VTuberとAITuberを並べて音声対話しながら配信する

実装要件
中の人が居る=VTuber
中の人がAI=AITuber
と、ざっくり解釈して、
2人並べて、音声会話しながら配信してみたい。
ゲーム配信したいので、AIとの音声会話は完全にハンズフリーにする。
使用アプリ/サービス
OBS 配信環境アプリ
Miibo AI会話サービス (ChatGPT API使えるならそれでも良さそう)
ゆかりねっと 音声からテキストに変換
VMagicMirror VRM表示用 (2つ起動用にexeとかを複製)
VoiceVox 音声合成出力
CeVIO AI 音声合成出力。入手が難しい場合はVoiceVoxで良いかと。お好みで
AssistantSeika 声作成連携アプリ
VB-Cable リップシンク用仮想オーディオデバイス。VB-Cable A+Bがあれば良いが入手が難しい場合はVB-CableとSYNCROOMで代用も出来る
SYNCROOM VB-Cable A+Bが無い場合の代用。ドライバだけ使う。
作成プログラム
多少のPython知識が必要です。
・連携プログラム
ゆかりねっとでのテキスト変換時に仕込むPythonアプリ。
テキストから、Miibo APIをたたき、返答を得て、
AssistantSeikaを使って操作者のテキストと、Miiboのテキストを音声変換し、
仮想オーディオデバイスに向けて再生する。
・音声再生プログラム
リップシンク用の仮想デバイスを使って音声再生するアプリ。
相関図

操作説明
基本的に声だけで操作します。
連携プログラムの変数AI_NAMEで設定した名前がトリガーになりAI(Miibo)が応答します。
発言の中に名前を入れるか、1つの発言が終わって次の発言で”名前だけ”呼ぶかすると反応します。
例1)
「こんにちは メタセコちゃん」 → 「こんにちは メタセコちゃん」がMiiboに送られる
例2)
「今日もゲームしよう」
「メタセコちゃん」 → ”名前だけ”呼ぶと、1つ前の発言「今日もゲームしよう」がMiiboに送られる。名前だけの発言は音声再生されず字幕も出ない
発言に名前が入っていないとAIは無反応となります。
音声を文字変換する時に誤訳があったり、独り言が入ったりするので、そういうのまで反応せず、必要な発言にだけAIに反応してもらう使い分けができます。
「文字消して」
と発言するとOBS上の字幕を消去します。「文字消して」の音声は再生されません。
各種設定
連携プログラム設定
連携プログラムから、各種アプリ連携方法を解説します。
下のコードを、miibo_playvoice.pyとして保存します。
基本的にはゆかりねっとから連携されることを想定しています。
コマンドラインから実行する場合は下のようになります。
>Python miibo_playvoice.py [操作者の発言テキスト] [ダミーを使う場合 -dummy]
うまく連携されない場合はコマンドラインから実行してエラーなどが出てないか確認しましょう。
#!/usr/bin/python
# -*- coding: Shift-JIS -*-
import obsws_python as obs
import re
import subprocess
import requests
import json
import uuid
import sys
import os
MIIBO_API_URL = 'https://api-mebo.dev/api'
MIIBO_API_KEY = "your miibo-api-key"
MIIBO_AGENT_ID = "your miibo-agent-id"
USER_NAME = 'your name'
#DUMMY_JSON = '{"utterance": "test","bestResponse": {"utterance": "【感情パラメータ】 喜び:2 怒り:0 悲哀:0 楽し:3 驚き:1 それは興味深いですね。おすすめの作品はありますか?"}}'
DUMMY_JSON = '{"utterance": "test","bestResponse": {"utterance": "hello message text"}}' #Dummy
AI_NAME = 'your ai-name'
AI_EMOTIONS = '【感情パラメータ】'
CLS_WORD = '文字消して'
VOICE_ME_CID = 50031 #your voice
VOICE_ME_FILENAME = 'voice_me.wav'
VOICE_ME_TEXT_FILENAME = 'voice_me_text.txt'
VOICE_ME_DEVICE = 21 #your voice-device
VOICE_AI_CID = 70061 #your ai-voice
VOICE_AI_FILENAME = 'voice_ai.wav'
VOICE_AI_DEVICE = 17 #your ai-voice-device
#OBS Settings
OBS_PASSWORD = 'mystrongpass'
TARGET_ME_SOURCE_NAME = 'jimaku_me'
CSS_ME_TEMPLATE_PATH = 'jimaku_me.css'
TARGET_AI_SOURCE_NAME = 'jimaku_ai'
CSS_AI_TEMPLATE_PATH = 'jimaku_ai.css'
TARGET_EMO_SOURCE_NAME = 'jimaku_emo'
CSS_EMO_TEMPLATE_PATH = 'jimaku_emo.css'
headers = {'Content-type': 'application/json'}
os.system('chcp 65001')
args = sys.argv
print(args)
if(len(args) < 2):
print('python miibo_playvoice.py [message text] (option)')
sys.exit(1)
TEMPLATE_PATHS = {
TARGET_ME_SOURCE_NAME: CSS_ME_TEMPLATE_PATH,
TARGET_AI_SOURCE_NAME: CSS_AI_TEMPLATE_PATH,
TARGET_EMO_SOURCE_NAME: CSS_EMO_TEMPLATE_PATH
}
templates = {}
for source_name, path in TEMPLATE_PATHS.items():
with open(path) as f:
templates[source_name] = f.read()
# 字幕表示
def send_jimaku(text, source_name):
css = re.sub(' content: .*;', ' content: "' + text + '";', templates[source_name])
obscl.set_input_settings(source_name, {'css': css}, True)
# テキストファイルを書き込む
def write_text(text):
with open(VOICE_ME_TEXT_FILENAME, "w") as f:
f.write(text)
# テキストを読み込む
def read_text():
try:
with open(VOICE_ME_TEXT_FILENAME, "r") as f:
text = f.read()
return text
except Exception:
return ""
obscl = obs.ReqClient(host='127.0.0.1', port=4455, password=OBS_PASSWORD)
print(args[1])
#字幕消去用
if CLS_WORD in args[1]:
send_jimaku(' ', TARGET_ME_SOURCE_NAME)
send_jimaku(' ', TARGET_AI_SOURCE_NAME)
send_jimaku(' ', TARGET_EMO_SOURCE_NAME)
sys.exit(1)
#名前だけ呼ばれた場合、前回の発言を送る
if AI_NAME == args[1]:
args[1] = read_text() #前回の自分の発言
print("名前だけ呼ばれたので、直前のメッセージを送ります。 Message="+args[1])
else:
send_jimaku('・・・(発言中)', TARGET_ME_SOURCE_NAME)
subprocess.run(['SeikaSay2', '-cid', str(VOICE_ME_CID), '-save', str(VOICE_ME_FILENAME), '-t', str(args[1])])
send_jimaku(str(args[1]), TARGET_ME_SOURCE_NAME)
p = subprocess.Popen(['python', 'playvoice.py', str(VOICE_ME_FILENAME), str(VOICE_ME_DEVICE)])
if AI_NAME not in args[1]:
print("呼ばれてないので返答しません。 AI_NAME="+AI_NAME)
write_text(args[1])
sys.exit(1)
else:
write_text("")
#メッセージが短すぎる場合は送らない
if len(args[1]) < 5:
print("メッセージが5文字未満なので送りません。 Message="+args[1])
sys.exit(1)
send_jimaku('・・・(考え中)', TARGET_AI_SOURCE_NAME)
if len(args) < 3: #Prod
params = {
'api_key': MIIBO_API_KEY,
'agent_id': MIIBO_AGENT_ID,
'utterance': str(args[1]),
'username': USER_NAME,
'uid': str(uuid.uuid4()),
}
response = requests.post(MIIBO_API_URL, headers=headers, json=params)
json_data = response.json()
else: #DummyJson
json_data = json.loads(DUMMY_JSON) #Dummy
best_response_utterance = json_data["bestResponse"]["utterance"]
print(best_response_utterance)
#これは”感情”の物語
if AI_EMOTIONS in best_response_utterance:
pattern = "(喜び|怒り|悲哀|楽し|驚き):(\d+)"
matches = re.findall(pattern, best_response_utterance)
best_response_utterance = re.sub(AI_EMOTIONS, "", best_response_utterance)
best_response_utterance = re.sub(pattern, "", best_response_utterance)
emo = ""
if matches:
print(matches)
for match in matches:
emotion = match[0]
number = int(match[1])
bar = "■" * number
nobar = "□" * (5-number)
emo += emotion + ":" + bar + nobar + "\\\\A"
print(emo)
send_jimaku(emo, TARGET_EMO_SOURCE_NAME)
best_response_utterance = best_response_utterance.lstrip() #trim
subprocess.run(['SeikaSay2', '-cid', str(VOICE_AI_CID), '-save', str(VOICE_AI_FILENAME), '-t', best_response_utterance])
if 'p' in locals(): #操作者の音声再生終了待ち
p.wait()
send_jimaku(best_response_utterance, TARGET_AI_SOURCE_NAME)
subprocess.Popen(['python', 'playvoice.py', str(VOICE_AI_FILENAME), str(VOICE_AI_DEVICE)])
各自の設定が必要なところは上の方の変数に纏めてある。
MIIBO_API_KEY ・・・miibo apiのキー
MIIBO_AGENT_ID ・・・miibエージェントのID
USER_NAME ・・・AIが操作者を呼ぶときの名前
AI_NAME ・・・AIの呼称
VOICE_ME_CID ・・・操作者の発言をどの声で再生するか。AssistantSeikaのCIDに準拠
VOICE_ME_DEVICE ・・・変換した操作者の声をどのデバイスで再生するか
デバイス一覧は以下のプログラムを実行し、各自の環境に合わせたIDに変更する。maxOutputChannelsが0のデバイスは利用できない。
デバイスはVTuber側の口パクと、AITuber側の口パクが必要なので、仮想デバイスを2つ用意する必要がある。
今回はVB-Cableと、CYNCROOMを使う前提で記載。
>17 CABLE Input (VB-Audio Virtual C 8
>21 繝ゥ繧、繝ウ (Yamaha SYNCROOM Driver (WD 2
import pyaudio
pa = pyaudio.PyAudio()
for i in range(pa.get_device_count()):
info = pa.get_device_info_by_index(i)
#print(info)
print(i, info['name'], info['maxOutputChannels'])VOICE_AI_CID ・・・AIの声をどの声で再生するか。AssistantSeikaのCIDに準拠
VOICE_AI_DEVICE ・・・AIの声をどのデバイスで再生するか
OBS_PASSWORD ・・・字幕連携用 OBS接続用パスワードを設定する
他項目はそのままで良いでしょう。
お好みにあわせて改造してください。
文字起こし
文字起こしはゆかりねっとで行います。
ゆかりねっとには字幕機能や読み上げアプリ連携の機能がありますが、今回は使いません。
「フィルター」に、「Miibo連携」と、「Miibo連携ダミー」を追加します。
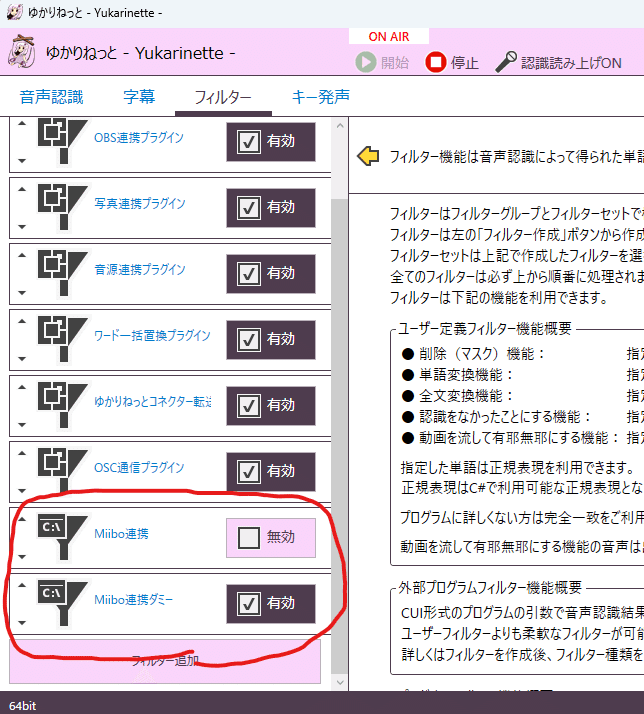
各設定は以下の通りです。
フィルター種類には、外部プログラムフィルターを選択します。
プログラムのある場所をE:\work\Miiboとし、今回作成する連携プログラムに文字起こししたテキストを渡しています。

2番目の引数に何か指定(引数の数しか見てないので何でもいい)すると、ダミー通信になります。
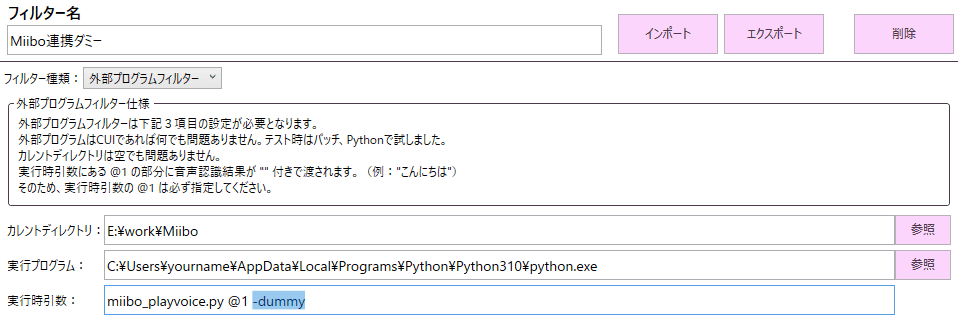
・Miibo連携 ・・・AIの名前が含まれていた場合にMiibo APIに発言を送ります。
・Miibo連携ダミー ・・・Miibo APIではなく、あらかじめ指定した返答文を固定で返します。APIは使用されません。
返答文は、miibo_playvoice.pyの、「DUMMY_JSON」変数に指定したものになります。
実際に使う場合はMiibo連携を選択し、ダミーのチェックを外します。
環境チェックなどをしたい場合はダミーのほうだけを使います。
字幕
操作者と、AIの音声は、文字変換されたあと、OBSに字幕表示するようにしています。
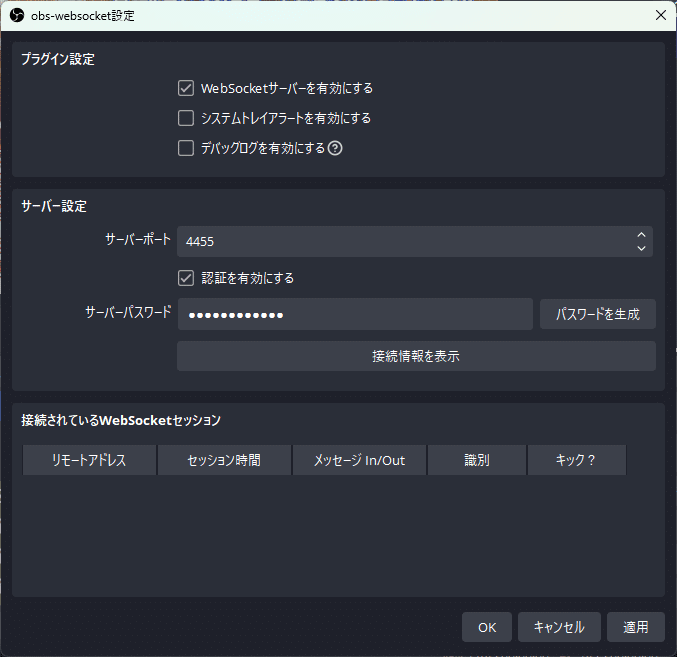
連携には、OBSのWebSocketを使います。obs-websocket設定が有効になっていることを確認してください。
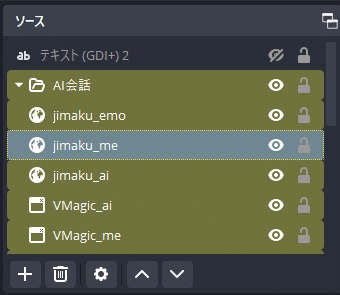
ソースにブラウザを追加し、ソース名を「jimaku_me」とします。
プロパティではURLに”none”を入力しておき、幅と高さはお好みで設定しておきます。
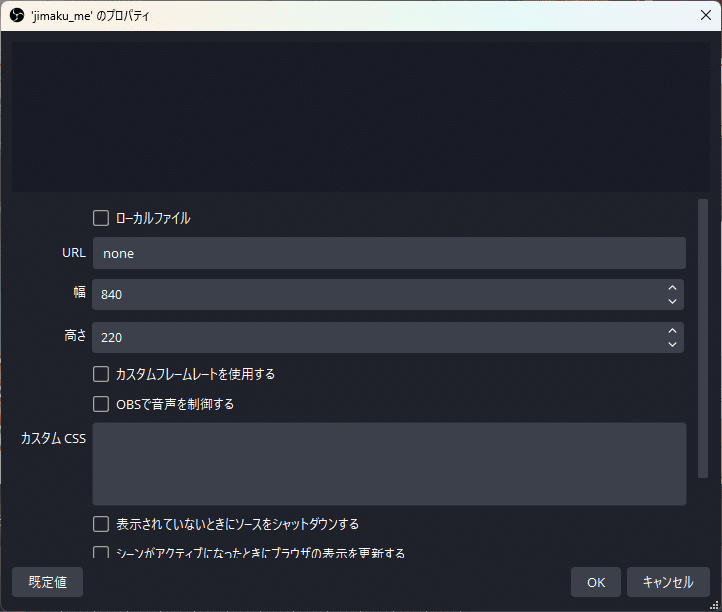
連携プログラムからカスタムCSSを上書きして字幕を表示するので、下のcssを「jimaku_me.css」ファイルとして保存しておいてください。
青文字の右寄せレイアウトになっています。
@import url('https://fonts.googleapis.com/css2?family=M+PLUS+Rounded+1c:wght@900&display=swap');
body {
margin: 0;
padding: 0;
border: 0;
display: flex;
flex-wrap: wrap;
justify-content: right;
align-items: flex-start;
align-content: flex-start;
overflow: hidden;
margin: 5vh 5vw;
font-family: 'M PLUS Rounded 1c', sans-serif;
font-size: 15vh;
line-height: 1.1em;
text-align: right;
position: relative;
}
body::before {
content: attr(data-text);
position: absolute;
color: #FFF;
-webkit-text-stroke: 0.5vh #000;
z-index: 30;
}
body::after {
content: attr(data-text);
position: absolute;
color: #FFF;
-webkit-text-stroke: 3.0vh #44F;
z-index: 20;
}「jimaku_ai」「jimaku_emo」についても同様に用意します。
下は「jimaku_ai.css」。左寄せの赤文字です。
@import url('https://fonts.googleapis.com/css2?family=M+PLUS+Rounded+1c:wght@900&display=swap');
body {
margin: 0;
padding: 0;
border: 0;
display: flex;
flex-wrap: wrap;
justify-content: left;
align-items: flex-end;
align-content: flex-end;
overflow: hidden;
margin: 5vh 5vw;
font-family: 'M PLUS Rounded 1c', sans-serif;
font-size: 10vh;
line-height: 1.1em;
text-align: left;
position: relative;
}
body::before {
content: attr(data-text);
position: absolute;
color: #FFF;
-webkit-text-stroke: 0.5vh #000;
z-index: 30;
}
body::after {
content: attr(data-text);
position: absolute;
color: #FFF;
-webkit-text-stroke: 2.0vh #F44;
z-index: 20;
}下は「jimaku_emo.css」フェードインして、数秒後色が薄くなるようにアニメーションさせています。
@import url('https://fonts.googleapis.com/css2?family=M+PLUS+Rounded+1c:wght@900&display=swap');
body {
margin: 0;
padding: 0;
border: 0;
display: flex;
flex-wrap: wrap;
justify-content: left;
align-items: flex-start;
align-content: flex-start;
overflow: hidden;
margin: 5vh 5vw;
font-family: 'M PLUS Rounded 1c', sans-serif;
font-size: 10vh;
line-height: 1.1em;
text-align: left;
position: relative;
}
body::before {
content: attr(data-text);
position: absolute;
color: #FFF;
opacity: 0.4;
animation: fade 7s;
white-space: pre-wrap;
-webkit-text-stroke: 0.5vh #000;
z-index: 30;
}
body::after {
content: attr(data-text);
position: absolute;
color: #FFF;
opacity: 0.4;
animation: fade 7s;
white-space: pre-wrap;
-webkit-text-stroke: 1.5vh #F48;
z-index: 20;
}
@keyframes fade {
0% {opacity: 0;}
20% {opacity: 1;}
60% {opacity: 1;}
100% {opacity: 0.4;}
}音声まわり
当方の環境ではCeVIOとVoiceVoxを使いましたが、お好みに合わせて変更してください。
AssistantSeikaを使うことで、CIDだけ変えれば大抵の音声に対応できるかと思います。
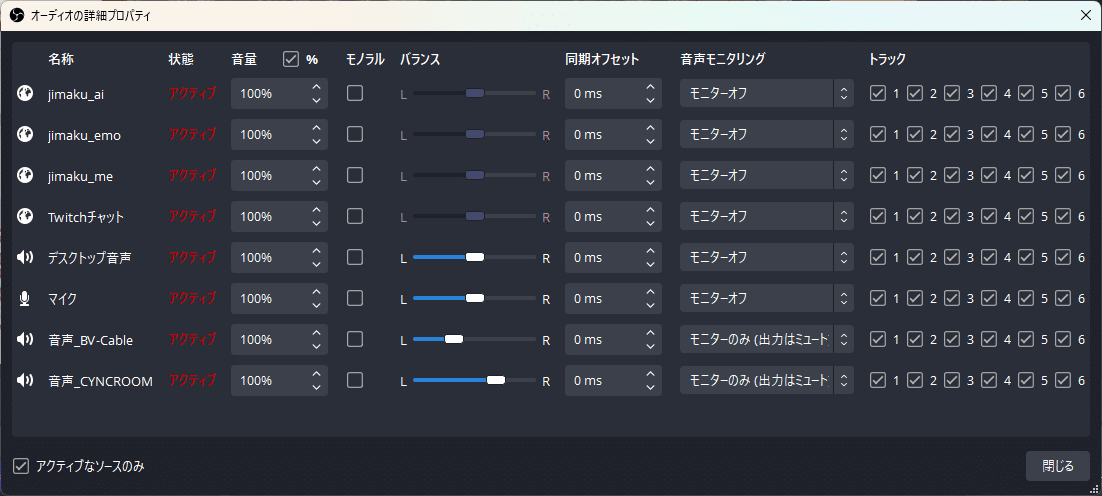
音声はデバイスを分けて再生する必要があるので、ファイルに保存してそれを再生するようにします。
AssistantSeikaの「基本設定」の「音声保存時に再生デバイスをキャプチャする」のチェックを外しておきましょう。
※追記:音声合成アプリ次第で保存時の挙動が異なるようです。うまく動かない場合(二重再生される、ダイアログが出るなど)は状況にあわせて改修してください。音声合成アプリ又はAssistantSeikaに再生を任せて、playvoice.pyで再生している行をコメントアウトし、SeikaSay2の実行をrunからPopenにするなどでの対応になるかと思います。

操作者側アバターの口パクと、AIアバターの口パクにそれぞれの音声デバイスを使います。
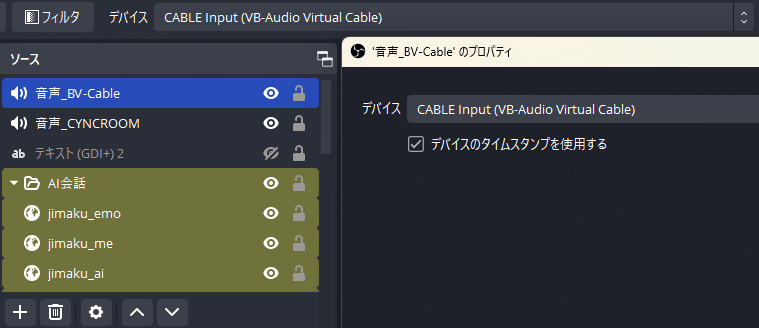
仮想オーディオデバイスを2つ使います。
今回は、操作者としてCYNCROOMと、AI側としてVB-Cableをインストールしておきます。
そしてOBSのソースに音声出力キャプチャを追加しておきます。
VB-Cableと、CYNCROOMを追加しましょう。
オーディオの詳細プロパティでは、追加した音声デバイスのモニタリングを、「モニターのみ(出力はミュート)」にしておきます。
パンポットバランスは、右のキャラの声は少し右から聞こえるような調整をしています。お好みで。
音声の再生にはデバイスを使い分ける必要があるので、下のプログラムを使います。
playvoice.pyとして保存します。
import pyaudio
import wave
import sys
args = sys.argv
def play_audio(filename):
chunk = 1024
wf = wave.open(filename, 'rb')
pa = pyaudio.PyAudio()
stream = pa.open(
format=pa.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output_device_index=int(args[2]),
output=True
)
data_stream = wf.readframes(chunk)
while data_stream:
stream.write(data_stream)
data_stream = wf.readframes(chunk)
stream.close()
pa.terminate()
play_audio(args[1])基本的に、miibo_playvoice.pyから連携されますが、コマンドラインでの使い方は、
>python playvoice.py [再生する音声ファイル名] [再生するデバイスID]
となります。
感情
AIに感情を持たせ、喜怒哀楽+驚きの表情を表したり、語調を変えてもらいます。
下の記事を参考にさせていただきました。
Miiboへ適応するには、Miiboの「エージェントの設定」にある、キャラクター設定で行います。
下のプロンプトを追加してください。
下記の5つの感情パラメータを持ち振る舞います。各感情パラメータは会話を通じて変動します。現在の感情パラメータの値を反映するように、あなたの返答のトーンや発言は変化します。現在の感情パラメータを出力してから会話を出力してください。
出力形式は以下のフォーマットです。
【感情パラメータ】
喜び:0〜5
怒り:0〜5
悲哀:0〜5
楽し:0〜5
驚き:0~5
【会話部分】こんな感じです。

連携プログラムでは「【感情パラメータ】」という文字列をトリガーに、各感情値0~5を取得し、OBSの字幕に送っています。
現時点では表示のみです。
アバター表示
アバターの表示にはVMagicMirrorを使います。
VMagicMirrorは元々多重起動できるのですが、OBSでそれぞれの画面をキャプチャーするときに誤認してしまう(どちらも同じ画面になる)ので、
実行ファイル名をかえてやる必要があります。
「VMagicMirror.exe」を複製して、「VMagicMirror2.exe」にリネームしましょう。
データフォルダも対応させる必要があるので、シンボリックリンクを作成しておきます。
>mklink /D VMagicMirror2_Data VMagicMirror_Data
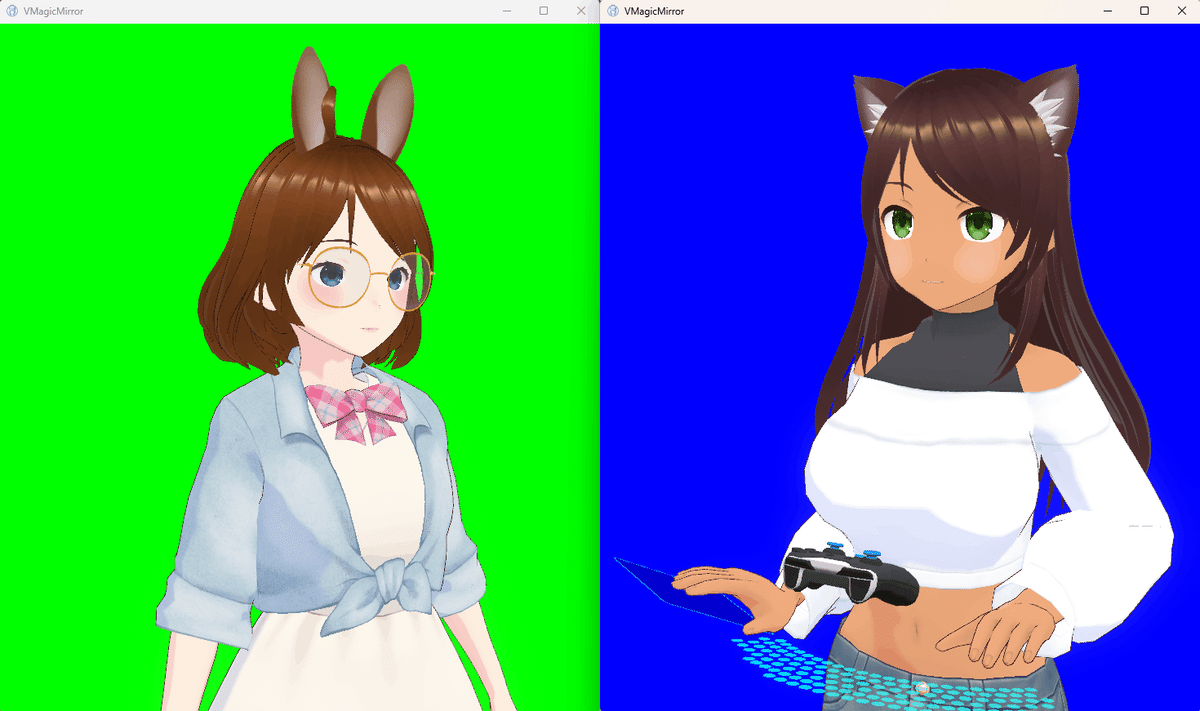
操作者側アバターと、AI側アバターの設定をセーブしておきます。
操作者側は、コントローラやキーボードマウスの表示をして、リップシンクをSYNCROOMデバイスで行うよう設定しました。
AI側は、キー/マウスでの動作をなしにして、コントローラなども非表示、後々のために、Word To Motionのデバイスの割り当てでMIDIコントローラを指定しておきました。
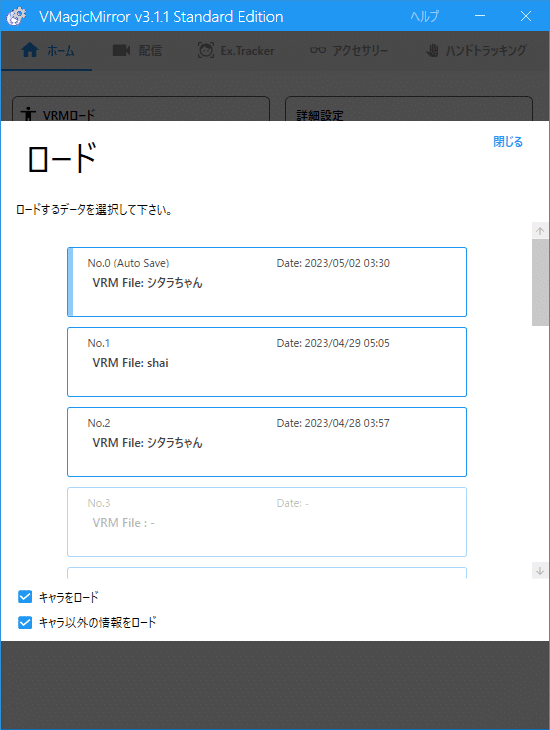
あとは、2つ起動して、それぞれのセーブデータをロードします。ロードする時、「キャラ以外の情報をロード」にチェックを入れてキー/マウスの設定も読み分けるようにします。
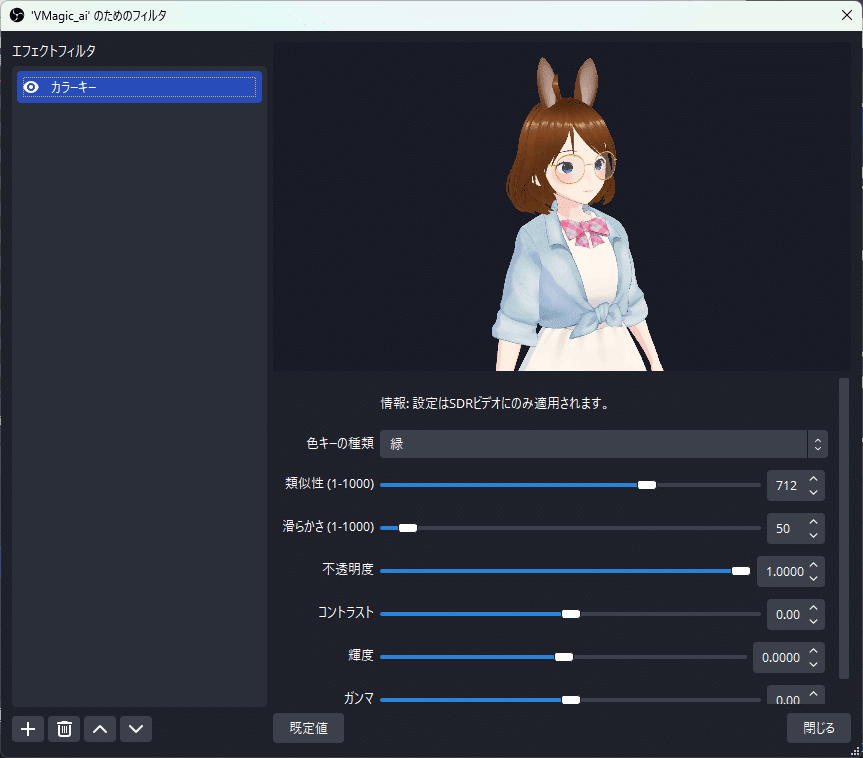
OBSのソースに、ウィンドウキャプチャを追加して、それぞれのVMagicMirrorの画面を表示させます。
バックのグリーンスクリーンを消すにはフィルタでカラーキーを追加します。

その他設定
今回生成するファイル一覧はまとめると以下になります。
devicelist.py ・・・オーディオデバイス一覧表示
jimaku_ai.css ・・・AI用字幕css
jimaku_emo.css ・・・AIの感情用字幕css
jimaku_me.css ・・・操作者用字幕css
miibo_playvoice.py ・・・連携プログラム
playvoice.py ・・・音声再生プログラム
voice_ai.wav ・・・[自動生成]AI音声
voice_me.wav ・・・[自動生成]操作者音声
voice_me_text.txt ・・・[自動生成]操作者の直近の発言記録
VRMモデルは、hub.vroid.com などで利用できるものを探すか、VRoid Studioなどを利用して作ります。
今回はVRoid Studioで作りました。下のリンクで公開しています。
https://hub.vroid.com/characters/2886881001613111983/models/2965092492258142141
Python導入、Miiboの初期設定や、OBSの使い方などは他の記事を参考にしていただければと。
Pythonは3.10.7を使用しています。
一部のimportでエラーが出る場合は、下のようにinstallすれば動きます。
>pip install pyaudio
※pyaudioの部分はエラーのでるモジュール名にする
配信の前に、OBSの「録画」で各種動作確認/練習をしてみましょう。
AIが反応してくれるか、音声が鳴っているか、二重で鳴ってたりしないか、マイク入力の音が出力されてないか、ボリュームなどをチェックしておきましょう。
設定完了、配信してみよう
AIと一緒にゲーム配信をしたかったので、OBSのソースにゲームキャプチャ、ウィンドウキャプチャを追加し、配信してみます。
パフォーマンスについて
操作者の発言が終了してから、文字起こし、音声変換、音声再生までに7秒ほどかかります。(環境や文字数次第で前後しそう)
操作者の音声再生中にAIの返答用意、音声変換を行っています。
状況や文字数にもよりますが、操作者の音声再生終了後、3秒くらいでAIの音声再生が開始されます。
今後
今後は、以下を計画中です。
・MIDI仮想入力プログラム
引数で指定した鍵盤をたたくアプリ。VMagicMirrorの感情表現に使う。
・Youtubeコメント欄読み込み連携プログラム
視聴者のコメントに何かリアクションしたい。
この記事が気に入ったらサポートをしてみませんか?