
YOLOv5を用いたスマブラspのピクミン使用割合の自動検出

初めまして、anaです。普段はスマブラspに登場するファイターの武器等の設計・製作を行っています。
今回は物体検出アルゴリズムであるYOLOがスマブラspに応用できないか考えました。
一例としてピクミンの使用割合の可視化を行いたいと思います。
なお、自分の専攻分野は機械学習/AIではないため、ご了承ください。
問題設定
・学習モデル構築に必要なデータは自分で用意する
・アノテーション作業は自分で行う
・YOLOv5を使用する(バッチサイズ 16、エポック数 200)
・学習モデル構築環境はGoogle Colaboratoryとする
・訓練データ(training data)は125枚
・検証データ(validation data)は35枚
方法
学習データの準備(元画像)
YOLOのために学習データを用意します。学習データは訓練データ(training data)と検証データ(validation data)の二つがあります。
訓練データを8割程度、検証データを2割程度とします。
今回は、switchで適当に録画したものをmicroSDカードに保存し、パソコンに保存しました。
その後、その動画を流してPC上でスクリーンショットをとり、160枚の学習データを用意しました。
元画像をリサイズ
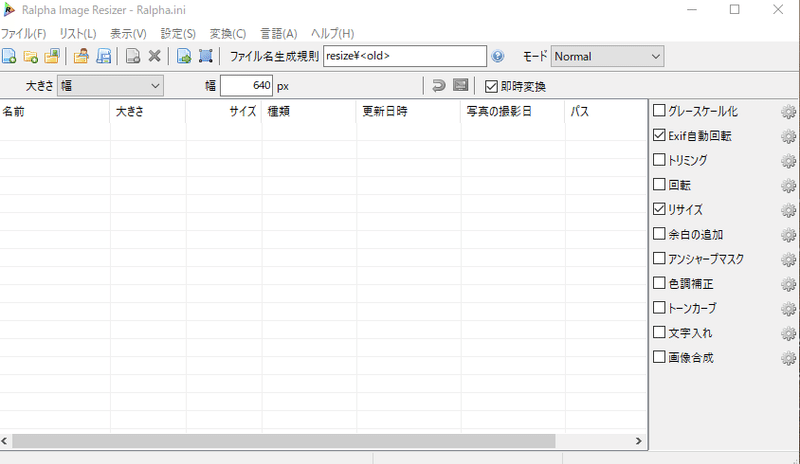
スクリーンショットした画像160枚をYOLOv5で使用するために、幅640pxにリサイズします。
リサイズには、Ralpa Image Resizerを使用しています。リサイズしたい画像を選択して、ドラッグすると自動でリサイズした画像が生成されます。
その後画像を、適当にtrainおよびvalフォルダを作成し,分けておきます。
アノテーション
アノテーションとは画像中に検出したいものがどこにあるか注釈をつけることです。今回はピクミンの種類を分類して検出したいので、画像中のピクミンに対し、ピクミンの種類と位置情報を記したデータを用意します。このデータを用いることで、学習モデルを構築し、学習モデルに使用していない画像・動画に対しても、ピクミンの検出ができるようになります。
アノテーションには、labelimgを使用しました。
アノテーションを行う前に、インストールしたlabelimgのフォルダ内にあるdata/predefined_classes.txtに、アノテーションしたいものに書き換えます。
今回はピクミンの種類を書きます。

その後、labelimgを起動し、「Open Dir」で先ほど作成したtrainフォルダを選択し、アノテーションを行います。この時、「Save」の下は「YOLO」にしましょう。
その後、「Create\nRectBox」(もしくはwキー)を選択し、実際にピクミンがいる箇所を1匹ずつ長方形で囲っていきます。囲うと、先ほど設定したpredefined_classes.txtの中から種類を選択できるため、ピクミンの種類に応じて、選択します(保存して、次の画像へ)。
解説記事用アノテーション動画(各ピクミンの位置情報データを作成) pic.twitter.com/1zsYNb1W1y
— ana (@ana93295878) September 4, 2023
これをtrainとvalの画像全てに行います(時間がかかるため大変)。
その後、labelimgの「data」フォルダには、画像と同じ名前のテキストファイル(画像中に存在する各ピクミンの種類と位置情報が書かれている)とclasses.txtが保存されています(後ほど使用します)。
Google Colaboratory(学習モデル構築と推論)
今回学習モデルの構築環境には、Google Colaboratoryを使用します。Google Colaboratoryとは、Googleが提供するサービスの一つでブラウザ上でPythonの記述や実行ができます(基本無料)。
Google Colaboratoryを調べ、適当な名前でノートブックを作成します。
「ランタイム」→「ランタイムのタイプを変更」→「GPU」を選択し、保存します。
その後、自分のGoogle ドライブをマウントします。
その後、下記のコードを打ち込み実行します(yolov5の導入)。
!git clone https://github.com/ultralytics/yolov5
%cd /content/yolov5/
!pip install -qr requirements.txt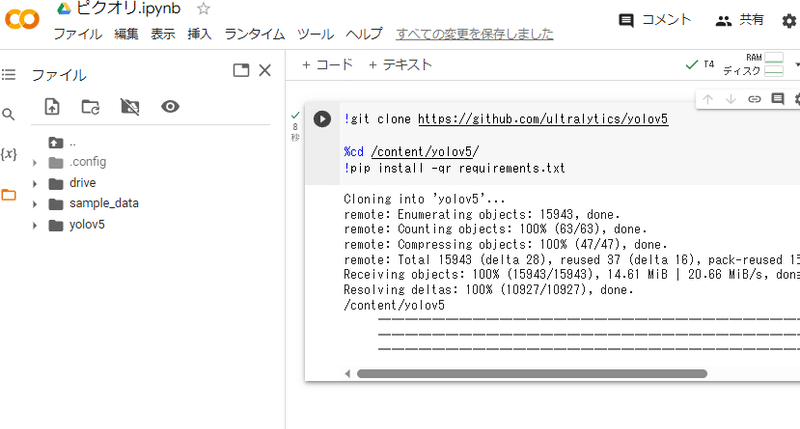
学習モデルのための画像とラベル(アノテーションで作成したtxtファイル)を自分のドライブにコピーします。
ディレクトリの作成は下記を参考にしてください。
content
|-drive
| |-MyDrive
| |-pikori
| |-train
| | |-tr_img1.png(画像)
| | |-tr_img1.txt(ラベル)
| | |-tr_img2.png
| | |-tr_img2.txt
| | ・・・
| | |-tr_img125.png
| | |-tr_img125.txt
| | |-classes.txt
| |
| |-val
| | |-val_img1.png(画像)
| | |-val_img1.txt(ラベル)
| | |-val_img2.png
| | |-val_img2.txt
| | ・・・
| | |-val_img35.png
| | |-val_img35.txt
| | |-classes.txt
| |
| |-test
| | |-test_img1.png(画像)
| | |-test_video.mp4(動画)
| | ・・・
| |
| |-pikori.yaml
|
|-yolov5pikori.yamlファイルは下記のとおり、train、val、testフォルダのパス、分類するピクミンの数(5)とピクミンの種類を書きます。
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /content/drive/MyDrive/pikori/train
val: /content/drive/MyDrive/pikori/val
test: /content/drive/MyDrive/pikori/test
# number of classes
nc: 5
# class names
names: ['AkaPikmin','AoPikmin','KiPikmin','SiroPikmin','MurasakiPikmin']学習モデルの構築には下記のコードを使用します。
#学習モデルの構築
yaml_path = '/content/drive/MyDrive/pikori/pikori.yaml'
!python train.py --img 640 --batch 16 --epochs 200 --data {yaml_path} --weights yolov5s.pt
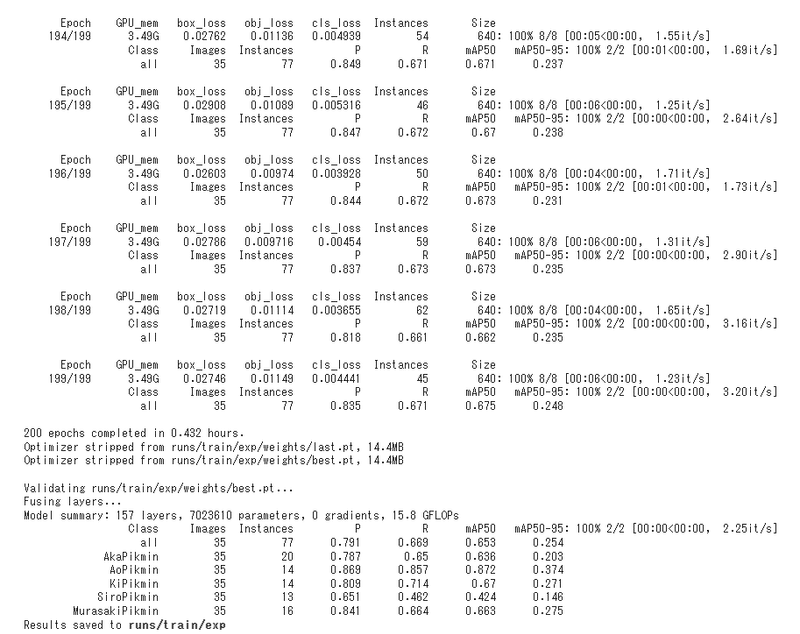
エポック数を200としているので、200回学習が行われ、/content/yolov5/runs/train/exp/weightsフォルダにあるbest.ptが学習中で最も評価が高かったものです。
また、TensorBoardによって学習の様子を見ることができます。
#モデルの学習過程を表示
# tensorboardの表示
%load_ext tensorboard
%tensorboard --logdir runs

今回は学習モデル用の画像が少ないため、PrecisionおよびRecallがどちらも低いです。
評価指標であるPはPrecision(予測の精度を表す、例:赤ピクミンと検出された総数のうち、実際に赤ピクミンであった割合)、RはRecall(検出による取りこぼしの少なさを表す、例:実際は赤ピクミンであった全ての事象の内、赤ピクミンと正しく検出できた割合)を示しています。
他にも様々な評価指標が存在し、場面に応じてどの評価指標を重視するか変わってくると思います。
学習モデルを使用して実際に画像・動画を用いて、検出を行います。
testフォルダに画像および動画をいれます。
動画も幅が640pxになるようにリサイズしておきます(動画のリサイズには、こちらのサイトを使用しました。URL:https://www.resize-video.com/jp/)。
#学習モデルを用いて,物体検出
#testの画像、動画を使う
best_param_path = '/content/yolov5/runs/train/exp/weights/best.pt'
test_datas_dir = '/content/drive/MyDrive/pikori/test'
!python detect.py --source {test_datas_dir} --weights {best_param_path} --conf 0.25 --name trained_exp --exist-ok --save-conf --save-txt結果は、ある程度検出はできていますが、撃墜演出の紙吹雪をピクミンと誤検出してしまっていました。
今後、学習データを増やす必要があります。
YOLOを用いてピクオリの色管理が可視化できないか試してみました。
— ana (@ana93295878) December 31, 2022
学習データが少ないので、撃墜演出の紙吹雪をピクミンと誤検出してしまっています。
訓練用画像:125枚
検証用画像:35枚 pic.twitter.com/INSEPmHObg
なお、推論結果は/content/yolov5/runs/detect/trained_exp/labelsフォルダに入っているため、こちらのコードでダウンロードできます。(画像・動画は、/content/yolov5/runs/detect/trained_expフォルダに入っています。)
# ダウンロードしたいフォルダを zip 圧縮する
!zip -r /content/download.zip /content/yolov5/runs/detect/trained_exp/labels
# 圧縮した zip ファイルをダウンロードする
from google.colab import files
files.download("/content/download.zip")ダウンロードしたテキストファイルを開くと、このような感じになります。

このテキストファイルを使用することで、ピクミンの使用割合を数値化することができます。
まとめ
今回は、物体検出アルゴリズムであるYOLOv5を用いて、ピクミンを自動検出することで、使用割合を可視化(数値化)できないか検証しました。
具体的には、訓練データを125枚、検証データを35枚用意し、Google Colaboratoryを用いて学習モデルを構築しました。
学習データが少ないため、精度がやや低いですが、今後学習用データを増やすことで改善する可能性があります。
なお、ステージ(背景)ごとの学習データが必要な可能性もあります。
また、ピクオリミラーではどちらのピクミンか判断することが難しく、ミラーでの検出は不可能であると考えています。
さらに、応用として技ごとの検出が挙げられますが、技ではどのフレームを使用するか、また学習データが膨大になることが課題点として挙げられます。学習データが膨大になると、アノテーション作業の時間も膨大になります。
今後、より簡単に学習モデルが構築できるようになれば、スマブラ分析者用のツールおよびリアルタイムでの技の自動検出が可能になると考えられます。
あとがき
実際にこちらの分析をしていたのは、半年前のことであり、noteに書くまでに時間があいてしまいました。
もしかしたら、今回の内容は需要がないかもしれませんが、自分自身が記録として見返せるように書きました。
また、私の専門は機械工学ですので、誤ったことを書いているかもしれませんが、ご了承ください。
そのため、今回の内容としても機械学習/AIの本質的な内容についてはあまり言及しておらず、手法(各ソフトや開発環境の使い方)を主軸に書かせていただきました。
今後、このような学習モデルがスマブラ分析の力になればと思っています。
ここまでお読みいただきありがとうございました。
この記事が気に入ったらサポートをしてみませんか?