論文解説 ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization

arxiv : https://arxiv.org/abs/2406.04312v1
github : https://github.com/ExplainableML/ReNO
ひとことまとめ
OneStepの推論モデルの初期ノイズに報酬モデルからの勾配を加算することで品質を向上させた
概要

拡散モデルは主流な画像生成手法の1つで、画像をランダムにノイズを加え、そのノイズを予測することでモデルの学習を行う。また、画像生成時はランダムなノイズ画像から少しづつ画像を取り除くことで画像を生成する。生成品質は高いが、生成に時間がかかる問題があった
そこで、少ないステップ数で高品質な画像を生成する手法が開発された。
数ステップで推論できるものや、1ステップで推論できるモデルの研究が盛んにおこなわれている。しかしながら複雑なプロンプトに沿った生成ができない場合が多い。そこで、本研究では初期ノイズに報酬モデルからの勾配を加算していくことで、よりプロンプトに沿った画像生成を行う手法を提案する
提案手法
通常のDiffusion Modelは画像生成に複数ステップの推論が必要である。そのため、単純に誤差逆伝播するのが難しい。いくつかの研究ではDiffusion Modelの勾配計算を行う手法が提案されているため、モデルに入力する初期ノイズの最適化も行うことができる。しかしながら10~40分程度時間がかかる問題がある。
そこで1ステップで推論できるモデルを使用することで初期ノイズの調整を20~50秒程度に短縮する
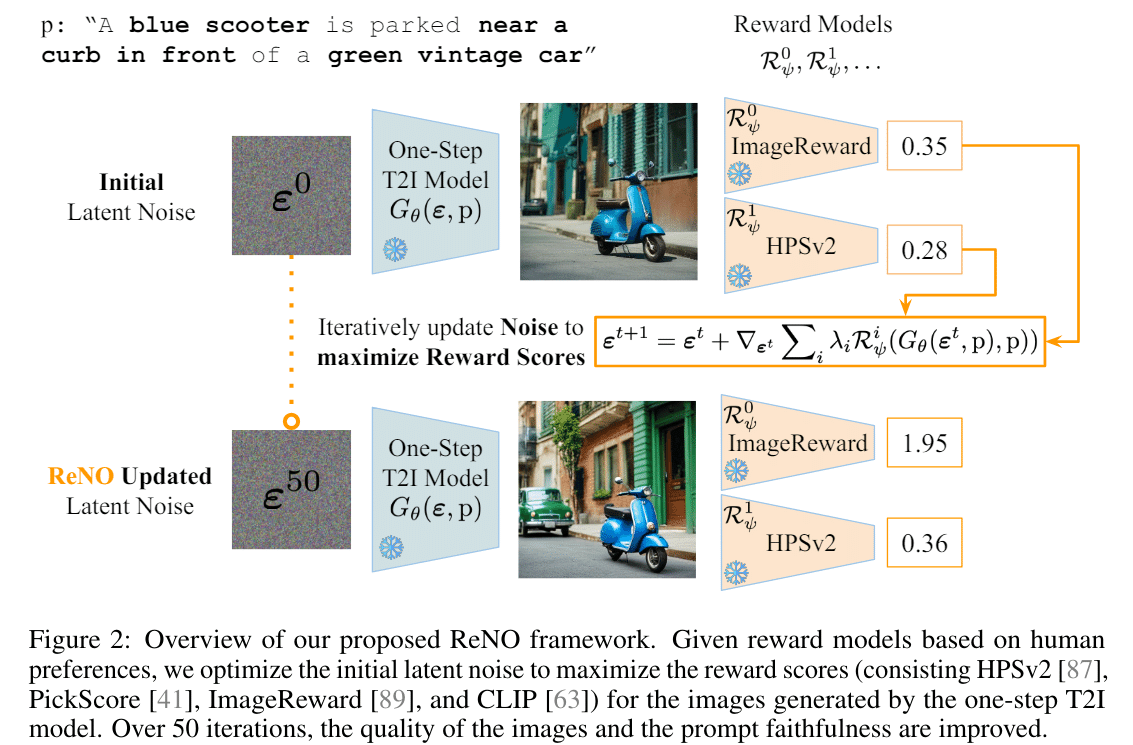
提案手法は画像のように、画像生成モデル$${G_{\theta}}$$、報酬モデル$${R^{0…N}_{\psi}}$$の2つを用いて初期ノイズを修正する。
$${G_{\theta}}$$とは、1ステップで推論できるSDXL-Truboなどのモデルのことで、$${R^{0…N}_{\psi}}$$は画像からその画像の品質・キャプションとの一致度などを計算するImageRewardやCLIPなどのモデルのことである。
まず、ランダムな初期ノイズを用いて画像を生成させ、次にそれらを報酬モデルに入力する。それらの報酬モデルの報酬が高くなる方向の勾配をもとめ、それを初期ノイズに加算し、再度画像を生成する。これを何度も実行することで初期ノイズを良い画像が生成できるノイズへ調節していく。
ノイズ正規化
重要なこととして、モデルに入力するノイズは正規分布に基づく数値でないと正常に画像が生成できない可能性がある。そこで、ノイズを正規分布に近づける項を最適化の関数内に入れ、極端に正規分布から外れないように制約をつける。

上の式のようにノイズ$${\epsilon}$$が正規分布からサンプリングされた場合のノルムと近くなるように正則化$${K(\epsilon)}$$を加える。これらの項は$${d}$$次元の正規分布のノルムの分布($${\chi^d}$$分布)の対数尤度から計算される
最終的な損失関数は以下のように

報酬モデルの報酬$${\tilde{C}(X_0)}$$とノイズの正則化項$${K(\epsilon)}$$を足し合わせたものとなっている
実験

提案手法は比較的品質の悪い1ステップ生成モデルに適用することで、他の複数ステップ手法に匹敵する生成能力を示した。特にHyperSDXLはDALL-E3を除くほかの手法よりもほぼすべての指標で上回っている

また、GenEvalベンチマークではDALL-E 3に4/6項目で勝つなど、非常に強力な手法であることがわかる。ただし、PositionやColor Attributionなどの指標で大きく差がある

User StudyではSD3などパラメータ数で劣る場合でもより好まれる傾向が高いことがわかる
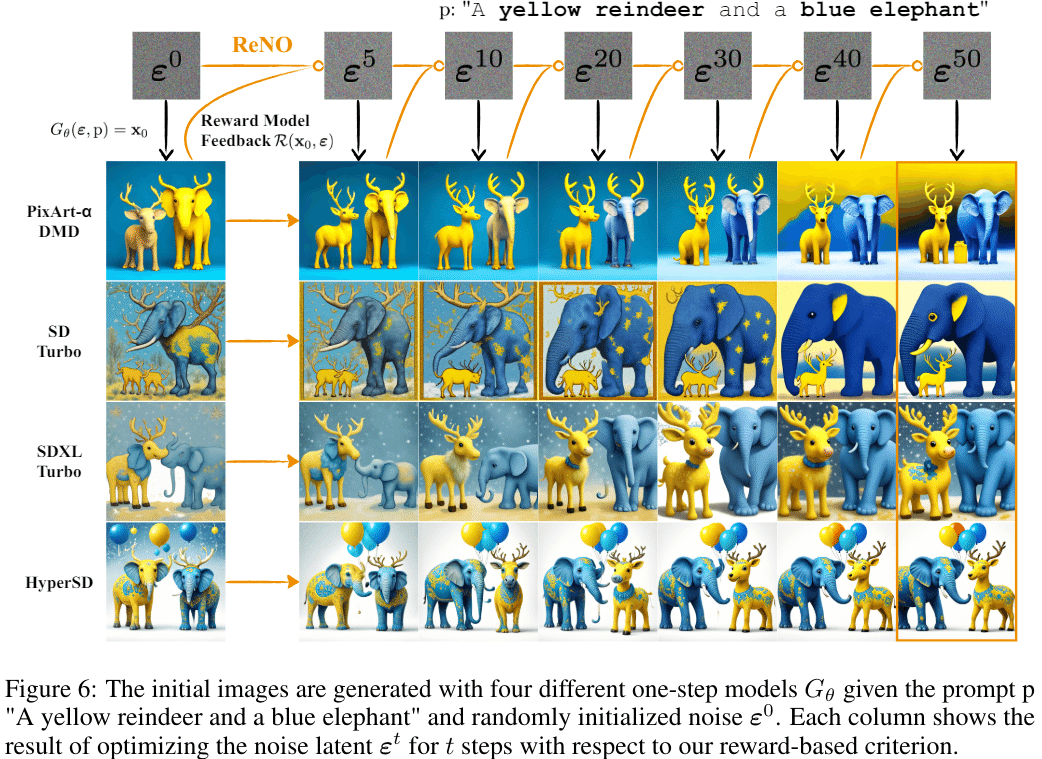
また、各イテレーションでの生成画像を可視化すると上のようになり、最初にテキスト通りに生成できていない画像が徐々にテキスト通りに生成されるように変化しているのがわかる
まとめ
ファインチューニングなしで画像生成の品質を向上させる手法を提案した
初期ノイズを調整することでモデル性能を底上げし、DALL-E 3などの商用モデルに匹敵する性能を実現できる
User Studyでは、SD3などパラメータ数で劣る場合であっても提案手法のの性能が上回る場合があることを示した
この記事が気に入ったらサポートをしてみませんか?