論文解説 MotionMaster: Training-free Camera MotionTransfer For Video Generation

Project page : https://sjtuplayer.github.io/projects/MotionMaster/
arxiv : https://arxiv.org/abs/2404.15789
github : https://github.com/sjtuplayer/MotionMaster

ひとことまとめ
カメラの動きを学習なしで別の動画から転用する手法を提案
概要
画像や動画の生成においてDiffusion modelは急速に発達している。しかし既存のカメラコントロールの手法の多くは追加で学習するモジュールに依存している。また、固定のカメラモーションのみに対応しており、柔軟性が低い。提案手法のMotionMasterでは、参照動画のカメラと物体の動きを生成する動画のガイドとして利用できる学習なしの手法を提案する
関連研究
物体の動き制御
物体の動き制御はバウンディングボックスをドラッグしたり、軌跡を指定することで行う研究がいくつかある。また、VideoCompserではピクセル単位の動きを条件にして生成を行っている。
これらの研究は物体の動きそのものに焦点を当てている
カメラ動き制御
いくつかの研究ではカメラの動き制御も行われている。AnimateDiffではtemporal LoRA modulesを似たカメラの動きで学習させる。しかしこの場合はLoRA一つに単一の動きしか割り当てができない。MotionCtrlではカメラポーズをアノテーションした動画で学習しているが、アノテーションコストがかかる。
Direct-a-Videoはカメラの動きを座標で条件付けしたが、ファインチューニングが必須になっている。
一方、提案手法では再学習なしに柔軟なカメラ動き制御を実現し、さまざまなアプリケーションへの適用を可能にする。
提案手法
提案手法は動きをカメラそのものの動きと物体の動きに分離し、カメラの動きだけを転用する。転用のやり方は2つあり、単純な1動画を使用する場合(one-shot camera motion disentanglement)と、少数の動画を使用する場合(few-shot camera motion disentanglement)で条件の与え方を変える。
one-shot camera motion disentanglement
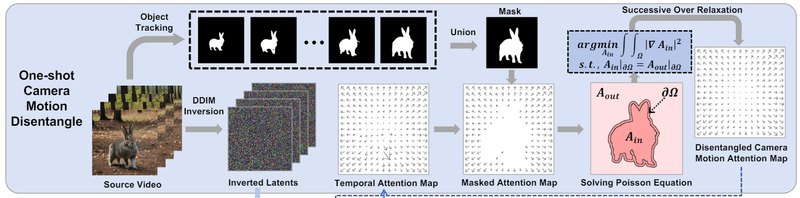
背景はカメラの動きのみの影響を受けると考えられるため、背景のみから動きを抽出すれば直接カメラの動きを計算できる。Segment Anythinを使い背景部分のみを抽出し、それらの動きを計算する。カメラの動きによるピクセルの変化はなめらかであり、距離が近いものは移動方向や距離も似たものになるはずなので、ポアソン方程式を用いてカメラの動きを推定した。
物体の動き推定
物体の動き推定は、分割した物体内での動きを同様に推定すればよい。背景の動きと異なり、同一物体は同じ方向に動くと考えられるため、内部の動きの勾配が小さくなるような制約を追加している。
Temporal Attentionを利用したカメラ動き抽出
Temporal Attentionはフレーム方向にAttentionを計算するモジュールで、AnimateDiffなどで用いられている。我々はこのTemporal Attentionではカメラの動き、物体の動き両方が組み合わさっていることを見つけた。そこで、このAttention Mapを転用したい動画のAttention Mapと入れ替えることで動きを移し替えることができる。
DDIM inversionを用いたAttention Mapの抽出
空間方向の(Spatial) Attention Mapと異なりTemporal Attention Mapはdenoiseの段階によらず似たような行列となる。そこで適当な時間で取得したTemporal Attention Mapをすべてのdenoiseの段階で用いる。ここで、取得する時間は中間に近い値が望ましい(小さいとほぼ画像が完成し情報がすくなく、大きいとノイズの影響が大きいため)。
few-shot camera motion disentanglement

物体の動きとカメラの動きを分離するのが難しい場合、1つの動画ではうまく動きを転用できない。そこでいくつか(5~10)の似たような動きの動画から1つの動きを生成する。
先ほどと同様にTemporal Attention Mapをすべての動画で計算し、近傍($${k \times k}$$)ごとに分割する。そしてDBSCANを用いてクラスタリングを行い、いくつかのクラスタを生成する。その中で最も大きなクラスタのcentroidは動画の基本的な動きと考えられるので、それを別の動画に転用する
カメラモーションの組み合わせ
カメラモーションを複数のTemporal Attention Mapを混ぜ合わせることで狙った動きを再現する。ここでは3つの方法を説明する。
1.重み付き平均

複数のAttention Mapを加算することで実現する。ほんとにただ加重平均をとるだけ
2.領域ごとの重み付き平均

重みの付け方をそれぞれのモーションごと、座標ごとに変更したもの。特定のモーションの特定の領域のみを転用するときなどに適している
3.特定の領域の見た目を維持

Temporal AttentionのValueには見た目の要素が格納されている。特定の領域の見た目を維持するためには、このValueを別の動画から持ってくる必要がある。式では見た目を適用したい動画のValue ($${V_t}$$)と、計算対象の動画のValue ($${V}$$)を重みづけしながら加算することで見た目の転用を実現している。
実験

提案手法は学習を全く行わない手法であるが、大量に学習を行ったMotionCtrlのようにカメラの動きを転用できていることがわかる。また、AnimateDiff + Loraではもとの動画の情報を保持してしまいキャプションを無視しているが、提案手法は1つの動画から動きだけを転用できていることがわかる。

多少複雑な動きであっても問題なく転用できていることがわかる。

学習を行わない手法でありながら、AnimateDiffやMotionCtrlに匹敵する精度で動画を生成することができる

また、専門的な動きの可変速ズームやDolly Zoomなどでも動きを自然に転用することができていることがわかる。
まとめ
カメラの動きを学習なしで転用するMotionMasterを提案
Temporal AttentionのAttention Mapをうまく用いることでカメラの動きを別の動画に転用することができる
実験では学習が必要な他の手法より優れた精度を示す
この記事が気に入ったらサポートをしてみませんか?