
ゲーム実況や動画用に使えるかもしれないオリキャラをAIで作ってみる

StableDiffusion歴1週間で適当なオリキャラを作りました。
制作過程やツールとしての向き不向きについて感じたことをシェアしたいと思います。
方法によってはスマホで無料でできるのぜひ試してみてください。
細かな方法はもっと他に良いサイトがあるので、あくまで方法としてこんなやり方があるんだなと参考になれば幸いです。
個人的な所感としてキャラクターは可愛い方がいい

キャラクターをChatGPT/BingAIで作る
まずどんなキャラクターがいいか考えます。
私にはクリエイターセンスがないのでAIに作らせます(丸投げ)
大雑把な希望をChatGPTに伝えます(初手大手)
するといきなりいい感じの画像が出てきます。
あとは続けて髪の毛の色とか目の色とか服装とか。どんどん指示を出して好みの娘を作っていきましょう。
ChatGPTは有料プランしかできない技ですがBing AIは無料でできるのでぜひ試してみてください。

私は
・ピンク色のロングヘアー
・黒いオフショルダーセーター
・ヘッドホンをつけている
という設定で作りました。
ここに関しては
各々の好みをAIにぶつけてマイキャラを作りましょう。

一つだけ注意点として髪型や服装など凝ったキャラクターはやめた方が無難です。複雑なデザインは再現に苦労します。
1枚絵を綺麗に作るなら良いのですが今後オリキャラとして使いたいのであればある程度シンプルなものが良いです。
作りたいキャラクターを作り上げる…というよりもある程度再現性の高いものからキャラクターを選ぶという運用上の工夫が必要です。慣れてくればLoRA等で自己学習できるかもしれませんが初心者なのでまずはおいておきます。
AIと会話をしているだけで好みのキャラクターができるのはとても楽しいです。
後ほど解決策は提示しますが、問題点として同じキャラクターでポーズを変えたい、絵柄を維持したまま微調整したい…という点にはChatGPTやBing AIは不向きで、1から絵を作ってしまいます。
例えば作った絵に関して微調整をしたいので、口をもうちょっと開けて楽しそうにしている絵にしてほしい…といった指示を出すと別の絵が出てきます。

これはこれで可愛いのですが、何度もリテイク指示を出す事になってしまいます。何回か指示を出して直れば良いのですが、段々初期の方向性を見失ったり、API制限にひっかかたりとChatGPTだけではうまく作れません。
ここで登場するのがStable Diffusionになります。
Stable Diffusionを使って細かなものを作る
ChatGPTやBing AIで指示出すのと比べて何が良いか?
・Img2Imgという画像から画像を作る機能
・ControlNetというポーズ指定を細かにできる機能
・透過PNGで背景無しにキャラが切り抜きできる
という点です。
以下の例は左下にControlNetという設定でで棒人形を指定し、そのポーズを守って画像が作られます。
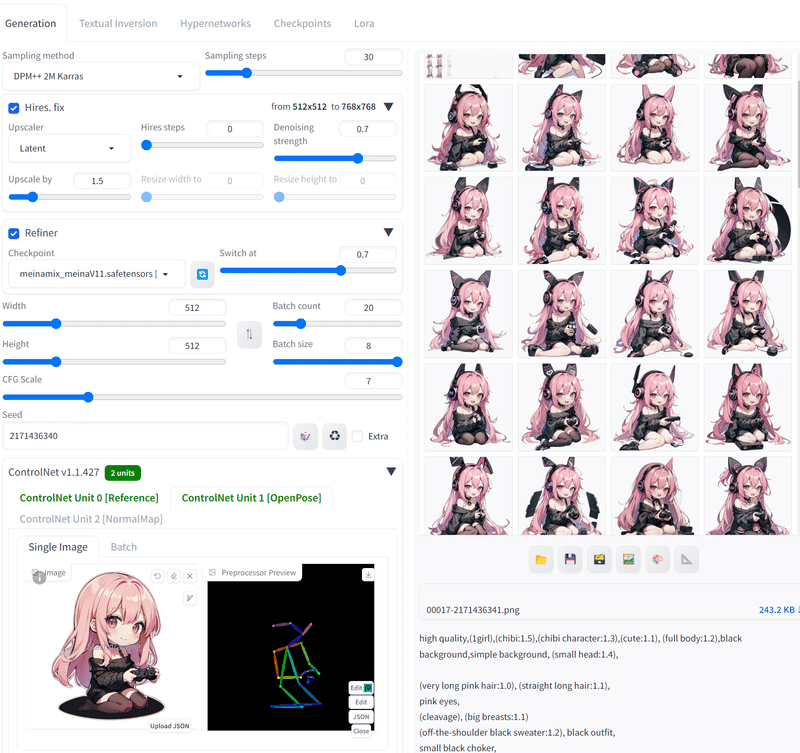
Img2Imgでは画像から画像を作るというもので、元のイラストの一部だけ修正ということも可能です。ちょっと見えにくいですが口元を指定し、そこだけ修正を依頼しています。

Stable Diffusionを使う方法ですが
1. ゲーミングPCのように高いGPUが乗ったマシンを使う (私はコレ
2. PixaiのようなWebサービスを使う
の2つがおすすめです。
1に関しては以下のサイトが非常に参考になります。
環境構築からプラグイン、細かな使い方、Prompt指南までこのサイト一つで完結できます。本当に作者には頭が上がりません。本記事ではこちらを扱います。
2に関しては以下のPixAIというサイトです。
StableDiffusionが無料で使えます。ログインボーナスか課金でコインがもらえて作成指示を出すとコインを消化するというタイプです。Algorithm/Sampling Stepを削り、高優先度を外れば少し待たされますが無課金でも全然遊べるので非常に良いサイトです。
ControlNetなどにもしっかりと対応しています。まずは気軽にStableDiffusionを遊んでみたい方にお勧めです。
ある程度やってくると色んなパターンを試したくなるのでやはり自前の環境を用意する方が良いと思います。
StableDiffusion Web UI おすすめ記事
先ほど紹介したサイトですがよくお世話になるのでもう一度…
まずは上記を見て環境を構築しましょう。
全20章ですが
Chap1~3はStableDiffusionの紹介
Chap4-5がInstall方法
Chap.7 基本操作
Chap.8 おすすめモデル。私はMeinaMixとKuronekoAnimemixが好きです。
Chap.9 VAE お好みで
Chap.12 ControlNetを導入する方法 これはとても便利です。慣れて来たらいれましょう。
あとは以下の記事が良さげです。
画像の一部だけ修正したり、作った画像をクオリティアップしたい場合。
一度作ったマイキャラをReferecen Onlyに入れておくと似たようなキャラを作ってくれます。
透過PNGでキャラクターだけ欲しいということはありませんか?
マイキャラの呪文を作る
romptnのプロンプト集を見たり、ChatGPTに相談してマイキャラのプロンプトを作ってみましょう。ある程度固ってきてReferecneなども使うと同じようなキャラクターが色んなポーズができるようになります。
一発で思った通りの物ができるのは稀なのである程度Try & Errorが必要
1. Promptを調整しつつ数枚生成 (4~8枚を一括で)
2. 数を生成して当たりが出るの祈る (一括設定のまま100枚ぐらい一気に
3. いい感じのものが出ればそのまま使う or Img2Imgで微調整
という流れになります。
あとは服装を変えたりコスプレさせたりして楽しみましょう。




チビキャラを作る

KuronekoAnimemixというモデルがチビキャラに強めです。
ただプロンプトの方が重要です。
上記サイトに書かれてませんが、Promptを増やしていくとChibiというチビキャラを作るPromptが無視され始めるので
high quality,(1girl),(chibi:1.5),(chibi character:1.3),(cute:1.1), (full body:1.2),black background,simple background, (small head:1.4),
のように重みを増やしてみてください。
チビキャラをお座りさせる

ControlNetを使いましょう。Openposeと呼ばれるものです。
自分がさせたいポーズをRefereceに突っ込んであとはマイキャラの呪文と合わせるだけです。
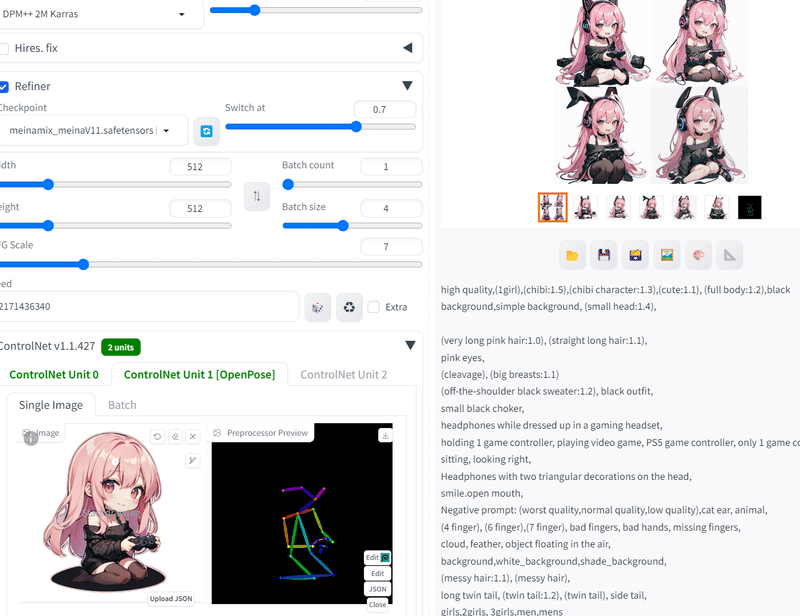
ControlNetのOpenPoseにポーズを、キャラ設定をRefereceに突っ込むとなお安定します。
そもそもの構図が難しい場合ChatGptと相談してみてください。
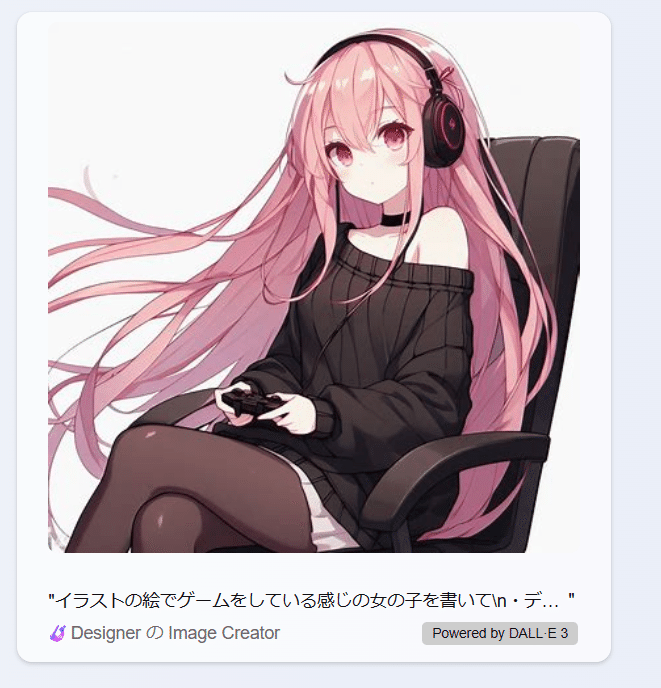
例えば
「チビキャラやSDイラストの絵でゲームをしている感じの女の子を書いて 髪はピンク 服は黒」
みたいのを丸投げするだけでかなりいい感じのものが出てきます。後は出てきた画像をControlNetに突っ込むだけです。

他にも面白いネタがあれば随時更新していきます。
Stable Diffusionはいろいろ触ってみると楽しいですね。
この記事が気に入ったらサポートをしてみませんか?