論文解説 An Image is Worth 32 Tokensfor Reconstruction and Generation

project page : https://yucornetto.github.io/projects/titok.html
arxiv : https://arxiv.org/abs/2406.07550
ひとこと要約
画像1枚をたったの32token×12bit=384bitに圧縮するモデル
概要
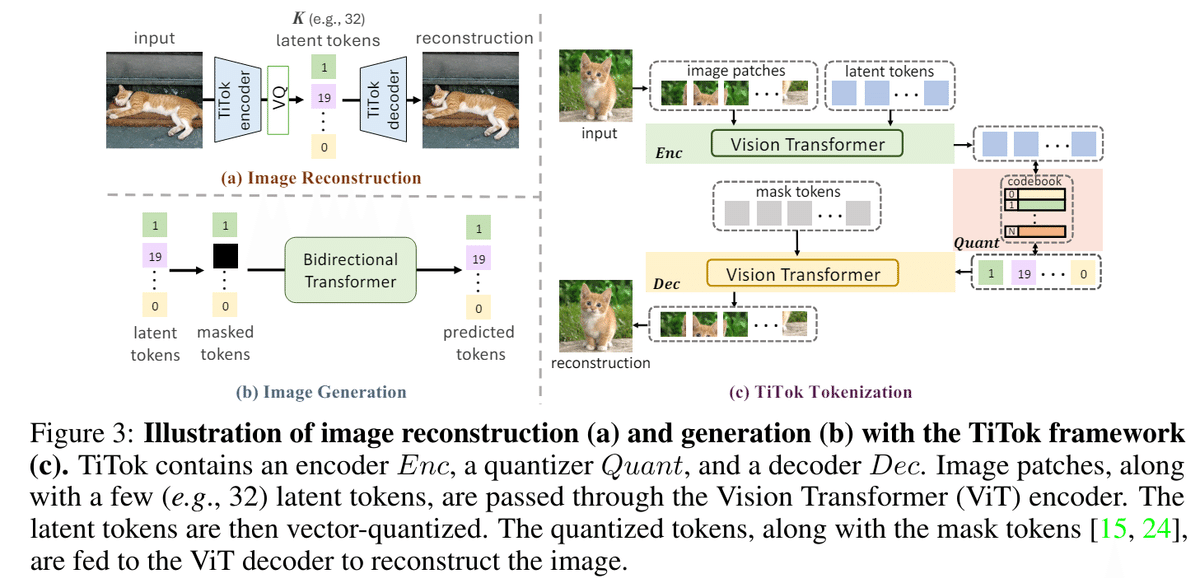
画像を離散トークンに変換する手法はVQGANが主流であるが、圧縮倍率はそれほど高くない。一般的に使われるVQGANは256×256の画像1枚であれば16×16=256個の離散値に変換される
これはCNNの構造を利用したボトルネック構造のAutoEncoderに離散値化処理を追加した形式であることに起因するが、Transformerを利用し情報を圧縮したトークンだけdecoderに伝えることで32トークンという極めて少ないトークン数で画像を表現できるようにした
関連研究
VQVAE

VQVAEは画像を固定の離散値ベクトルに変換する手法で、画像を低次元の離散値に変換する手法の1つ。例えば256×256解像度の画像を16×16の解像度の離散値に変換できる
手法としては、中間特徴量をトークンの集合(codebook)の中で最も近いトークンに変換する。つまり学習時はcodebookのトークンに変換し、離散値が欲しい場合はそのトークンのインデックスに変換することで実現している
VQGAN

VQGANはVQVAEにGANの手法を取り入れた方法。VQVAEは単体で用いると再構成誤差のみで学習するためボケが多い。そこで敵対的学習を行うことでボケが少ないリアルな状態で再構成できる
提案手法
提案手法であるTiTokは画像トークンと潜在変数を合わせてEncoderのTransformerに入力し、潜在変数のみを量子化し画像トークンは破棄する。その後画像トークンの代わりになるMaskトークンと量子化した潜在変数をDecoder Transformerに入れ画像を再構成するように学習する。
たったこれだけの非常にシンプルな手法であるが、画像の視覚的情報の大半を固定のトークンに押し込むことができる。
2段階学習
TiTokでは性能を上げるために2段階の学習手法を取り入れている
1. warm-up
1段階目では画素を直接推論する代わりにMaskGIT-VQGANで生成した離散コードを推測するように学習する。これにより複雑な損失関数やGANアーキテクチャになることを回避できる(おそらく入力は画像)。つまりこの段階では画像を32のトークンに圧縮することだけをモデルに教え込んでいる。
2. decoder fine-tuning
2段階目では、Museなどで取り入れているように再構成品質を向上させるためにdecoder部分のみを再学習する。このとき、離散コード予測からRGBの値を直接推測するようにしている。(敵対的損失も追加されている)
画像生成への応用
既存のMaskGiTや自己回帰などの離散コードを生成する手法を用いてTiTokの離散コードを生成し、画像として復元することができる。それを示すため、MaskGiTを用い画像生成の性能をテストした。
なお、画像をより低次元のトークンに圧縮しているので、学習スピード(1秒あたりの画像数)が12.8倍、推論速度も4.5倍と高速化した。
実験

提案手法は他の手法と比較しても謙遜ない性能をしめしている。特にスループットが極めて高く、小さいモデルであれば1秒間に100枚(!!)も生成でき、最も大きいモデルであってもDiT-XL/2の10倍以上高速により品質の高い画像を生成できる。

また、解像度を上げた場合でも他の手法と異なり推論速度の悪化があまり発生せず、ほぼ変わらない速度で画像生成を行うことができる
まとめ
TiTokは1つの画像をたったの32トークンで圧縮できることを示した論文
従来よりもトークン数が少ないにも関わらず、画像生成の精度は変化しないことを示した
画像生成速度も他の手法と比べ非常に高速であり、画像生成と非常に相性が良い
この記事が気に入ったらサポートをしてみませんか?