論文解説 LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control


project page : https://liveportrait.github.io/
arxiv : https://arxiv.org/pdf/2407.03168
code : https://github.com/KwaiVGI/LivePortrait
ひとことまとめ
超高速で動くポートレート動画変換
概要
写真をポートレート動画にする研究はGANやDiffusionなどで数多く研究されている。しかしDiffusionベースのモデルは品質は良いものの、大量の計算リソースを使用する問題点と、細かな制御が利かない問題があった。そこで、暗黙的なキーポイントを使用したポートレート動画生成を行うことで、汎化性能、計算効率、制御性を向上させた。(ここで言う暗黙的なキーポイントとは、モデルに教師なしで学習させ、生成したキーポイントのことを指す)
関連手法 vid2vid
vid2vidでは、以下の5つのモデルを使用する。
appearance feature extractor $${\mathcal{F}}$$
canonical implicit keypoint detector $${\mathcal{L}}$$
head pose estimation network $${\mathcal{H}}$$
expression deformation estimation network $${\mathcal{\Delta}}$$
warping field estimation $${\mathcal{W}}$$
generator $${\mathcal{g}}$$
まず、ソース画像をappearance feature extractorを用い3D外見特徴量に変換する。ソース画像の3Dキーポイント $${x_s}$$と制御動画の3Dキーポイント $${x_d}$$は以下のように計算される

ここで、$${x_{c,s} \in \mathbb{R}^{K \times 3}}$$はソース画像のcanonicalキーポイントを表しており、$${R_sとR_d \in \mathbb{R}^{3 \times 3}}$$はポーズ(向き)を表す。
$${ \delta_s と\delta_d \in \mathbb{R}^{K \times 3}}$$は表情の変形を表し、$${t_sとt_d \in \mathbb{R}^{3}}$$は平行移動を表す。
次に、warping field estimationは暗黙的なキーポイント表現$${x_s, x_d}$$を用いソース画像の3D外見特徴量を変形する。その後、generatorに入力し、画像に変換する。
以下はvid2vidに掲載されているキーポイントの変換例である。

提案手法
Stage I: Base Model Training
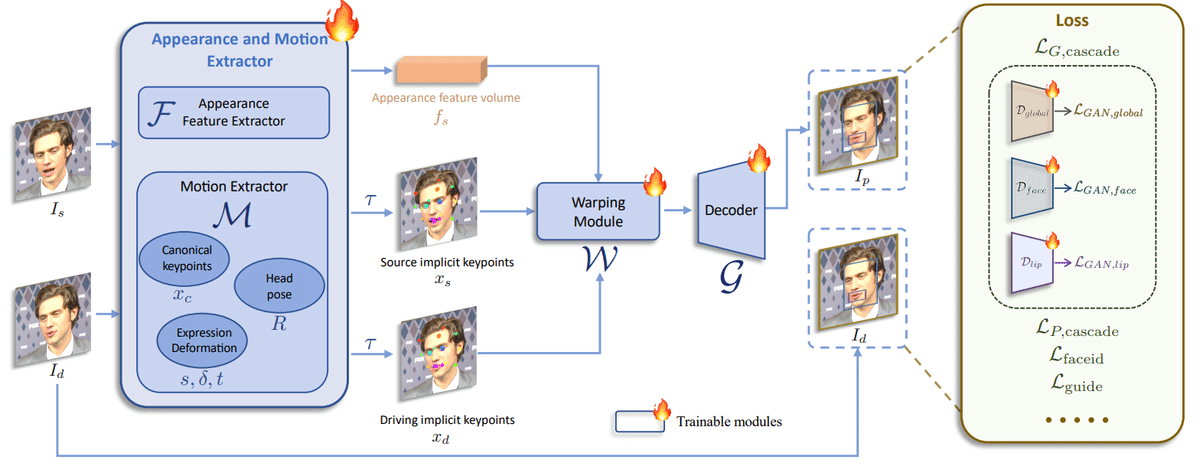
vid2vidをベースとして、いくつかの変更を行う。これにより、アニメーションの感情表現を強化し、モデルの汎化性能を向上させた。
High quality data curation
学習にはVoxceleb, MEAD,RAVDESSなどの公開されているデータセットを用いた。同様に、スタイル画像としてAAHQも使用した。追加で4K解像度の200時間分ポートレート動画を収集した。また、LightStageデータセットも利用している。
動画は30秒未満に分割され、1人のみ映るようにトラッキングと認識を行った。学習データの品質を維持するため、KVQ(画像の品質評価モデル)を用いフィルタリングした。最終的に得られたのは69M動画で、18.9Kの人物が60Kのスタイルのポートレートで映っている。
Mixed image and video training
実際のポートレート動画だけで学習する場合、実写であればうまくいくものの、アニメなどのスタイル画像ではうまくいかない。これらの動画は非常に少なく、1.3Kクリップで、100人以下の多様性しかない。対照的に、スタイル画像は約60Kと大量にあり、それぞれが別人である。この両方を利用することで、1枚の画像から動画を生成できるようになる。この混合学習により、モデルの汎化性能を向上させた。
Upgraded network architecture
以下の3つのモデルを1つのモデル $${\mathcal{M}}$$ に統合した。
canonical implicit keypoint detector $${\mathcal{L}}$$
head pose estimation network $${\mathcal{H}}$$
expression deformation estimation network $${\mathcal{\Delta}}$$
このとき、バックボーンとしてConvNeXt-V2-Tinyを用い、canonical keypoints, head pose, expression deformationを画像から直接予測する。generator $${\mathcal{g}}$$はSPADEデコーダを用いることで、vid2vidよりも強力な表現をできるようになった。
Scalable motion transformation
vid2vidのキーポイント変換(1)は、スケールを無視しており、expression deformationに強く依存するほか、学習が難しくなっている。このため、スケールを追加した変換を以下のように修正する。

ここで、$${s_s}$$と$${s_d}$$はソース画像、制御動画のスケールの倍率で、スケール直交射影 $${x = s \cdot ( (x_c + \delta) R ) + t}$$とは異なる。このスケール直交射影は$${\delta}$$が柔軟に学習できすぎるため、テクスチャがちらつく。そのため、(2)式のような定式化で学習する。
Landmark-guided implicit keypoints optimization
vid2vidはウインクや目の動きなど表情の表現が足りない部分がある。特に、生成画像の目線は頭の向きと並行で固定されている。これは目の動きなどの微表情は教師なし学習ではうまく学習できないことを示唆している。そこで、2Dのランドマーク検出を行うことで微表情をうまく学習させる。ランドマークガイド損失$${\mathcal{L}_{guide}}$$$${\mathcal{L}_{guide}}$$は以下の式で表す。

$${N}$$は選択したランドマーク数、$${l_i}$$は$${i}$$番目のランドマーク、$${x_{s,i,:2}}$$と$${x_{d,i,:2}}$$はそれぞれの対応する暗黙的なキーポイントの最初の2次元成分であり、Wing loss(参考)を採用した。この研究では$${N}$$を10に設定し、目と唇の動きを対象にした。
Cascaded loss term
以下の損失関数を使いモデルを学習する
$${\mathcal{L}_{E}}$$ : 変換後のキーポイントと生成画像のキーポイントを一致させる
$${\mathcal{L}_{L}}$$ : 推定した画像のキーポイントが顔全体に広がるようにする損失。近づきすぎると損失が大きくなる
$${\mathcal{L}_{H}}$$ : 予測した頭部の回転量と実際の回転量の差を小さくする損失。実際の回転量の推定には事前学習済みモデルを使用した
$${\mathcal{L}_{\Delta}}$$変形の絶対量に対して計算される損失で、表情の変化によるcanonicalキーポイントの変形は小さいはずという制約
$${\mathcal{L}_{P,cascade}}$$ : 画像全体および顔と唇それぞれに対するperceptual loss
$${\mathcal{L}_{G,cascade}}$$ : 画像全体および顔と唇それぞれに対するGAN loss。画像全体および顔と唇それぞれで別のDiscriminatorを用いている
$${\mathcal{L}_{faceid}}$$ : 顔のアイデンティティが保持されるようにする損失
$${\mathcal{L}_{guide}}$$ : さきほど説明した、目や口の動きを近づける損失
最終的な損失は以下のようになる

これらを用い、1段階目では0から学習する。
Stage II: Stitching and Retargeting

暗黙的なキーポイントはポーズと異なり明示的に表情を制御できないが、暗黙的なブレンドシェープでこれを実現する。これは小さなMLPで十分学習することができる。提案手法では目と唇を対象としている。stitching moduleは肩の部分などのピクセルが足りない問題を修正するため、動画化したポートレートを元画像に直接貼り付ける。これにより、大きな画像サイズや複数の顔を同時に生成できる。(実験の画像がわかりやすいが、顔位置を元の画像に戻し、動きだけ反映するようなイメージ)
目のretargeting moduleは目の開閉具合をコントロールするために用い、唇のretargeting moduleも同様に使用する。
Stitching module
学習時、Stitching module($${\mathcal{S}}$$)はソース画像と制御動画のキーポイント$${x_s}$$,$${x_d}$$を入力とし、その変形差分$${\Delta_{st} \in \mathbb{R}^{K \times 3}}$$を推定する
1段階目の学習と異なり、ソース画像と制御動画が別々の動画から参照される割合を増やし、一般的な使用法での性能を向上させる。$${\Delta_{st}=\mathcal{S}(x_s,x_d)}$$は制御動画のキーポイントを$${x'_{d,st} = x_d + \Delta s_t}$$とし、予測画像は$${I_{p,st} = D_W(f_s; x_s, x'_{d,st})}$$と計算される。自己再構成画像は$${I_{p,recon} = D_W(f_s; x_s, x_s)}$$と表され、損失は以下のようになる

ここで、$${\mathcal{L}_{\textrm{st,const}}}$$は肩部分の再構成誤差で、$${\Vert \Delta s_t \Vert_1}$$はstitching 変形の$${L_1}$$正則化である。
Eyes and lip retargeting module
目のretargetingモジュール$${\mathcal{R}_{eyes}}$$はソース画像の暗黙的keypoints$${x_s}$$とソース画像の目の開き条件$${c_{s,eyes}}$$とランダムな目の開き具合$${c_{d,\text{eyes}} \in [0, 0.8]}$$を入力とし、変化$${\Delta_{\text{eyes}} \in \mathbb{R}^{K \times 3}}$$を$${\Delta_{\text{eyes}} = \mathcal{R}_{eyes}(x_s; c_{s,\text{eyes}}, c_{d,\text{eyes}})}$$のように予測する。目の開き条件は大きければ目を大きく開くような条件である。同様に、唇のretargetingモジュールも予測する。(ほぼ一緒なので割愛)
最終的な損失関数は以下のようになる
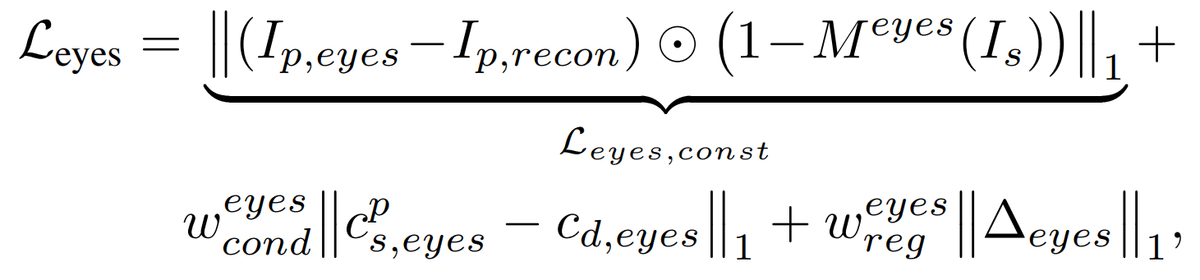
ここで、$${M^{eyes}}$$は目の部分以外をマスクする操作である。
Inference
推論時は、まず3D特徴量$${\mathcal{f}_s=\mathcal{F}(I_s)}$$とcanonicalキーポイント$${x_{c,s}=\mathcal{M}(I_s)}$$をソース画像$${I_s}$$から計算する。制御動画$${\{ I_{d,i} \mid i = 0, \ldots, N - 1 \}}$$を抽出し、$${s_{d,i}, \delta_{d,i}, t_{d,i}, R_{d,i} = M(I_{d,i})}$$と、条件 $${c_{d,\text{eyes},i}}$$ and $${c_{d,\text{lip}}}$$を計算する。

ここで、$${\alpha_{st},\alpha_{eyes},\alpha_{lip}}$$は0~1の数値をとる調整値で、最終予測はwarping network$${\mathcal{W}}$$とdecoder$${\mathcal{D}}$$を経由して生成される。アルゴリズムは以下のようになる。

実験

提案手法は他の手法と比較し目や口の動きをきちんと反映しており、大きな動きでも安定して生成できる。

元画像と制御画像で異なる画像を使用しても非常に自然に顔を生成できる。特に目と口の動きの再現度が高い。


提案手法はほぼすべての評価指標で他の手法よりも圧倒的に精度が向上していることがわかる。特に眼球の動き(MAE)の精度が圧倒的に高いことがわかる。
まとめ
緻密な制御と高い推論性能を持つポートレート画像を動画化する手法を提案
RTX4090で12.8ms(78fps)という圧倒的な推論速度を実現
目の動きや唇の動きを正確に反映し、定性的・定量的にも非常に高い精度での変換を実現
この記事が気に入ったらサポートをしてみませんか?