
Imaginary Dictionary -未来を編む辞書

はじめに
こんにちは、メディア研究開発センターの浦川です。
この記事では、本日12月21日から東京・六本木にあります21_21 DESIGN SIGHTで開催される「2121年 Futures In-Sight」展にて展示中の作品「Imaginary Dictionary -未来を編む辞書」についてご紹介します。
この作品は、デジタル技術を生かしたアート作品の制作などを行うQosmo, Incとの共作による「未来を編む=未来に存在している(かもしれない)語の収められた辞書をつくる」といったプロジェクトです。
はたして、どういった過程を経て「未来を編む辞書」がつくられているのか。今回はその裏側についてお話ししてまいります。
作品について




この作品は、未来に存在しているかもしれない新しい言葉や、既存の言葉の新しい意味などを鑑賞しながら、遠い将来の姿を想像するような作品です。
今回は、保有する約30年分の記事データから将来の言葉の環境を推測し、そこから新語とその意味を生成しています。
「新語の推測」と「新語の生成」と工程を2つに分けながら、その内容を以下でご紹介していきます。
辞書ができるまでー新語の推測ー
ここからの項は、実際に新語推測を担当した新妻が紹介いたします。
この「新語推測」とは、誤解を恐れずに言えば統計モデルを使って未来の語彙を想像した、というプロセスになります。
もう少し具体的に言えば、過去約30年分の朝日新聞の記事データから単語の意味の時間変化を捉えて、その変化をさらに現代の単語の意味に外挿することで未来の単語の意味を推測しています。
こう説明してしまうと「いまはAIを使えばそんなことができちゃうの!?」と思ってしまうかもしれません。しかし、ぶっちゃけてしまうと「未来の単語を予測する」技術というのは、この2021年の時点ではおそらく存在しておりません。
なので、本作品では自然言語処理における単語埋め込みという技術をもとに、〈通時的に単語の意味の変化を捉える研究〉と〈単語埋め込みの中のバイアスを取り除く研究〉を組み合わせて、単語の意味の変動を捉えて外挿する仕組みを考案しました。
そのため、この作品における新語推測は「確実にこの単語が100年後に登場する」というものではなく、「単語埋め込みから読み取れる変化がもし今後も同じくつづくとすれば、こういう意味になるかもしれない」という提案をする技術となります。
それでは、具体的な解説に入っていきましょう。
まず次の重要な3つの要素技術について軽く触れます。
・単語埋め込み
・通時的単語埋め込み
・単語埋め込みのバイアスを取り除く技術
そして、最後にそれらを使ってどうやって、未来の単語埋め込みを作ったのかを解説します。
単語埋め込み
単語埋め込みとは、数百次元のベクトル空間に、類似した単語が近くなるよう配置する統計モデルです。これは言語学において「単語の分布仮説」と呼ばれる「単語の意味はその周辺によって特徴付けられる」という仮説に基づいています。
その単語埋め込みの特徴を三次元にして簡略化したもので、説明すると次の図のようになります。
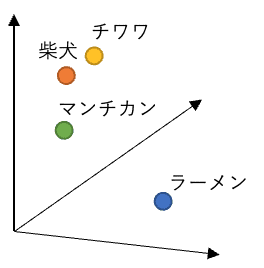
単語埋め込みは、単語の意味の近さをベクトル空間内の位置で表現するものです。そのため、「柴犬」と「チワワ」は同じ犬種を表す単語であり、非常に近い単語です。また、同様にペットである猫の種類である「マンチカン」も、犬種同士ほどではないですが「柴犬」や「チワワ」の近くに配置されそうです。一方で、「ラーメン」という単語は他の3つの単語と比べると使われる文脈が非常に異なります。そのため、それらの単語とは全く異なる位置に配置されそうです。
さらに、単語埋め込みは単語の意味を四則演算のように処理することができる表現であることが大きな特徴となります。
それゆえ、単語埋め込みは次のアナロジーを表現した等式が近似的に成り立つとされています。
king - man + woman = queen
つまり、単語埋め込みは言語表現を計算可能なものにしたものだと考えてください。
より詳しく知りたい方は、以下の記事などをご覧ください。
通時的単語埋め込み
単語の意味をベクトル空間で表す単語埋め込みですが、一般的にはコーパスを用いて学習をすることで獲得されます。
そして、コーパス毎に獲得される表現が異なっています。そのため、1980年代の新聞記事と2010年代の新聞記事で獲得された単語埋め込みは、同じ次元数であっても単純に比較することができないのです。
しかし、それぞれの空間の軸を合わせることができる手法があります。それは、単語埋め込みが空間ベクトルであるという特徴から、行列分解を用いた変換によってなされます。次の画像はそのイメージです。

この変換によって、次の画像のように二つの年代の単語を同じ空間に置いて、それぞれの位置を見ることでそれらの単語が時を経てどのように動いたのか = どう意味が変わったのかを知ることができます。
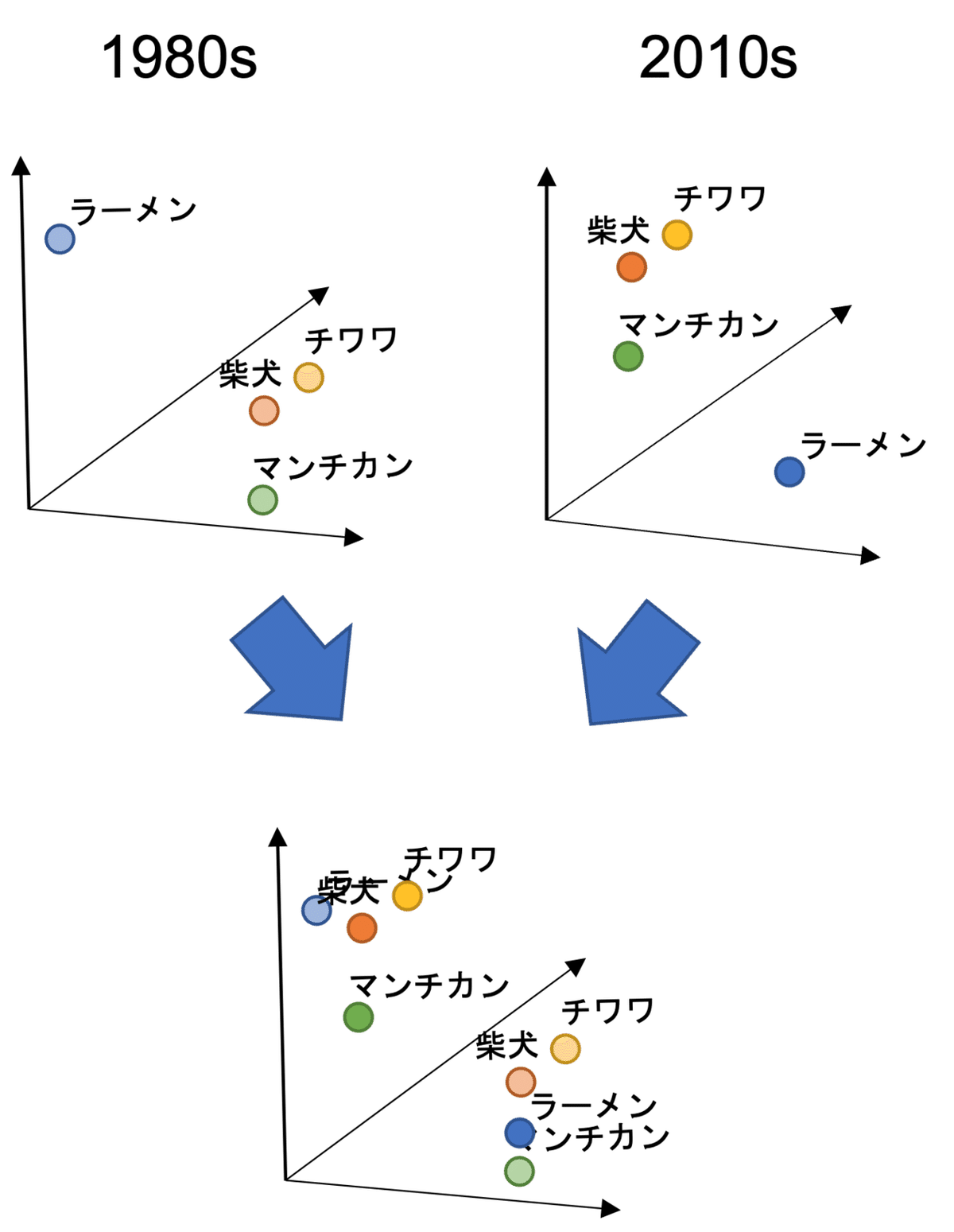
この変換によって得られる、年代間で比較可能な単語埋め込みを通時的単語埋め込みと呼びます。
本手法をもっと知りたいという方は、元ネタの論文であるWilliamらの「Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change」を見ていただければと思います。
バイアスを取り除く方法を応用した未来予想
単語埋め込みがコーパスから学習されていることに言及しました。これはコーパスに潜むバイアスをも同時に学習していることを示しています。
前項で言及した次の等式よって表される言語のアナロジーも、そのようにコーパスから学習されたから成り立つわけです。
king - man + woman = queen
では、次の等式では一体どんな単語で成り立つでしょうか?
Computer Programmer - man + woman = ?
これについて言及した有名な論文であるBolukbasiらの「Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings」という論文によると、次の式がアナロジー的に成り立ったと指摘しています。
Computer Programmer - man + woman = Homemaker
Computer Programmerは男性だけの職業ではないにも関わらず、男性を引いて女性を足すとHomemakerに近似してしまう、つまり単語埋め込みがComputer Programmerを男性寄りの職業と認識している、というバイアスが可視化されてしまったというわけです。
このバイアスは、先の論文における単語埋め込みの学習に使われたGoogle News上の単語の共起を、素直に反映してしまった結果であると考えられます。
そこで、先の研究では次の手続きでバイアスを取り除くことを試みています。
1. 単語埋め込みのベクトル空間上でバイアスを表す部分空間を特定する
2. バイアスを取り除きたい単語からバイアスを表す部分空間を減算する
以上の手続きを図解したものが次の画像です。

これはプログラミングが男性に近く、家事が女性に近い単語になっているという例です。
家事、プログラミングは本来は性別から無関係であるべき(性別を表す単語間で距離に大きな差があるべきではない)なはずです。そこで、この二つの単語のバイアスを取り除くことを試みます。
ジェンダーを表すような軸をPCA(主成分分析)と呼ばれる手法によって計算し(①)、そこで得られた第一主成分から、本来は性別とは無関係であるべき単語(家事、プログラミング)のジェンダー部分空間を計算し、性別との関係が薄まるように移動させます。(②)
ちなみに、このPCAは対象の特徴量の分散が最大となる軸を見つけて主成分とする手法です。そのため、この図の例では男性と女性の間の分散が最大となる軸を探し、それをジェンダー部分空間とします(※本来であれば、男性と女性以外にも父と母といった他の性別を表してそうな言葉のペアも含めてPCAを実行した方が良い)。
さらに具体的な詳細を知りたい方は、上記で挙げた論文を参照していただければと思います。
提案手法
そして、〈バイアスを取り除く技術〉を〈通時的単語埋め込み〉に応用することで、時系列の変化を捉え、その変化を進められるように外挿したのが本作品となります。
先ではPCAは特徴量の分散が最大となる軸を探すと述べましたが、今作品ではそれを通時的単語埋め込みの時代間の単語に用いました。
つまり、1980sの「パソコン」と2010sの「パソコン」といったようなペアをつくり、共通する全ての単語を対象にPCAを実行して、通時性を表現する部分空間を計算できる主成分を得ました。
そして、先のバイアスを取り除く方では性別による変動をなくすように単語を動かしました。
一方で、本手法では通時性による変動が大きくなる方向に単語を動かす、つまり単語に通時的なバイアスをかけることで時間による変動を外挿することを表現しました。
以下がその手法を図解した画像となります。
ここでは一つの主成分だけを使って一方向の変動だけを表現していますが、実際の作品では複数の主成分を使ったり、1980sと2010sだけではなく1990sと2010sや2000sと2010sといったペアで得た主成分も活用して、さまざまなパターンの通時的な変動を外挿することでいくつかの未来を表現しています。

そして、以下に示すように、二通りの未来の形をつくるよう、異なるバイアスの掛け方を適用しています。

上記のような未来を表現できるように、LINEARのタイプでは時系列の変動を10年分、20年分と入れているのに対して、CHAOSではどの時系列のどの主成分を入れるかを全てランダムで選んで外挿しました。
これによって得られる未来を外挿した単語埋め込みを使って、次に浦川さんが紹介する生成モデルの入力となる、「未来にはある単語の類語がどうなっているか?」をアウトプットとしました。
辞書ができるまでー新語の生成ー
ここからは浦川が〈新語〉とその〈意味〉の生成についてお話しします。
新語生成
さて、前段では未来に存在するかもしれない単語埋め込みを推測しました。この〈未来の単語埋め込み〉をもとに、新語の生成を行います。
造語法
新しい語をつくる方法については〈造語法〉として言語学などの分野で体系的にまとめられています。
またこの造語法において、新しい語がつくられる典型的なケースとして、すでにある語を複数繋ぎ合わせる合成語があると言われています(参考:窪薗晴夫「新語はこうして作られる」)。
「はまぐり(浜にある栗)」や「コンピューターウイルス(コンピューターのウイルス)」などが例としてあげられるそうですが、この合成語は以下で説明するように今回つくった未来の単語埋め込みとも相性がよいと考え、この手法を元に新語の生成をおこないます。
〈未来の単語埋め込み〉における新語生成
未来の単語埋め込みでは、語の未来の類似語を計算することができます。
例えば、「文章」という語の未来の類似語を計算すると、以下のようになりました。

「文章論」「簡潔」などは現在の感覚でもわかりますが、「皮膚感覚」や「肉体派」といった見慣れない語があらわれています。
先程の「コンピューターウイルス」の例などは、過去には遠い文脈で語られていた「コンピュータ」と「ウイルス」それぞれの語が現在では近い文脈で語られはじめたことから、合成されたものといえるでしょう。
まさにそのようにして、ここから例えば「皮膚感覚文章」や「肉体文章」といった語を、未来に発生しうる新語として計算できないか。そのように考え、ある単語とその未来の類語から、新語を生成していきます。
具体的には、以下のような手順です。
1. ある注目単語wの未来の類語w_sを単語埋め込みにより計算
2. wと、w_sの各語の要素を分解し組み合わせを新語として生成
また上記に加えて、新語や注目単語のモーラ数(拍数)の条件から語尾に「る」や「い」などをつけて動詞、形容詞を合わせてつくっています。
意味生成
続いて、以上でつくった新語に添えられる意味=説明文を生成する方法についてお話しします。
ここでは、GPT-2という言語モデルを用いて「入力:新語→出力:その意味を説明するテキスト」となるような生成を行います。
このGPT-2は弊社の保有する約900万の記事を事前学習したもので、以前に記事のタイトルからその内容を生成するデモンストレーション「#この記事は実在しません」でも用いたモデルです。
これを以下で説明する学習データでfine-tune(少量データで学習し、モデルのパラメータを調整する)することで、単語名を入力に、意味内容を生成するモデルをつくりました。

単語からその意味を生成させるためには、辞書のように〈単語〉と〈意味〉の対応がテキストで綴られたデータが必要です。
今回は日本語版Wiktionaryのダンプを用いて、

と先頭に単語名を配置し、その後に意味内容が続くデータを作成。
これによりモデルをfine-tuneすることで、単語意味の生成を行うモデルをつくることができました。
例えば先程の「肉体文章」を入力してみると、以下のような出力が得られました。

類語指定による意味生成
一方で、このままでは先ほど計算した「未来の単語埋め込み」を完全に反映した生成とは言えません。
先程の「肉体文章」は一見うまくいったように見えましたが、例えば新語のつもりで「つうける」という動詞を入力したとします。またこの付近には、仮に「勇気_元気_栄養_応援 」などといった語が未来の埋め込みには存在しているとしましょう。
この時、モデルに「つうける」と単語名のみを与えても、その語感からそれが動詞らしいことは理解できても、それが一体どんな動作なのか、先ほど設定した〈勇気_元気_栄養_応援〉という未来の埋め込みを反映した内容とはならないのです。
そこで、新語に加えて近い意味を持つであろう〈類語〉を入力とすることで、類語の内容に応じた意味生成を行うfine-tuneを行いました。

例えば、「つうける」という語について、それぞれ異なる類語から、それにあった内容を生成することが出来ます。

このようにして、未来の単語埋め込みを考慮した意味生成ができました。
おわりに
いかがでしたでしょうか。このように、新語推測と新語生成の二つの手法の組み合わせから「未来を編む辞書」をつくる過程についてご紹介しました。
最後に、いくつか実際の生成例を紹介しましょう。未来を推測しながら編まれた新語たちから、一体こんな語が扱われる未来とはどんなものだろうか、と想像が広がれば幸いです。

(メディア研究開発センター・浦川通, 新妻巧朗)
展覧会概要
「2121年 Futures In-Sight」展
会期: 2021年12月21日(火)- 2022年5月8日(日)
会場: 21_21 DESIGN SIGHT ギャラリー1&2
休館日: 火曜日(12月21日、5月3日は開館)年末年始(12月28日 - 1月4日)
開館時間: 10:00-19:00(入場は18:30まで)*入場予約制の可能性あり
入館料: 一般1,200円、大学生800円、高校生500円、中学生以下無料
Imaginary Dictionary -未来を編む辞書:クレジット
コンセプト :Qosmo, 朝日新聞社メディア研究開発センター
企画・Data Dramatization:Qosmo
Art Director: 堂園翔矢
Lead Engineer(Data Visualization): Jungers Robin
Engineer(Data Visualization): 中嶋亮介
Designer: 伊勢尚生
Project Manager: 安江沙希子
Supervisor: 徳井直生
新語推測・生成:朝日新聞社メディア研究開発センター
Technical Director/Language Modeling: 浦川通
Data Scientist: 新妻巧朗
Supervisor: 田森秀明