暗号紹介:ADFGVX暗号(2) 解読実例

表記・用語について
プレーンテキスト(暗号化前のメッセージ)の文字は小文字で、暗号文の文字は大文字で表すことにする。
ADFGVX暗号とは
前回の記事を参照。
解読実例
ADFGVX暗号には、特別な場合の解読法と、一般解読法がある。今回は一般解読法を示す。アメリカ国家安全保障局所蔵の資料に掲載されている例を用いて、その解読作業を追っていく。
実際、かなり複雑である。筆者自身が説明不足を感じ、自分なりに解決した部分を補っているが(あるいはそのせいで?)、それでもかなり難解である。簡潔な解法を求めてこの記事を開いた方には申し訳ないが、これが筆者の限界である。
同じ鍵で暗号化された12のメッセージを手に入れた。その内容は後述の暗号文一覧に掲載する。それらを解読する。
転置鍵の大きさは奇数か偶数か
まず最初にすべきことは、転置鍵の大きさが奇数か偶数かを決めることである。
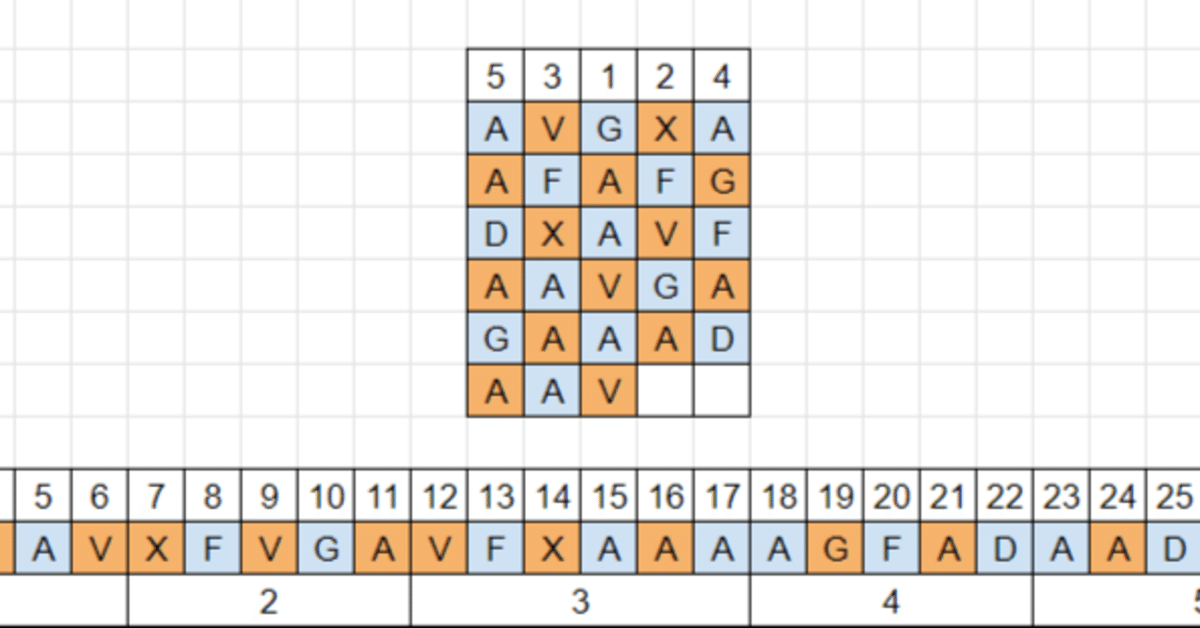
ADFGVX暗号においては、元のメッセージの1文字は換字表によって2文字組に変換される。この2文字組は「始めの文字」と「終わりの文字」の2つのカテゴリから成り立つ。このことを「example message」という例文を用いて示したのが図1である。

次に転置を行うのだが、転置鍵の大きさが奇数か偶数かによって、大分様子が違ってくる。まず、奇数の場合を見てみよう。図2を見てわかるように、一つの列に着目すると「始めの文字」と「終わりの文字」が交互に現れる。

一方、転置鍵の大きさが偶数の場合、図3のように、どの列にも必ず「始めの文字」か「終わりの文字」の片方のみが含まれる。

転置鍵の大きさが奇数であれ偶数であれ、二次暗号文の1文字目、3文字目、……は同じカテゴリに属する。2文字目、4文字目、……の場合もまた、同じカテゴリに属する。そこで、両者の傾向を、頻度分析により比べてみる。奇数文字目と偶数文字目が同じ傾向を示すならば、両者は同じカテゴリであり、したがって転置鍵の大きさは偶数だろう(図3)。違う傾向を示すならば、両者は異なるカテゴリであり、したがって転置鍵の大きさは奇数だろう(図2)。
ここで、注意するべきことがある。図2を見ると、1文字目、3文字目、5文字目は同じ「始めの文字」だが、7文字目は「終わりの文字」である。このように、片っ端から文字を拾っているうちに、いつの間にか文字のカテゴリが変わってしまうかもしれない。よって頻度分析を行うにあたり、暗号文から拾う文字数は制限しなければならない。
「頻度分析のために、出来るだけ多くの文字を取りたい」が、「多く文字を取り過ぎると、かえって頻度分析を狂わせる」。では、何文字取るのが安全なのだろうか。
参考文書によれば、転置鍵の幅は25を超えることはないとみてよさそうである(何故そう言えるのだろうかは分からないが、経験則なのだろうか)。そして、1つの列に含まれる文字数は、少なくとも「暗号文の文字数÷転置鍵の大きさ」以下の最大の整数である。例えば、暗号文No.1は212文字からなるが、転置鍵の大きさが25だとしても212÷25=8.48であり、したがって1つの列に含まれる文字数は少なくとも8文字である。だから最初の8文字VDDGGGVFが同じ列に含まれるのはほぼ確実であるため、その中でいきなりカテゴリが不規則な変わり方をすることはない、と考えてよいのである。
他の暗号文についても拾う文字数、そして拾う文字列を決めると、図4に示す表のようになる。
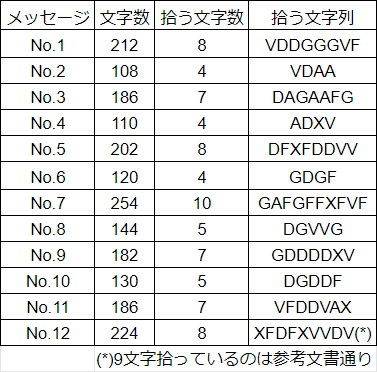
こうして拾った文字たちを、奇数文字目と偶数文字目に分けたうえで頻度分析を行った結果、図5に示す表のようになる。
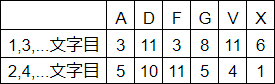
参考文書では2,4, …文字目のAの数を4としているが誤りだろう
両者の傾向は明らかに異なる。したがって、両者は異なるカテゴリであり、転置鍵の大きさは奇数であると推定される。次に、両者の間ではっきりと異なる傾向にある暗号文字を探す。VとXは奇数文字目に多く現れて偶数文字目には少なく、Fは偶数文字目に多く現れて奇数文字目に少ない。
転置鍵の大きさを推定する
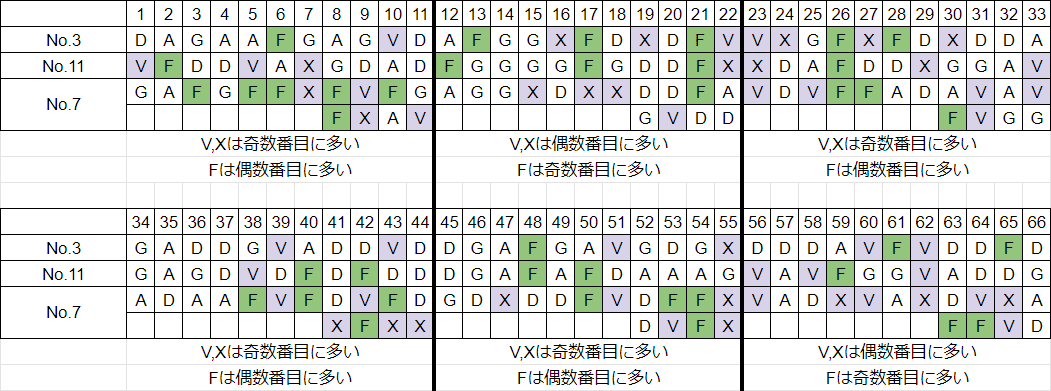
転置鍵の大きさが奇数であること、および暗号文字の出現傾向が分かった。ここで、暗号文を調べてみよう。No.3とNo.11は共に186文字からなる。これらを重ね合わせると、はじめのうちはVとXが奇数文字目に、Fが偶数文字目に多く現れる傾向が見えてくるだろう。もしこの傾向が逆転することがあれば、そこで暗号格子の一つの列が終わり、別の列が始まることを示唆している。このことに注意しつつ2つのメッセージを見ると、図6のようになる。

VとXを紫で、Fを緑で強調している
1~10文字目を見ると、VとXが奇数番目に多く、Fが偶数番目に多い。11~20文字目を見ると、逆にVとXが偶数番目に多く、Fが奇数番目に多い。このことは暗号格子の1番目の列が10文字目付近で終わったことを示唆している。21~30文字目でも再び逆転が起こっているが、その境目と思しき部分が見て取れる。22文字目にVとXが現れ、23文字目に再びVとXが現れていることである。つまり、22文字目で2番目の列が終わり、23文字目から3番目の列が始まっている可能性を示唆している。
ここで、暗号文No.3とNo.11について推定できることを整理する。
(1) おそらく1列目と2列目は11文字からなる。
(2) 暗号文は186文字なので、186÷11=16.9…より、転置鍵の大きさは17であると推定できる。
(3) 186=17×11-1であるから、11文字からなる「長い列」が16個と、10文字からなる「短い列」が1個存在する(図7)。

青は11文字からなる「長い列」を、オレンジは10文字からなる「短い列」を表す。
列を暗号格子上の位置の偶奇により分類する
転置鍵の大きさが17と推定できたところで、さらにもう1つの暗号文No.7に注目する。その文字数は254文字であり、254=17×15-1であるから、暗号文No.7は15文字からなる「長い列」が16個と、14文字からなる「短い列」1個から成り立つ。No.7に注目する理由は、No.3とNo.11と同様、「短い列」を1個だけ含んでいるからである。そして、No.7の列は、No.3及びNo.11の対応する列より、きっかり4文字だけ多い(「長い列」「短い列」問わず)。
それぞれの暗号文に1個だけ含まれる「短い列」がいつ現れるのかはまだ分からないが、仮にそれが最後に現れると仮定したうえで3つの暗号文を重ねてみる。すると図8のようになる。ここで、No.7には各列ごとに余る4文字(12~15文字目)は偶奇にさえ気を付ければどんな配置にしてもよいので、参考文書にならって8~11文字目の直下に置いた。
VとXを紫で、Fを緑で強調している
55文字目と56文字目の間に境目が見て取れる。このことから、暗号格子の最初の5個の列は、すべて「長い列」であると考えられる。つまり、No.3とNo.11の場合、最初の5列は全て11文字からなり、No.7の場合、最初の5列は全て15文字からなる。
これらの5個の列は、暗号格子ではどの位置にあっただろうか。奇数番目の位置か、偶数番目の位置かの2パターンである。そこで、5個の列を+と-に分類する。片方は奇数番目の位置を、もう片方は偶数番目の位置を表している。ただし、+と-がそれぞれ奇数・偶数どちらを表しているかはまだ分からない。
+と-の分類は、文字の出現傾向を基準にして行う。VとXが奇数文字目に、Fが偶数文字目に多く現れる場合を+とし、その逆を-とする。
ここで、奇数文字目・偶数文字目の数え方には注意を要する。ここでいう奇数文字目とは、「暗号文全体で」ではなく、「その列の中で」奇数文字目ということである。例えば暗号文の12文字目は、2番目の列の1文字目であるから、その列の中では奇数文字目である。
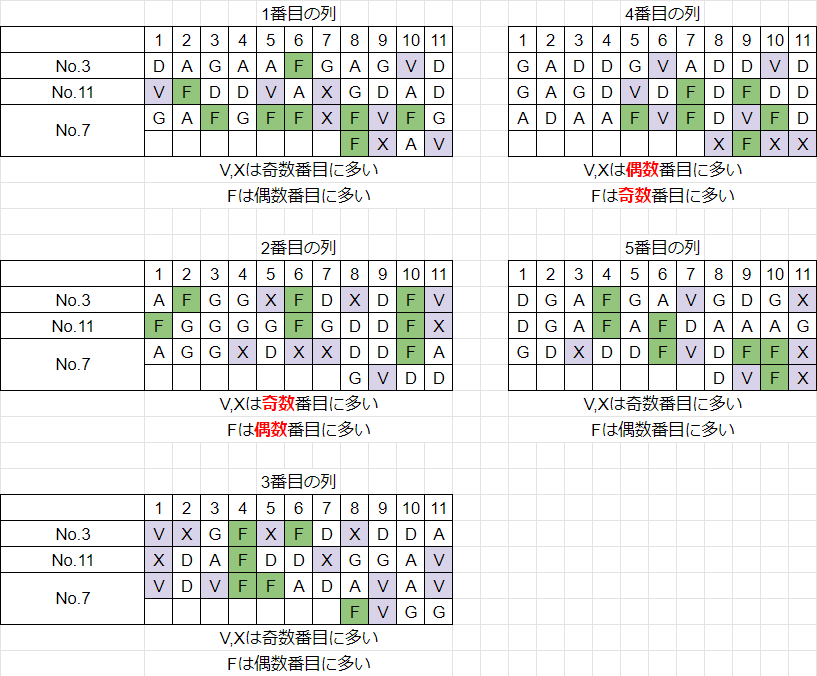
図8と奇数偶数の逆転が起きている部分を強調している
1番目の列はV,Xが奇数番目に、Fが偶数番目に多いので、+である。2番目も奇数偶数の逆転に注意しつつ数えると+である。以下同様にして数える。結果、最初の5個の列はそれぞれ+,+,+,-,+に分類される。
分類の内容を決定する
1~5番目の列が暗号格子のどの位置にあるかは未だ不明だが、手掛かりは得られた。他の列に関しても推測するために、数学的方法を使うことにする。図4、図5において各暗号文の最初の何文字かを拾い頻度分析を行ったが、これは転置鍵の大きさが25という仮定のもとで行ったものである。今、転置鍵の大きさは17と推定できている。つまり、もう少し多く文字を拾って、最初に行った分析を改良してみてもいいだろう。その結果を図10に示す。

左 頻度分析のために拾う文字列(赤は図4から増えた文字)
右 頻度分析の結果
次は暗号文No.5に注目する。文字数は202文字であり、202=17×12-2であるから、この暗号文は12文字からなる「長い列」15個の他に、11文字からなる「短い列」を2個持っている。これまでに見てきたNo.3、No.7、No.11と共通するものと、そうではなくNo.5にだけあるものである。この追加の「短い列」は、暗号文のどこに存在し得るか。
No.5の1番目の列が「短い列」だとしよう。このとき、2番目の列は(「短い列」ではないと仮定して)FXFXFFFVAGFDになるだろう。これらの文字を、奇数文字目・偶数文字目の出現回数に、頻度による重みづけを行ったものを足し合わせる。この計算値は、予測される頻度分布と、実際の出現回数が似た傾向にあるほど大きい値を取る。これを図11に示す。

上 図10で求めた頻度の場合
下 図10とは逆の頻度の場合
つまり、2番目の列が+(V,Xが奇数番目に多く、Fが偶数番目に多い)であると仮定したときの計算値は77、-(V,Xが偶数番目に多く、Fが奇数番目に多い)であると仮定したときの計算値は144である。したがって、2番目の列は-の分類になる。ところが、先の分析で既に2番目の列は+であることが分かっており、矛盾する。したがって、1番目の列は「短い列」ではないと判断できる。
No.5の2番目が「短い列」だとしよう。すると、3番目の列は(「短い列」ではないと仮定して)XAVDAGFDVDGFになる。先ほどと同様の計算を行うと、3番目の列が+である場合は136、-である場合は109となるので、+である。これは先の分析とは矛盾しない。
前述の推論がすべて正しければ、No.3などの2番目の列は「短い列」ではないが、No.5の2番目の列は「短い列」である。したがって、2番目の列の位置は16番目(最後から2番目)である。それは+に分類されるので、偶数番目の位置が+、奇数番目の位置が-に分類されることになる。このことを図12に示す。また、-に分類される列が9個、+に分類される列が8個になることも注目すべきである。

列の位置を確定する
No.3、No.7、No.11は1つだけ「短い列」を持つ。1~5番目の列は「長い列」であることが確定しているから、「短い列」はそれより後に現れる。6番目から17番目までそれぞれの列が「短い列」であると仮定した場合について、すべての列を+/-分類したものを図13に示す。
もし仮定が正しいのなら、次の2つの条件を満たさなくてはならない。(1)-は9個、+は8個である。(2)「短い列」と仮定した列そのものは+に分類されてはならない(「短い列」の位置は17番目であるから、その分類は-であるため)。
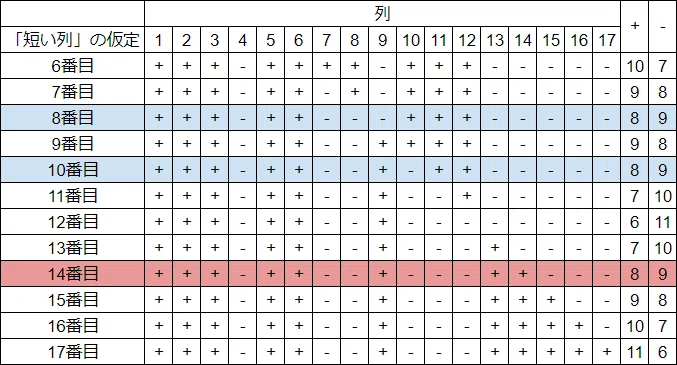
青は条件(1)(2)双方を満たす仮定、赤は条件(1)のみ満たす仮定を示す。
これより、8番目もしくは10番目の列が「短い列」である。これが暗号格子の17番目(最後)の位置に来る。つまり2番目の列と隣接している。
候補が2つに絞られたので、どちらかを決める。
まず、8番目の列が「短い列」である場合。No.3の2番目および8番目の列は次の文字列からなる。
2番目:AFGGXFDXDFV
8番目:GGDDAVGVFG
これらから、一次暗号文の暗号文字のペアFG, GD, FV, XV, FGの5つが得られる(図14)。

左 転置後の暗号格子(8番目の列まで) 2番目と8番目の列を緑で示す。
右 転置前の暗号格子 青は「始めの文字」、オレンジは「終わりの文字」を示す。「始めの文字」と「終わりの文字」からなる一次暗号文の暗号文字のペアが5つできている(矢印)
同様にNo.11からはGA, GD, FV, DD, FVの5つ、No.7からはGA, XV, XF, DX, FG, GD, DVの7つを得られる。これら17のペアの頻度分析を行う。すると図15の左のようになる。さらに、10番目の列が「短い列」である場合に同様の分析を行ったら図15の右のようになる。

どうやら、乱雑ではなくある程度まとまりのある8番目の列の方が「短い列」であるようである。
以上により、転置鍵の最後の2つは「2, 8」であることが推定できる。
解読完了まで
他の暗号文の「長い列」「短い列」に注目して、さらに転置鍵を決定することができる。暗号文No.12は224文字からなり、224=17×13+3である。No.6は120文字からなり、120=17×7+1である。よってNo.12は3個の「長い列」を持ち、No.6は1個の「長い列」を持つ。これらから、転置鍵の最初の3つが「16, 5, 7」であることが分かる……らしい。参考文書はここを略している。
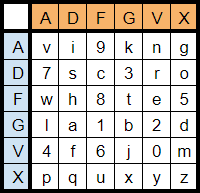
その後も過程を略し、最終的に得られる転置鍵が「16, 5, 7, 6, 9, 3, 14, 1, 13 ,11, 17, 4, 12, 15, 2, 8」であること、それが「VIKINGSCROWNHOTEL」の各文字をアルファベット順に数字に置き換え、同じアルファベットは左から小さい順に数字を割り振り、そうして出来たものであることを示し、最後に換字表を載せて、参考文書の解説は終わる。
ちなみに換字表を図16に示す。これもキーワードは「VIKINGSCROWNHOTEL」である。重複を省き、キーワード内にもしA, B, C, …, Jがあれば、その次のマスに1, 2, 3, … ,0を書き入れ、キーワードを書き入れ終わったらアルファベットを順に、上記同様の規則で数字も書いて作ったようである。
以上、かなりややこしい。この解法が出来たのは第一次世界大戦後であるため、コンピューターを必要とするものであるとは思えないのだが、一人でやっていたら時間がいくらあっても足りないと思われる。また、転置鍵の大きさが偶数だったらどうなるのか、など疑問は残る。文書の解釈に手一杯で、随分と煩雑な解説になってしまった。重ね重ね、簡潔な解説を求めて来た人がいたら、申し訳ない限りである。
まとめ
・ADFGVX暗号の解読は、まず転置鍵の大きさ(暗号格子の列の数)を決めることである。
・限られた中でもできる限りの文字を拾い、暗号文字の出現頻度分布を調べる。
・暗号格子には「長い列」「短い列」があることを考慮しながら、それらの列がどのような頻度分布に従っているかを見極める必要がある。
・暗号文によってどの列が長いか短いかが異なる。それを利用し、何番目の列がどの位置に来るかを推定することが出来る。
参考文献
・"General solution for the ADFGVX cipher system", National Security Agency
暗号文一覧
No.1(212文字)
VDDGGGVFDFVDVVFVDGADDAFFFVDXFDDXDVXADVDVFXGDFVADDGDGDGVGDDDFXFADAVDVGDGADXVDADADFXAVFVDDAAVDFFDFVGDFVDDGVDDDDAVADAFADDXADDGADFVGFVDGADVFXVXDGDDAGGDDXFFDDXADFGDAGXDDAVFDAFGVFVFAFFVFAFXGFXDGVADFVDGGAVGGDDGDVXAXFDDX
No.2(108文字)
VDAAVDDFXFXDDAXGXFXDDFXADVAGDDFAXDVAVDVDDFVFVFFGDGFVAXVXAVGDVDXFDXDGAXGFGGFVFGDFVDXAVXDDVGDDVGVAGFXFAAAXDDXG
No.3(186文字)
DAGAAFGAGVDAFGGXFDXDFVVXGFXFDXDDAGADDGVADDVDDGAFGAVGDGXDDDAVFVDDFDAAAADXAGDXAGGDDAVGVFGDVFVDGGXGGAFFVFDAXGDDDGDAFDADGGADDGDXAFVDFDXFVGDDVAVFDDDVFAGDFFFXAADFADGGVFDAVDGXFVDAAVGDXFGGDDXGDA
No.4(110文字)
ADXVFXVGGVFDDVAFGAAVFDGVDDDGDGFDVVAFGXFXFDDDDVGDAXDAXDDDAGVFFAADVGDFXGXGVGDDDDADVXVFAVDAXXDFAAFAVDVGVDVDDAXDAA
No.5(202文字)
DFXFDDVVVDXFXFXFFFVAGFDXAVDAGFDVDGFADAADFDVFGDADFVFVFXGXDDAGDVGVFDGXXDFFGDGXGVDDVDDFGFVGDDVFVAGXXDFVDXAVFGAGAGAXDVDFXGVGDADDXAGXDADFDGXFDGGFVGXVVGDDDAGXVDGVDVGXDDFDDVAGAADGDDFDGAGDFDDDDXGVGVGGGDGXDFGFAD
No.6(120文字)
GDGFXAGVFVDDXGXDVDDAXDAAXFAGVGDXFFVXFADGFFDXAAFVXFDFXFVGDGFXFDVVXVGDFVDDVFDFVVDVDGGVFXFGVXFFVGVDDGDDDDGDDAVGVXGAFFXFVDDD
No.7(254文字)
GAFGFFXFVFGFXAVAGGXDXXDDFAGVDDVDVFFADAVAVFVGGADAAFVFDFVDXFXXGDXDDFVDFFXDVFXVADXVAXDVXAFFVDFDGXFDGFDDFVDVVAAFVFFVXDGFDDVADDFDDDXFFAGFXFXAAGVDGGVDFGGGXDFDFVAFFGFXGDAXDGDGGDDAVDXADFAFVFXDDXVAGDVVDDFXDGXXDVFVFDDDDAAFDFXDXGDAAFVDFDVDDVADDVDVAVDGAFVFXFAAVDDFVD
No.8(144文字)
DGVVGFXGGGADFAFVVVAXAVGGVVDVGVVDAVGDGDGAVFDDADDDXXDXFVFXGVGGDGDFGGDADFDDXAVFDDVFADXGDADGVAFFXADFADXDGFADFDDGVDVXAVADDXFFAGDXFFVFGFGFDFDVDXXDDGGD
No.9(182文字)
GDDDDXVGVDVDAVGFGDFVDVAVDGFAGXAVFFGVADDDAXXAXDGADGXAVVDGXXAAAVADADGXDVGDDDDGVFXAAVGGVFXDAFDGVGAFGDDFAVVGDDVDFXDVDGFVAAGDXFDVAADAGDAXFVGDDDAGVAVFGXXFDDGXFVDGGDAVDAGGFDAXDXFFVGFAXXADDF
No.10(130文字)
DGDDFVFAVDVFDADGFVGVGGDFVDVVXDDFDDVGXGVDXGVGDXDGDXFXFDXVDAADDFXDDAFFAAFVFAGDAAGGFAXGVXXFXADGDFDGXGDADAXGVVVDAAGGVFGVAVFVAAGAXGXDGA
No.11(186文字)
VFDDVAXGDADFGGGGFGDDFXXDAFDDXGGAVGAGDVDFDFDDDGAFAFDAAAGVAVFGGVADDGDDFGFVDDADFGAFDFVDDFVVVADAGDXFXXXFFDXGDFDGFDDFGDAGFAAGGADXDGVDGAVGVDFDDFXGAGXFGVFVVDGVDXDFFFXGXGXAGAGVGDVVXGFVDXDDXFVDDx
No.12(224文字)
XFDFXVVDVDAVDADVFAGDGVADDFDAADXADFVGVDGFXFGDVFVDDDDGDVVAVVVFADDAXAVFVADAXDVGDDFAXDDGXGVFXAVXVFDGDXDFDVXADVAVAVGVDDDAFDFADVFFVVGDAGFXDDFADVXVDFXFFVVGFXXGFVAVFAGGDAVVDXDXGDDVVADDDAGAAGXFGDDDGVFGFVGVXGVFDFFDAADVDDXGDFDDVDDGAFGD
解読文は割愛する。
この記事が気に入ったらサポートをしてみませんか?