどうでしょうか?
Pythonの知識がない場合、出力されたコードが正しいのか間違っているのかということを判断する方法もありません。
そういった場合はどうすればいいのでしょうか?
こういった場合、出力された内容を確認した上で、「〇〇という間違いがありました。これを△△という状態になるように修正してください。」というように修正するとよいです。
これは後ほどの実践編でも頻出する、重要な改善方法です。
注意事項:有料のGPT-4oのメリットについて
ここまででは無料で使えるGPT-4oを使ってきました。後ほど見ていくように、無料で使える範囲でもGPT-4oは十分な性能を発揮しています。
しかし、有料のGPT-4o(月20ドルのサブスク or 従量課金のAPI)を使うことによるメリットもあります。
回数制限がない
上限トークン数が多い
特に2番目の「上限トークン数が多い」という点は重要です。無料版のGPT-4oは入力/出力を合わせた上限トークン数が4096までですが、有料版ですとそれよりも長い入力/出力をすることができます。
おススメする使い方の順番としては、「性能やトークン数、回数制限に不満が出るまではPlaygroundを使う」→「不満が出たら月20ドルのサブスクを使う」→「より詳しくなったら、APIを使う」という感じです。
特にAPIを使う場合はそれなりに環境構築が必要であることに注意してください。
(APIを使う場合の環境構築の仕方もGPT-4oに聞けば教えてもらえるという点はありますが、教えてもらえる点を含めても躓きやすいポイントです。特にAPIキーの設定は初心者にとって難関です)
ここまでで、Google ColabとGPT-4oを使うことができる環境を整えてきました。
次に、分析した結果を図表として表示するために必要な道具であるMatplotlibの使い方について見ていきましょう。
Matplotlibを使ってみる
さて、データを分析したらそのデータを図表として出すのも大事になってきます。
Pythonの場合、図表を作るための道具は数多くありますが、その中でも最もメジャーなものがMatplotlibでしょう。
MatplotlibはPythonで使えるライブラリの一つです。プログラミングにおけるライブラリとは、いわば道具箱のようなものに近いでしょう。
例えば家を建てるときに、道具箱にハンマーやネジ締めなどを入れておき、それを場合によって使い分けます。
Matplotlibもこれと同じように、「図表を作る」という目的を達成するための道具箱として使うことができます。
(他にもPythonで使える図表作成のためのライブラリは色々ありますが、初めのうちは無難にメジャーなものを選んだ方がよいです。主に下記のようなメリットがあるためです。)
定期的なアップデートがされているので、ある程度使いやすい。
多くの人が使っており、品質がある程度担保されている。
多くの情報がネット上で書かれており、検索することで情報を得やすい。
テスト:Google ColabとGPT-4oとMatplotlibを用いて、図表を改善してみる
以前、FFの鯖茶漬さん(@Eikura__Metrics)と下記のようなやり取りをしました。
https://twitter.com/Eikura__Metrics/status/1780791300503286115
上記のやり取りの中では(ChatGPT等を用いずに)Matplotlibを使って普通に散布図を作りました。しかしここでは改めて、これまで見てきたGoogle ColabとGPT-4oとMatplotlibを用いてこのような図を作ることができるかを試してみましょう。
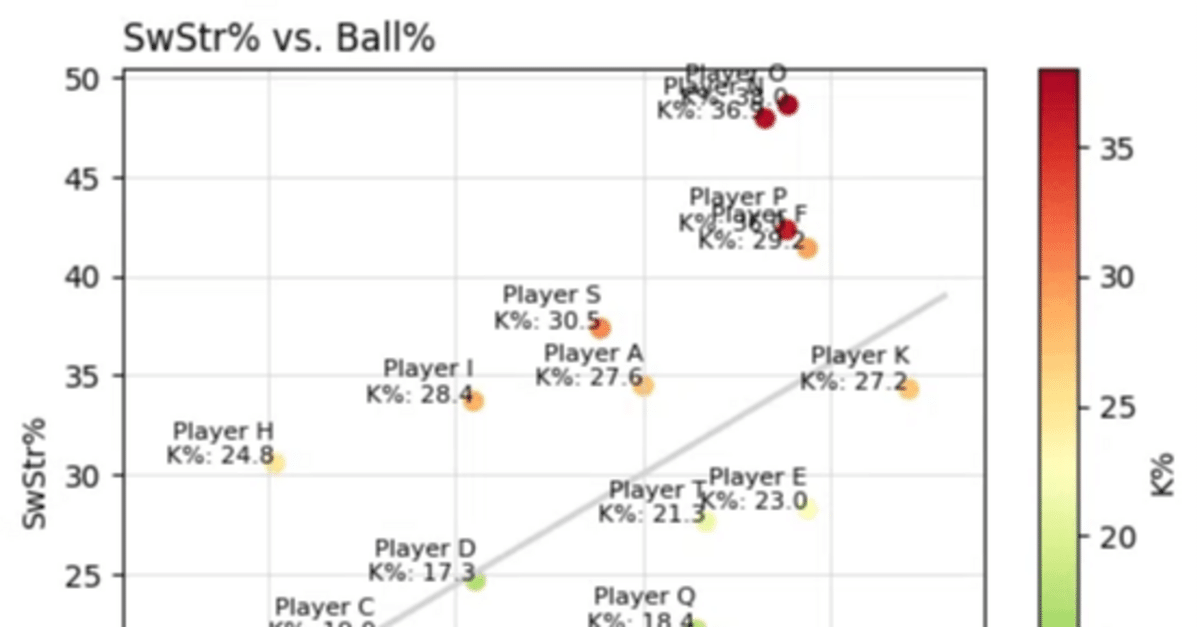
まず、当該ツイートの表が持つ特徴について整理してみましょう。
x軸(横軸)にはBall%、y軸(縦軸)にはSwStr%が記載されている。
Ball%の軸は2%ずつ減少し、SwStr%は2%ずつ上昇している。
図はそれぞれ44.0%~26.0%、6.0%~24.0%の範囲で収まっている。図のタイトルは「SwStr% vs Ball%」である。
K%が高い場合は赤色、低い場合は緑色で色分けされている。
相関係数の線が描かれている。
これらの整理した特徴は、後ほどGPT-4oが出力してきた図表を修正するために用います。
それでは、このような図を出力するコードを書くため、まずGPT-4oに「画像のような図表をMatplotlibで実現するためのコードを出力してください。なお、図表の特徴を出来るだけ取りこぼさないように注意してください。」と質問してみます。
(ちなみに特にプログラミング言語の指定がない場合、GPT-4oはPythonで出力するのがほぼデフォルトとなっています。例えばもしRで出力してほしい場合は、「コードはRで出力してください。」等の指示が必要となります。)

結果が出てきたので、これをそのままGoogle Colabで実行してみましょう。
出てきた画像は以下のようになります。

なんだかイマイチですね。ですが初めは大体こんなものです。
(今回は図の形式を真似ることが出来るかが主眼にあるので、各投手のデータは正しいものではなくテストの値を用いています)
Tips:コードの内容をGPT-4oに説明してもらう
ここで出力されたコードについて、Python初心者の場合ですと「このコードが何をしているのかよく分からない」という状態になるかと思います。
これについては、GPT-4o自身に説明してもらいましょう。
先ほど出力されたコードをそのまま貼り付けながら、「下記のコードを、初心者でも分かりやすいように詳細なコメントを付してください」と指示してみましょう。
出力された結果は下記のとおりとなります。
# matplotlibをインポートしてプロット(グラフ描画)機能を使用可能にする
import matplotlib.pyplot as plt
# numpyをインポートして数値計算を容易にする
import numpy as np
# seabornをインポートして統計的なデータ可視化を簡単にする
import seaborn as sns
# データの準備工程
# 投手の名前一覧
names = ["Jose Quintana", "A.J. Puk", "Joe Boyle", "Marcus Stroman", "Zac Gallen", "Dylan Cease",
"Jesus Luzardo", "Dane Dunning", "Reid Detmers", "Max Meyer", "Jordan Wicks", "Bryce Miller",
"Logan Gilbert", "Nathan Eovaldi", "Zack Wheeler", "Tarik Skubal", "Chris Sale", "Luis Castillo",
"Logan Webb", "Erick Fedde", "Michael Soroka", "Lance Lynn", "Jared Jones", "Joe Ryan",
"George Kirby", "Zach Littell", "Nestor Cortes", "Marco Gonzales", "Zach Eflin", "Seth Lugo",
"Miles Mikolas", "JP Sears", "Brandon Pfaadt"]
# ボール率(Ball%)のデータ
ball_pct = np.array([44, 43, 41, 40, 37, 36, 35, 34, 32, 31, 30, 29, 29, 28, 27, 26, 26, 25, 24,
23, 22, 21, 20, 20, 20, 20, 19, 18, 17, 16, 16, 16, 15])
# 空振り率(SwStr%)のデータ
swstr_pct = np.array([6, 8, 9, 10, 11, 12, 12, 13, 15, 13, 12, 13, 14, 15, 15, 14, 14, 15, 14,
13, 12, 10, 20, 18, 19, 20, 18, 19, 17, 16, 10, 17, 14])
# 三振率(K%)のデータ
k_pct = np.array([8.1, 12, 14, 15, 15, 16, 16, 17, 18, 16, 17, 15, 14, 18, 16, 15, 14, 15, 16,
14, 15, 17, 40.6, 26, 28, 29, 20, 17, 16, 17, 13, 17, 18])
# グラフのサイズを設定
plt.figure(figsize=(12, 8))
# 散布図の描画
# ボール率をx軸、空振り率をy軸、三振率の値で色をつける
scatter = plt.scatter(ball_pct, swstr_pct, c=k_pct, cmap='RdYlGn_r', s=100, alpha=0.75,
edgecolors="w", linewidth=0.5)
# 軸ラベルの設定
plt.xlabel('Ball%') # x軸のラベル
plt.ylabel('SwStr%') # y軸のラベル
plt.title('SwStr% vs. Ball%') # グラフのタイトル
# カラーバーの描画
cbar = plt.colorbar(scatter) # カラーバーを追加
cbar.set_label('K%') # カラーバーのラベル
# カラーバーの目盛りを設定
cbar.set_ticks([8.1, 40.6]) # 目盛りの位置
# カラーバーの特定の位置にテキストを追加
cbar.ax.text(-1, 8.1, '8.1%', ha='right') # 8.1%を表示
cbar.ax.text(-1, 40.6, '40.6%', ha='right') # 40.6%を表示
# 回帰線の描画
# ボール率と空振り率の関係を示す回帰線を描く
sns.regplot(x=ball_pct, y=swstr_pct, scatter=False, color='grey', order=1,
line_kws={"linestyle":"--"}) # 点を表示せず、グレーの破線で回帰線を描く
# 各ポイントに名前を追加
for i, name in enumerate(names):
plt.text(ball_pct[i], swstr_pct[i], name, fontsize=9, ha='right') # 各ポイントに名前を追加
# Jared Jonesを特別に強調
highlight = 'Jared Jones' # 特定の選手をハイライト
highlight_index = names.index(highlight) # 選手のインデックスを取得
# 強調表示するためのポイントを再描画
plt.scatter(ball_pct[highlight_index], swstr_pct[highlight_index], c='red', s=150,
edgecolors="w", linewidth=1.5)
# 強調表示する名前も追加
plt.text(ball_pct[highlight_index], swstr_pct[highlight_index], highlight, fontsize=12,
fontweight='bold', ha='left', color='red')
# グラフの表示
plt.show()Tips:「ステップバイステップで出力してください」と指示する
GPT-4oを扱う際のテクニックとして「プロンプトエンジニアリング」と呼ばれるものがあります。
詳細については述べませんが、この技術を使用することによってGPT-4oの性能を高めたり、意図した出力を出しやすくすることができます。
ここではプロンプトエンジニアリングの基本的なものとして、「ステップバイステップで出力してください」と指示する方法があります。この方法では段階を踏んで出力してくれるだけでなく、GPT-4oがいわば少し「賢く」なる(性能が上がる)ことが報告されています。
Tips:問題を小分けにして入力する
第二は、私が検討する難問の一つ一つを、できるだけ多くの、しかも問題をよりよく解くために必要なだけの小部分に分割すること。
17世紀の哲学者・数学者であるデカルトは、上記のように「困難は分割せよ」という意味の言葉を残しています。
(『方法序説』については現代のデータ分析においても通用する部分があり、岩波文庫で安く手に入りかつかなりページ数が少なめので初めての哲学書としておすすめです)
この「困難は分割せよ」は、ChatGPTにおいても成り立ちます。
ChatGPT等のLLMについて、「問題を小分けにする方が性能が向上する」という特徴があります。
ここで「問題を小分けにする」というのは、求める出力を得るために、段階を踏んで入力していき、その結果を結合していくというものです。
言い換えれば「ステップバイステップで質問していき、その結果を合わせていく」ということです。GPT-4oがステップバイステップで出力することで性能が向上するように、ステップバイステップで入力することによっても求める出力が得やすくなります。
例えば先ほどの方法では、「画像のような図表を出力することができるコードを出してください」という指示で、一気にコードを全て出力させていました。
そうすると既に完成形となるコードが出力されてしまうため、後から細かい調整がききにくいという問題が生じます。また、出力された完成形のコードがちゃんと質問の意図を読み取れているかも保証できません。
つまり、自分の意図に沿うようなコードが出てくるかどうかで不毛なガチャを引かなくてはならないことになってしまいます。
問題を小分けにすると、(様々な分け方がありますが)例えば下記のようになります。
図のタイトルを「SwStr% vs Ball%」にする。
x軸(横軸)にはBall%、y軸(縦軸)にはSwStr%を記載する。
Ball%の軸は2%ずつ減少し、SwStr%は2%ずつ上昇するようにする。
図はそれぞれ44.0%~26.0%、6.0%~24.0%の範囲で収まるようにする。K%が高い点(選手)は赤く、低い点(選手)は緑に塗り分ける。
相関係数の線を引く。
初めの方法が「まず全体的なコードを出力してから、部分的な修正を繰り返す」というものだったのに対して、今回の方法は「段階を踏んでコードを出力していき、最終的に必要なコードを構成する」と言うことができます。
建物を建てる時にはまず図面を引くわけですが、それに近いイメージです。
個人的なおすすめは後者の方法なのですが、後者の方法を実行するためには「自分が何を作りたいのかをあらかじめ把握し、言語化する」ということが必要になってきます。
これはGPT-4o等のLLMを使う際に本質的な部分ですが、「自分が解決したい問題をどれだけ言語化できるか」という点がとても大切です。
そうして(例えば上記では)4つの問題を一つずつGPT-4oに入力し、その問題が解決されているかを確認し、もし確認されていなければ修正・改善し、問題が解決されたことを確認したら次の問題へ進む、という順序を踏んでいきます。

Matplotlib上で、左上にタイトルとして「SwStr% vs. Ball%」となるようなPythonのコードを出力してください。
先ほど出力されたコードについて、横軸がSwStr%、縦軸がBall%となっていますが、これを逆にしてください。
先ほど出力されたコードについて、背景に薄くグリッド線を引くように修正してください。

先ほど出力されたコードについて、グリッド線をより薄い色で、細く引くように修正することはできますか?

先ほど出力されたコードについて、横軸のBall%が右側に行くほど大きくなるのではなく、右側に行くほど小さくなるように修正してください。

先ほど出力されたコードについて、ランダムなデータとなる点を20個ほど追加してください。なお、それぞれの点には野球選手の名前(ダミー)が付くようにしてください。7回目先ほど出力されたコードについて、相関係数の線を描くようにコードを修正してください。 なお、相関係数の線の色は薄いグレーになるようにしてください。
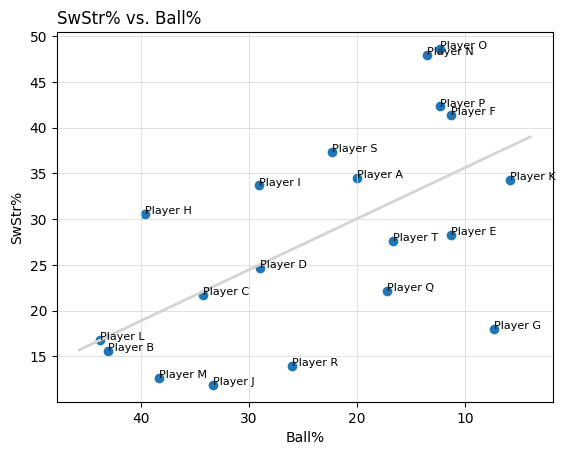
先ほど出力されたコードについて、相関係数の線を描くようにコードを修正してください。 なお、相関係数の線の色は薄いグレーになるようにしてください。
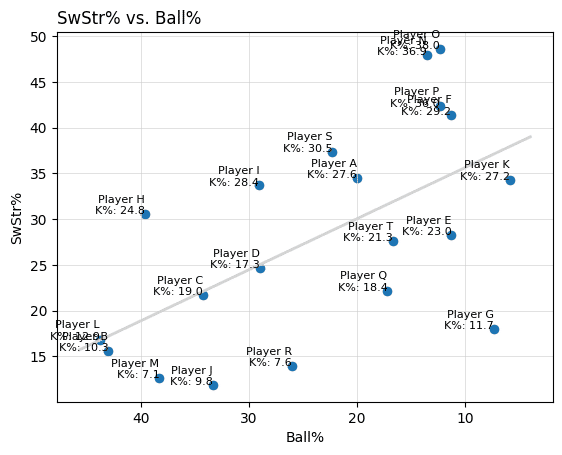
先ほど出力されたコードについて、新たにK%という項目を設け、ダミーデータの選手にK%のデータを追加してください。なお、K%はSwStr%とある程度の相関があります。
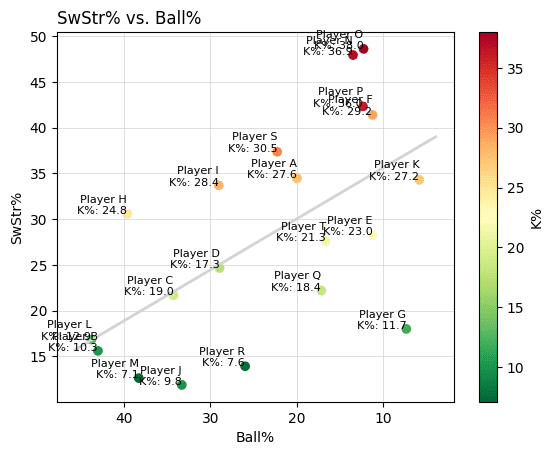
先ほど出力されたコードについて、K%が高い選手は赤色で、低い選手は緑色で表すようにコードを修正してください。なお、赤から緑の間はグラデーションで表現してください。

先ほど出力されたコードについて、プレイヤー名の下にK%を表示しないようにコードを修正してください。

先ほど出力されたコードについて、K%のバーをグラフ内の左上部分に移動することは可能ですか?

先ほど出力されたコードについて、K%のバーの位置をより下に(タイトルの下に)移動し、バーの向きも縦向きではなく横向きになるように修正してください。
ここまでで、なかなか満足いく図表が作れたのではないでしょうか。
(K%のバーが図の左上にカッ飛んでしまっていますが、大略こんな感じで修正していくとよい、ということをイメージしていただければと思います)
応用編:Matplotlibの公式ドキュメントを読んでみる
ここまでで、GPT-4oを用いて分析する方法については一通り確認ができました。
しかし、プログラミングの知識がないままでGPT-4oを用いて分析を行う場合、下記のようなリスクが生じます。
エラーが出た時にそのエラーを修正できるとは限らないこと
自分の意図とは異なるコードが出力された場合に、それをコントロールすることが難しいこと
新卒のエンジニアが仕事をする時の研修で、「公式ドキュメントを読みましょう」と言われることも多いかと思います。
Python自体についても公式ドキュメントがありますし、その中のライブラリ(道具箱のようなもの)であるMatplotlibにもやはり公式ドキュメントがあります。
公式ドキュメントはいわば分厚い取扱説明書のようなものであり、これを都度参照しながらプログラミングをしていくことはむしろ自然だと言えるでしょう。
公式ドキュメントは基本的に英語であることが多いので、Google翻訳やDeepL等に通して読んでいきましょう。
また、公式ドキュメントの内容の一部をChatGPTにコピペして、「この内容を分かりやすく解説してください」と指示することもおすすめです。
ググってみる
GPT-4oに聞いても分からず、公式ドキュメントを読んでも解決しないようなエラーが生じるといった場合があります。
例えば下記記事のような場合です。
https://note.com/unga_oakland/n/n9c64bb37e313
これはデータを取得するための関数の引数が92個なのですが、Baseball Savantがアップデートされ、Bat Speed等の追加によりテーブルの項数が94個になったため、関数の引数(92個)とテーブルの項数(94個)が一致しなくなった結果エラーが生じたものです。
しかし、この当該関数をユーザー側が編集するというのも現実的ではないですし、Baseball SavantのGlossary(各種指標について解説したもの)を見たところで解決するものでもありません。当然GPT-4oに聞いても答えてくれません。
そういった場合はどうすればいいのでしょうか?
これはググるしかありません。Google検索でもTwitter上でもいいので、エラーの内容等をキーワードとして検索してみましょう。
そして万が一それでも該当する記事等が見当たらなかった場合は、Twitter上で質問してみましょう。有識者が答えてくれる可能性があります。
(有識者が状況を把握し回答しやすいように、質問する場合は状況を詳細に記載することが望ましいです。エンジニアの質問サイトであるStack Overflow等でも、状況を詳細に記載することが奨励されています)
ググってみる(Qiita編)
先ほど紹介した「ググる」という方法ですが、これはライブラリについて学ぶ際にも使うことができます。
この「ググること」による、公式ドキュメントと比較したメリットは「公式ドキュメントに比べて分かりやすい」という点です。
分からないことがあればまずググってみて、それでも分からなければ公式ドキュメントを読んでみる、という順序で進めるのがよいでしょう。
ただし、公式ドキュメントに比べて玉石混淆となってしまうことには注意が必要です。
おまけ:Claude-3.5-Sonnetについて(おすすめ)
この記事を書き始めたのは5月頃でしたが、記事を放置している間にClaude-3.5-Sonnetが出てきました。
正直今であれば、性能的に考えてもClaude-3.5-Sonnetを使った方がいいです。
Claude-3.5-Sonnetは無料ですし、GPT-4oよりも性能が高く、またUIもGPT-4oのPlaygroundよりも分かりやすく使いやすいです。
Claudeの使い方については下記を参照してください。
https://highreso.jp/edgehub/wordgenerationai/claude-app.html#index_id3
最後に
ここまで長い間読んでいただきありがとうございます。そして大変お疲れ様でした。この記事はいかがだったでしょうか?
この記事を読んで、一人でもPythonを用いたセイバーメトリクスを志す方が新しく誕生すれば幸いです。
この記事が気に入ったらサポートをしてみませんか?